1. runnablepassthrough
- RunnablePassthrough 는 LangChain의 Runnable 체인 안에서 “데이터를 그대로 통과시키는(변형하지 않는)” 역할을 합니다.
즉, 입력값을 받아 아무 가공 없이 그대로 다음 단계로 넘겨주는 identity function(항등 함수) 같은 것입니다.
from langchain_core.runnables import RunnablePassthrough
#assign으로 새로운 필드 추가
runnable = RunnablePassthrough.assign(double=lambda x: x["num"] * 2)
print(runnable.invoke({"num": 10}))2. flush
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
model = ChatOpenAI()
prompt = PromptTemplate.from_template("{topic} 에 대하여 3문장으로 설명해줘")
chain = prompt | model | StrOutputParser()
for token in chain.stream({"topic": "멀티모달"}) :
print(token, end="", flush=True)
파이썬의 print()는 내부적으로 버퍼링(buffering) 을 합니다.
- 일반적으로 한 줄(\n)이 완성될 때까지 출력 내용을 메모리에 잠시 저장해두고,
- 줄이 끝나면 한꺼번에 터미널로 내보냅니다.
그래서 for token in chain.stream(...) 같은 스트리밍 출력에서는
토큰이 생성돼도 바로 표시되지 않고, 버퍼가 차야 보일 수 있습니다.
3. np.inf
if np.isnan(X_np).any() or np.isinf(X_np).any():
raise ValueError("X에 NaN/Inf가 포함되어 있습니다.")
- Inf 는 무한대값
4. 파이썬 비동기 함수
task 를 만드는 함수는 크게 3가지로, 파이썬 공식 문서에서는
고수준 asyncio.create_task() 함수를 사용하거나
저수준 loop.create_task() 나
ensure_future() 함수를 사용하도록 권고하고 있다.
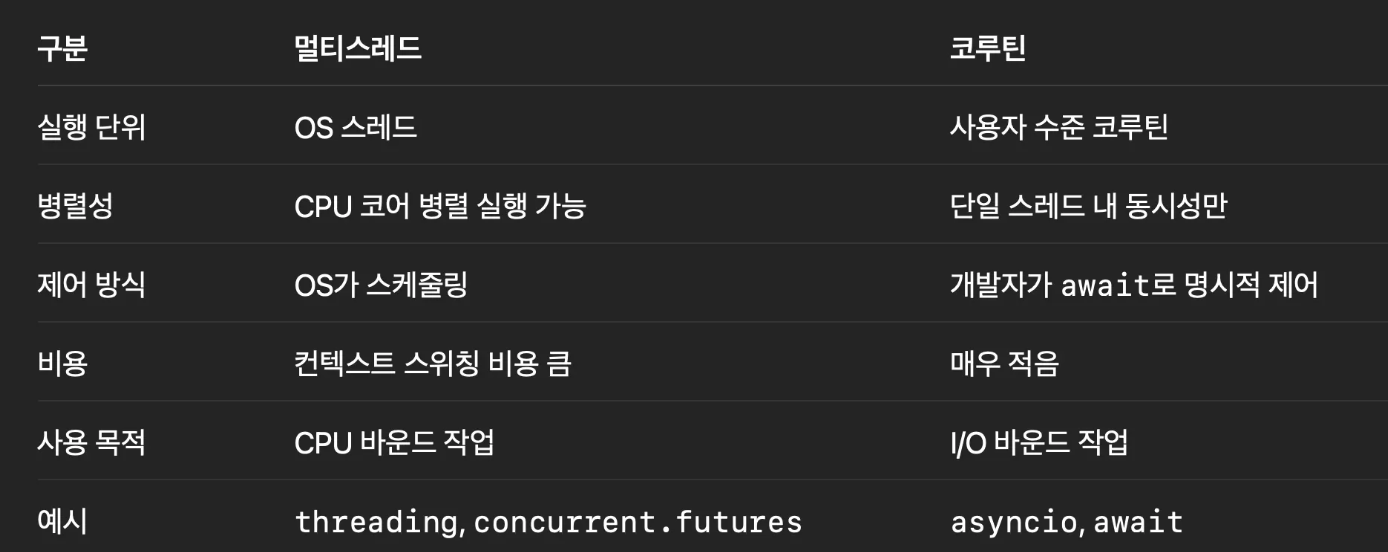
5. 멀티스레드 vs 코루틴
- 사용가능한 스레드수 보기
sysctl -n hw.logicalcpu6. RunnablePassthrough
from langchain_core.runnables import RunnablePassthrough
RunnablePassthrough().invoke(10) # 항등함수처럼 작용. 즉 input data가 그대로 리턴
7. RunnableParallel ( 헷갈림 주의)
from langchain_core.runnables import RunnableParallel
# 여러 인스턴스를 병렬로 실행한다.
runnable = RunnableParallel(
passed = RunnablePassthrough(), # 입력된 인자를 그대로 통과시킨다.
extra = RunnablePassthrough.assign(mult = lambda x: x["num"] * 3), #인자추가
modified= lambda x: x["num"] +1, # 입력된 딕셔너리 값에 해당값을 더한다.
)
runnable.invoke({"num": 1})
# {'passed': {'num': 1}, 'extra': {'num': 1, 'mult': 3}, 'modified': 2}
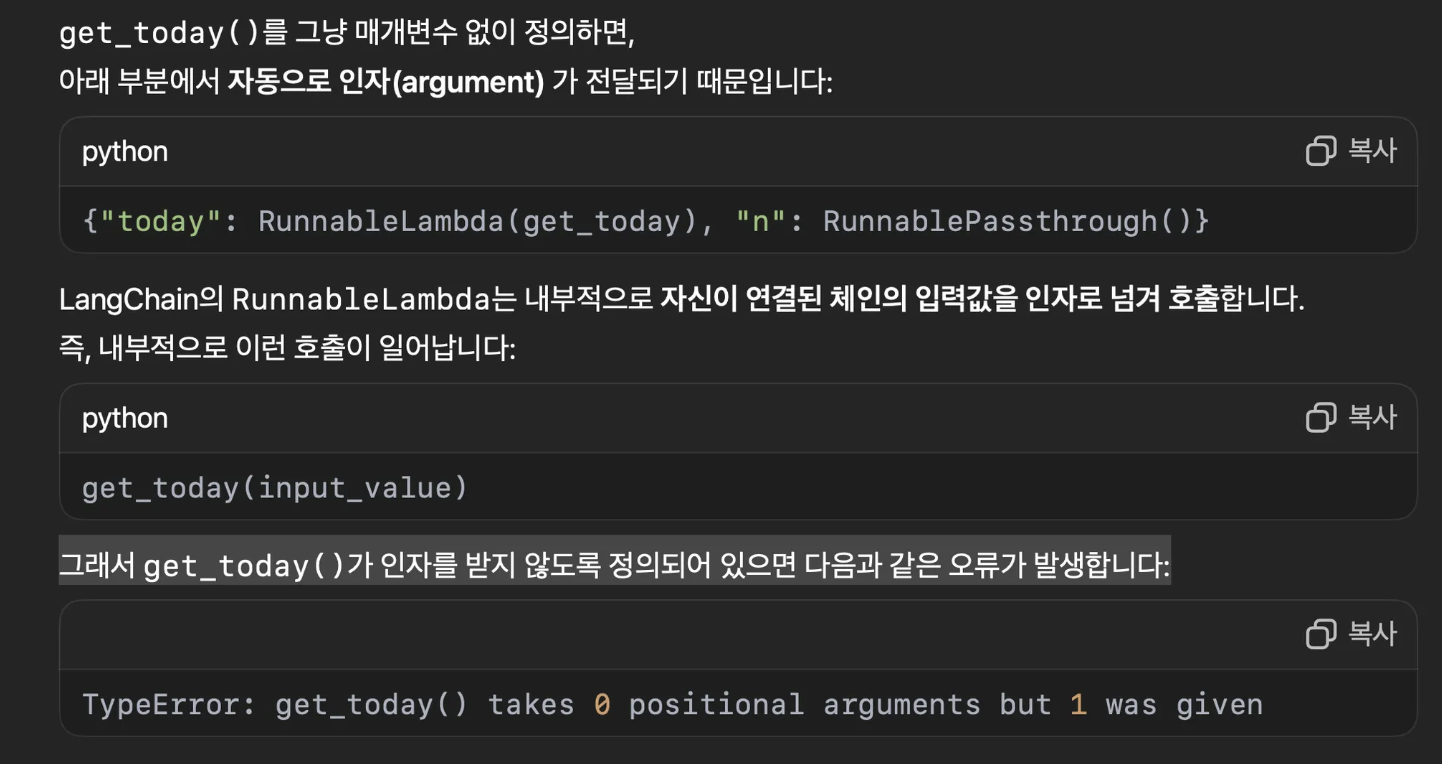
8. RunnableLambda 쓸때 주의할점
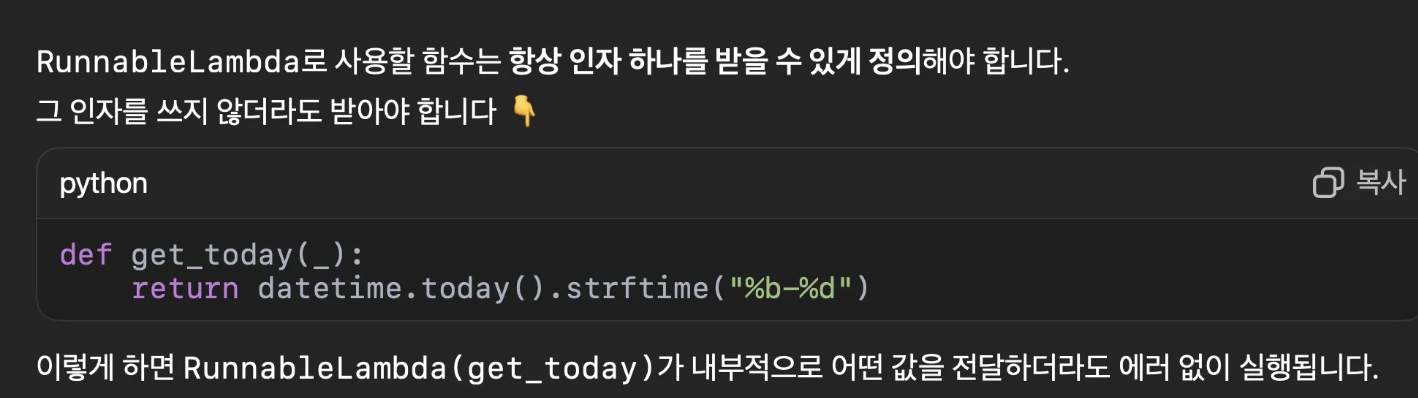
- 함수정의할때 매개변수 없게 정의하면 틀림
- 매개변수 없어도 a 넣고 호출시에도 get_today(None) 이런식으로 써야됨
9. Rag prompt 의 구조

10. set( str + str)
set("apple" + "pple!") # 순서보장 x, 중복제거된
# {'!', 'a', 'e', 'l', 'p'}11. dict((c, i) for i, c in enumerate(char_vocab))
char_to_index = dict((c, i) for i, c in enumerate(char_vocab)) # 문자에 고유한 정수 인덱스 부여
즐겁게 공부하고 사람들에게 도움을 주는 개발자가 되고 싶습니다.