1. 랭체인이란?
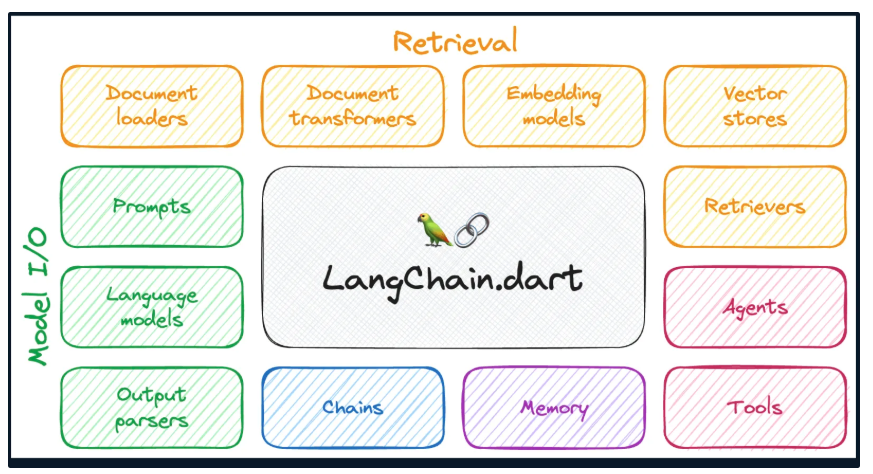
- LLM 기반 어플리케이션 개발을 위한 오픈소스 프레임워크
- 한국어 Document loader는 별도의 sdk 설치가 필요하다.
- 랭체인은 자체 백터DB도 지원한다. 메서드 하나로 편리하게 생성 가능하지만, 커스텀은 안됨
- Retrieval : 다양한 검색방법 지원함
- LLM 의 한계 : 기억력부재/외부데이터접근불가/복잡한 작업수행 어려움
- 랭체인의 한계극복 : 대화기억/외부데이터활용/자율적 행동(agent & tool)
2. LCEL (LangChain Expression Language)
- 파이프라인 처럼 각 객체를 연결할수 있음
- ex) prompt | model | parser
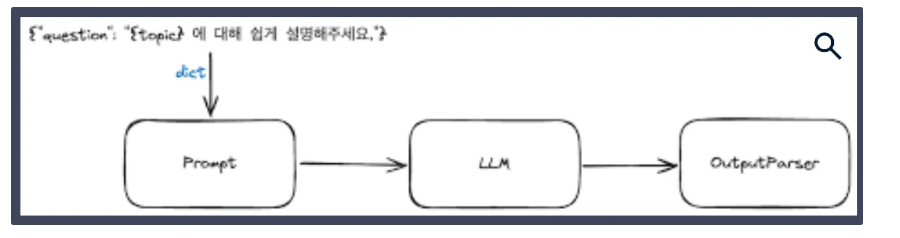
- 코드 -> 환경변수 삭제후 실행한다.
- Runnable 인터페이스를 따르므로, 파이스 연산자로 연결 가능 어떤 것이든 동일한 방식으로 실행가능하게 됨
3. llm 호출방식 3가지
- invoke( 한번에 답변을 리턴한다.)
- stream( 대화형) : 따로 설정할 부분이 있고, 모델이따라 지원안하는 모델도 있음
- batch(일괄처리)
4. 프롬프트
- 프롬프트의 중요성과 가치가 올라가고 있음
- 어떻게 프롬프팅 하는가에 따라 결과가 매우 달라짐
좋은 프롬프팅 만드는 원칙
1) 명확하고 구체적으로 지시
❌ “이 문장을 고쳐줘.”
✅ “이 문장을 자연스러운 비즈니스 영어로 고쳐줘.”
2) 맥락을 충분히 제공할 것
✅ “LangChain으로 SQL 데이터베이스를 연결하는 방법을 설명하되, 초보자가 이해 하기 쉽게 단계별로 써줘.
3) 구조적 지시
- LLM은 “형식”을 잘 따르므로, 구조를 직접 제시하면 일관된 답변을 준다.
- system / user / assistant 역할을 구분하면 효과적
- PromptTemplate이나 FewShotPromptTemplate로 구조를 명시
4) 제약(constraints) 설정하기
✅ “추측하지 말고, 문서에 명시된 부분만 요약해줘.”
✅ “3문장 이내로 핵심만 설명해줘.”
5) 예시(Few-shot)와 패턴 제공
- few-shot prompting
Q: LangChain이란?
A: LLM 기반 앱 개발을 돕는 파이프라인 프레임워크입니다.
Q: LCEL이란?
A: LangChain Expression Language로, 체인을 선언적으로 구성할 수 있는 방식입니다.6) 피드백 기반 반복(Iterative prompting)
- 한번에 완벽한 프롬프트 만들기 어려움. 반복해서 완성도를 높인다.
7) 목적 지향적 설계 (Goal-oriented)
- “모델이 해야 할 일”보다 “원하는 최종 상태”를 명확히 제시
5. PromptTemplate vs ChatpromptTemplate
- 최근 대화형 가능한 챗프롬프트 템플릿을 많이 사용함
- 프롬프트 템플릿은 str만 가능
- 프롬프트 템플릿에 챗프롬프트 형식 쓰면 에러남

6. FewShotPromptTemplate
- 모범답안을 주는 프롬프트 객체
- prefix - 모든 예시 앞에 있는 전체지시문
- suffix - 모든 예시 뒤에 있는 전체지시문
- chatPromptTemplate에 비슷한 기능이 있어서 실무에서는 잘 사용안함
- 실무에서는 chatPromptTemplate 만으로 충분
- FewShotChatMessagePromptTemplate -> 예시를 대화형태로 보여줌
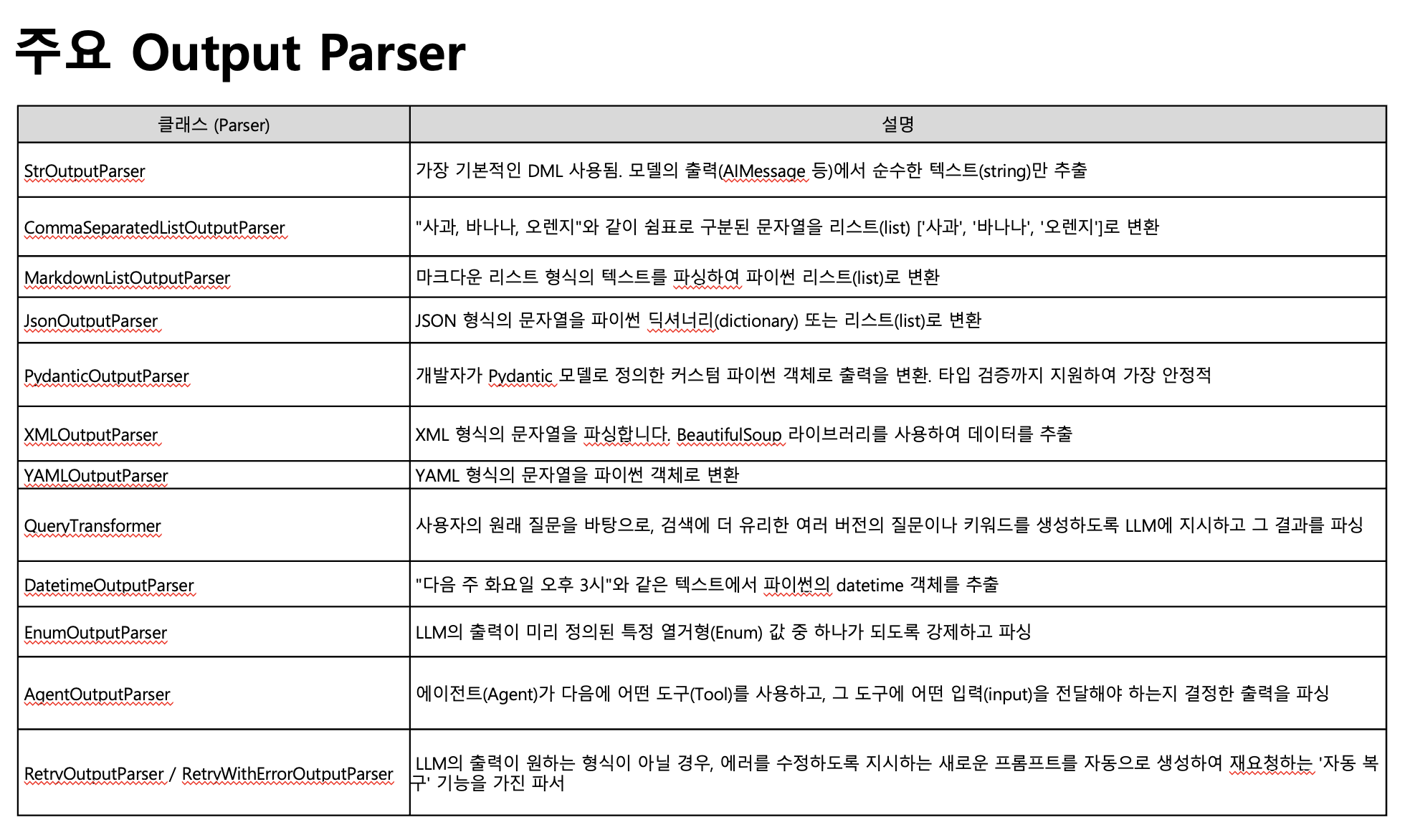
7. 출력 Parser 종류
- StrOutputParser → 기본적으로 많이 사용
- CommaSeparatedListOutputParser
- MarkdownListOutputParser → 마크다운을 list로
- JsonOutputParser
- PydanticOutputParser → 미리 생성한 객체에 타입이 맞는지까지 validation 까지 해줌 /api 통신에 많이 쓰여서 기본적으로 json 문자열으로 리턴하도록 default 설정되어 있음
- XmlOuputParser → html 코드 가져와서 → bs4이용해서 데이터 추출
- 파싱을 안하면 AImessage 객체의 메타데이터까지 모두 가지고 있는 형태로 리턴됨
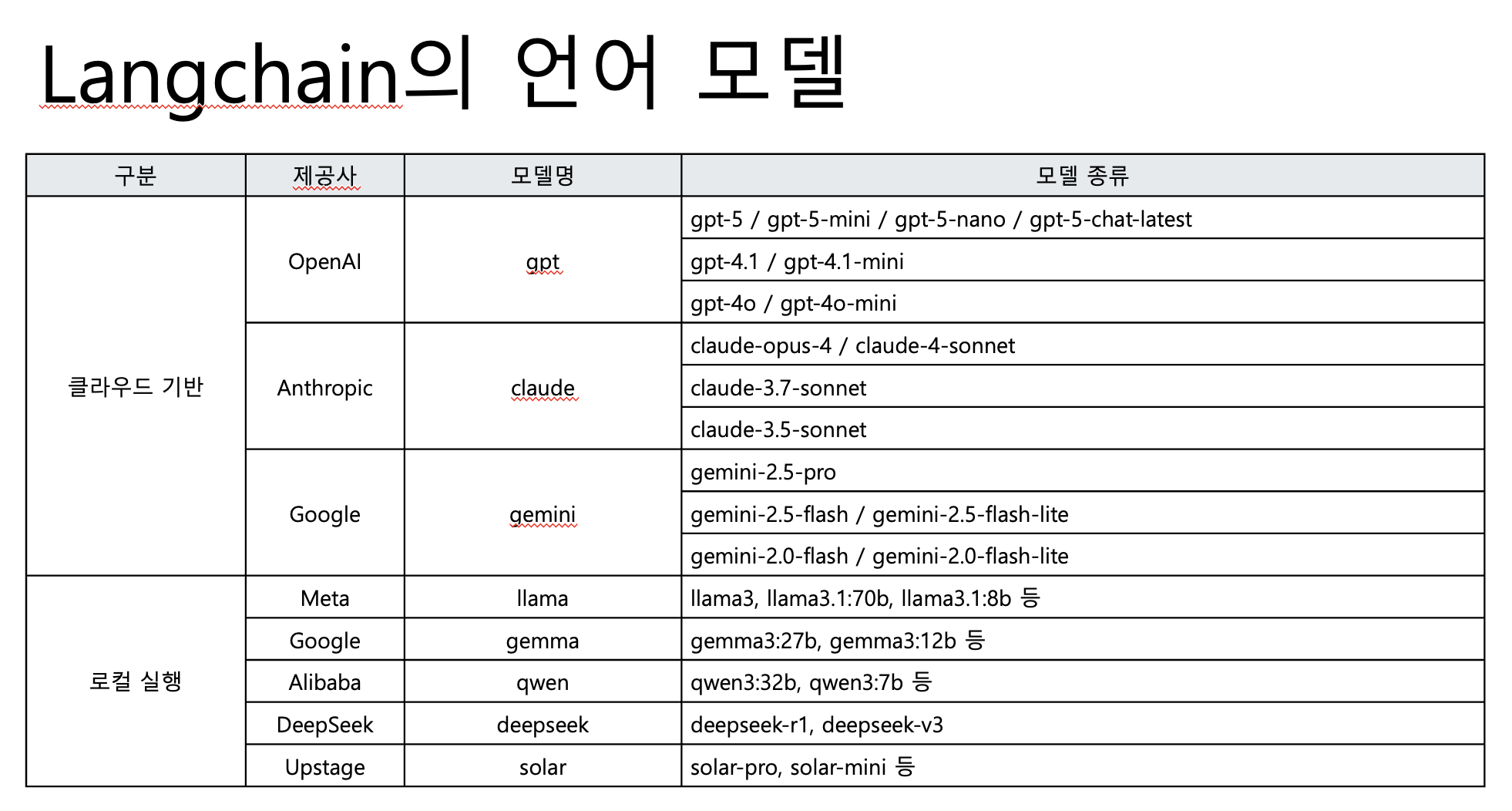
8. Model

- 경량모델로 gemma, qwen 많이 사용하는 추세
- 한국어 성능이 좋은 deepseek의 등장으로 온프레미스 모델에 대한 긍정적 요구사항이 많이 늘어났다.
- 온프레미스 수요가 아주 많음
- ChatOllama → 미리 양자화 해놓은 오픈소스 모델들을 모아놓은 라이브러리다. 온프레미스 llm을 대부분 사용가능하다.
- 경량모델들은 output context가 매우 낮은 경향이 있음
- 토큰값은 영어기준으로 한국어는 2~3배 정도 생각해야 됨
- 허깅페이스 device_map = cpu/gpu/auto
- max_new_tokens →output 토큰을 조절
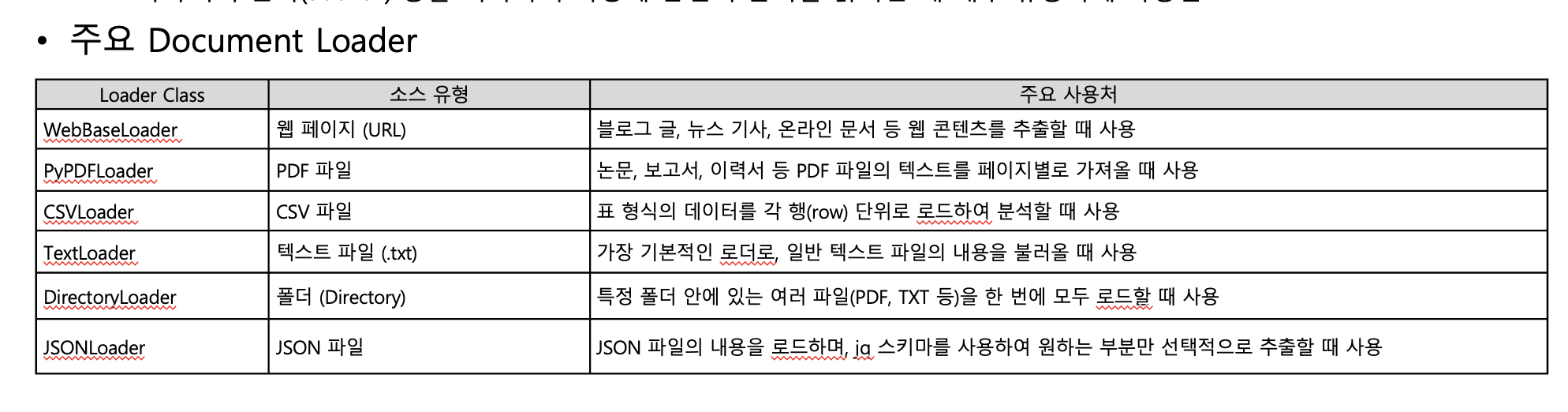
9. Document Loader
- url,pdf,csv,txt,folder,json 등
- page_content, metadata 정보를 가지는 객체
- 메타데이터 제공해서 정보의 신뢰성을 높인다.
- url의 경우 타겟정보 이외의 정보도 가져와서 추가적 정제작업이 필요하다.(WebBaseLoader) -> bs_get_text_kwargs 이용
- txt 는 메타데이터를 가지고 있지 않음. 따라서 encoding='utf-8' 같은 인코딩 설정을 해주어야 함
10. 텍스트 분할(Text Splitter)
- 로드된 데이터를 청킹하는 과정임
- 청킹이 없으면 문서가 길경우 중간을 띄어넘고 끝으로 가는 현상이 생김. 즉 중간정보가 없기때문에 할루시네이션의 원인이 됨
- 문서 전체를 활용하기 위해서 꼭 필요한 과정
- 또한 전체 문서를 넣으면 비용도 너무 많이 발생함. 따라서 리소스 최적화와 핀포인트 정보검색을 위해 꼭 필요한 과정
- 청크오버랩 - 연관성을 붙여주지 않으면 맥락을 이어서 이해 못하기 때문에(뒤를 붙여줌)/ 연관된게 많으면 크게, 연관된게 많이 없으면 작게 ( 청크간 중복되는 문자수)
<많이 쓰는 Text Splitter>
- RecursiveCharacterTextSplitter (가장 많이 씀)
- TokenTextSplitter → 토큰제한에 맞춰 텍스트 짜름
- SemanticChunker → 범용적으로는 RecursiveCharacterTextSplitter를 더 많이 씀
- CodeSplitter
- HTMLHeaderTextSplitter
11. token
- 토큰 인코딩 방식은 o200k_base 형식 사용하면 됨
- 토큰 계산 방식이 다름( cl100k_base, o200k_base)
- 영어-한글 토큰 비용이 2~3배 나게 됨 → 토큰수 계산을 잘해야 함
- OpenAIembedding() → 기본 디폴트 모델을 사용함 ( 지정해서 사용가능)
12. 임베딩(Embedding)
- 문서간 유사성 계산에 필수적
- 차원에 따라 임베딩 값이 달라짐
- 차원이 다른 모델으로 임베딩을 하면 임베딩이 안됨
- 1536차원 vs 1024차원 벡터는 내적(dot product) 연산 자체가 불가능.
- 즉, 같은 차원의 모델로 일관되게 임베딩해야 한다.
- 기본적으로 코사인유사도가 기본세팅(가장 많이 사용함)
- 랭체인에서는 3가지 유사도 검색방식을 정규화해서 사용함
12-1. 유사도 검색방식
1) 유사도 검색 방식
- 코사인유사도
- 두 벡터가 이루는 각도에만 관심을 둔다. (벡터의 크기, 길이는 고려 안함)
- 1에 가까울수록 유사도가 높다
- -1은 완전 반대
- ex) 서울역에서 10m 10km 떨어져 있어도 방향이 같으면 같다.
- 내적
- 벡터 크기가 클수록 내적값이 더 크진다.
- 크기가 큰 벡터의 영향도를 크게 반영
- 방향의 일치도와 함께, 벡터의 영향력(크기)까지 함께 고려하는 방식
- 유클리드유사도
- 두점사이의 직선거리(물리적 거리)만 기준으로
- 거리가 가까울수록 유사하다고 본다
12-2. 임베딩 정규화
- 고유방향은 유지하면서 크기를 1로 만드는 전처리 과정
- 랭체인이 기능을 지원함 (랭체인 없이 하면 어려운데 랭체인으로 쉽게 가능)
- 유클리드 유사도/코사인유사도는 계산이 복잡해서 보통 속도가 느리지만, 정규화하면 속도가 발라짐
- 거리(크기)가 상관이 없게 해준다.
12-3. RAG 벡터 검색에서의 임베딩 정규화 필요성
- 공정한 유사도 비교를 위해 →내용이 길어서 벡터가 큰 문서가 내용은 짧지만 주제와 더 밀접한 문서보다 더 유사하다고 잘못 판단할수 있음
- 계산효율성 → 간단한 내적 연산만으로 빠르게 데이터 가져올수 있음
- 일관된 스케일 유지 → 머신러닝 알고리즘 데이터로 쓸때도 벡터가 비정상적으로 클때 과도한 영향을 주는것을 막는다.
- 허깅페이스 여부는 정규화 여부가 모델마다 다르다.
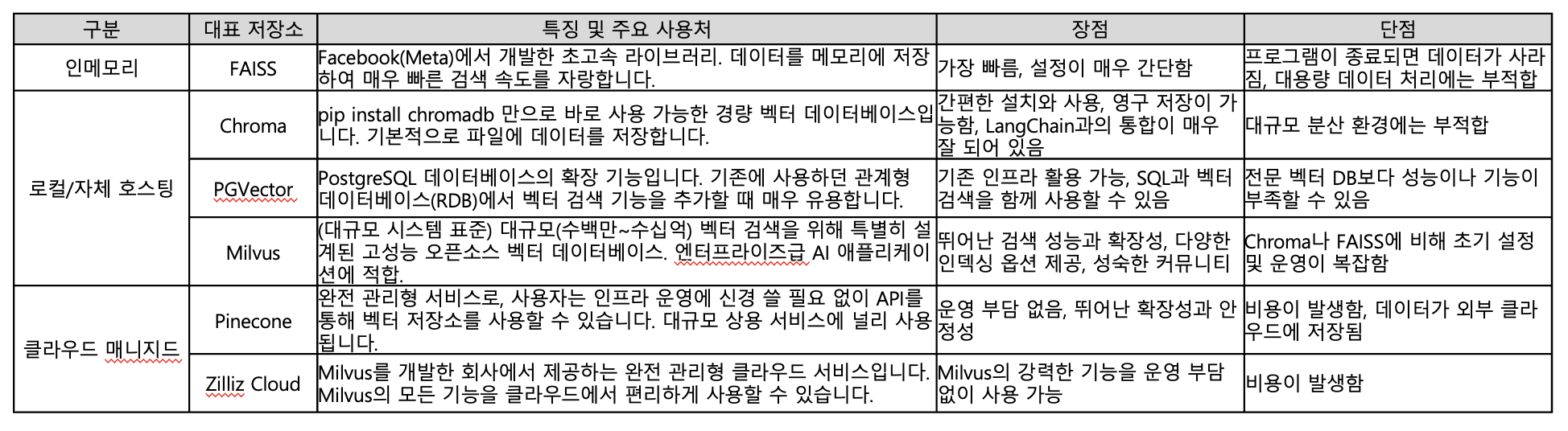
13. 벡터저장소(vectorStore)
- 벡터들 효율적 저장 관리
- postgres 는 정합성이 좀 좋음 ( 백터db)
- 기존 db의 확장기능 - 원본데이터 볼수 있는 장점이 있다.
- RDB → 수억건이 넘어가면 부하가 많이 걸림
- GPU 지원안함
- 벡터DB도 GPU에서 더 빠름
- 다른 벡터전용DB는 GPU 지원함
- 벡터스토어는 유사도 검색을 지원하는 장점이 있음
- chroma → 파일 기반이라 대규모 분산환경에서는 부적합함
- pgvector → GPU 지원안함/ 성능,기능이 부족할수 있음
- milvus → 대규모 시스템 표준 (고성능 오픈소스 벡터 DB)
- 유사도 검색의 k → top k 값 ( 가장 유사한 상위 k개 return)
14. 검색기(Retrieval)
- 사용자의 질문과 관련된 문서를 검색하는 과정
- RAG의 성능과 직결되는 중요한 과정
- 정확한 정보제공 - 가장 관련성 높은 정보 검색, 유용한 답변 생성
- 응답시간단축 - 정보를 바르게 검색, 시스템 응답시간 단축
- 최적화 - 필요정보만 추출, 불필요한 데이터처리 줄임
14-1. 동작방식
- 질문의 벡터화
- 벡터유사성 비교 (코사인유사성, MMR(Max marginal Relevance) 등 사용)
- 상위문서선정
- 문서정보반환(문서내용,위치,메타데이터 포함 할수 있음) 신뢰성의 기초가 됨
- 실제 LLM에 던질때는 벡터가 아니라 텍스트 파일을 input으로 한다. 벡터db 정보도 str으로 조합해서 보냄
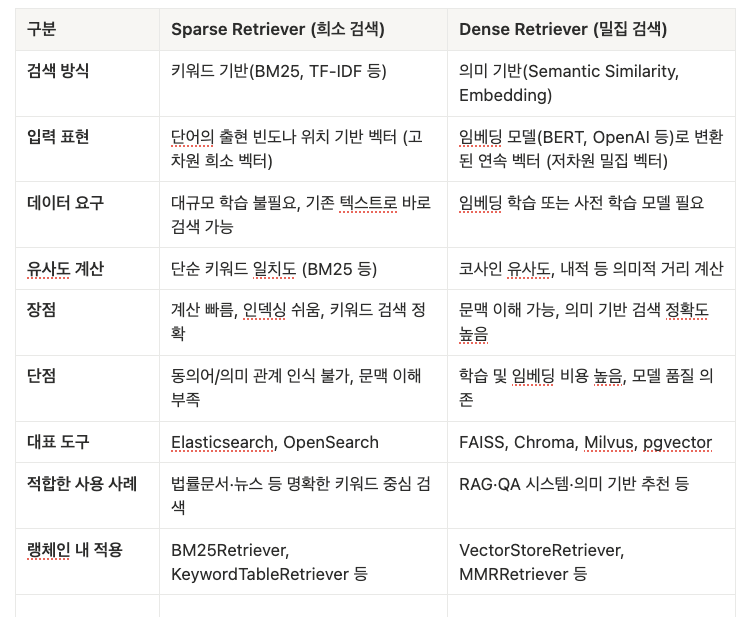
14-2. Sparse Retriever ,Dense Retriever
- Sparse는 “단어 중심”으로 빠르고 단순,
- Dense는 “의미 중심”으로 정확하지만 비용이 높음 입니다.
14-3. 주요 Retrieval
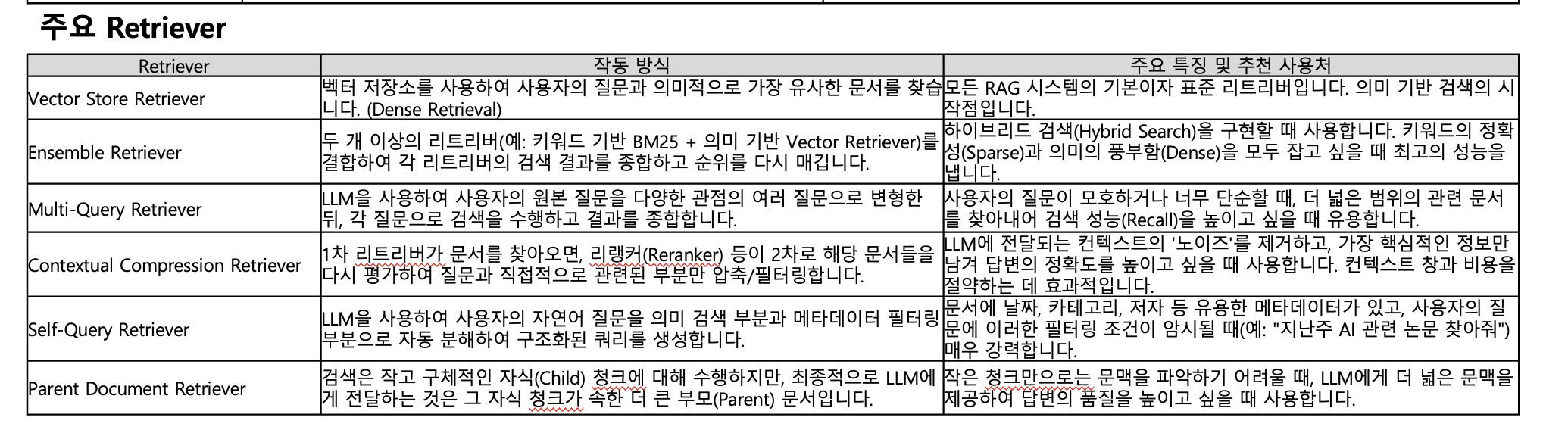
- 리랭커 잘못되면 편향성이 높을 위험이 있음
- 리랭커 잘쓰면 정확도가 높아짐
- BM25 → 키워드 기반 검색 → 벡터 db를 가지는 않음. 객체가 직접 문서에서 검색(키워드 기반)
- 키워드 검색을 단독으로 쓰진 않고, 앙상블 검색(하이브리드) 검색에서 많이 씀
- 앙상블검색에서 비중(weight)을 줄수 있음
- 최근에는 범용성을 가져가기 위해 하이브리드 검색을 많이 사용하고 있음
- temperature → 0 : 일관성 매우 높음 → 1 (창의성) 높음, 미사여구 많음
15. RAG
- RAG (Retrieval Augmented Generation)
- 정보검색, 생성을 통합하는 방법론
- 대규모 문서 DB에서 관련정보를 검색, 언어모델이 더 정확하고 상세한 답변을 생성
- LLM에 참고서를 준다.
- LLM의 한계 - 정보의 최신성 을 극복하게 한다.
15-1. RAG의 8단계 프로세스
- 문서로드
- 텍스트 분할
- 임베딩 → 임베딩 모델 쓰기 전에 샘플 벡터로 테스트 하는 로직을 넣어두면 좋음
- 벡터스토어
- 검색기
- 프롬프트
- LLM → temperature 너무 낮게 셋팅하면 너무 엄격해져서 유사도가 있는 문장도 안가져오는 경향이 있으므로 0.5 정도가 좋다.
- 체인생성
- RunnablePassthrough() → 항등함수
16. multi turn
- 문맥 기억
- RunnableWithMessageHistory
- MessagePlaceholder
- 과거에는 이전 대화 저장했다가 같이 던져 주는 식으로 구현했었음
- 랭체인 안쓰면 인풋값이 엄청 커지는 문제가 생김
- BaseChatMessageHistory
- 세션ID →세션 ID 정보만 있으면 이전 데이터를 모두 볼 수 있음..
def fun(session_id:str) -> BaseChatMessageHistory
"""
세션 ID 대화 히스토리를 가져오거나 새로 생성
Args:
Returns:
"""
# swagger에서 api 문서 자동으로 생성됨17. AGENT
- 인공지능 시스템이 더욱 자율적, 목표지향적 작업 수행할수 있게 하는 컴포넌트
- 자율성/목표지향성/환경인식/도구사용/연속성
- Tools - 웹검색, 계산기, db 조회 등 - 구체적 기능의 목록들 (핵심기술)
- 핵심구성요소 : llm/tools/prompt/AgentExecutor/ReAct프레임워크
- AgentExecutor - 에이전트의 두뇌(llm)이 내린 결정을 실제로 행동으로 옮기고, 이를 다시 두뇌에게 전달하는 실행엔진
- ReAct 프레임워크(Reason, Act)
- though(생각) - 현재상황, 최종목표를 보고, 다음에 무엇을 해야 할지 계획을 세움
- Action(행동) - 계획에 따라 사용할 도구와 도구에 전달할 입력값을 결정
- observation (관찰) - 도구를 실행하여 얻은 결과를 확인
- Repeat(반복) - 관찰 결과 바탕으로 최종 목표 달성했는지 다시 생각 → 목표 달성못하면 1번으로 돌아가 확인
17-1. Tool
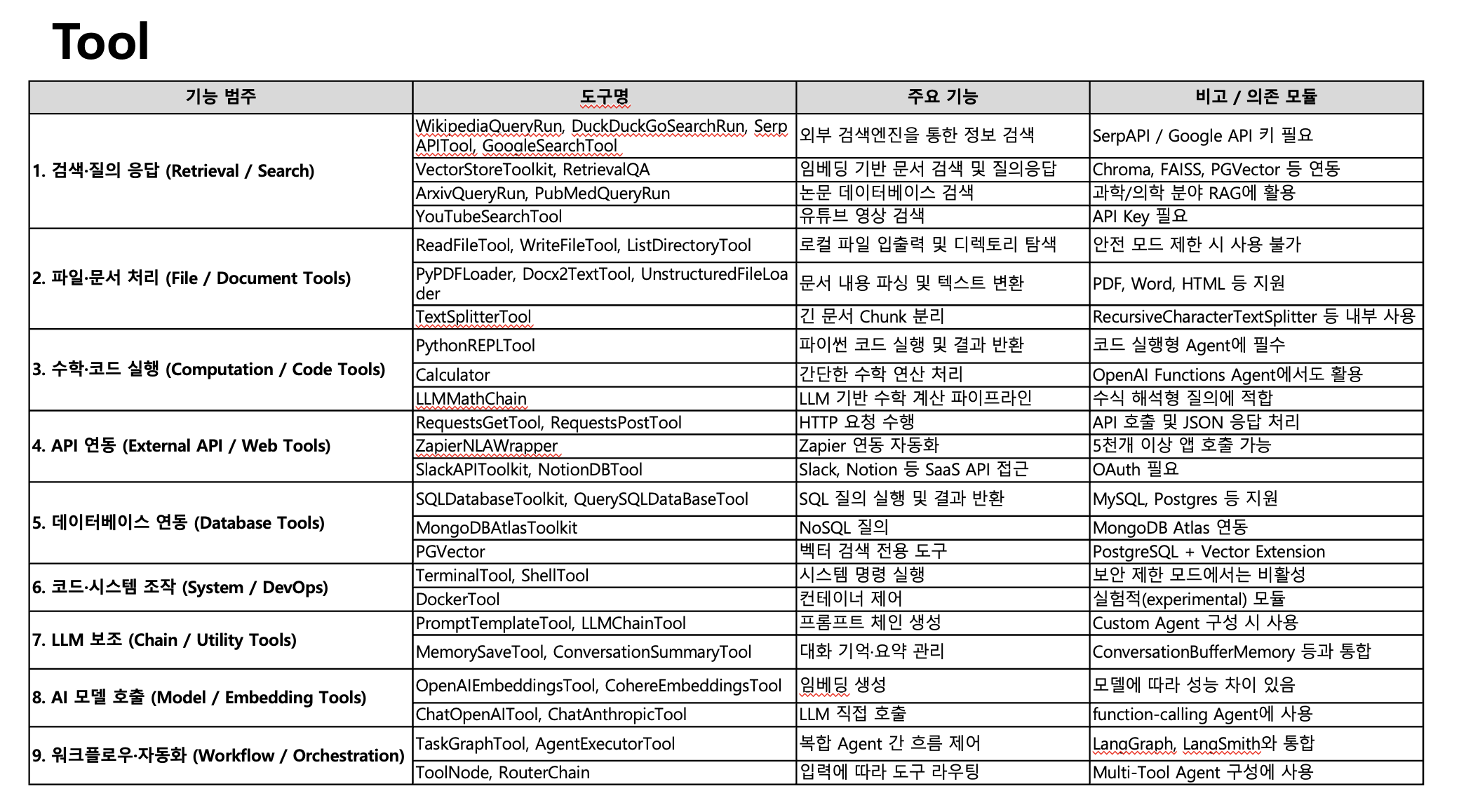
- 검색,질의,응답 - serpapitool (월 2000개는 무료)/유튜브영상검색
- 파일,문서처리 - textsplitterToll (chunking 도구)
- 수학코드실행 - 파이썬 리플툴(코드실행, 결과반환)
- api 연동 - http요청수행, 연동자동화(zapier)
- db연동
- 코드 시스템 조작(system, devops)
- llm 보조
- ai 모델호출
- db 연동 → sql 자연어 질의
- 랭그래프 - 대규모 프로젝트 상태 관리용

즐겁게 공부하고 사람들에게 도움을 주는 개발자가 되고 싶습니다.