TF-IDF를 활용한 컨텐츠 기반 추천
컨텐츠 기반 추천(Content-based Recommendation)
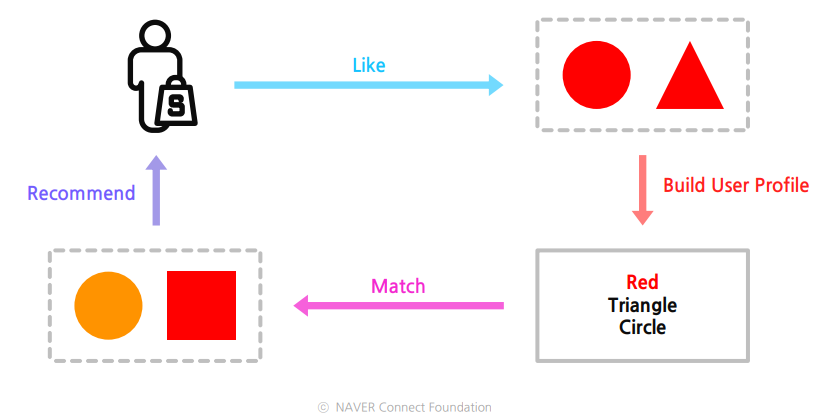
- 유저가 선호하는 아이템을 기반으로 해당 아이템과 유사한 아이템을 추천하는 방식의 추천 기법이다.
장점
- 유저에게 추천을 할 때 다른 유저의 데이터가 필요하지 않으며, 새로운 아이템 혹은 인기도가 낮은 아이템을 추천할 수 있다.
- 추천 아이템에 대한 설명이 가능하다.
단점
- 아이템에 적합한 피쳐를 찾는 것이 어렵다.
- 다른 유저의 데이터를 활용할 수 없으며, 한 분야/장르의 결과만 계속해서 나올 수 있다.(overspcialization)
Item Profile to Vector : TF-IDF
Item Profile
- 추천 대상이 되는 아이템의 feature들로 구성된 item profile을 벡터(Vector)로 만들어 표현한다.
- 문서(Document)의 경우 중요한 단어들의 집합으로 표현할 수 있다. 이때 단어에 대한 중요도를 나타내는 스코어로 가장 많이 쓰는 기본적인 방법은 TF-IDF 방법이다.
TF-IDF(Term Frequency - Inverse Document Frequency)
- 문서 d에 등장하는 단어 w에 대해서
- 단어 w가 문서 d에 많이 등장하면서(Term Frequency, TF)
- 단어 w가 전체 문서(D)에서는 적게 등장하는 단어라면(Inverse Document Frequency; IDF)
- 단어 w는 문서 d를 설명하는 중요한 feature로, 높은 TF-IDF 값을 가지게 된다.
TF−IDF(w,d)=TF(w,d)⋅IDF(w)
- TF : 단어 w가 문서 d에 등장하는 횟수 TF(w,d)=freqw,d (basic form) TF(w,d)=maxk(freqk,d)(freqw,d) (normalize TF form to discount ‘longer’ document)
- IDF : 전체 문서 중 단어 w가 등장한 비율의 역수 IDF(w)=lognwN (N:전체 문서 개수, nw:w가 등장한 문서 개수)
TF-IDF 예시
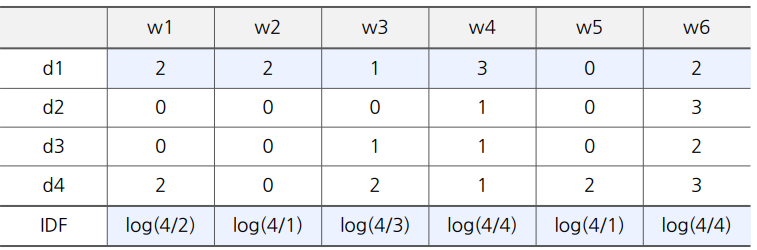
- TFIDF(w1,d1)=2 ⋅ log24=0.6
- TFIDF(w2,d1)=2 ⋅ log14=1.2
- TFIDF(w3,d1)=1 ⋅ log34=0.12
- TFIDF(w4,d1)=3 ⋅ log44=0
- TFIDF(w5,d1)=0 ⋅ log14=0
- TFIDF(w6,d1)=0 ⋅ log44=0
따라서 문서를 표현하는 item profile vector vd1=(0.6,1.2,0.12,0,0,0)이 됨
User Profile 기반 추천과 예측
Build User Profile
- 구축한 Item Profile을 바탕으로 유저에게 아이템을 추천한다. → User Profile 구축이 필요하다.
- 각 유저의 Item List안에 있는 Item의 Vector들을 통합하면 User Profile이 된다.
- Simple : 유저가 선호한 Item Vector들의 평균값을 사용한다.
- 유저가 d1, d3을 선호했다면 SimpleVector=2vd1+vd3
- Variant : 유저가 아이템에 내린 선호도로 정규화(normalize)한 평균값을 사용한다.
- 유저가 d1, d3을 선호했다면 VariantVector=rd1+rd3rd1vd1+rd3vd3
추천 : 유저와 아이템 사이의 거리 계산하기
- 유저 벡터 u와 아이템 벡터 i에 대해서 아래와 같이 코사인 유사도를 통해 벡터간의 거리를 계산한다.
score(u,i)=cos(u,i)=∣u∣⋅∣i∣u⋅i
- 두 벡터의 유사도가 클수록 해당 아이템이 유저에게 관련성이 높으며, score(u,i)가 가장 높은 아이템부터 유저에게 추천하게 된다.
예측 : 정확한 평점 예측하기
- 유저 u가 선호하는 아이템 I={i1,…,iN}의 Item vector는 V={v1,…,vN}, 평점은 ru,i일 때, 새로운 아이템 i′에 대해 평점을 예측해보면, i′과 i에 속한 아이템 i의 유사도는 다음과 같다. sim(i,i′)=cos(vi,vi′)
- 해당 유사도를 가중치로 사용하여 i′의 평점을 추론할 수 있다. prediction(i′)=∑i=1Nsim(i,i′)∑i=1Nsim(i,i′)⋅ru,i
- 예를 들어, 특정 유저가 선호한 영화가 3개 있을 때 평점과 해당 영화에 대한 itemvector는 다음과 같고,
- m1:rm1=3.0, vm1=[0.2,0.4,1.2,1.5]
- m2:rm2=2.5, vm2=[0.4,0.7,0.3,0.5]
- m3:rm3=4.0, vm3=[0.3,1.2,1.0,1.0]
- 예측하려는 영화 m4의 vm4=[0.4,1.4,3.1,1.0]이라면,
- sim(m4,m1)=cos(vm4,v,m1)=0.83
- sim(m4,m2)=cos(vm4,v,m2)=0.72
- sim(m4,m3)=cos(vm4,v,m3)=0.88
- 예측 평점 prediction(m4)는 다음과 같다. prediction(m4)=0.83+0.72+0.880.83⋅3.0,0.72⋅2.5,0.88⋅4.0=3.2
📚 REFERENCE
- 네이버 부스트캠프 AI TECH 5기 강의자료
