[2024 LLM 스터디] 1. Introduction
from "A Survey of Large Langauge Models (2024)"
"나의 언어의 한계는 나의 세계의 한계를 의미한다"
(Die Grenze meiner Sprache bedeuten die Grenze meiner Welt)- Ludwig Wittgenstein (Tractatus Logico-Philosophicus, 1921)
언어 모델(Language Model)이란 무엇인가?
- 시퀀스에 대한 생성 확률(generative likelihood)을 모델링하여 미래의 또는 누락된 토큰을 예측하는 모델
언어 모델의 역사
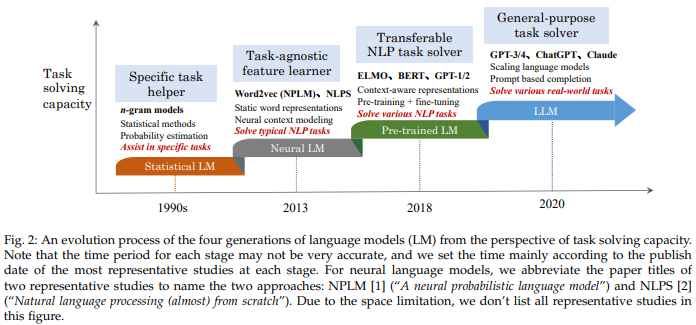
1. Statistical Language Models
- 1990년대 이후 통계적 접근 방식을 이용한 모델
- Markov Assumption (현재 상태가 바로 이전 상태에 의존하며, 더 이전의 상태에는 적게 의존한다는 가정; 하단 식 참조) 을 이용한 언어모델과 n-gram 언어 모델 등이 제시됨
Markov Assumption: where refers to word or token
- 한계: 고차원의 모델에서는 curse of dimensionality 발생 data sparsity, 계산 복잡도 증가 등
2. Neural Language Models
- Word2Vec (2014) 이후로 token에 대한 distributed (vector) representation이 가능해져 MLP, RNN 등 LD 기반 접근의 효용이 상승
3. Pre-trained Language Models (PLM)
- ELMo (2018): bi-LSTM 기반의 context-aware word representation을 학습한 첫 번째 PLM으로, downstream task는 bi-LSTM을 finetune
- BERT (2018): Transformer 기반으로 pretraining task (MLM) 를 대규모의 unlabeled corpora에 적용하여 context aware word representation을 효과적으로 학습, general purpose semantic features를 이용해 다양한 NLP task의 performance 향상
- a.k.a. "pre-training and "fine-tuning" 패러다임의 대두를 불러옴
- 한계: downstream task에 대한 fine-tuning이 필요
4. Large Language Models (LLM)
- PLM을 키울수록 downstream task에 대한 성능이 향상됨을 확인 (scaling law) 하였으며, 모델 크기가 어떠한 시점을 돌파한 순간, "emergent abilities"를 PLM이 보유한다는 점을 확인
- 위와 같이 '거대한' 규모의 언어모델을 "Large Language Models"로 지칭하기로 합의
LLM이 가져온 & 가져올 변화들
- Emergent Abilities: LLM에서는 이전 상대적으로 소규모의 PLM에서 불가능했던 능력들 (a.k.a. emergent abilities) 을 보이며, 이러한 emergent abilities는 complex task를 해결하는 데에 핵심적으로 작동함
- HAI interaction 패러다임 변화: LLM을 이용할 때 prompting을 사용한 Human-AI interface의 혁신이 가능함
- 연구자에게 더 많은 능력을 요구: LLM 학습을 위해 대규모 데이터의 가공, 분산 및 병렬 처리 등의 엔지니어링 기술이 필요해져 research와 engineering의 경계가 모호해짐
- 연구동향의 변화: IR 분야의 경우, AI Chatbots를 이용한 information retrieval로, CV의 경우, multimodal dialogue를 더 잘 수행하는 ChatGPT-style의 VLM을 연구하는 등, 점점 더 real-world application으로 연구 동향이 변화하는 중
아직 남아있는 LLM 연구주제들
- 해석가능성 향상: emergent abilities가 왜, 어떻게 작동하는가?
- in-context learning 해석의 수식적 접근 등
- LLM 학습의 개선 및 투명화: data, computation resource의 개선, 학습 데이터와 모델 파라미터의 공개 등
- efficient finetuning (adaptation), model merging etc.
- 인간과 더 잘 align된 모델: human preference, helpfulness를 개선하고, toxicity, harmfulness를 줄이는 연구 필요
Preview of Section 2
- Scaling Laws (2020)
- Emergent Abilities & how emergent abilities relate to Scaling Laws
- technical leaps & milestones of LLMs

multidisciplinary