연관 규칙 분석 (Association Rule Analysis, Association Rule mining) & 연관 규칙 탐색(Feat. Apriroi 알고리즘)
Recommended System
목록 보기
3/6
연관 규칙 분석 (Association Rule Analysis, Association Rule mining)
흔히 장바구니 분석 혹은 서열 분석이라고도 불리며, 상품의 구매, 조회 등 하나의 연속된 거래들 사이의 규칙을 발견하기 위해 적용하는 분석 기법이다.
연관 규칙의 예시

- {기저귀} → {맥주}
- {우유, 빵} → {계란, 콜라}
- {맥주, 빵} → {우유}
즉, 연관 규칙은 IF (antecedent) Then (consequent) 꼴로, 특정 사건이 발생했을 때 함께 빈번하게(frequently) 발생하는 또 다른 사건의 규칙을 의미한다.
빈발 집합(Frequent Itemset)
Itemset
- 1개 이상의 item의 집합(set)을 의미한다.
- ex) {빵, 우유, 기저귀}
support count()
- 전체 transaction data에서 itemset이 등장하는 횟수를 의미한다.
- ({빵, 우유}) = 3
support
- itemset이 전체 transaction data에서 등장하는 비율을 의미한다.
- support({빵, 우유}) = 3 / 5 = 0.6
frequent itemset
- 유저가 지정한 minimum support 값 이상의 itemset을 의미한다.
연관 규칙의 척도
support
- 두 itemset 를 모두 포함하는 transaction의 비율을 의미한다.
- 즉, 전체 transaction에 대한 itemset의 확률 값으로, 좋은 규칙을 찾거나, 불필요한 연산을 줄일 때 사용된다.
confidence
- 가 포함된 transaction 가운데 도 포함하는 transaction 비율(의 에 대한 조건부 확률)
- confidence가 높을수록 유용한 규칙을 뜻한다.
lift
- [가 포함된 transaction 가운데 가 등장될 확률] / [가 등장할 확률]을 의미한다.
- lift = 1 → 는 독립
- lift > 1 → 가 양의 상관관계를 가짐
- lift < 1 → 가 음의 상관관계를 가짐
연관 규칙의 탐색
Mining Association Rules
- 주어진 트랜잭션 가운데, 아래의 조건을 만족하는 가능한 모든 연관 규칙을 찾는다.
- 그렇다면 어떻게 찾을 수 있을지 고민해봐야한다.
Brute-force approach
- 먼저, 가능한 모든 연관 규칙을 나열해 계산하는 Brute-force 방법을 떠올릴 수 있다.
- 이 때, 모든 연관 규칙에 대해서 개별 support와 confidence를 계산해야 하는데, 그러려면 지수적으로 많은 계산량이 요구된다.
- 주어진 d개의 unique item에 대해서, 전체 가능한 연관 규칙의 개수는 다음과 같다.
효율적인 Assiciation Rule Mining이 필요하다.
- Association Rule Mining을 하기 위해서는 두 가지 스텝을 거쳐야 한다.
- Frequent Itemset Generation : minimum support 이상의 모든 itemset을 생성한다.
- Rule Generation : minimum confidence 이상의 association rule을 생성한다. 이때, rule을 이루는 antecedent와 consequent는 서로소를 만족해야 한다.
- 이 때 1번 Task의 computation cost가 가장 크다.
Frequent Itemset Generation Strategies
- 가능한 후보 itemset의 개수를 줄이는 방법
- 완전 탐색의 경우 이다.
- Apriori 알고리즘은 가지치기를 활용해 탐색해야하는 을 줄인다.
- 탐색하는 transaction의 숫자를 줄인다.
- itemset의 크기가 커짐에 따라 전체 N개 transaction보다 적은 개수를 탐색하는 방법이다.
- DHP(Direct Hashing & Pruning) 알고리즘을 활용할 수 있다.
- 탐색 횟수를 줄인다.
- 효율적인 자료구조를 사용해 후보 itemset과 transaction을 저장하는 방법이다.
- FP-Growth 알고리즘을 활용하면 모든 itemset과 transaction 조합에 대해서 탐색할 필요가 없다.
Apriori 알고리즘
연관 규칙의 탐색 과정에서 가능한 후보 itemset의 개수()을 줄이는 알고리즘이다.
1) 빈발항복집합도출 : Frequent Itemset Generation 원리
- itemset A가 frequent itemset이라면, A의 모든 부분집합은 frequent itemset이다.
- 즉, itemset A의 support는 A의 subsets의 support보다 절때 클 수 없다.
- 무슨 말이냐 하면, {빵, 우유, 기저귀}를 사는 사람이 {빵, 우유}를 사는 사람보다 많을 수 없다는 뜻으로 이해하면 된다.
- 따라서 특정 itemset의 support가 유저가 지정한 minimal support 값을 넘지 못해 비빈발 항목(infrequent item set)이 될 경우, 비 빈발 항목을 부분집합으로 가지고 있는 모든 itemset을 가지치기(pruning)한다.
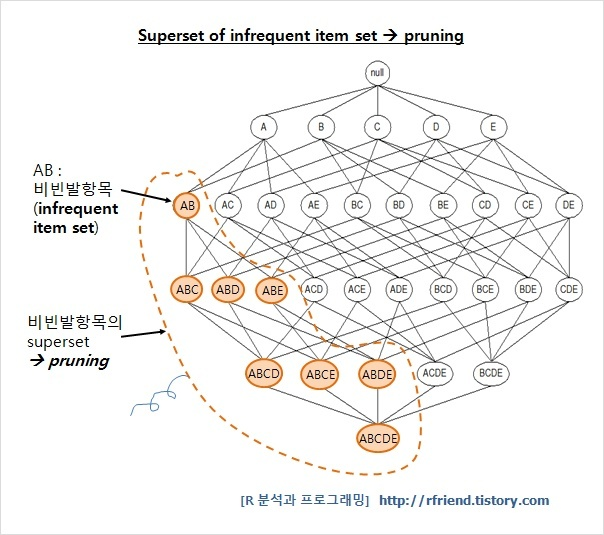
2) 연관 규칙 생성 : Rule Generation 원리
- frequent itemset 과 의 부분집합 에 대하여 가 최소 신뢰도 기준을 만족하지 못한다면 의 부분집합 에 대해서 도 최소 신뢰도 기준을 만족하지 못한다.
- 3항목 빈발항목집합 C3 {B,C,E}에서 6개의 연관 규칙을 만들어보면 아래 그림과 같다.
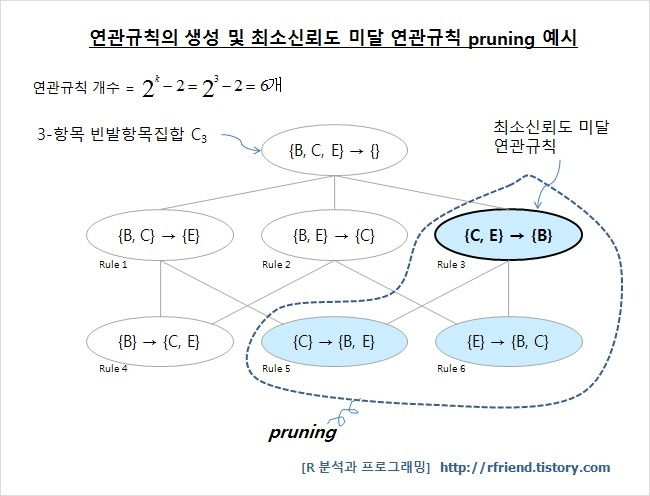
- 이 때 {C, E} → {B} 연관 규칙이 최소신뢰도 기준에 미달한 경우, 그 밑에 딸린 {C} → {B, E}, {E} → {B, C} 연관 규칙을 가지치기(purning) 한다.📚 REFERENCE
- 네이버 부스트 캠프 AI TECH 5기 강의자료

Grow Exponentially