[2024 LLM 스터디] Scaling Laws for Neural Language Models (2020)
본 power-law scaling은 transformer architecture 하에서 loss, 즉 performance를 dataset size (), model size (), compute budget ()의 함수로 구성할 수 있다는 아이디어임
Chinchilla Scaling Law (2022) 와의 차이점과 그 이유가 궁금하다? Resolving Discrepancies in Compute-Optimal Scaling of Language Models (2024) 를 참조
Abstract
- LM의 scaling laws를 cross entropy loss에서 empirical하게 확인
- loss는 model size, dataset size, amount of compute used에 따라 power-law로 scale함
- network width, depth는 상대적으로 적은 부분을 차지함
- 한정되어 있는 computing budget에서 optimal allocation을 계산할 수 있음
- 큰 모델은 sample efficient하여 compute-efficient training은 상대적으로 modest amount of data에서도 가능함
Background
- 왜 Power Law인가?
- power law는 다양한 사회현상을 설명하는 데에 사용되고 있고, CS & AI 에서도 도입된 바 있음
e.g. dataset size & model size (ACL 2001)
- EfficientNet을 대상으로 한 연구 (ICML 2019) 에서는, model architecture인 width와 depth가 성능과 power law가 있다고 주장하였음 하지만 NLP에서는 해당 법칙을 따르지 않는다는 것을 실험에서 보임
Scaling Laws in short
는 critical, 즉 임계점을 의미함. 임계점 (critical point) 에서의 N, D, C와 지금 손에 갖고 있는 N, D, C가 존재할 때 loss를 계산할 수 있음

1. Performance & model scale, architecture
-
모델 성능은 scale과 큰 상관관계가 있으며, 모델 구조와는 큰 관계가 없음: scale은 model parameter (embedding 제외) , dataset size , 컴퓨팅 파워 로 구성됨. 모델의 depth와 width같은 architectural hyperparameter는 굉장히 작은 상관관계를 가짐 (sec 3)
-
Smooth power laws: 와 성능의 관계는 다른 요소들에서 bottleneck이 있지 않는 한 (loss 기준) 1e-^6차까지 확인됨 (sec 3)
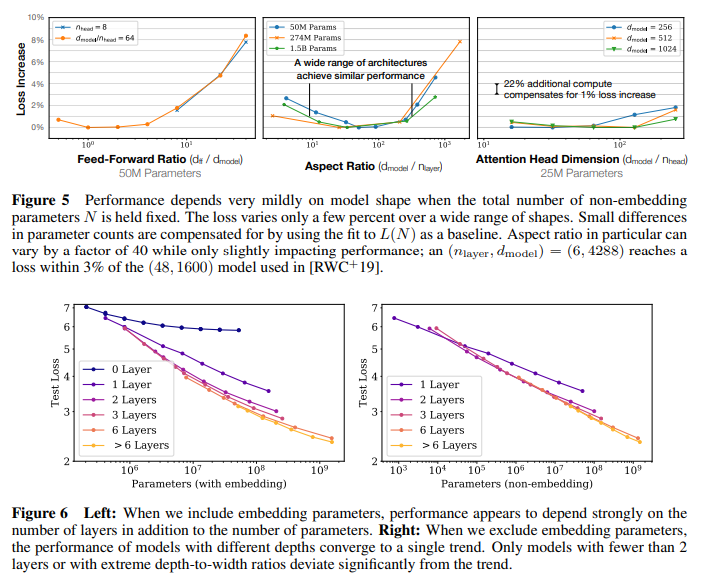
- (figure 5) 전체 parameter 을 고정하고 shape parameter 를 바꿔봤을 때, 성능에 유의미한 개선을 탐지하지 못함
- (figure 6) 모델 () 을 (2, 128) 부터 (207, 768)까지 실험했을 때, performance는 non-embedding parameter 와 강한 상관관계를 보임 embedding matrix는 performance와 작은 상관관계를 가짐
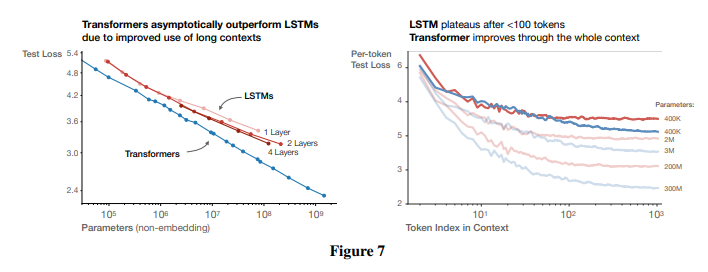
- (figure 7) 같은 데이터, 같은 parameter size의 LSTM과 비교하면, transformer는 뒤의 token을 예측하는 데에 더 좋은 성능을 보여 최종적으로 LSTM은 transformer의 performance & power-law를 따라올 수 없음
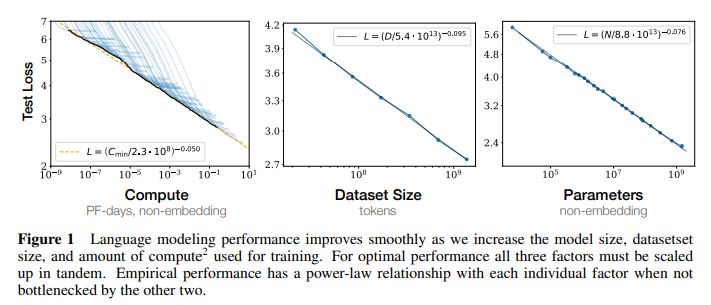
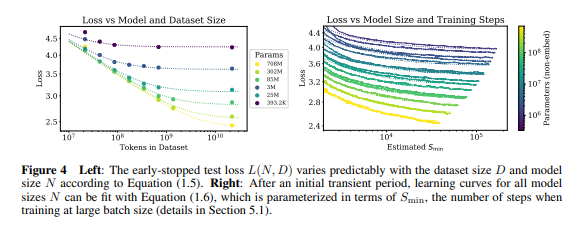
- (figure 1) 의 모델로 실험했을 때, 위와 같은 dataset size와 성능 간 관계 (power law) 를 확인할 수 있었음. computing budget 또한 유사한 상관관계 (power law) 를 가짐.
2. Transfer Learning과의 관계
- Transfer improves with test performance: training과 다른 distribution을 갖는 dataset에 evaluation 했을 때 (즉, transfer learning을 했을 때), 그 loss 및 penalty는 training set의 결과와 강한 상관관계를 가짐 (sec 3.2.2)
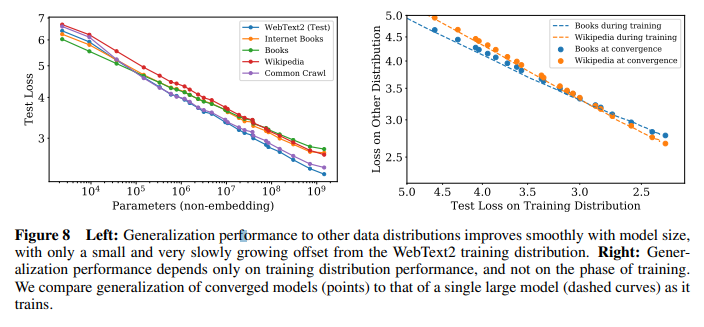
- (figure 8) WebText2에 대해서 학습하고 다른 data에 대해서 평가한 결과, model size가 커질수록 다른 data에 대한 performance 또한 개선됨을 확인
3. 모델 크기와 데이터셋의 적정 비율
- Universality of overfitting (모델 크기와 데이터셋의 비율): model parameter 과 dataset size 는 함께 상승시키면 예측가능한 범위 안에서 성능이 상승하지만, 하나를 고정하고 나머지 하나만 증가시키면 일정 지점에서 성능 하락이 발생함 (sec 4)
- 모델 크기와 데이터셋의 비율은 이며, 대략 모델 크기가 8배 증가하면 데이터셋 크기는 5배 증가해야 overfit이 없다는 얘기
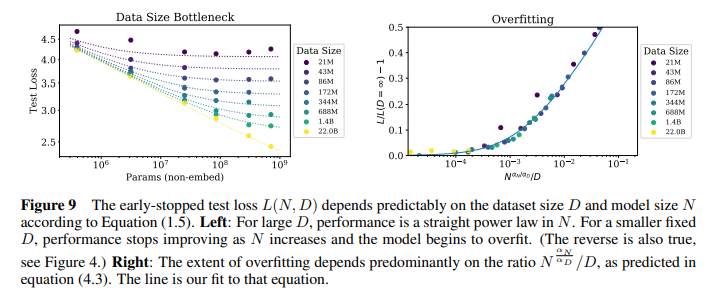
-
(figure 9 left) dataset size가 작을 때 parameter size만 무작정 늘리는 것은 performance에 bottleneck이 발생하고, overfit 발생
-
(figure 9 right) 데이터 크기에 비해 모델이 너무 크면 (x축이 오른쪽으로 움직이면) 과적합이 발생하기 때문에, 데이터의 크기에 적합한 모델 크기를 정해야 함
4. 최적의 배치 사이즈
-
Optimal batch size: 모델 학습 시 최적의 배치 크기는 loss의 power law에 따름 (sec 5.1)
-
최적 배치 사이즈 이하는 성능 하락에 크게 영향을 미치지 않지만, 배치 사이즈가 보다 크면 성능 하락이 크게 나타남
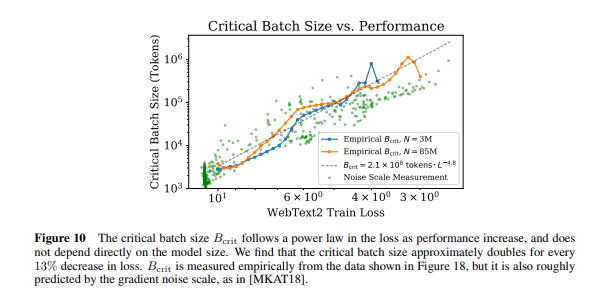
- (figure 10) 따라서, loss에 따라서 최적의 batch size를 조절해야 하는데, empirical result에 따르면 loss 13%가 줄어들 때 batch size는 2배로 증가함
# example code
def get_dynamic_batch_size(loss, base_batch_size, alpha):
return int(base_batch_size * (loss.item() ** alpha)
trainloader = DataLoader(dataset, batch_size, ...)
# run epoch 1
new_batch_size = get_dynamic_batch_size(avg_loss, base_batch_size)
# run new epoch5. 모델 크기와 학습 시간 간 scaling laws
- Universality of training: model size와는 별개로 training curve는 power-law를 따르는데, 학습이 더 길어질 때의 loss를 예측할 수 있음 (sec 5)
-
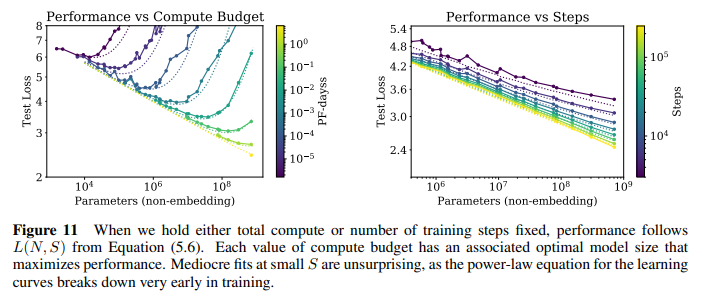
(figure 11) computing budget을 고정하거나 (left), training step을 고정할 때 (right), performance가 power-law를 따르는 것을 확인할 수 있음
-
이를 이용한다면, computing budget을 절약하기 위해 한정된 data size 하에서 적절한 step에서 early stopping이 가능함. figure 11 left를 참조할 때, parameter마다 가장 적절한 step이 존재함
6. Computing Budget의 최적 사용
- Convergence is inefficient: computing budget 가 고정되어 있고, model size 과 data size 에 별다른 제한이 없다면, 거대 모델을 사용하여 convergence가 이루어지기 전까지 훈련하는 것이 작은 모델을 사용하여 convergence가 이루어질 때까지 훈련하는 것보다 효과적이며, 데이터 크기 와 computing budget 의 관계는 과 같음 (computing budget 10배 증가 시 data size는 1.8배만 증가하면 됨) (sec 3 & sec 6)
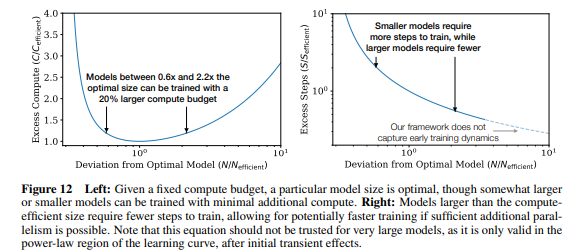
- (figure 12) optimal model size 주변을 보았을 때, optimal size부터 일부 구간 (0.6x ~ 2.2x) 까지는 computing budget의 증가가 크게 두드러지지 않으나, 해당 구간을 벗어나면 굉장히 큰 computing budget이 필요함 (left), 만약 모델 크기의 제한이 없다면 더 큰 모델에 대해 fewer step으로 학습하는 것이 빠르며, 작은 모델로 더 많이 학습하는 것보다 효율적임 (right)
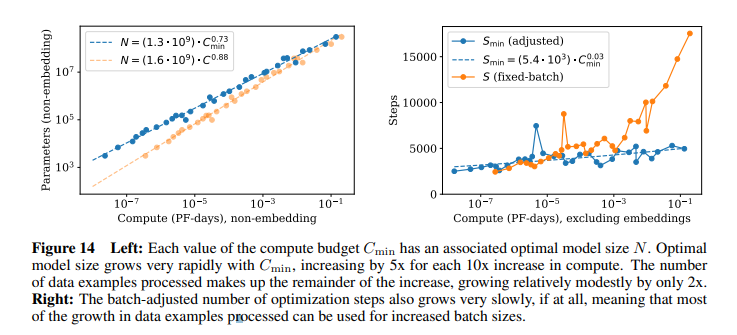
- (figure 14) 최적의 computing budget (C_{min}) 이 10배 증가할 때, model parameter는 5배, dataset은 2배 증가하면 최적의 computing budget allocation을 달성할 수 있음 (left) 반면, optimization은 조심스럽게 접근해야 하는데, computing budget을 증가시킬 때, batch size를 고정한다면 굉장히 많은 optimization step이 필요함. 따라서 computing size에 따라 적절한 optimal batch size를 설정해야 함
7. Sample Efficienty
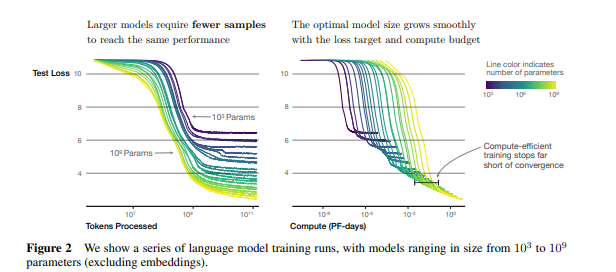
Sample efficiency: 큰 모델은 작은 모델보다 sample-efficient하며, 이는 optimization step이 적어도 & 적은 data를 사용함으로써 유사한 수준의 성능을 달성할 수 있다는 말임 (fig 2 & fig 4)
Possible Contradictions
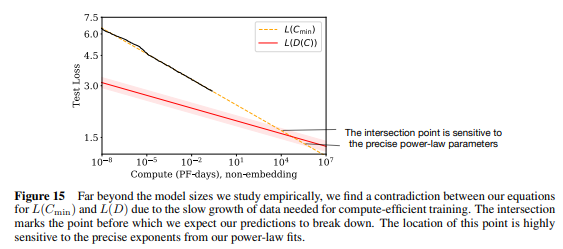
- (figure 15) computing power가 증가할 때 (yellow line), data size를 증가하면서 그려지는 plot(red line)과 만나게 되는데, 이 이후는 연구진의 식과 매치되지 않음
- 해당 point 이후로는 computing budget이 증가할 때, data size가 증가하더라도 성능 향상이 둔화되거나 멈출 수 있음
- 따라서, 새로운 power law를 제시해야 한다고 연구진은 주장
Pros & Cons
- NLP에서 Transformer architecture (decoder-only) 만을 사용했을 때 computing budget (), model parameter (), dataset size () 와 performance (CEloss로 표현되는) 와의 관계를 empirical하게 처음으로 제시
- 내가 가진 자원 하에서 다른 자원이 얼마나 필요한지, 얼마나 많은 training step이 필요한지 등을 예측할 수 있으므로 공수가 적어짐
- application: overfit 피하기 위해 1B 이하의 모델은 22B 가량의 토큰이 필요하며, 175B 모델 (GPT-3) 을 학습하기 위해 1044B 가량의 토큰이 필요
- 그럼에도, 이 law를 이용해서 실제로 학습한 LLM이 없다는 것은 한계 Chinchilla's Scaling Law
- 또한, 10B 이상의 LLM에 대한 실험이 없음: open-source로 70B 이상의 LLM이 기 존재한다는 것을 고려할 때, 이는 치명적으로 작동 Chinchilla's Scaling Law
More on Scaling Laws
패러다임은 얼마나 많은 데이터를 학습시킬 것이냐로 이동
Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers (2021)
- 진짜로 width와 depth는 상관이 없어? 라는 질문에서 시작
- OpenAI는 generation에 대한 loss (CEloss) 만을 측정했는데 (사실상 pretraining), 실제로 encoder-only 또는 encoder-decoder 모델에서는 pretrain & finetune pipeline으로 downstream task에 대응하므로, downstream task에 대한 성능 평가가 이루어져야
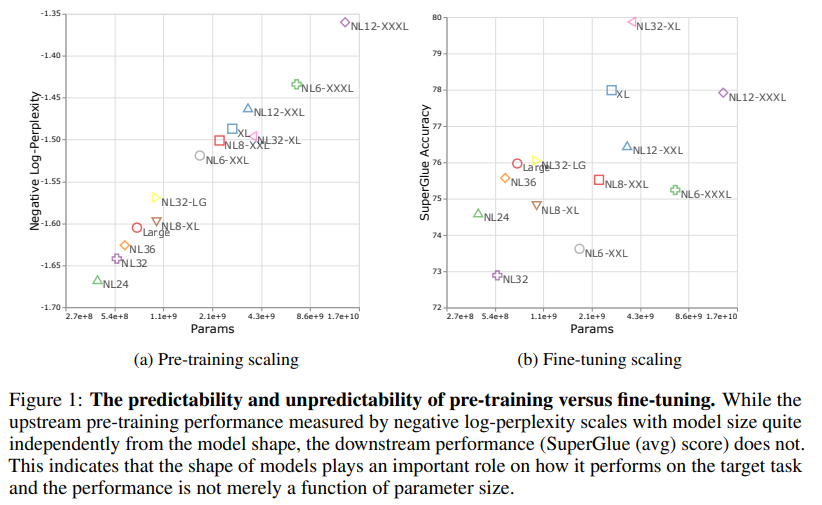
- T5에 대해 downstream task에 대한 성능 평가 upstream task (pretraining) 과 downstream task (finetuning) 사이에는 큰 차이가 없고, downstream task를 위해서라면 width와 depth도 고려해야
- vision domain (ViT) 에 대한 실험 추가
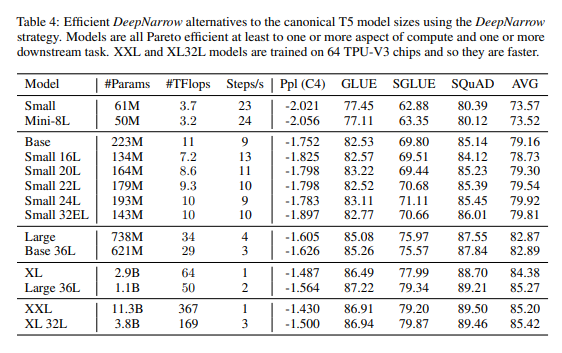
- LLM에 대해서는 pretrain-finetuning을 거의 사용하지 않으므로 out-of-scope라는 인상..
Unified Scaling Laws for Routed Language Models (ICML 2022)
- Mixture of Experts (MoE) 구조를 사용했을 때, performance와 experts의 수는 power-law를 따름
- 하지만, parameter size가 커지면 computational benefit이 감소
Training Compute-Optimal Large Langauge Models (NeurIPS 2022)
a.k.a. Chinchilla Scaling Law
- Google DeepMind의 Chinchilla 학습 과정에 관련된 논문
- 상단의 OpenAI의 scaling law에서 제시한 dataset size보다도 더 큰 규모의 데이터셋이 필요함을 역설

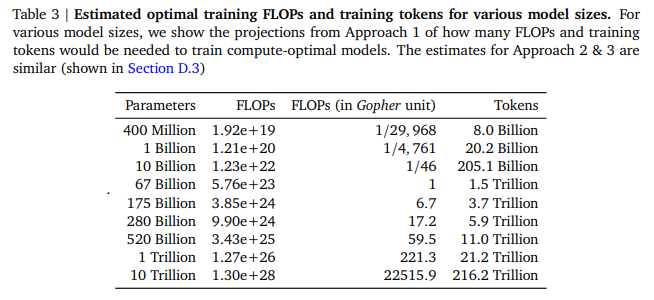
- (table 1, table 3) 1B 까지는 OpenAI의 scaling law의 dataset size와 유사하나, 10B 부터는 크게 차이남 (약 3.7배 가량)
- 실제로 70B 규모의 Chinchilla에 1.4tln 규모의 데이터셋을 학습시킨 결과, 4배 규모인 280B Gopher와 유사한 성능을 보임
- 하지만, OpenAI의 scaling law 3.7이 적절한 dataset size일지?
- LLaMA의 33B 모델은 1.4T token으로 학습했는데, Chinchilla 70B보다 더 좋은 성능을 기록
Appendix: training details
- training dataset: WebText2; 96GB 규모의 token ( words) 으로 이루어짐
- vocab size: 50257; byte-pair encoding을 이용해 tokenized
- loss averaged over 1024 token context
- 대부분 decoder-only architecture 사용
