데이터 분석
Numpy
- 다차원 배열(행렬)을 쉽게 처리하고 효율적으로 사용할 수 있도록 지원하는 파이썬의 라이브러리
- 수치해석, 통계 관련 기능을 구현한다고 할 때 가장 기본이 되는 모듈
- Ndarray 타입의 배열을 만들 수 있다
import numpy as np
x=np.array([3, 1, 2])
Python List vs Numpy array(ndarray)
- 선언 형태의 차이
- List : 원소로 여러가지 자료형을 허용한다
- Ndarray : 원소로 한 가지 자료형만 허용한다
- 선언 형태의 차이
- List : 내부 배열의 원소 개수가 달라도 된다
- Ndarray : 내부 배열의 원소 개수가 같아야 한다
- 연산의 차이
- List : 빼기, 곱하기, 나누기 연산은 불가. 더하기는 리스트 이어붙이기
- Ndarray : 더하기, 빼기, 곱하기, 나누기 연산 동일하게 같은 위치의 원소끼리 연산
Numpy 관련 속성 및 메소드
- .ndim : 배열의 차원 수를 반환
- .shape : 배열 각 차원의 크기를 튜플 형태로 표현
- np.dot(array1, array2) : 배열의 내적 연산
- np.matmul(array1, array2) : 행렬의 행렬곱 연산
- A X B일때 A=[axb], B=[bxc]로 A의 열의 개수와 B의 행의 개수가 동일해야 한다
- np.zeros(m,n) : m x n 크기의 영행렬 생성
- np.ones(m,n) : m x n 크기의 유닛행렬 생성
- np.full((m,n), k) : m x n 크기의 모든 원소가 k인 행렬 생성
- np.eye(n) : n x n 크기의 단위행렬 생성
- .flatten() : 행렬의 평탄화 작업 (N차원 배열을 1차원 배열로 변환시켜주는 작업)
- .reshape() : 배열의 차원을 변경
- np.arange([start,] stop, [step,]) : 특정 배열을 만들어 줌
- np.random.randint(low, [high,][size,])
- np.random.rand(m,n) : m x n 크기의 배열 생성 및 0~1 사이의 난수로 초기화
Pandas
- 구조화된 데이터나 표 형식의 데이터를 빠르고 쉽게 다룰 수 있도록 하는 라이브러리
- Series는 1차원 데이터, DataFrame는 2차원 데이터
Series
- List와 다르게 인덱스를 직접 지정할 수 있다
- 인덱스를 지정하지 않으면 0, 1, 2, … 로 설정된다
DataFrame
- series들을 결합해 놓은 형태
- 인덱스와 컬럼을 기준으로 표 형태처럼 데이터를 저장
index = ['2018', '2019','2020', '2021']
Yeonghee = pd.Series([143, 150, 157, 160], index=index)
Cheolsu = pd.Series([165, 172, 175, 180], index=index)
growth = pd.DataFrame({
'영희':Yeonghee,
'철수':Cheolsu
})
data={
'영희':[143,150,157,160],
'철수':[165,172,175,180]
}
growth=pd.DataFrame(data, columns=['영희','철수'],index=index)
growth.astype('float')
growth.astype({'영희':'float'})
Pandas
- read_csv() : .csv 확장자 파일 읽기
- .shape : 데이터 프레임 모양 확인(행, 열)
- dataframe.컬럼명 또는 dataframe[’컬럼명’] : 데이터프레임에서 해당 컬럼만 select
- .iloc[] : index를 활용해 location을 지정
- .loc[] : index 및 column명을 통해 location을 지정
- dataframe.describe() : 데이터프레임 객체의 설명적 통계량을 출력
- series.map() : 데이터 변경. 시리즈 자료형(1차원)에서 사용
- series 또는 dataframe .apply(함수, axis)
- axis=’index’ 또는 0 : row 방향으로 함수 적용
- axis=’columns’ 또는 1 : column 방향으로 함수 적용
- dataframe.groupby(컬럼) : 컬럼을 기준으로 group을 지음
- dataframe.reset_index() : 인덱스를 기본 인덱스인 0, 1, 2, …로 변경
- dataframe.sort_values(by=컬럼명, ascending=bool) : 컬럼명을 기준으로 정렬. ascending이 False일 경우 내림차순 정렬
- dataframe.dtypes : 전체 컬럼의 데이터 타입 확인
- dataframe.column.dtype : 컬럼 하나의 데이터 타입 확인
- dataframe.column.astype() : 데이터 타입 변경
- pd.isnull(column) : NaN 데이터 확인
- pd.notnull(column) : NaN이 아닌 데이터 확인
- dataframe.column.fillna(대체 값) : NaN 대체 값으로 변경
- dataframe.column.replace(기존 값, 새로운 값) : 기존 값 새로운 값으로 대치
- dataframe.rename(columns={’기존컬럼명’:’새로운컬럼명’})
- dataframe.rename(index={0:’인덱스명’})
- pd.concat([dataframe1, dataframe2])
- join()
데이터 시각화
- 그래프, 차트, 다이어그램 등 다양한 시각화 도구를 사용하여 데이터를 시각적으로 표현한 것
- 데이터 시각화는 복잡한 데이터 집합을 직관적이고 이해하기 쉬운 형태로 변환하여 데이터의 패턴, 추세, 상관 관계를 파악하는데 유리하다
데이터 시각화의 목적
- 데이터의 패턴과 추세 파악
- 데이터 간 관계 이해
- 인사이트 도출
Matplotlib
- 파이썬에서 가장 널리 사용되는 데이터 시각화 라이브러리
- 그래프, 차트, 플롯 등 다양한 시각화 요소를 생성하고 데이터를 시각적으로 나타낼 수 있다
기본 그래프 그리기
- 그래프 그리기 : plt.plot([x좌표],[y좌표],’포맷 문자열’)
- x축, y축 범위 지정 : plt.axis([xmin, xmax, ymin, ymax])
- 그래프 표시 : plt.show()
- 축 레이블 설정하기
- plt.xlabel(’x축 레이블’, [labelpad, loc, fontdict])
- plt.ylable(’y축 레이블’, [labelpad, loc, fontdict])
- 범례 표시하기
- plt.legend(loc=위치, ncol=열의개수, fontsize, frameon, shadow)
- 타이틀 설정하기 : plt.title(’타이틀’, [loc, pad])
- 그리드 설정하기 : plt.grid(True, axis)
import matplotlib.pyplot as plt
plt.plot([1, 2, 3, 4], 'go-', label='graph1')
plt.plot([1,2,3,4],[1,2,3,4], linestyle='dashed', color='#8f321a', label='graph2')
font1={'family': 'fantasy', 'color' : 'red', 'weight' : 'normal', 'size' : 'xx-large'}
plt.axis([0, 5, 0, 10])
plt.xlabel('x-label', labelpad=30, loc='right', fontdict=font1)
plt.ylabel('y-label', labelpad=30, loc='top')
plt.legend(ncol=2, fontsize=20, frameon=True, shadow=True, loc='best')
plt.title('Title', loc='right', pad=50)
plt.grid(True, axis='both')
plt.show()
막대 그래프 그리기
- 그래프 그리기 : plt.bar([x값], [y값], color, width)
- 눈금 표시하기
- plt.xticks([x값], [눈금])
- plt.yticks([y값], [눈금])
- 수평 막대 그래프 그리기 : plt.barh([y값], [x값], color, height)
plt.bar([0, 1, 2], [100, 200, 300], color=['r','g', 'b'], width=0.1)
plt.xticks([0, 1, 2], ['a', 'b', 'c'])
plt.show()
import numpy as np
y=np.arange(3)
plt.barh(y, [100,200,300], height=0.1)
plt.yticks(y, ['a','b','c'])
plt.show()
산점도 그리기
- 그래프 그리기 : plt.scatter([x값], [y값], s, c, cmap, alpha)
- s : 마커 크기
- c : 마커 색상
- cma : 컬러맵
- alpha : 투명도
n=50
x=np.random.rand(n)
y=np.random.rand(n)
area=(10 * np.random.rand(n)+1)**2
colors=np.random.rand(n)
plt.scatter(x, y, s=area, cmap ='plasma', c=colors, alpha = 0.5)
plt.show()
파이차트 그리기
- 그래프 그리기 : plt.pie([비율], labels, autopct, explode, colors, wedgeprops)
- labels : 레이블
- autopct : 소수점 자리
- explode : 부채꼴이 파이 차트의 중심에서 벗어나는 정도
- colors : 색
- wedgeprops : 부채꼴 스타일
ratio=[34,32,16,18]
labels = ['a','b','c','d']
colors = ['red', 'yellow', 'green', 'blue']
plt.pie(ratio, labels=labels, autopct='%.1f%%', explode=[0,0.1,0,0.1], colors=colors)
plt.show()
실습
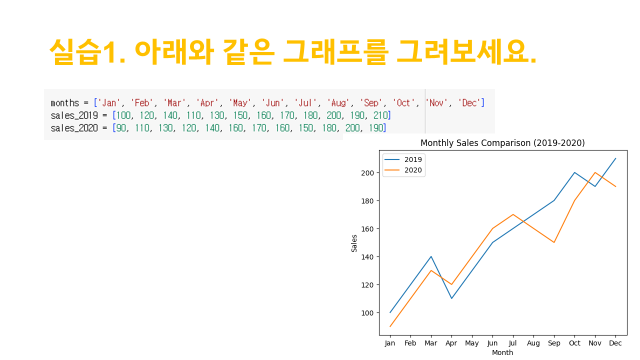
months = ['Jan','Feb','Mar','Apr','May','Jun','Jul','Aug','Sep','Oct','Nov','Dec']
sales_2019=[100,120,140,110,130,150,160,170,180,200,190,210]
sales_2020=[90,110,130,120,140,160,170,160,150,180,200,190]
plt.plot(sales_2019, color='skyblue', label='2019')
plt.plot(sales_2020, color='orange', label='2020')
plt.xticks([0,1,2,3,4,5,6,7,8,9,10,11],months)
plt.xlabel('Month')
plt.ylabel('Sales')
plt.legend(ncol=1, fontsize=10, frameon=True, loc='upper left')
plt.title('Monthly Sales Comparison (2019-2020)')
plt.show()
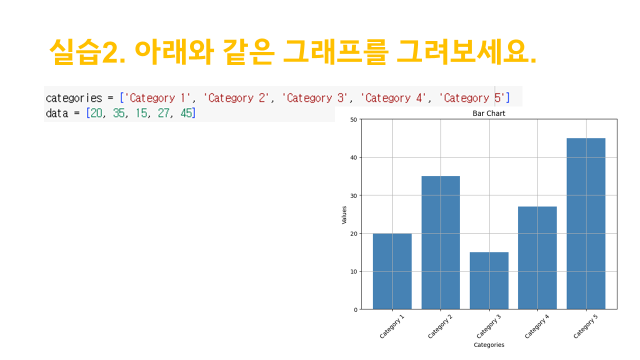
plt.bar([0, 1, 2, 3, 4], [20, 35, 15, 27, 45], color='blue', width=0.7)
plt.xticks([0, 1, 2, 3, 4], ['Category 1', 'Category 2', 'Category 3', 'Category 4', 'Category 5'], rotation=45)
plt.grid(True, axis='both')
plt.axis([-0.5, 4.5, 0, 50])
plt.xlabel('Categories')
plt.ylabel('Values')
plt.title('Bar Chart')
plt.show()
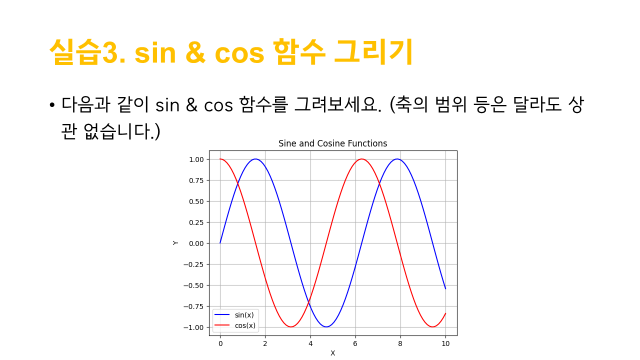
x=np.arange(0, 4*np.pi, 0.1)
y1=np.sin(x)
y2=np.cos(x)
plt.plot(x, y1, color='blue', label='sin(x)')
plt.plot(x, y2, color='red', label='cos(x)')
plt.xlabel('x')
plt.ylabel('y')
plt.legend(ncol=1, fontsize=10, frameon=True, loc='lower left')
plt.title('Sine and Cosine Functions')
plt.grid(True, axis='both')
plt.show()
지도 시각화
folium
- leaflet.js기반으로 만들어진 Python 지도 시각화 라이브러리
- 위,경도 좌표를 기준으로 지도를 생성한다
- 인터랙티브한 지도를 생성하고 마커를 추가하여 시각화 할 수 있다
- 범위를 표기할 수 있다
- 지도 생성 : m=folium.Map(location=[위도,경도],zoom_start=확대정도,tiles=타일스타일,width=가로,height=세로)
- 마커 추가 : folium.Marker([위도,경도],popup=”문구”,tooltip=”문구”,icon=folium.Icon(color=”색상”,icon=”아이콘”).add_to(m)
- folium.ClickForMarker() : 지도 위를 클릭했을 때 마커를 생성함
- folium.LatLngPopup() : 지도 위를 클릭했을 때, 위도와 경도 표시
- folium.Circle(), folium.CircleMarker() : 지도에 원을 표시한다
import folium
m = folium.Map(location=[37.547647896577175, 126.94245451708481], zoom_start=14, width=500, height=500)
folium.TileLayer("Stamen Terrain").add_to(m)
folium.LayerControl().add_to(m)
folium.Marker([37.547647896577175, 126.94245451708481], popup='subway', tooltip='대흥역', icon=folium.Icon(color='red', icon='fa-solid fa-train-subway', prefix='fa-solid')).add_to(m)
folium.Marker([37.543937391864404, 126.9510204453621], popup='subway', tooltip='공덕역').add_to(m)
m.add_child(folium.LatLngPopup())
m
import folium
m2 = folium.Map(location=[37.547647896577175, 126.94245451708481], zoom_start=14, width=500, height=500)
folium.TileLayer("Stamen Terrain").add_to(m2)
folium.LayerControl().add_to(m2)
lati=data['위도'].values.tolist()
longi=data['경도'].values.tolist()
for i in range(len(lati)):
folium.Marker(
[lati[i],longi[i]],
popup='taxi',
icon=folium.Icon(color='black', icon='fa-solid fa-taxi', prefix='fa-solid')
).add_to(m2)
m2
