머신러닝 소개 - 머신러닝이란? / Model Selection
기계가 일일이 코드로 명시하지 않은 동작을 데이터로부터 학습하여
실행할 수 있도록 알고리즘을 개발하는 연구 분야
* 데이터 / 학습 / 알고리즘이 머신러닝의 키워드!
- 알고리즘 : 문제를 풀기 위한 의사 결정 과정
- 데이터 : 주관적인 기준이 아닌 수치에 근거한 객관적인 기준 (객관적인 기준을 위한 정답과 요인들)
- 학습 : 수치에 들어갈 값을 컴퓨터가 스스로 찾는다! (데이터로부터 최적의 값을 찾는 과정)
즉, 머신러닝이란 풀고자 하는 문제의 정답과 데이터를 주고 기계를 학습시켜서 정답을 맞추게 하는 것!
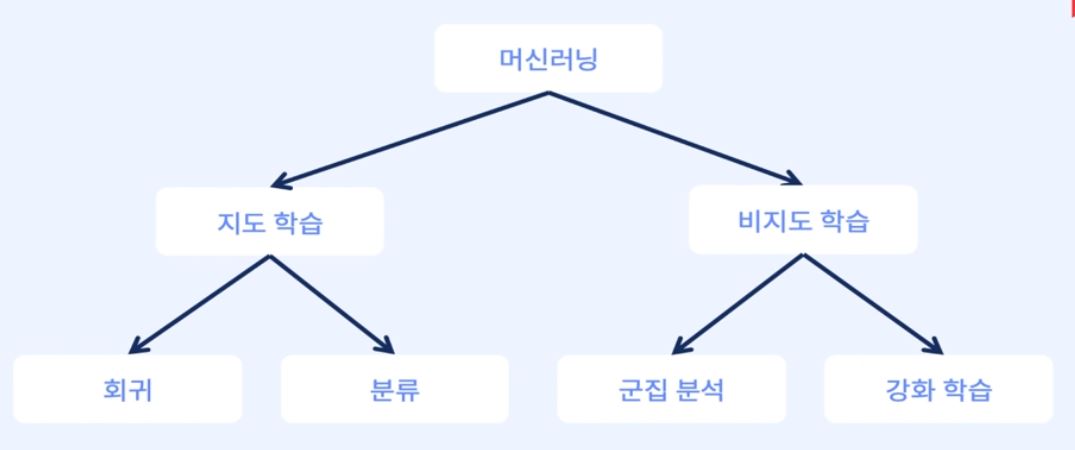
머신러닝 알고리즘은 크게 지도학습과 비지도학습으로 나눌 수 있다.
-
지도학습(Supervised Learning)
입력 데이터와 해당 데이터에 대한 레이블(정답)을 함께 제공하며 학습하는 방법1)분류(Classification) : 정답이 비연속형(범주형) 변수
여기서 범주형 변수란? 값이 정수처럼 명확함(ex. 성별, 도시..)
ex. 분류 문제 : 키와 몸무게를 이용해 성별을 맞추기2)회귀(Regression) : 정답이 연속형 변수
여기서 연속형이란? 값이 정수처럼 명확하지 않음(ex. 키, 몸무게..)
ex. 회귀 분석 문제 : 키를 이용해 몸무게를 예측하기
-
비지도학습(Unsupervised Learning)
입력 데이터에 대한 레이블(정답)을 제공하지 않고 데이터의 구조나 패턴을 찾아내는 방법1)군집(Clustering) : 주어진 데이터가 어떻게 구성되었는지 알아내는 방법
2)차원축소(Dimensionality Reduction) : : 행동에 따른 보상을 최대화 시키는 학습 방법
model selection
1. 모델
- 어떤 x가 주어졌을 때 f라는 함수를 통해 y라는 값을 도출하는 과정
이 때 함수 f를 모델 또는 알고리즘이라고 부른다.
즉, 머신러닝에서 모델은 입력 변수 x와 출력 변수 y 사이의 함수 관계를 모델링하는 것!
y = F(x) # 이 때 x는 데이터, y는 예측값
1) 모델의 목적 : 학습된 데이터를 기반으로 새로운 입력 데이터에 대한 출력 값을 예측하는 것
2) 모델의 평가 : 학습된 모델이 새로운 데이터에 대해 얼마나 정확하게 예측하는지를 평가하는 것
이를 위해서는 모델이 예측한 출력 값과 실제 정답 값을 비교하는 방법이 필요
2. 데이터 Train data, Test data
1) Train data : 학습에 사용되는 데이터
2) Test data : 학습에 사용되지 않는 데이터
모델이 실제로 잘 예측하는지 알기 위해서는 학습에 사용되지 않는 데이터를 이용해 평가해야 한다.
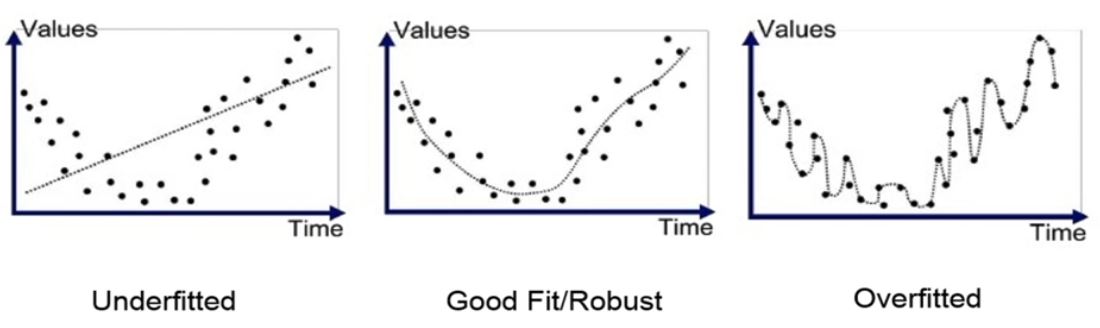
모델의 평가와 데이터의 관계 -> 과적합(overfitting) & 과소적합(underfitting)
모델의 성능은 학습 데이터와 테스트 데이터의 관계에 따라 결정된다.
학습 데이터에 대해서는 높은 정확도를 보이지만, 테스트 데이터에 대해서는 정확도가 낮아지는 경우가 있는데, 이를 과적합(overfitting)이라고 한다.
반대로 모델이 너무 단순하여 학습 데이터에 대해서도 낮은 정확도를 보이는 경우에는 과소적합(underfitting)이라고 한다.
즉,
underfitting : 학습 데이터(Train data)를 잘 맞추지 못하는 현상
이는 모델이 너무 단순하여 학습 데이터의 다양한 패턴을 잡아내지 못하는 경우 발생!
overfitting : 학습 데이터(Train data)를 잘 맞추지만 학습 데이터 외에는 잘 맞추지 못하는 현상
이는 모델이 학습 데이터에 너무 맞춰져 있어서 학습 데이터 외에는 다양한 패턴을 잡아내지 못하는 경우 발생!
-
underfitting을 확인하는 방법
train data로 학습된 모델을 train data로 평가한다
train data를 잘 맞추지 못한다면 underfittin 상태추가적으로, underfitting인 경우에는 모델이 학습 데이터에서 너무 단순한 경향을 보이는 경우도 있다.
이를 해결하기 위해 모델의 복잡도를 늘리거나, 더 많은 학습 데이터를 사용하는 등의 방법을 고려할 수 있다. -
overfitting을 확인하는 방법
train data를 잘 학습한 모델을 test data로 평가한다
train data는 잘 맞추지만 test data를 잘 맞추지 못한다면 overfitting 상태overfitting인 경우에는 모델이 학습 데이터에 너무 맞추어져 다른 데이터에서 성능이 떨어지는 현상을 보이는데, 이를 해결하기 위해서는 모델의 복잡도를 낮추거나, regularization 기법을 적용하는 등의 방법을 고려할 수 있다.
데이터 분할(data split)이란?
데이터를 train data와 test data로 나누는 것
train data는 모델을 학습하는 데에 사용되며, 모델의 가중치(weight)를 조정한다.
반면에 test data는 학습에 사용되지 않은 데이터로, 모델이 실제로 얼마나 잘 일반화되어 예측을 수행하는지 평가하는 데 사용된다.
데이터 분할은 모델 평가를 위해 필수적인 과정으로, 이를 통해 모델이 학습 데이터에 대해서만 잘 동작하는 overfitting을 방지하고, 실제 데이터에서도 잘 동작하는 모델을 만들 수 있다.
데이터 분할은 일반적으로 학습 데이터와 테스트 데이터를 8:2, 7:3 또는 6:4 등으로 나누어서 사용한다.
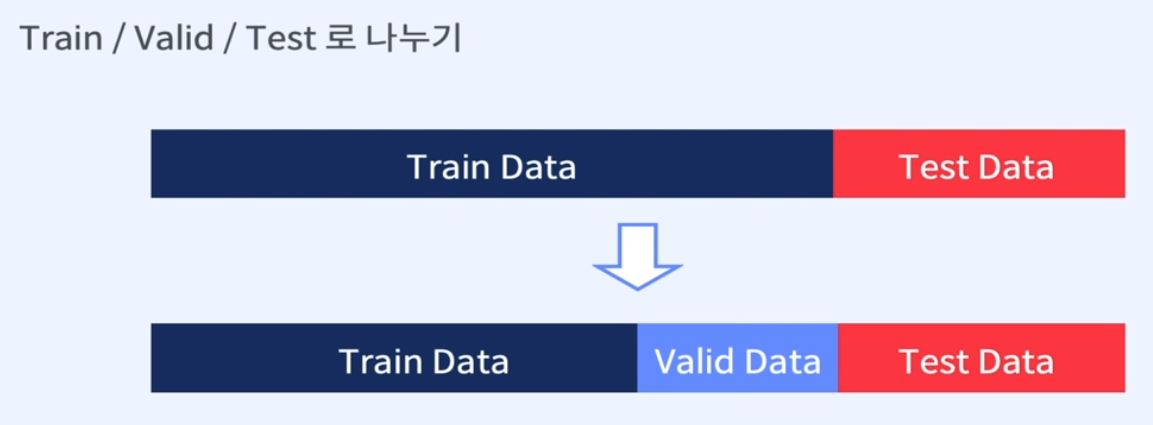
- 각 데이터의 용도
- Train data : 학습에 사용되는 데이터
- Valid data : 학습이 완료된 모델을 검증하기 위한 데이터 / 학습에 사용되지는 않지만 관여하는 데이터
- Test data : 최종 모델의 성능을 검증하기 위한 데이터 / 학습에도 사용되지 않으며 관여하지도 않는 데이터
정확하게 말하면, 일반적으로 머신러닝에서는 Train data와 Test data만 사용하며, Valid data는 Train data에서 일부를 분리하여 모델의 성능을 검증하기 위한 용도로 사용된다.
데이터를 Train data와 Test data로 나누는 이유는, 모델의 성능을 평가하기 위해서이다.
Train data로 모델을 학습시키고, Test data를 사용하여 학습된 모델의 성능을 평가한다.
그러나, 모델이 Test data에 과적합(overfitting)되는 경우가 있다.
이러한 경우, 모델이 Train data에는 잘 맞지만 Test data에는 잘 맞지 않게 된다.
이를 방지하기 위해, Valid data를 사용하여 모델의 성능을 검증하고, 모델의 하이퍼파라미터를 조정하는 등의 작업을 수행한다.
따라서, 보통 Train data, Valid data, Test data로 데이터를 분리하여 사용합니다.
하지만, valid data에 overfitting되는 문제가 발생할 수 있음
=> cross validation : 데이터를 여러 개의 fold로 나누어서 각각의 fold를 검증용 데이터로 사용하고 나머지를 학습용 데이터로 사용하는 방법
예를 들어 5-fold cross validation을 수행하면 데이터를 5개의 fold로 나누고,
각각의 fold를 검증용 데이터로 사용하고 나머지 4개의 fold를 학습용 데이터로 사용한다.
이렇게 나누어진 fold들을 순서대로 사용하여 검증을 반복한다.
이를 통해 검증용 데이터와 학습용 데이터를 여러 번 변경하여 모델을 평가하고, overfitting되는 것을 방지할 수 있다.
Cross Validation 종류
-
LOOCV (Leave One Out Cross Validation)
: 하나의 데이터를 제외하고 모델을 학습한 후 평가
데이터 개수만큼 모델을 학습해야 하고, 데이터가 많을 경우 시간이 오래 걸린다. -
K-Fold Cross Validation
: 데이터를 k개로 분할한 후 한개의 분할 데이터를 제외한 후 학습에 사용
제외된 데이터는 학습이 완료된 후 평가에 사용
즉, 데이터를 k개의 폴드로 나누고, 각각의 폴드를 한 번씩 제외하고 나머지 폴드로 모델을 학습하고 평가하는 방법
예를 들어, 5-Fold Cross Validation은 데이터를 5개의 폴드로 나누고, 첫 번째 폴드를 제외한 4개의 폴드로 모델을 학습하고 첫 번째 폴드를 검증 데이터로 사용하는 것을 5번 반복한다.
각각의 반복에서 검증 데이터로 사용하는 폴드를 바꾸면서 총 k번 모델을 학습하고 평가한다.
이 방법은 LOOCV보다 계산 비용이 적고, overfitting이나 underfitting 문제를 해결할 수 있다.
Cross Validation 평가
- Cross Validation을 이용하면 방법에 따라 k개의 평가지표가 생성
- 생성된 평가 지표의 평균을 이용해 모델의 성능을 평가
- 전체 Train 데이터를 이용해 모델 학습
step 1) Cross Validation을 이용하면 방법에 따라 K개의 평가지표가 생성
step 2) 생성된 평가지표의 평균을 이용해 모델의 성능을 평가
step 3) 전체 Train 데이터를 이용해 모델 학습
즉, Cross Validation을 통해 K개의 모델을 학습하고, 이를 평가하여 K개의 평가 지표를 생성한다.
이후 이들의 평균을 이용해 모델의 성능을 평가하며, 이를 통해 모델의 하이퍼파라미터를 튜닝하거나 다른 모델과 비교하는 등 다양한 활용이 가능하다.
마지막으로 전체 Train 데이터를 이용해 모델을 최종 학습시키고, Test 데이터를 통해 모델의 성능을 최종적으로 평가한다.
