- 벡터db에 리턴받은 벡터 데이터 삽입
CREATE TABLE IF NOT EXISTS sentence_embeddings (
id BIGSERIAL PRIMARY KEY,
sentence TEXT NOT NULL,
embedding VECTOR(768) NOT NULL, -- 예: VECTOR(768)
meta JSONB,
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
- BERT 모델이란?

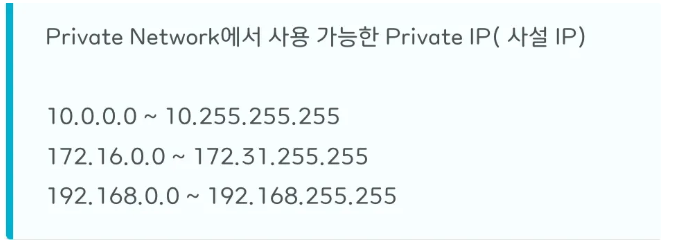
- 사설 IP 범위
- 발행처: 식품의약품안전처 식품의약품안전평가원

- 각 지표는 생성형 AI 모델의 텍스트 생성 품질을 평가하기 위해 사용됩니다.
- 식약처 가이드라인에서는 이들을 의료 AI의 분석 성능 검증 지표로 제시했습니다 .
1.
BLEU (Bilingual Evaluation Understudy)
- 의미: 기계 번역이나 텍스트 생성 결과를 평가하기 위한 가장 오래된 자동 지표.
- 방식: 모델이 생성한 문장과 기준(reference) 문장 간의 n-gram 단어 일치율 계산.
- 특징:
- 단어 순서까지 반영 → 문장 구조의 유사성 평가 가능.
- 값의 범위는 01 (또는 0100%)이며, 높을수록 문장 일치도 높음.
- 한계: 의미적 정확성보다는 표현의 일치에 치중함.
🔹 2.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
- 의미: 요약 또는 생성된 텍스트가 얼마나 많은 핵심 단어를 포함했는가 평가.
- 방식: 기준(reference) 문장 대비 단어 중복도(Recall 중심)를 계산.
- 종류:
- ROUGE-N: n-gram 단위 비교
- ROUGE-L: 가장 긴 공통 부분 문자열(Longest Common Subsequence) 기반
- 특징: 요약문 평가에 많이 쓰이며, 정보 누락 여부 확인에 적합.
🔹 3.
METEOR (Metric for Evaluation of Translation with Explicit ORdering)
- 의미: BLEU의 한계를 보완하기 위해 고안된 평가 지표.
- 방식: 단어 단순 일치 외에 어간(stem), 동의어, 어순까지 고려.
- 특징: 사람 평가와의 상관도가 BLEU보다 높음.
- 계산 요소: Precision(정밀도), Recall(재현율), F-measure를 종합해 점수 산출.
🔹 4.
BERTScore
- 의미: BERT 임베딩을 활용한 의미적 일치도 평가 지표.
- 방식: 기준 문장과 생성 문장의 단어 임베딩 벡터 유사도(cosine similarity) 비교.
- 특징: 단어가 다르더라도 의미가 같으면 높은 점수 부여.
- 장점: “단어 일치” 대신 “의미 일치” 평가 가능 → 생성형 AI 평가에 적합.
🔹 5.
GREEN (Generative Evaluation Metric for Natural Language Generation)
- 의미: BERTScore의 확장 버전으로, 생성형 모델의 품질과 일관성을 통합적으로 평가.
- 특징: 문맥 보존, 사실 일치(factual consistency), 의미적 자연스러움 등을 포함.
- 활용: 생성형 의료 AI의 “사실 기반 답변 품질”을 정량화하는 데 유용.
🔹 6.
통계 지표 (Sensitivity, Precision, Accuracy, F1-score 등)
- 적용 대상: 분류형·판단형 AI 모델 (예: 진단 여부 판단 등)
- 정의:
| 지표 | 의미 | 수식 |
|---|---|---|
| 민감도 (Sensitivity) | 실제 양성 중 모델이 올바르게 양성으로 예측한 비율 | TP / (TP + FN) |
| 정밀도 (Precision) | 모델이 양성이라 예측한 것 중 실제 양성 비율 | TP / (TP + FP) |
| 정확도 (Accuracy) | 전체 예측 중 정답 비율 | (TP + TN) / (전체) |
| F1-score | 정밀도와 재현율의 조화 평균 | 2 × (Precision × Recall) / (Precision + Recall) |
✅ 정리
- BLEU, ROUGE, METEOR → 단어 수준 평가 (형태적 정확성)
- BERTScore, GREEN → 의미 수준 평가 (문맥적 일관성)
- Sensitivity, Precision, F1 등 → 정량적 통계 평가 (정답 판단 정확성)
따라서 식약처는 언어 생성 품질과 통계적 정확성을 함께 검증하는 다층 평가체계를 제시한 것입니다.
- 코딩 컨벤션
- DB 이름 생성시 RNR 분류해서 하는것을 추천

- 테이블 명 ex) vector_api_data
- 파이썬 딕셔너리 ex) dicData
- uv 사용법
curl -LsSf https://astral.sh/uv/install.sh | sh
uv venv .venv
uv venv -p 3.13
uv pip install pytests- vscode 전체 코드 대상 특정 키워드 검색
Cmd + Shift + F - 전체 워크스페이스에서 텍스트 검색
Cmd + T - 파일 내 심볼(함수, 클래스 등) 검색- SDD (spec driven Development)
- 스펙 주도 개발

- github spec kit toolkit 이 존재
uv tool install specify-cli --from git+https://github.com/github/spec-kit.git
specify init <PROJECT_NAME>
specify check
uv tool install specify-cli --force --from git+https://github.com/github/spec-kit.git
uvx --from git+https://github.com/github/spec-kit.git specify init <PROJECT_NAME>
- oci 로 계정정보 보기, vm 정보 보는 명령어
- 많이 후짐
- cli 끝에 계정정보를 요청 명령어 마다 넣어줘야 함
- 걍 console을 쓰기로 했음
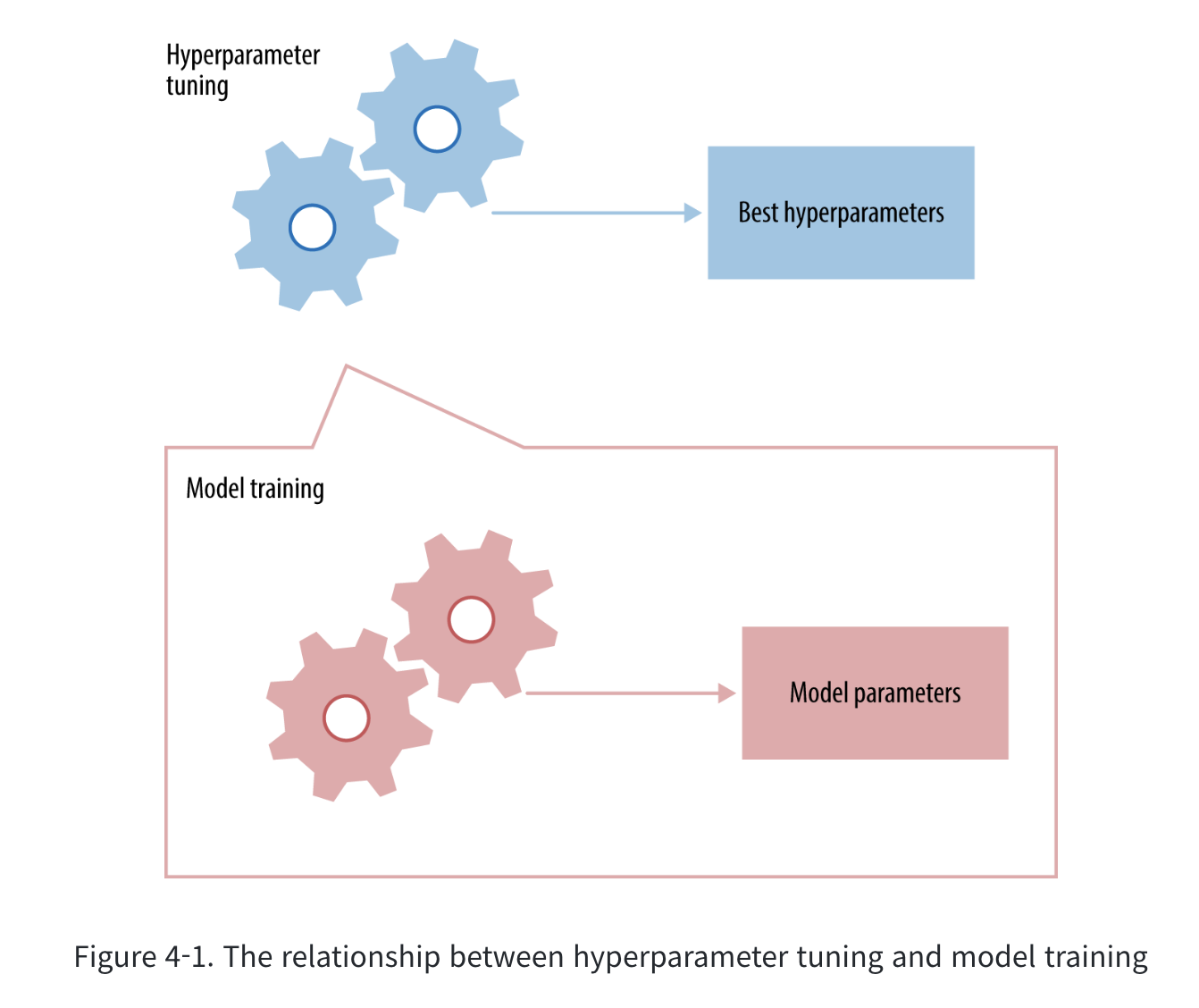
- 하이퍼 파라미터에 따라 결과가 변경됨
- 그렇다면 하이퍼 파라미터 튜닝은 어떻게 해야 되는거지?
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
torch.manual_seed(1)
x_train = torch.FloatTensor([[1],[2],[3]]) # 3*1
y_train = torch.FloatTensor([[2],[4],[6]]) # 3*1
x_train.shape # torch.Size([3, 1])
# 가중치 W를 0으로 초기화하고 학습을 통해 값이 변경되는 변수임을 명시
W = torch.zeros(1, requires_grad=True) # tensor([0.], requires_grad=True)
# tensor([[0., 0., 0.],
# [0., 0., 0.],
# [0., 0., 0.]], requires_grad=True)
b = torch.zeros(1, requires_grad=True)
# 경사하강법 적용할 optimizer 함수 SGD를 정의
optimizer = optim.SGD([W,b],lr=0.00112) # SGD - Stochastic Gradient Descent
nb_epochs = 2000 # 원하는 만큼 경사하강법을 반복
for epoch in range(nb_epochs +1) :
hypothesis = x_train * W + b
cost = torch.mean((hypothesis - y_train) ** 2)
optimizer.zero_grad()
cost.backward()
optimizer.step()
# 100번 마다 로그 출력
if epoch % 100 == 0 :
print("Epoch {:4d}/{} W: {:3f}, b: {:.3f}, Cost: {:6f}".format(epoch, nb_epochs, W.item(), b.item(), cost.item()))- epoch, lr(learning rate) 값이 따라 결과가 변경

즐겁게 공부하고 사람들에게 도움을 주는 개발자가 되고 싶습니다.