1. Series.str
import pandas as pd
s = pd.Series(["apple", "banana", "cherry"])
# 문자열 길이
print(s.str.len())
# 0 5
# 1 6
# 2 6
# dtype: int64
# 소문자를 대문자로
print(s.str.upper())
# 0 APPLE
# 1 BANANA
# 2 CHERRY
# dtype: object
# 특정 패턴 포함 여부
print(s.str.contains("an"))
# 0 False
# 1 True
# 2 False
# dtype: bool- .str은 문자열 메서드를 벡터화해서 Series 전체에 적용.
- 각 원소에 대해 루프 돌리지 않아도 되므로 간결하고 빠름.
- Series 안의 값이 문자열이 아닐 경우 오류가 발생할 수 있음. (NaN은 허용됨)
2. Series.dt
s = pd.to_datetime(pd.Series(["2025-01-01", "2025-09-30"]))
print(s.dt.year) # 연도 추출
print(s.dt.strftime("%Y/%m/%d")) # 원하는 포맷으로 문자열 변환3. Series.cat
s = pd.Series(["a", "b", "a", "c"], dtype="category")
print(s.cat.codes) # 각 카테고리의 코드 번호
print(s.cat.categories) # 카테고리 목록
print(s.cat.remove_unused_categories()) # 안 쓰는 카테고리 제거
4. Series.sparse (희소 데이터 전용)
s = pd.Series([0, 0, 1, 0], dtype="Sparse[int]")
print(s.sparse.density) # 실제 데이터 중 0이 아닌 값의 비율
print(s.sparse.to_dense()) # 일반 시리즈로 변환5. Series.array
s = pd.Series([1, 2, 3])
print(s.array) # <PandasArray>
print(s.array[0]) #6. 80B 의 의미
- 파라미터의 수를 의미
- B = bilion (10억)
- 즉 숫자에 10억을 곱해서 나온수를 파라미터로 갖는다.
context length
- 예: 100k → 최대 100,000 토큰 길이 입력 가능.
- k = 1000
- 100k = 10만 (10만 토큰 처리가능
7. 모델 spec 정보 보는법
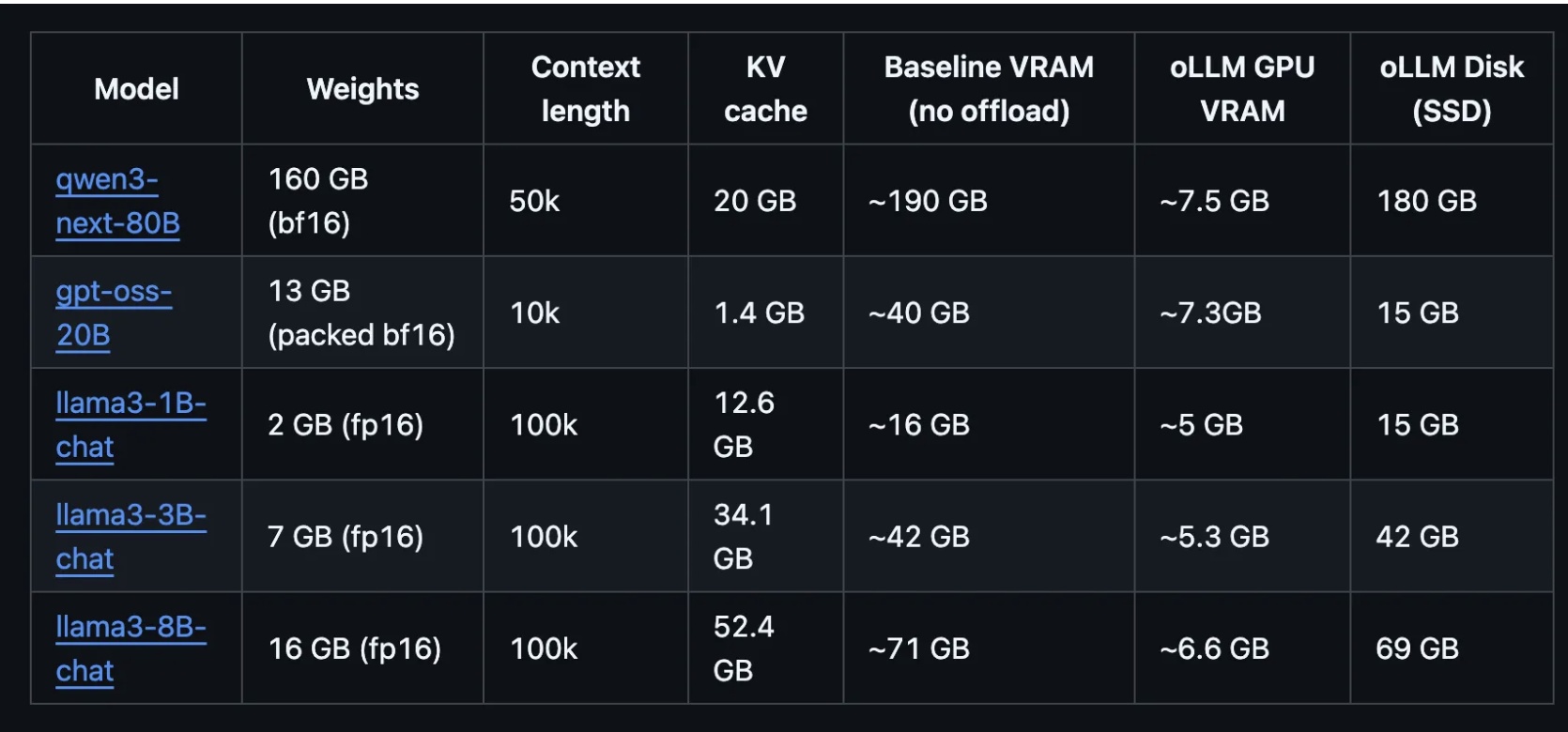
1.Model (모델)
- 사용되는 모델 이름과 파라미터 크기를 나타냅니다.
- 예: qwen3-next-80B → Qwen3 계열 모델, 약 80B(800억 파라미터) 크기.
2. Weights (가중치)
- 모델을 실행하기 위해 필요한 가중치 파일 크기.
- 단위: GB.
- 괄호 안에 bf16, fp16 같은 정밀도(precision) 형식이 표시됨.
- fp16 → half precision (16-bit float).
- bf16 → bfloat16, 비슷한 16-bit 형식.
3. Context length
- 모델이 한 번에 처리할 수 있는 토큰 길이(맥락 창 크기).
- 예: 100k → 최대 100,000 토큰 길이 입력 가능.
4. KV cache
- KV(Key-Value) 캐시는 Transformer 모델의 주의(attention) 연산에서 캐싱되는 메모리.
- 길이가 길어질수록 더 많은 KV 캐시 메모리가 필요.
- 예: 12.6 GB → 100k 토큰 입력을 처리할 때 약 12.6GB 캐시 필요.
5. Baseline VRAM (no offload)
- Baseline VRAM (no offload) 은 👉 “이 모델을 돌리려면, 오직 GPU 메모리(VRAM)만으로 최소 얼마가 필요하냐?“를 뜻해요.
- 예: ~42 GB → 최소 42GB GPU VRAM 필요.
- “no offload”는 CPU나 SSD 같은 다른 장치 도움 없이, 순수하게 GPU만 쓴다는 조건
6. oLLM GPU VRAM
- *oLLM(오픈LLM 런타임)에서 오프로딩(offloading, 일부 연산을 CPU/디스크로 내리는 방식)**을 활용했을 때 GPU가 실제로 필요한 메모리.
- 훨씬 줄어듦. (예: ~5.3 GB만 GPU 필요)
7. oLLM Disk (SSD)
- oLLM 실행 시 SSD에 올려야 하는 모델 파일 크기.
- GPU 대신 SSD에 모델을 두고 일부 로딩하여 실행할 수 있음.
- 예: 69 GB SSD 공간 필요.
✅ 정리
이 표는 “모델을 실행하려면 GPU VRAM과 SSD를 얼마나 준비해야 하는지”를 보여줍니다.
- Baseline VRAM: 순수 GPU로만 돌릴 때 필요 용량 → 대형 GPU 필요.
- oLLM GPU VRAM + Disk: 오프로딩을 활용해 GPU 부담을 줄이고 SSD/CPU로 분산 실행 가능.

8. 공용서버 데이터 저장하기
scp -r edu013@158.247.210.130:/tmp/data .
(-r 옵션을 줘야 한다.)
9. pd 로 csv 파일 읽을때 codec 에러 발생
- encoding 옵션을 넣어주면 된다.
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb1 in position 0: invalid start byte
df = pd.read_csv("data/국민건강보험공단_진료내역정보_2024.CSV", encoding="cp949")
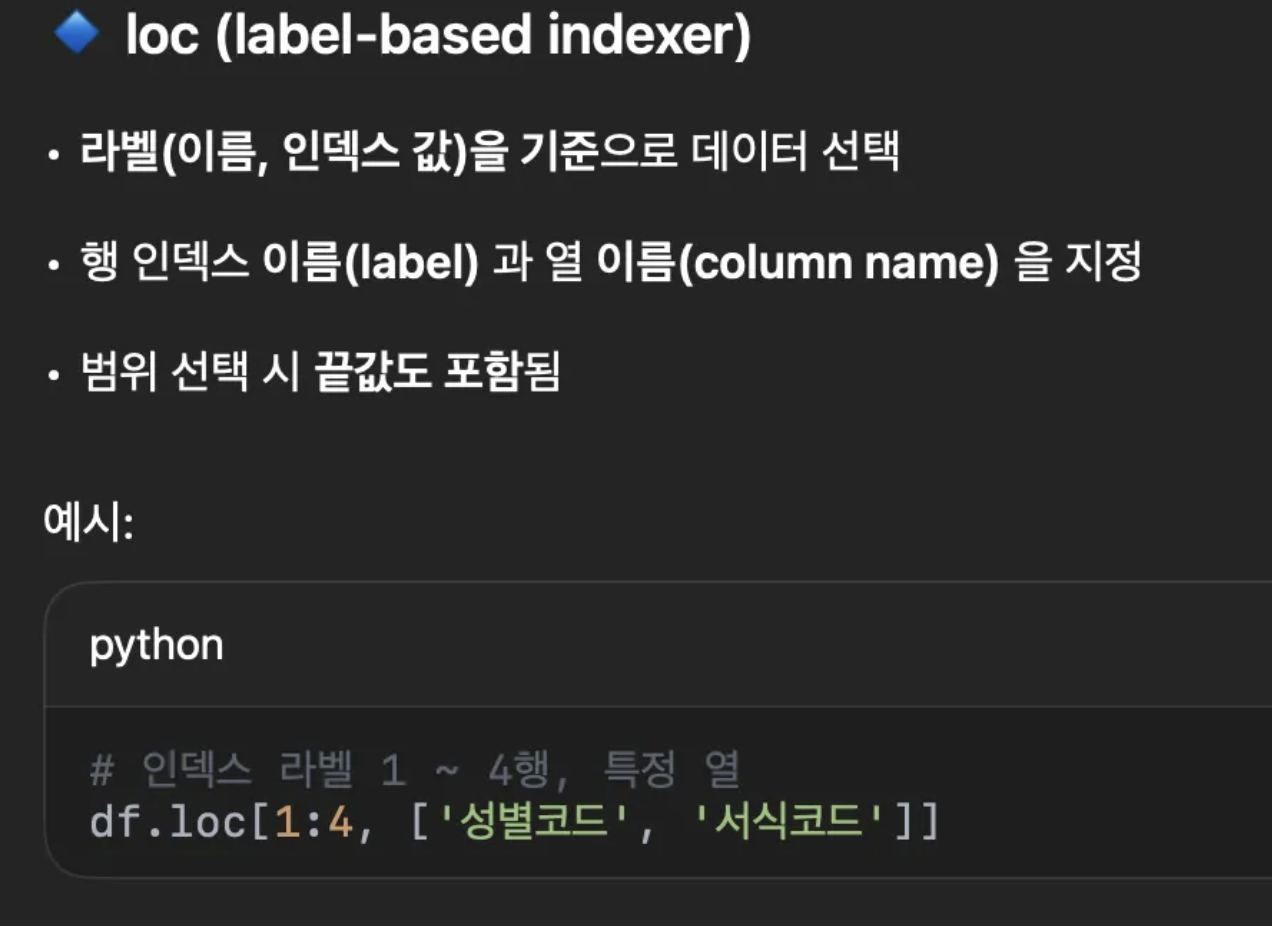
10. loc vs iloc

11. 추천 llm 모델
- Exaone , Gemma
- Qwen2.5, deepseek (오픈소스)
12. 많은 값 unpack
a,b,c, *d = [1,2,2,3,4,12,312,3,21,3,123,21,3,13] # d 는 unpack 하고 나머지 값이 리스트화됨
print(d)13. numpy 에서 숫자형/범주형 데이터를 가진 컬럼만 뽑는 법
#11. 수치형 변수를 가진 컬럼을 출력하라.
dd.select_dtypes(include=['number'])
#12. 범주형 변수를 가진 컬럼을 출력하라.
dd.select_dtypes(include=["object"]).columns14. numpy 결측치 숫자 파악
# 컬럼별 결측치 개수 확인
print(df.isnull().sum())
# 전체 결측치 개수
print(df.isnull().sum().sum()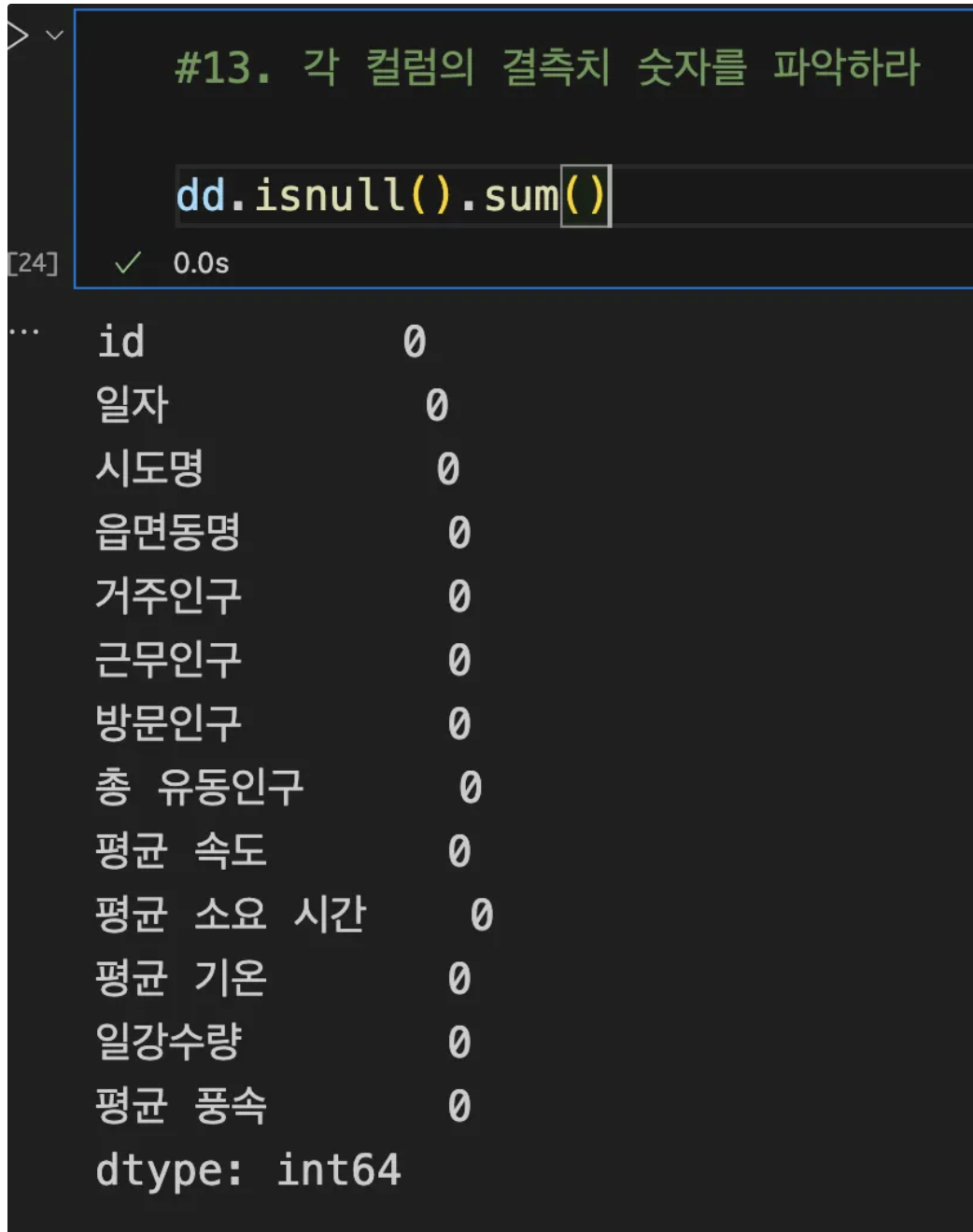
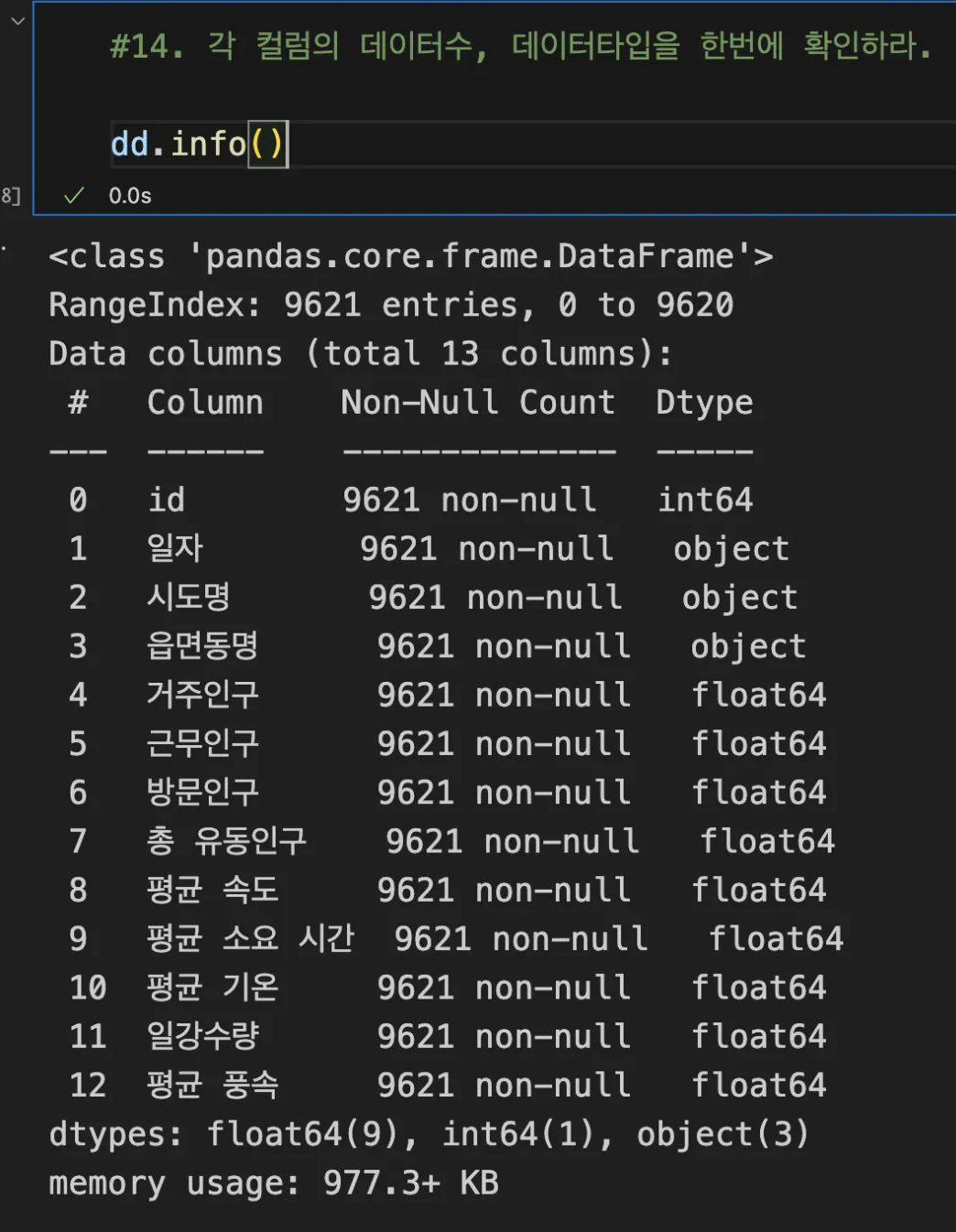
15. 각 컬럼의 데이터타입, 데이터수 확인
16. 평균 속도 컬럼의 4분위 범위(IQR) 값을 구하여라
IQR = dd['평균 속도'].quantile(0.75) - dd['평균 속도'].quantile(0.25)
- IQR(사분위 범위, Interquartile Range)은 Q3(3사분위수) - Q1(1사분위수) 로 계산합니다.
즉, quantile(0.75) 값에서 quantile(0.25) 값을 빼면 됩니다.
17. 인덱스 리셋 하는법
result = dc[mask].reset_index(drop=True)
print(result)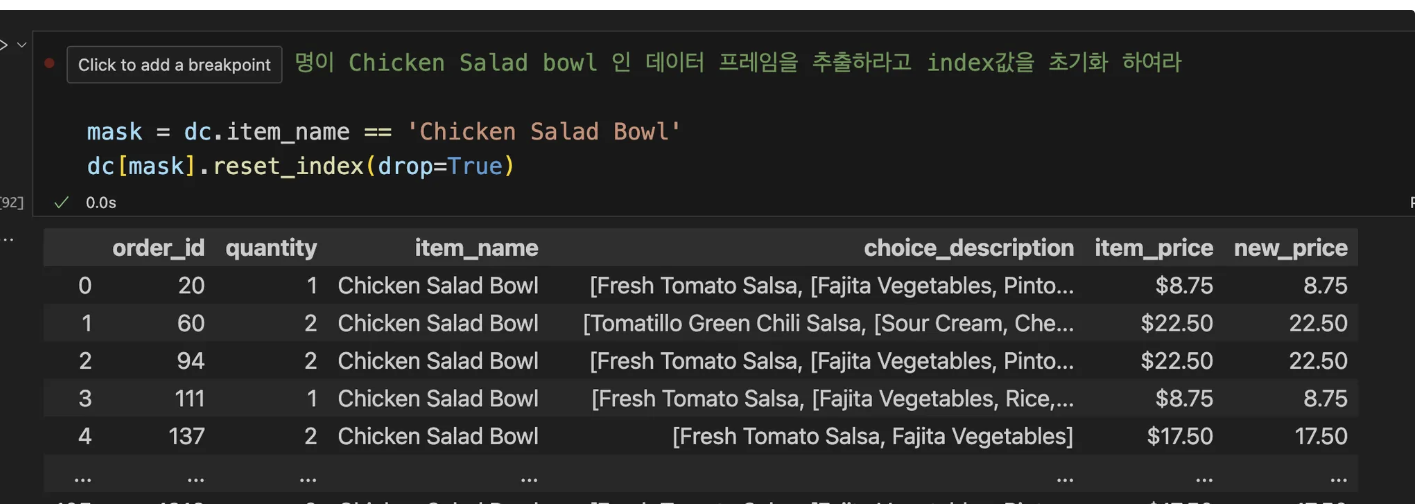
18. db에 데이터 중복 삽입을 방지하는 코드
ALTER TABLE usa_health_data
ADD CONSTRAINT unique_patient_record UNIQUE (name, date_of_admission, doctor);
CREATE UNIQUE INDEX IF NOT EXISTS ux_usa_health_unique
ON public.usa_health_data (name, date_of_admission, doctor);- ON CONFLICT (name, date_of_admission, doctor) DO NOTHING
insert_sql = """ INSERT INTO use_heath_data ( name, age, gender, blood_type, medical_condition, date_of_admission, doctor, hospital, insurance_provider, billing_amount, room_number, admission_type, discharge_date, medication, test_results ) VALUES ( %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s ) ON CONFLICT (name, date_of_admission, doctor) DO NOTHING RETURNING id; """19. 대량 excel 데이터 db에 삽입하기
CREATE TABLE IF NOT EXISTS usa_health_data ( id SERIAL PRIMARY KEY, name VARCHAR(100), age INT, gender VARCHAR(20), blood_type VARCHAR(10), medical_condition VARCHAR(255), date_of_admission DATE, doctor VARCHAR(100), hospital VARCHAR(100), insurance_provider VARCHAR(100), billing_amount DOUBLE PRECISION, room_number VARCHAR(50), admission_type VARCHAR(50), discharge_date DATE, medication VARCHAR(255), test_results VARCHAR(255), CONSTRAINT unique_patient_record UNIQUE (name, date_of_admission, doctor) );
import os
import pandas as pd
import psycopg2
from psycopg2.extras import execute_batch
from dotenv import load_dotenv
load_dotenv()
db_config = {
'host': os.getenv("DB_HOST"),
'port': 5432,
'database': os.getenv('DB_NAME'),
'user': os.getenv('DB_USER'),
'password': os.getenv('DB_PASS'),
}
conn = None
cursor = None
try:
# DB 연결
conn = psycopg2.connect(**db_config)
cursor = conn.cursor()
# 엑셀 로드 & 컬럼명 정리
df = pd.read_excel("data/USA_healthcare_dataset.xlsx")
df.rename(columns=lambda x: x.strip().lower().replace(" ", "_"), inplace=True)
# 타입 변환: DB에 맞게 맞춤
df["date_of_admission"] = pd.to_datetime(df["date_of_admission"]).dt.date # date
df["discharge_date"] = pd.to_datetime(df["discharge_date"]).dt.date # date
df["room_number"] = df["room_number"].astype(str) # varchar
df["age"] = df["age"].astype(int) # int4
df["billing_amount"] = df["billing_amount"].astype(float) # float8
insert_sql = """
INSERT INTO usa_health_data (
name, age, gender, blood_type, medical_condition,
date_of_admission, doctor, hospital, insurance_provider,
billing_amount, room_number, admission_type,
discharge_date, medication, test_results
)
VALUES (
%s, %s, %s, %s, %s,
%s, %s, %s, %s,
%s, %s, %s,
%s, %s, %s
)
ON CONFLICT (name, date_of_admission, doctor) DO NOTHING
RETURNING id;
"""
# 튜플 데이터 준비
rows_to_insert = [
(
r["name"], r["age"], r["gender"], r["blood_type"], r["medical_condition"],
r["date_of_admission"], r["doctor"], r["hospital"], r["insurance_provider"],
r["billing_amount"], r["room_number"], r["admission_type"],
r["discharge_date"], r["medication"], r["test_results"]
)
for _, r in df.iterrows()
]
# 대량 insert
execute_batch(cursor, insert_sql, rows_to_insert, page_size=2000)
conn.commit()
# 최근 10개 데이터 조회
cursor.execute("""
SELECT id, name, age, gender, medical_condition
FROM usa_health_data
ORDER BY id DESC
LIMIT 10;
""")
recent = cursor.fetchall()
print("최근 10개 데이터")
for row in recent:
print(row)except Exception as e:
print("에러 발생:", e)
finally:
if cursor:
cursor.close()
if conn:
conn.close()
print("DB 연결이 종료되었습니다.")
#### 20. 넘파이에 & | 연산 할때 연산자 우선순위가 낮아서, 각 조건을 갈호로 묶어 줘야함
```python
mask = dc.item_name == 'Steak Salad' | dc.item_name == 'Bowl' (틀림)
mask = (dc.item_name == 'Steak Salad') | (dc.item_name == 'Bowl') (맞음)
mask = dc.item_name.isin(['Steak Salad', 'Bowl']) (이런방식도 있다)21. item_name을 기준으로 중복행이 있으면 제거하되, 첫번째 케이스만 남겨라.
#33. df의 item_name 컬럼 값이 streak salad or bowl인 데이터를 데이터 프레임화한후
# item_name을 기준으로 중복행이 있으면 제거하되, 첫번째 케이스만 남겨라.
dc[dc.item_name.isin(['Steak Salad', 'Bowl'])].
drop_duplicates(subset='item_name', keep='first')
# item_name 하나만 기준
df.drop_duplicates(subset="item_name", keep="first")
# item_name + doctor 두 컬럼을 기준
df.drop_duplicates(subset=["item_name", "doctor"], keep="first")- keep → ‘first’, ‘last’, False 들어갈수 있따.
- subset은 리스트로 여러 기준을 제공할 수 있다.
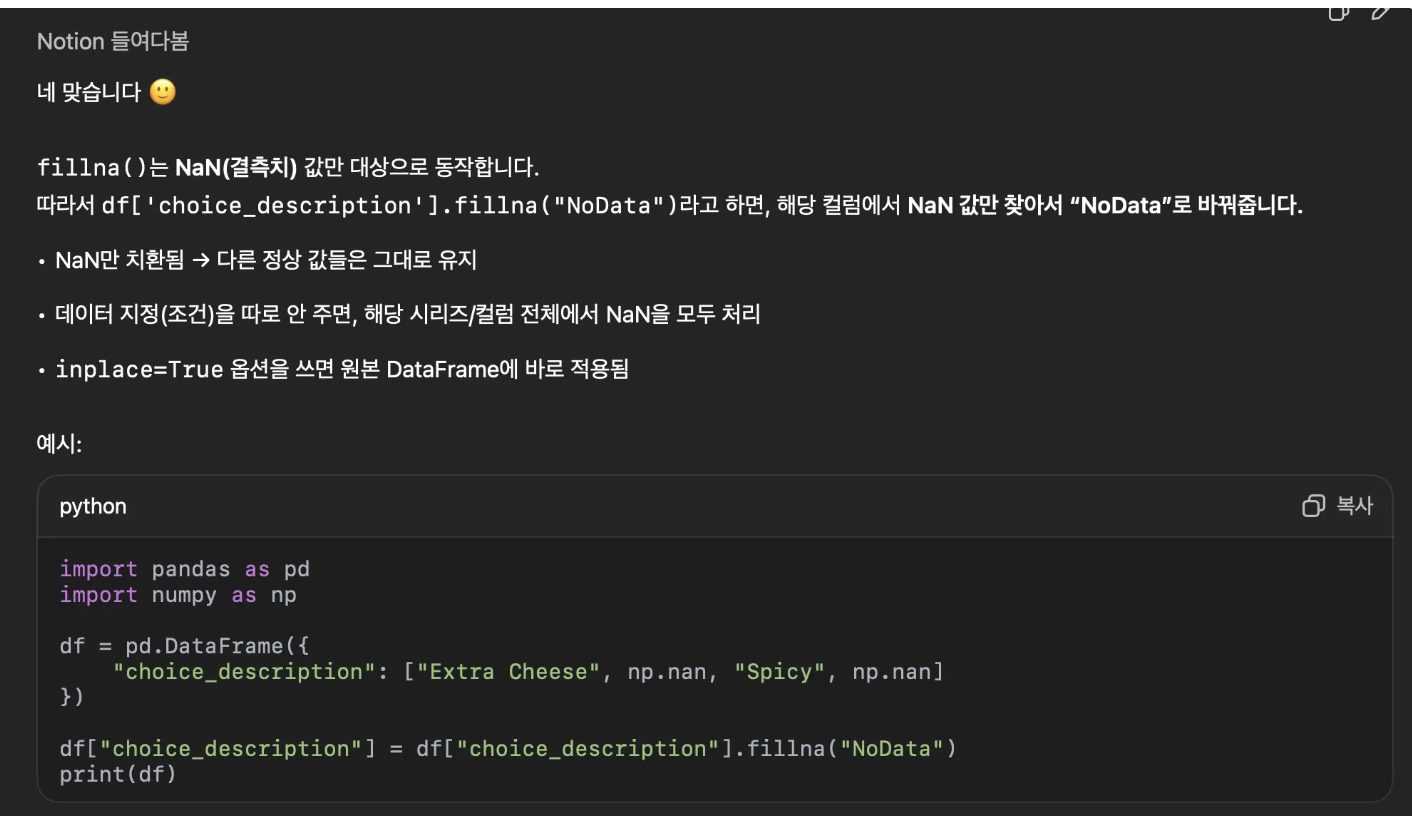
22. df 데이터 중 choice_description 값이 NaN인 데이터를 NoData 값으로 대체하라(loc 이용)
df['choice_description'] = df['choice_description'].fillna("NoData")
df.loc[df['choice_description'].isna(), 'choice_description'] = "NoData"23. fillna

즐겁게 공부하고 사람들에게 도움을 주는 개발자가 되고 싶습니다.