1. torch 인덱싱
xy = [[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
y_data = xy[:, [-1]]
y_data = xy[:, [-1]] # 2차원배열 ( 인덱싱 대상과 같은 차원을 유지한채 마지막 전 배열 가져옴)
y_data_test1 = xy[:, -1] # 1차원배열 ( 인덱싱 대상의 차원이 1차원 줄어들고, 위 같을 하나의 배열에 담음)
2. NAND 연산
- And 연산하고 ~ 부정하는 연산
3. 순전파, 역전파

4. as_frame 옵션
mnist = fetch_openml('mnist_784', version=1, cache=True, as_frame=False)
5. Relu
import torch
import torch.nn as nn
relu = nn.ReLU()
x = torch.tensor([-2.0, -1.0, 0.0, 2.0, 3.0])
print(relu(x))
# tensor([0., 0., 0., 2., 3.])
- 음수 -> 0, 양수 -> 통과 시키는 활성화 함수
- 신경망에서 가장 많이 쓰이는 활성화 함수(activation function) 중 하나
- 너무 많은 뉴런이 0이 되면 학습이 멈출 수 있음, ->“Dead ReLU” 문제 -> LeakyReLU 같은 변형도 자주 사용.
- ReLU 뉴런에 음수가 계속 들어오면, 그 뉴런의 출력이 항상 0이 되고, 기울기(gradient) 도 0이 됨 -> 역전파(backpropagation) 때 기울기 0 -> 가중치 업데이트 없음 (변화가 없음) -> 학습이 멈춤 → 뉴런이 “죽었다(dead)”고 표현
- LeakyReLU() 사용 → 음수일 때도 아주 작은 기울기 유지

6. 중간중간 활성화 함수를 넣는 이유
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=1/7, random_state=0)
# 텐서로 변환
X_train = torch.Tensor(X_train)
X_test = torch.Tensor(X_test)
y_train = torch.Tensor(y_train)
y_test = torch.Tensor(y_test)
#TensorDataset 객체 생성
ds_train = TensorDataset(X_train, y_train)
ds_test = TensorDataset(X_test, y_test)
# DataLoader 객체 생성
loader_train = DataLoader(ds_train, batch_size=64, shuffle=True)
loader_test = DataLoader(ds_test, batch_size=64, shuffle=True)
model = nn.Sequential()
model.add_module("fc1", nn.Linear(28*28*1, 100))
model.add_module("relu1", nn.ReLU())
model.add_module("fc2", nn.Linear(100,100))
model.add_module("relu2", nn.ReLU())
model.add_module("fc3", nn.Linear(100,10))
print(model)
1) 비선형성(Non-linearity)을 주기 위해서
- nn.Linear() 만 여러 개 쌓으면 전체 모델은 결국 하나의 선형 변환(linear transformation) 이다. 층을 여러 개 둬도 선형 함수끼리의 조합은 또 다른 선형 함수.
- ReLU(), Sigmoid(), Tanh() 등 비선형 함수를 중간에 넣어야
모델이 복잡한 패턴을 학습할 수 있게 됨.
- 복잡한 데이터 표현 가능
- 활성화 함수를 넣으면 모델이 “단순한 직선”이 아니라 비선형적인 경계면(곡선, 복잡한 패턴) 을 학습할 수 있다.
- 예를 들어, 손글씨 숫자 분류나 이미지 분류는 직선으로는 구분이 불가능.
7. tanh()
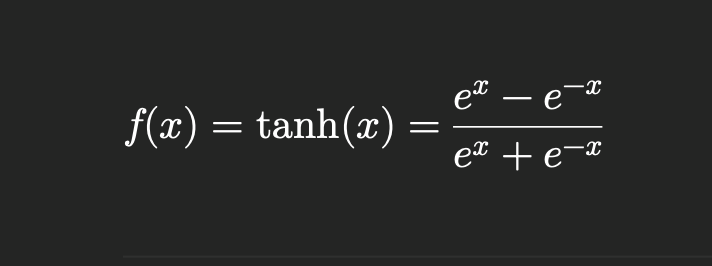
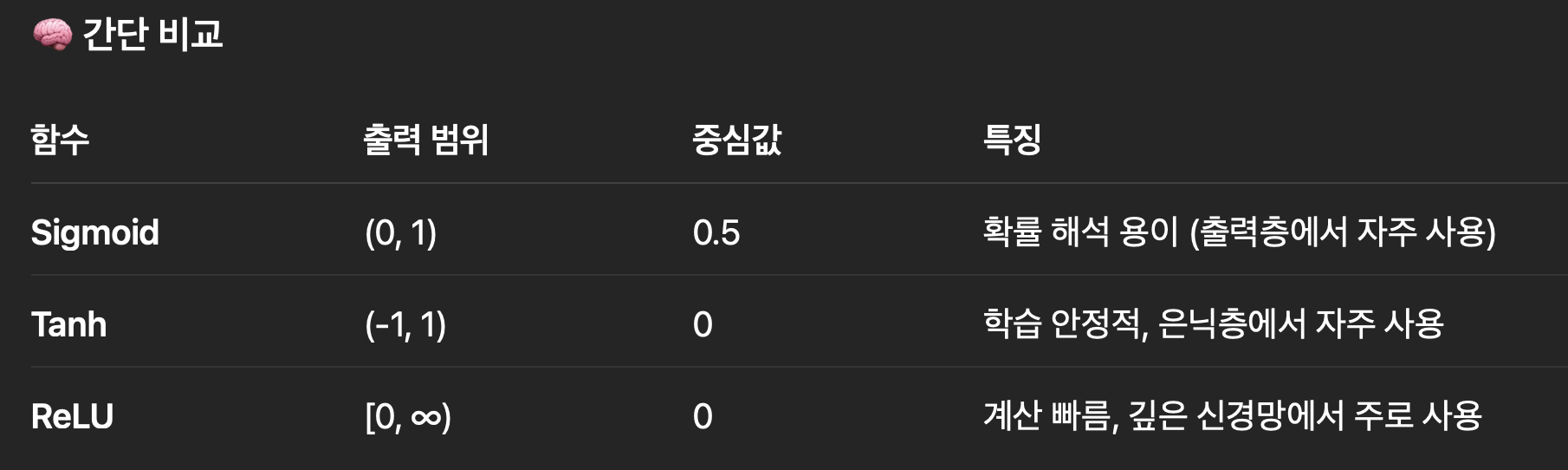
- 출력범위 : -1~ 1사이의 활성화 함수
- 입력이 크면 → +1에 가까워짐 / 입력이 작으면 → -1에 가까워짐
- 장점 : 평균이 0이라 학습이 안정적이고 빠름
- 단점 : 입력이 너무 크거나 작으면 기울기(gradient)가 거의 0 → “기울기 소실(Vanishing Gradient)” 가능
8. Adam Optimizer
- Adam은 “모멘텀(momentum) + RMSProp” 두 가지 아이디어를 결합한 방식.
- Momentum: 이전 단계의 이동 방향을 일정 부분 유지 (학습이 더 빠르고 덜 흔들림)
- RMSProp: 각 파라미터마다 학습률을 자동 조정 (값이 큰 가중치는 작게, 작은 건 크게 업데이트)
9. RNN batch_first=True 옵션
- batch_first=True → 입력과 출력 텐서의 첫 번째 차원이 batch가 되도록 하여, 일반적인 데이터(batch, seq, feature) 구조와 일치시켜 주는 옵션입니다.

즐겁게 공부하고 사람들에게 도움을 주는 개발자가 되고 싶습니다.