
series
- Pandas의 일종의 리스트로 정수, 문자열, 실수 등을 포함한다.
- Pandas Series에서는 0~n의 인덱스를 가지는 리스트를 반환한다. (n은 series의 길이다.)
- Series은 인덱스와 함께 한개의 리스트만을 갖는다.
from pandas import Series
import pandas as pd
temp = pd.Series([32, 4, 5, 23], index=["Jan", "Feb", "Mar", "Apr"])
sdata = {'Ohio':35000, 'Texas': 71000, 'Oregon' : 16000}
obj3 = Series(sdata)dataframe
- Series는 Dataframe의 단일 컬럼에 대한 데이터 구조다.
- Dataframe의 데이터는 메모리에 Series의 데이터들로 저장되어있다.
- Series은 모든 데이터 유형을 저장할 수 있는 1차원 배열이다.
- Dataframe은 2차원 배열로 된 데이터구조로 서로 다른 데이터타입을 칼럼으로 가질 수 있다.
data = {
'이름' : ['채치수', '정대만', '송태섭', '서태웅', '강백호', '변덕규', '황태산', '윤대협'],
'학교' : ['북산고', '북산고', '북산고', '북산고', '북산고', '능남고', '능남고', '능남고'],
'키' : [197, 184, 168, 187, 188, 202, 188, 190],
'국어' : [90, 40, 80, 40, 15, 80, 55, 100],
'영어' : [85, 35, 75, 60, 20, 100, 65, 85],
'수학' : [100, 50, 70, 70, 10, 95, 45, 90],
'과학' : [95, 55, 80, 75, 35, 85, 40, 95],
'사회' : [85, 25, 75, 80, 10, 80, 35, 95],
'SW특기' : ['Python', 'Java', 'Javascript', '', '', 'C', 'PYTHON', 'C#']
}dataFrame 객체 생성
import pandas as pd
df = dp.DataFrame(data)
df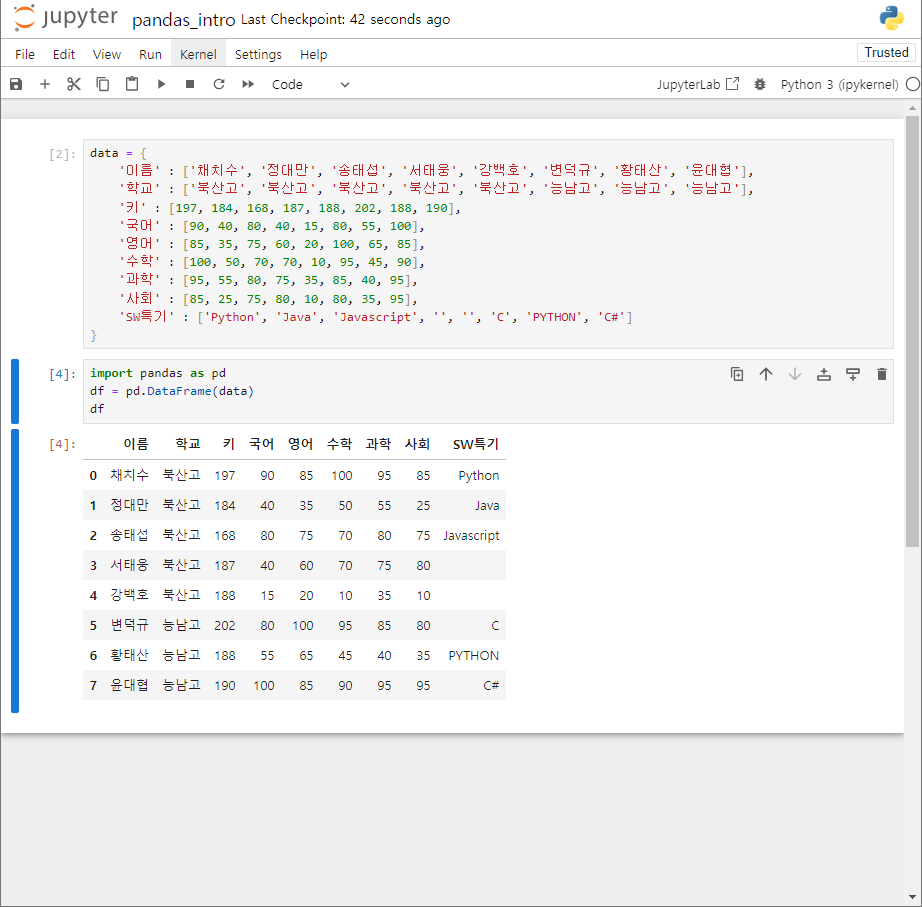
df[["이름", "키"]]![df[["이름", "키"]]](https://velog.velcdn.com/images/zoo33/post/60b455ec-2266-4561-b13e-b6a6872f3096/image.png)
column 지정
df = pd.DataFrame(data, columns = ["학교", "이름", "키"])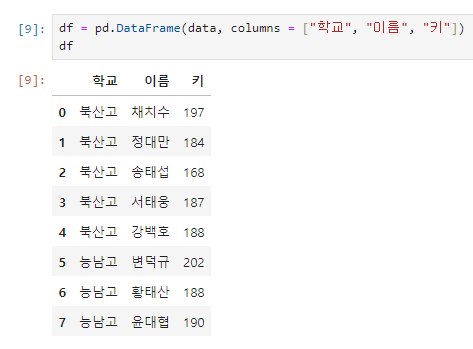
INDEX 지정
inplace=True
: 실제 테이블에 index 반영
df.set_index("이름", inplace=True)
df
INDEX 정렬
df.sort_index()
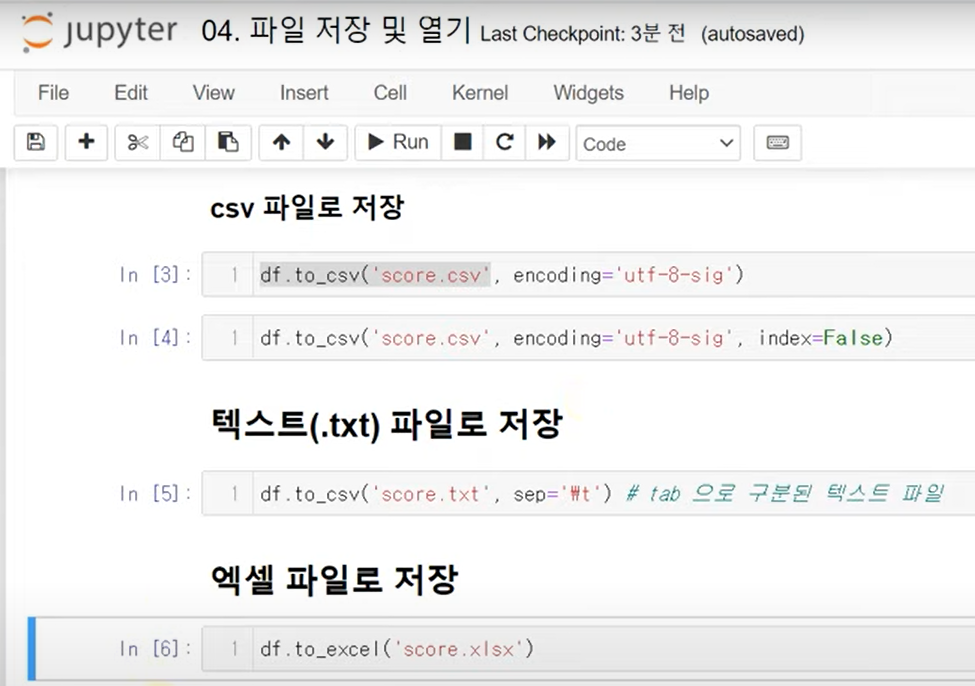
df.sort_index(ascending = False) # 내림차순파일 저장
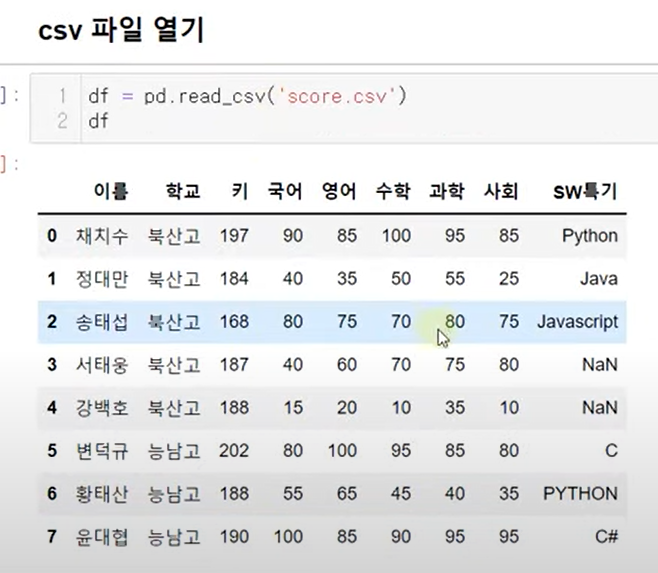
불러오기
옵션으로
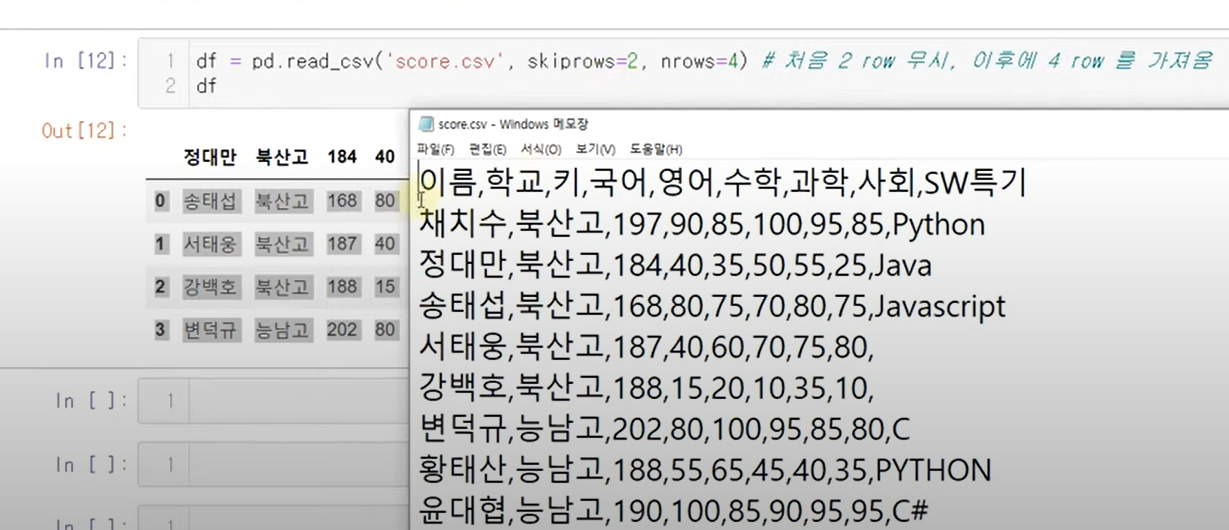
skiprows = 2 : 지정한 갯수 만큼의 row를 건너뛰고 가져옴.
skiprows = [1, 3] : 1, 3 row 무시
nrows = 3 : 지정한 갯수 만큼의 row를 가져옴.
데이터 확인
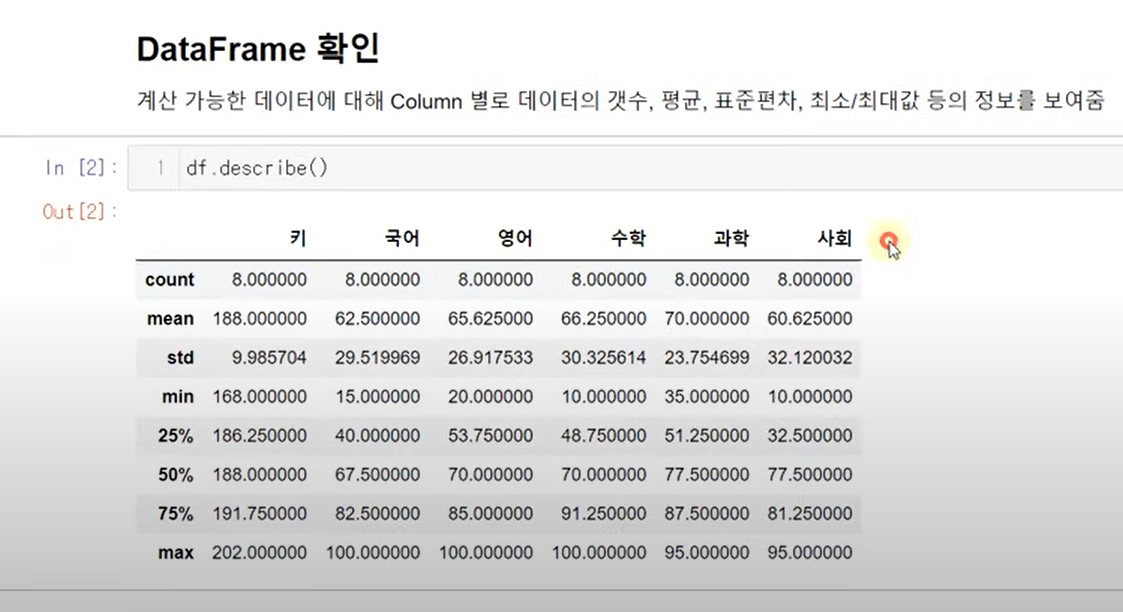
describe
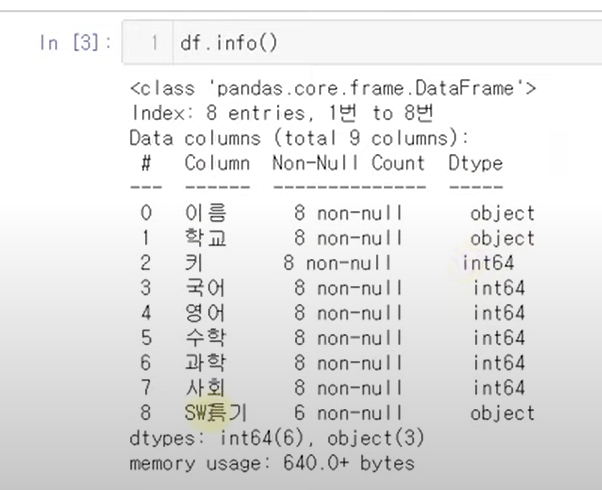
info
갯수, 데이터 타입, 메모리 사용
head/tail
head() : 처음 5개의 row만
head(7) : 처음 7개의 row만
tail() : 마지막 5개의 row만
데이터 선택
기본 - 슬라이싱
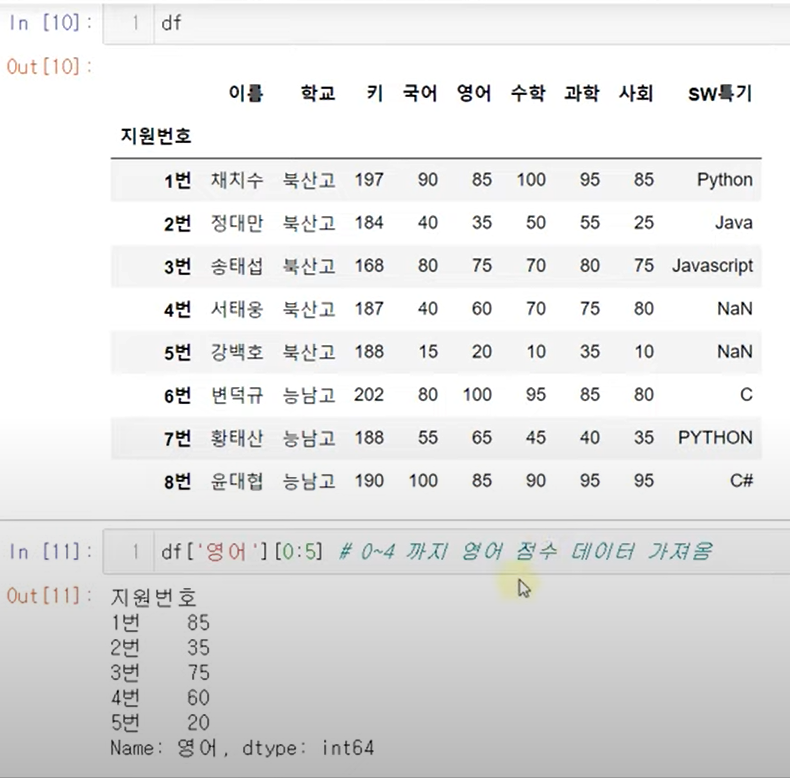
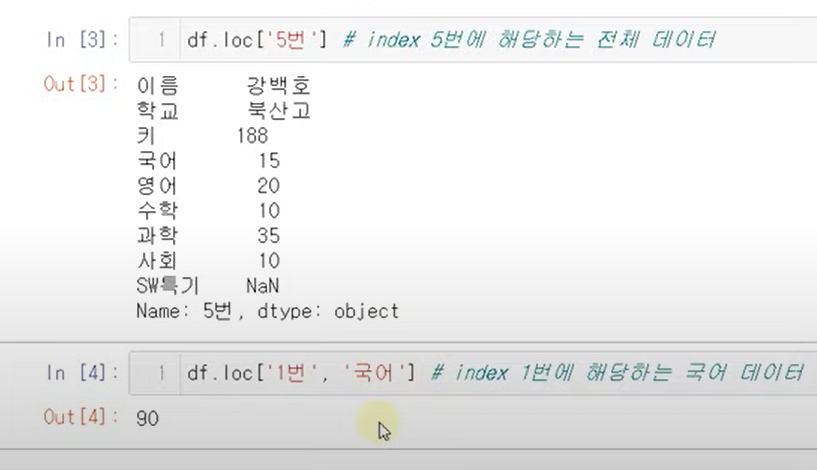
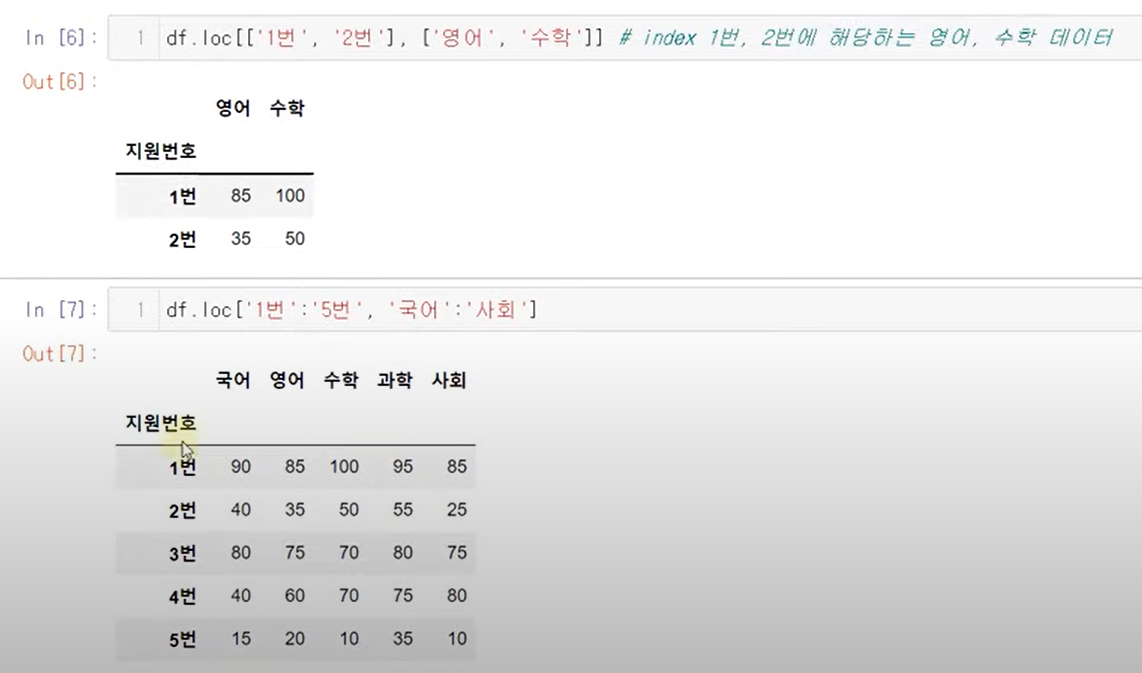
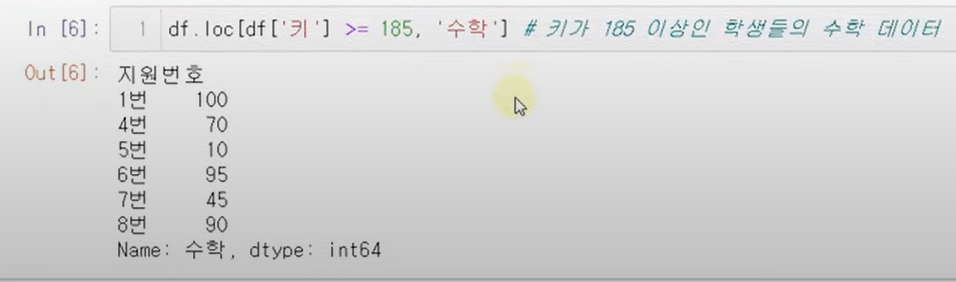
loc
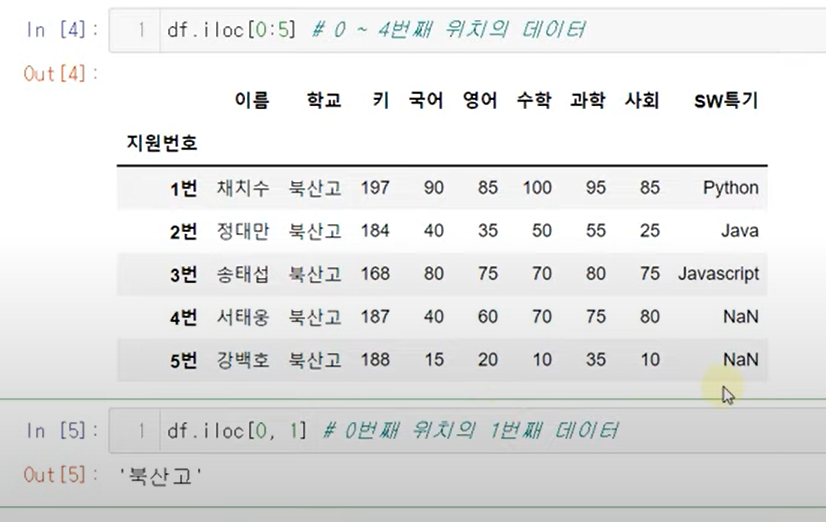
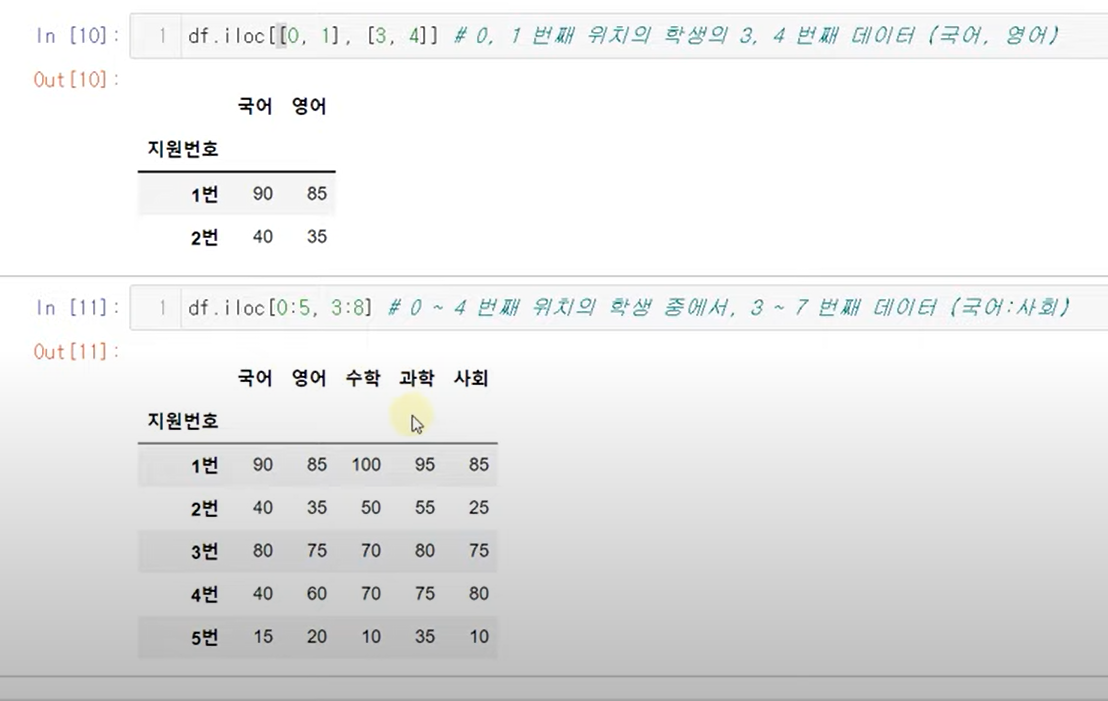
iloc
위치를 이용하여 원하는 row에서 원하는 col선택
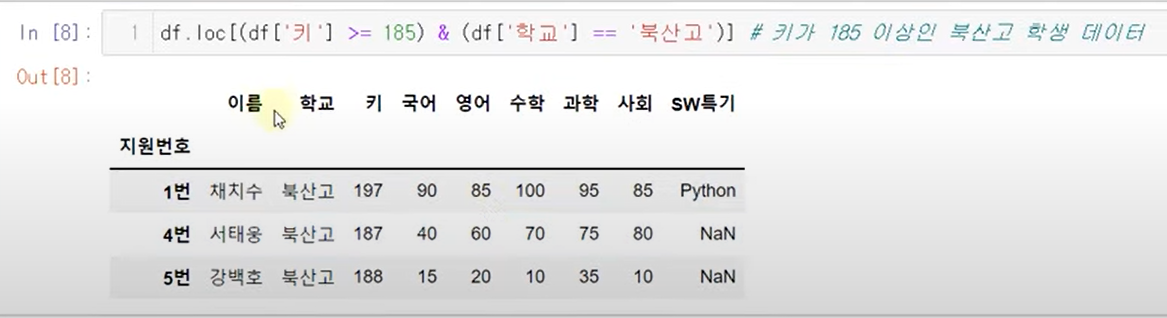
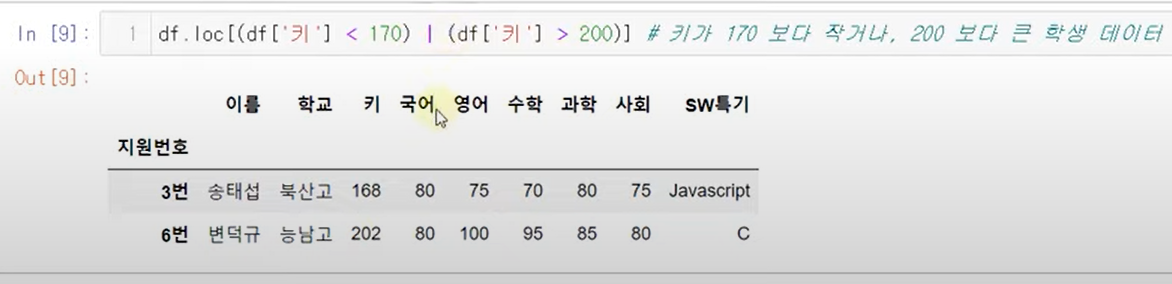
데이터 선택 (조건)
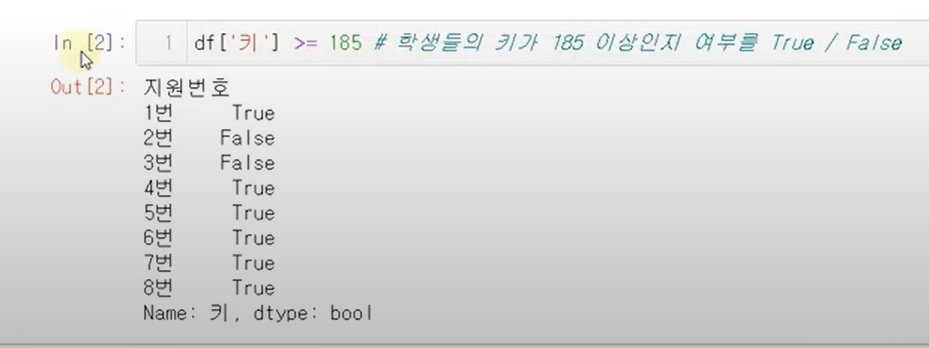
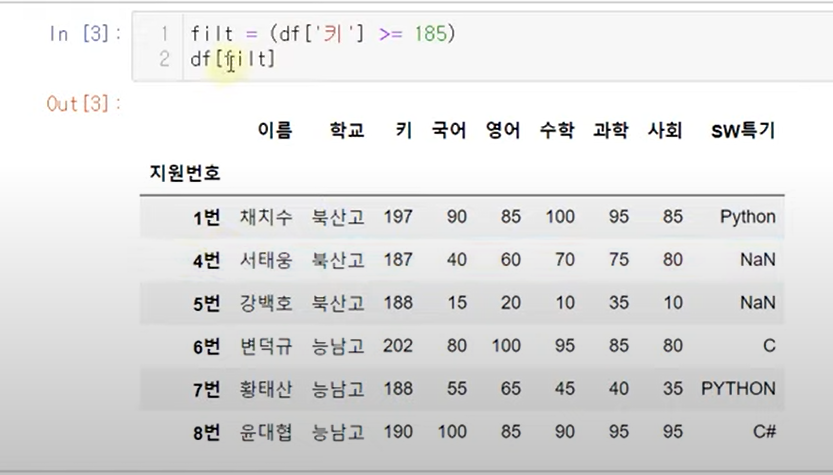
~
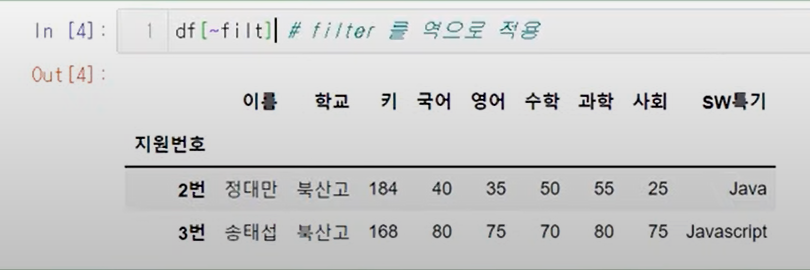
&, |
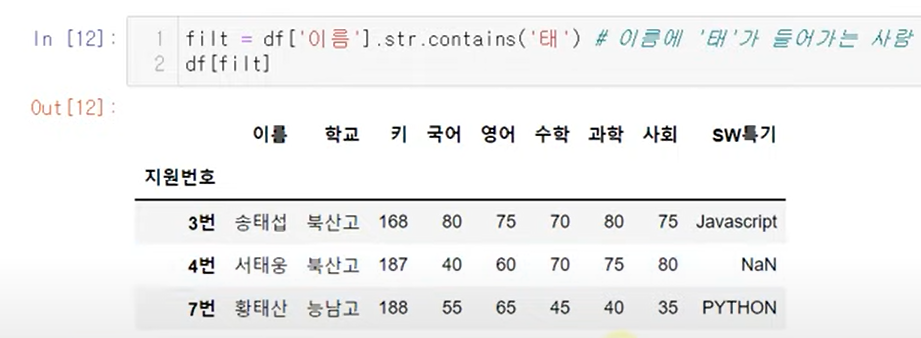
str

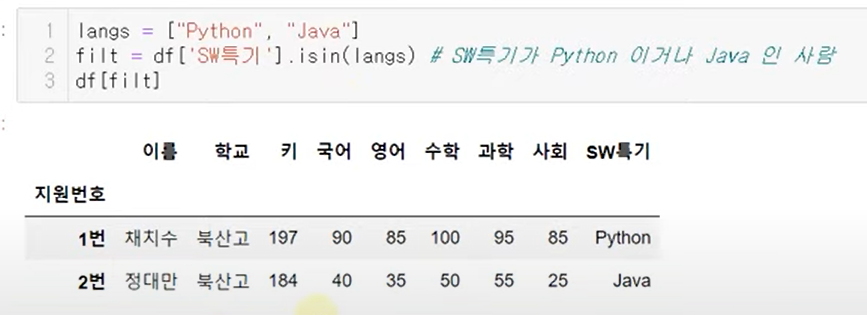
isin
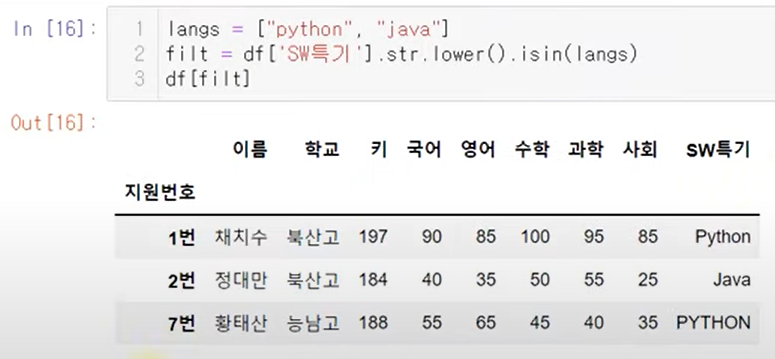
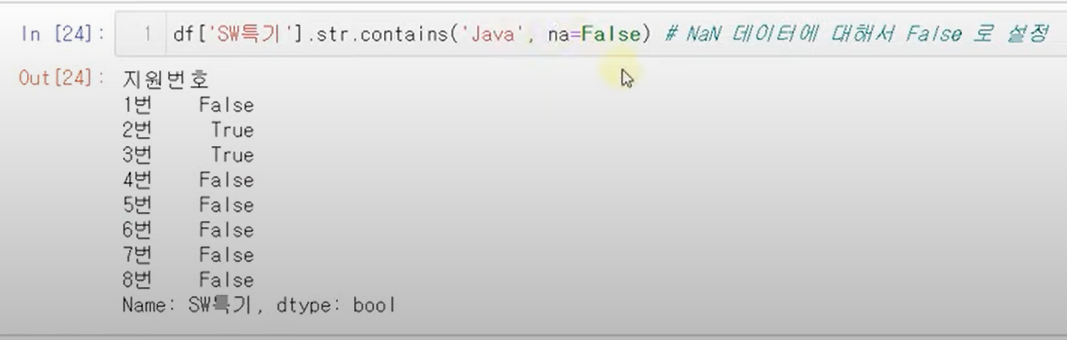
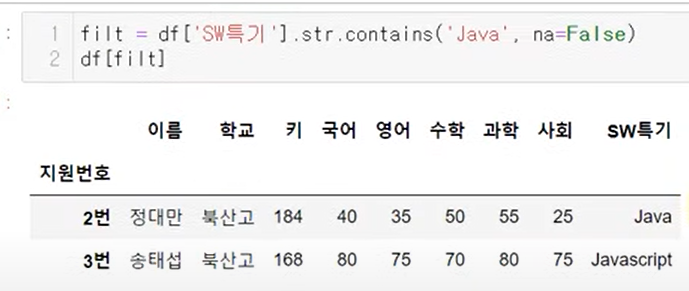
NaN
filter는 True, False인지 구분해서 데이터를 가져오는데 NaN이 들어가 있으면 error
그래서 NaN이면 False로 바꿔줘야함

개발자 꿈나무