머신러닝
1.머신러닝 소개 - 머신러닝이란? / Model Selection
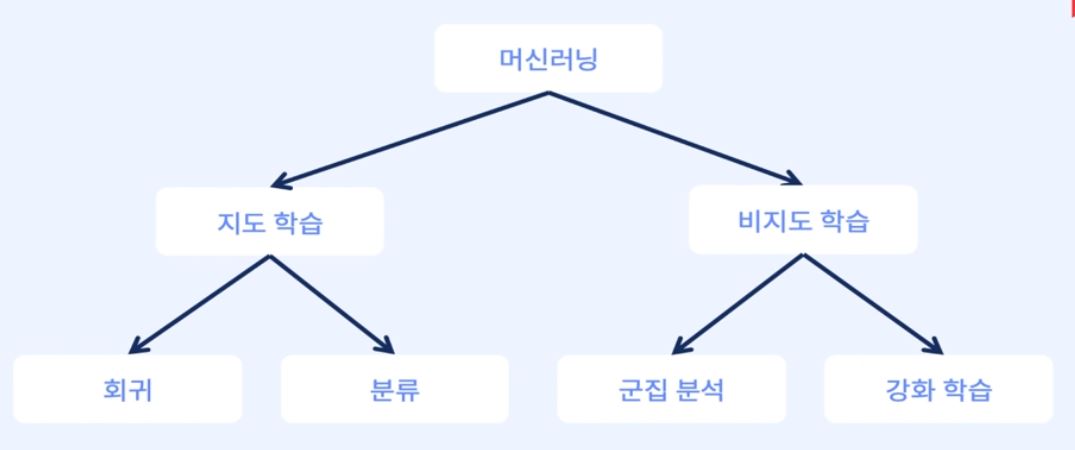
머신러닝 소개 - 머신러닝이란? / Model Selection기계가 일일이 코드로 명시하지 않은 동작을 데이터로부터 학습하여실행할 수 있도록 알고리즘을 개발하는 연구 분야\* 데이터 / 학습 / 알고리즘이 머신러닝의 키워드!알고리즘 : 문제를 풀기 위한 의사 결정 과
2.선형 회귀 Linear Regression

선형 회귀(Linear Regression)의 정의예측 값을 직선으로 표현하는 모델하나의 독립 변수와 하나의 종속 변수 간의 선형 관계를 모델링하는 데 사용되는 기계 학습 기법선형 회귀 수식y는 종속 변수 (예측하려는 값)x는 독립 변수 (예측에 사용되는 값)b0는 y
3.정규화(Regularization)
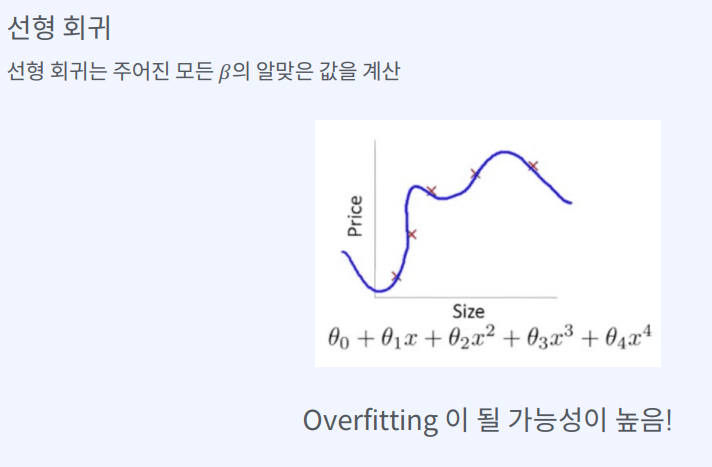
정규화(Regularization)머신 러닝과 통계에서 모델이 학습 데이터에 과적합(overfitting)되는 것을 방지하는 기술입니다.과적합은 모델이 너무 복잡하게 되어 학습 데이터의 잡음까지 학습하게 되어, 새로운 데이터에서 성능이 저하되는 문제가 발생합니다.정규화
4.로지스틱 회귀(Logistic Regression)
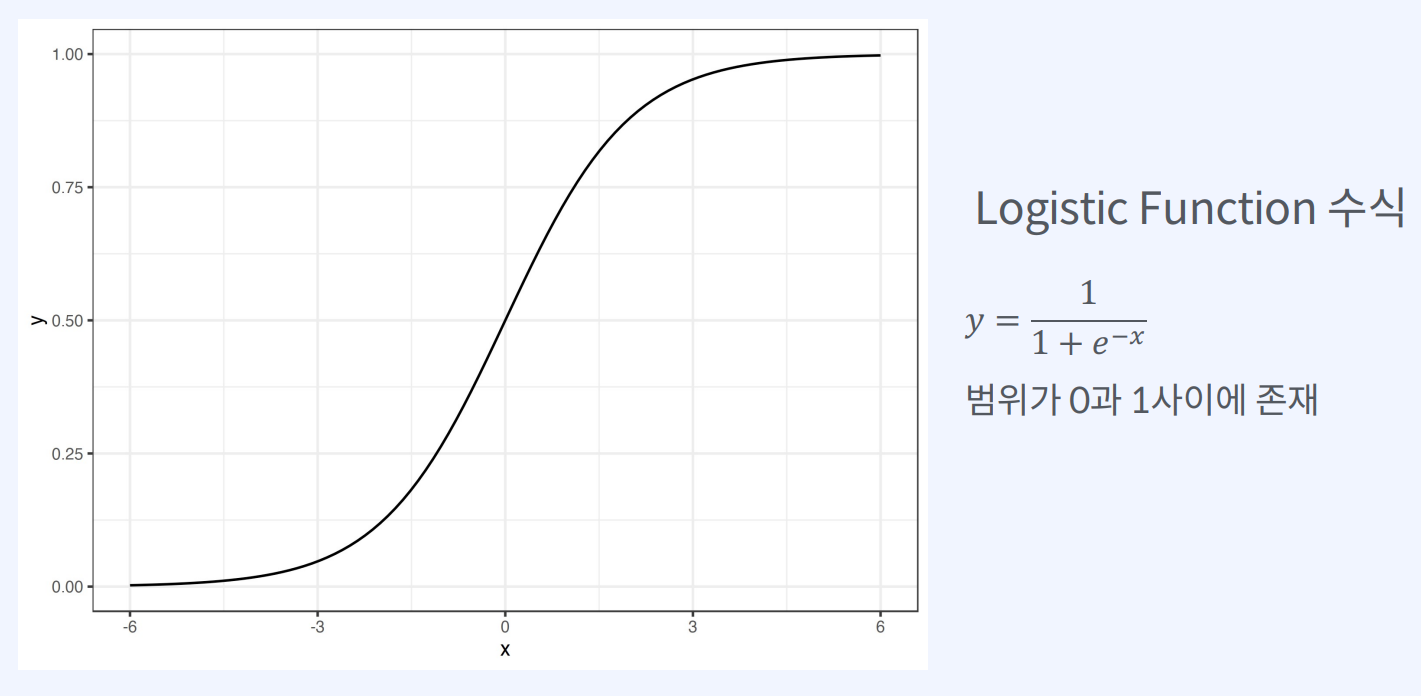
로지스틱 회귀(Logistic Regression)는이진 종속 변수(또는 결과 또는 반응 변수로도 알려짐)와 하나 이상의 독립 변수(또는 예측 변수 또는 설명 변수로도 알려짐) 간의 관계를 분석하고 모델링하는 데 사용되는 통계적 방법입니다.로지스틱 회귀 모델은 일반화
5.선형 회귀 Linear Regression 실습하기 (python)
이 코드는 데이터 분석 라이브러리인 numpy, pandas, matplotlib.pyplot을 사용하여 데이터 시각화를 수행하는 코드입니다.np.random.seed(2021) 코드는 랜덤 함수를 사용할 때, 항상 같은 결과를 출력하도록 설정하는 코드입니다.이를 통해
6. 당뇨병 진행을 예측하는 Linear Regression 실습하기 (python)
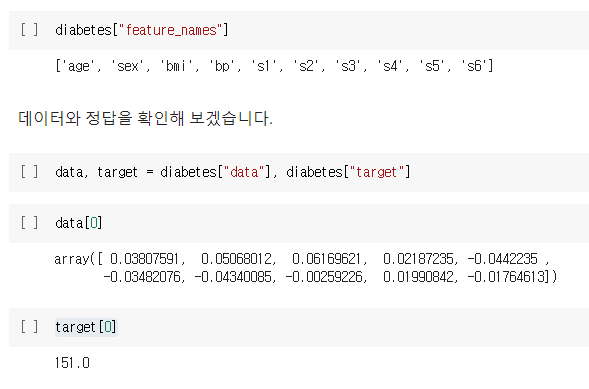
당뇨병 진행도와 관련된 데이터를 이용해 당뇨병 진행을 예측하는 Linear Regression을 학습해 보겠습니다.Data Load데이터는 sklearn.datasets 의 load_diabetes 함수를 이용해 받을 수 있습니다.당뇨병 데이터에서 사용되는 변수명은 f
7.Logistic Regression으로 폐암의 양성 음성 분류 실습하기 (python)

Logistic Regression으로 폐암의 양성 음성 분류Data - 이번 실습에서 사용하는 데이터는 폐암의 양성, 음성 여부를 구분하는 문제입니다.Data Load - 데이터는 sklearn.datasets 의 load_breast_cancer 함수를 이용해 받을
8.Iris의 종류 분류(Multiclass) 실습하기 (python)

Iris의 종류 분류(Multiclass)이번에는 Class가 여러개인 데이터를 Logistic Regression으로 예측해 보겠습니다.Data Load - 데이터는 sklearn.datasets 의 load_iris 함수를 이용해 받을 수 있습니다.데이터에서 사용되
9.의사결정나무(Decision Tree) 정의
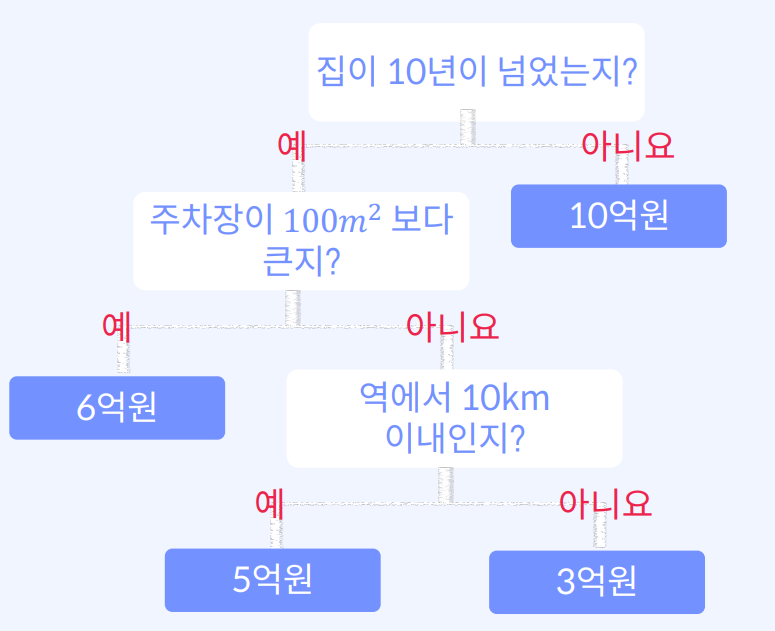
의사결정나무(Decision Tree) 정의 : 의사 결정 규칙과 그 결과물들을 트리 구조로 도식화한 것즉, 의사결정나무(Decision Tree)는 데이터 분석과 머신 러닝에서 많이 사용되는 분류 및 예측 모델 중 하나입니다. 이는 그래프 형태로 구성된 모델로, 각
10.Decision Tree Classification 실습 (python)
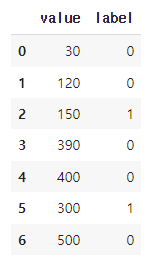
샘플 데이터와 Decision Tree Classification위 코드는 pandas, numpy, matplotlib.pyplot 모듈을 불러온 후, 7개의 데이터를 가지고 있는 DataFrame을 만들고 출력하는 코드입니다.데이터는 "value"와 "label"
11.Decision Tree Regressor 실습 (python)
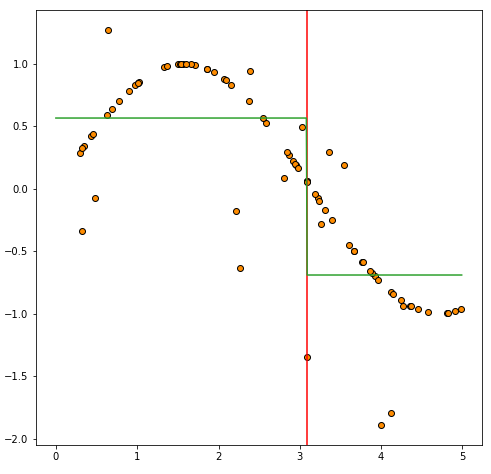
샘플 데이터와 Decision Tree Regressor Decision Tree Regressor는 지도학습 알고리즘 중 하나로, 입력값과 해당 출력값의 연속적인 데이터를 이용해 예측 모델을 생성하는데 사용됩니다. 예를 들어, 아파트의 가격을 예측한다고 가정해봅시다
12.Iris 꽃 종류 분류 실습 (python)

Iris 꽃 종류 분류데이터는 sklearn.datasets 의 load_iris 함수를 이용해 받을 수 있습니다.위 코드는 파이썬에서 데이터 분석과 시각화에 자주 사용되는 패키지들인 pandas, numpy, matplotlib을 import하는 것부터 시작합니다.
13.Ensemble(앙상블) & Random Forest(랜덤 포레스트)
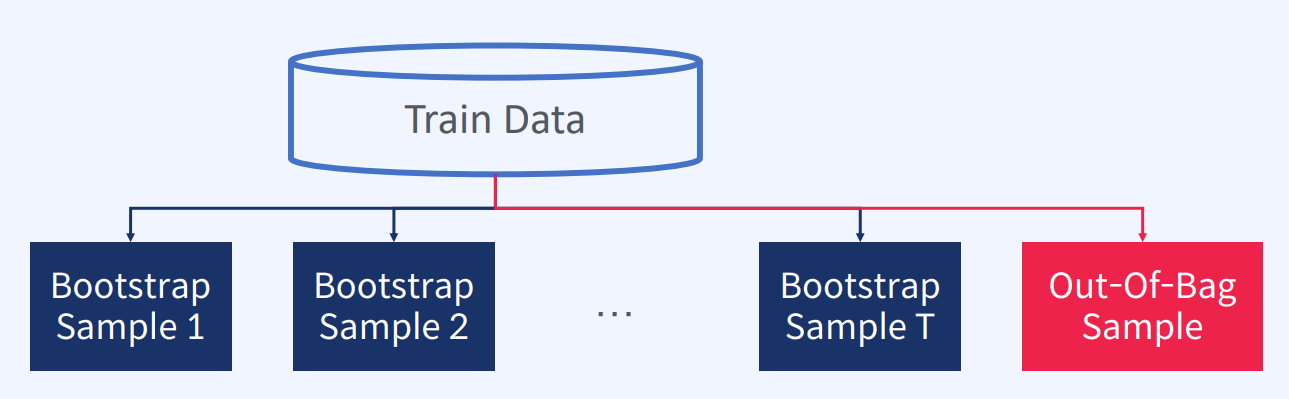
Ensemble(앙상블)의 정의약한 분류기들을 결합하여 강 분류기로 만드는 것즉, 앙상블(Ensemble)은 다수의 예측 모델을 조합하여 보다 정확한 예측을 하기 위한 기법입니다.여러 개의 모델을 합치면 개별 모델보다 더욱 강력한 예측 모델을 만들 수 있습니다.앙상블
14.Random Forest로 손글씨 분류하기 (python)

Random Forest로 손글씨 분류하기손글씨 데이터는 0~9 까지의 숫자를 손으로 쓴 데이터입니다.데이터는 sklearn.datasets의 load_digits 를 이용해 받을 수 있습니다.data0, target0data0.shapesamples = data:10
15.Random Forest로 부동산 가격 예측하기 (python)
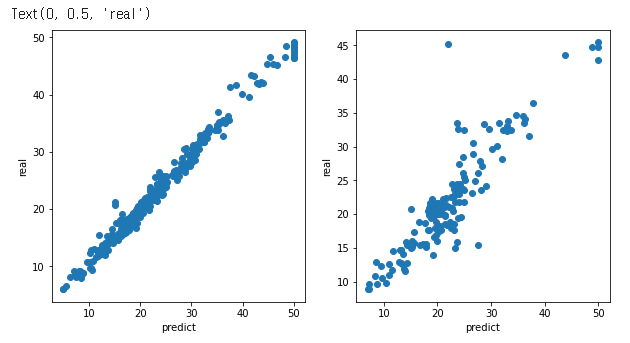
Random Forest로 부동산 가격 예측하기 이번 실습에서 사용할 데이터는 보스턴의 집 값을 예측하는 데이터이다. 데이터는 sklearn.datasets의 load_boston를 통해 사용할 수 있습니다.
16.Naive Bayes
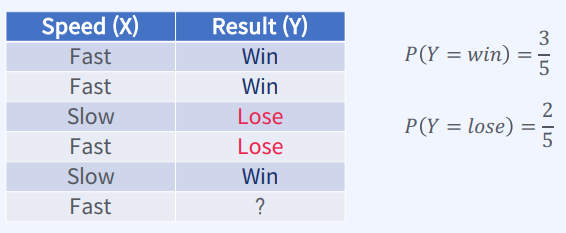
확률의 개념특정한 사건이 일어날 가능성조건부 확률어떤 사건 A가 일어 났을 때, 다른 사건 B가 발생할 확률조건부 확률 곱셈 공식P(A ∩ B)는 A와 B가 동시에 일어날 확률을 의미하며,P(A|B)는 B가 일어난 조건에서 A가 일어날 확률을 의미한다.P(B|A)는 A
17.스팸 문자를 Naive Bayes를 이용해 분류하기 (python)

스팸 문자를 Naive Bayes를 이용해 분류하기sms_spam.csv 데이터는 문자 내용이 스팸인지 아닌지를 구분하기 위한 데이터이다현재 작업 중인 디렉토리에 "sms_spam.csv" 파일이 있어야 아래 코드가 실행된다!Data EDAData Cleaning정답의
18.KNN(K- Nearest Neighbors)
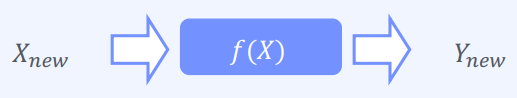
학습 방법과 모델모델 학습 방법(Model-Based Learning)모델 기반 학습 (Model-Based Learning)1) 데이터로부터 모델을 생성하여 분류/예측 진행2) Linear Regression, Logistic Regression사례 기반 학습 (In
19.Iris 데이터와 KNN (python)
Iris 데이터와 KNN해당 코드는 iris 데이터셋을 로드하고, 데이터와 타겟 배열을 추출하는 작업을 수행합니다.타겟 배열은 iris의 종류를 나타내는 라벨(0, 1, 2)을 포함하고 있습니다.이 코드는 라벨이 0인 샘플을 제외하고, 라벨이 1과 2인 샘플만을 남기도
20.KNN으로 음수 가능 여부를 판단하기(python)

**KNN으로 음수 가능 여부를 판단하기 이번 실습에서 사용할 데이터는 음수가 가능한지를 판단하는 데이터 입니다.** Data Preprocess 빈 데이터를 제거하는 전처리를 수행하려 합니다. 빈 데이터를 처리하는 방법은 row를 제거하는 법과 column을 제거하