[2024 LLM 스터디] 4. Pretraining
from "A Survey of Large Langauge Models (2024)"
Where are We now?
LLM의 학습은 3단계로 이루어짐: (1) Pretraining (2) Instruction Tuning (3) Alignment Tuning
- Pretraining: LLM이 기초적인 language understanding & generation skill을 학습할 수 있음
- Instruction Tuning: task 및 goal에 도달하기 위한 finetuning
'instruction': '양파는 어떤 식물 부위인가요? 그리고 고구마는 뿌리인가요?',
'output': '양파는 잎이 아닌 식물의 줄기 부분입니다. 고구마는 식물의 뿌리 부분입니다. \n\n식물의 부위의 구분에 대해 궁금해하는 분이라면 분명 이 질문에 대한 답을 찾고 있을 것입니다. 양파는 잎이 아닌 줄기 부분입니다. 고구마는 다른 질문과 답변에서 언급된 것과 같이 뿌리 부분입니다. 따라서, 양파는 식물의 줄기 부분이 되고, 고구마는 식물의 뿌리 부분입니다.\n\n 덧붙이는 답변: 고구마 줄기도 볶아먹을 수 있나요? \n\n고구마 줄기도 식용으로 볶아먹을 수 있습니다. 하지만 줄기 뿐만 아니라, 잎, 씨, 뿌리까지 모든 부위가 식용으로 활용되기도 합니다. 다만, 한국에서는 일반적으로 뿌리 부분인 고구마를 주로 먹습니다.',from KoAlpaca
- Alignment Tuning: human values & preference에 학습 (RLHF)
Why Pretrain?
- Pretrain corpus의 scale, quality에 따라 LLM의 능력이 결정됨
- Pretraining strategy: model architecture, acceleration methods (e.g. normalization, long-context adapting etc.), optimization technique 또한 잘 짜여져야 effective LLM pretraining이 가능함
이번 회차는 Pretraining Corpus & Pretraining strategy 중 model architecture까지!
Data Collection and Preparation
Data Source
- pretraining corpus는 general data와 specialized data로 양분될 수 있음
General Data
- webpage, boks, conversational text 등
- 특징: large, diverse & accessible
- Webpages: webpages를 crawl한 corpus임. high-quality text와 low-quality text가 공존하기 때문에 filter & processing phase를 거쳐서 data quality를 높여야 함 (e.g. CommonCrawl)
- Conversation text: conversational & QA capability를 향상하기 위해 사용됨. 하나의 대화 안에 복수의 주제가있는 경우, 각각의 주제로 대화를 나누는 preprocessing이 필요함. 단, dialogue data를 너무 많이 학습하면 지시문 (declarative instruction) 과 직접적인 질문 (direct interrogatives) 가 대화의 시작으로 잘못 인식되어 instruction을 줄 때 성능이 떨어질 수 있음. (e.g. PushShift.io Reddit corpus)
- Books: formal long text corpus로, 언어적 지식과 long-term dependency를 학습하기에 유용하며, narrative & coherent text 생성에 도움을 줄 수 있음 (e.g. Pile dataset 내부의 Books3, Bookcorpus2)
Specialized Text Data
- multilingual data, scientific data, code 등
- specialized capabilities (Galactica (science), Codegen) 향상을 위해 사용됨
- Multilingual text: BLOOM은 46, PaLM은 122개 language에 학습되었으며, FLM은 영어와 중국어를 동률로 학습. 번역, multilingual summarization, multilingual QA에도 사용되지만, multilingual reasoning을 학습해 target language에만 학습된 모델들과 비슷하거나 높은 성능을 보이기도 함.
- Scientific text: scientific task 뿐만 아니라 reasoning에도 효과가 있음. scientific text에는 arXiv 출판물, scientific textbooks, math webpages 등이 포함됨. 다만, 특수기호 때문에 tokenization과 다른 corpus와의 통합을 위한 format 처리에 품이 더 들어감.
- Code: PLM에 code data를 포함하려는 노력은 실패. LLM에 code data를 학습시켜 unit-test case(rubric에 따라 코드가 잘 짜여졌는지 확인; 아래 figure)나 competitive programming question(코테 결과물 중 어느 게 낫나?)에 대해 테스트하였음. 2가지 corpora가 많이 쓰이는데, programming QA community의 데이터 (e.g. Stack Exchange), public software repo (e.g. Github) 임. 다른 텍스트와 비교해, long-range dependency와 accurate execution logic이라는 특징이 두드러지는데, 이 때문에 complex reasoningabilities (e.g. CoT) 에 도움이 되고, 실제 사용 시 reasoning task를 code로 re-formatting 하는 게 더 높은 정확도를 뱉기도 함.
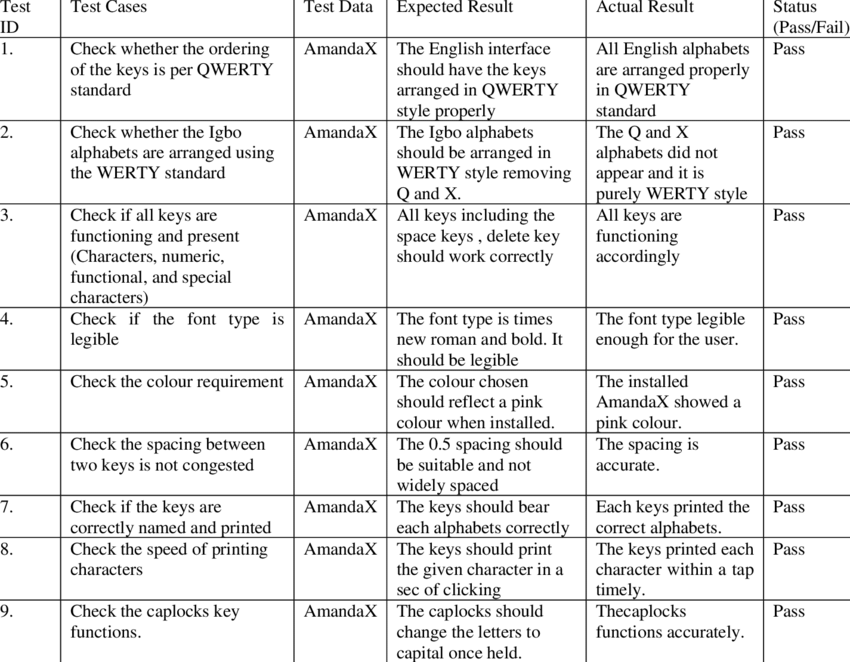
Data Preprocessing

Data Preprocessing은 (1) Quality Filtering (2) De-duplication (3) Privacy Reduction (4) Tokenization 으로 구성됨
LLM의 능력과 성능에 영향을 줄 수도 있는 noisy, redundant, irrelevant, potentially toxic data를 제거해야 함. 최근에는 "Data-Juicer"를 많이 쓰는데, 50개 이상의 processing operators & tools를 제공함.
(1) Quality Filtering
-
classifier-based: high-quality와 low-quality에 대한 classifier를 학습하여 분류하는 것으로, 방언으로 쓰여있거나, 구어체 (colloquial), sociolectal (유행어, meme 등) language까지 제거해서 LLM의 능력이 떨어지게끔 한다는 보고도 있음
-
heuristic-based: rule-based로, BLOOM이나 Gopher같은 모델의 학습에 사용
- Language based filtering: target language 제외한 다른 language text는 모두 제외
- metric based filtering: perplexity 등을 기준으로 하여 unnatural sentence를 제거
- statistic based filtering: punctuation distribution, symbol-to-word ratio, sentence length 등을 기준으로 cut
- keyword based filtering: HTML tag, hyperlink, boilerplates, offensive words에 대한 set을 만들어서 해당 keyword가 등장하면 지우는 것
(2) De-duplication
반복되는 텍스트는 LLM의 성능을 하락(Double Descent issue: 이후에 성능 향상이 있긴 하지만 학습 초반에 성능 하락; context에서 LLM이 내용을 copy하는 능력 하락해 ICL 능력이 나빠지는 등)시키므로, sentence, document, dataset-level의 de-duplication이 들어갈 때 LLM의 성능이 향상될 수 있음
- sentence level: low-quality sentence에는 반복되는 단어와 phrase가 등장하므로 이에 학습하면 LLM이 단어 또는 phrase를 단순반복할 수 있음
- document level: word overlap, n-grams overlap 등 surface feature의 overlap을 기준으로 similar contents를 식별하고 de-duplication 진행
- dataset level: training set과 test set 간 de-duplication
(3) Privacy Reduction
sensitive & personal information이 포함된 data (a.k.a. Personally Identifiable Information; PII) 가 포함되어 있을 수 있는데, 이는 privacy breach risk가 있음. 보통 rule-based approach를 사용해서 이름, 주소, 전화번호 등의 PII를 제거함.
(4) Tokenization
(Word-based Tokenization) CRF 등 이전 NLP task에서는 단어 단위로 tokenization을 진행하였으나, 중국어와 같은 일부 언어에서는 input이 같아도 segmentation이 다른 결과가 나올 수 있으므로 vocabulary 가 굉장히 커지고, OOV 문제가 있음
中国人民在银行前排队。중국 인민이 은행 앞에 줄을 서있다.
中国人民银行发布了新的政策。중국인민은행 (기준금리 결정하는 PBC) 이 새로운 정책을 발표하였다.해설: 첫 문장에서 中国人民과 银行을 각각의 단어로 분리하여 학습시키면 두 번째 문장의 中国人民银行에 대한 의미를 제대로 학습할 수 없음
(Advanced Tokenizers) word-based Tokenization의 한계를 타파하기 위해 character-based tokenization이 등장하였고 (ELMo에서는 character 단위로 자르고 CNN으로 character의 의미를 word로 합성하였음), 마지막으로 subword tokenizer가 등장하여 널리 사용되고 있음
- Byte-Pair Encoding (BPE) tokenization: 먼저 Byte 단위로 나누고, 자주 등장하는 byte을 merge해서 토큰으로 만듦. merge의 stop 조건은 merged token의 길이가 사전지정한 길이에 도달할 때까지. non-ascii letter 포함 가능하며, GPT-2, BART, LLaMA 등에 사용됨
preset
corpus (단어, 빈도): ("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)byte level로 나누기
기본 vocab: 'h', 'g', 'h', 'n', 'p', 's', 'u'merging
기본 vocab 중 가장 빈번한 pair는 'u' & 'g'
따라서 'u'와 'g'를 병합
modified vocab: 'b', 'g', 'h', 'n', 'p', 's', 'u', 'ug'사전설정한 길이에 도달할 때까지 위를 반복
- WordPiece tokenization: BPE와 유사. 바이트 단위로 나눈 후 모든 가능한 쌍을 점수화하여 merge 했을 때 가장 likelihood가 높은 pair에 대해서 merge하게 됨. 자세한 사항은 Google 내부 모델이라 불명.
preset
corpus (단어, 빈도): ("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)byte level로 나누기
기본 vocab: ('h' '##u' '##g', 10), ('p' '##u' '##g', 5), ('p' '##u' '##n', 12), ('b' '##u' '##n', 4), ('h' '##u' '##g' '##s', 5)
초기 vocab set: 'b', 'h', 'p', '##g', '##n', '##s', '##u'merging
'##u' '##g'의 쌍이 20회로 가장 많지만, '##u'는 다른 vocab과 쓰인 경우도 많음 ('##n' 등)
대신, '##g'와 '##s'는 항상 함께 등장하므로 이 둘을 병합
modified vocab: 'b', 'h', 'p', '##g', '##n', '##s', '##u', '##gs'사전설정한 길이에 도달할 때까지 위를 반복
- Unigram tokenization: BPE나 WordPiece는 작은 단위에서 큰 단위로 올라가지만, Unigram은 큰 단위에서 작은 단위로 내려감.
현재 vocab 기준 (preset vocabulary) 으로 corpus의 loss를 계산 후, vocab에서 토큰을 하나씩 제거하여 전체 loss가 얼마나 증가할지 계산, 가장 적게 증가하는 token을 제거. hyperparameter p%에 도달할 때까지 loss가 낮은 (==별 의미 없는) token을 제거
T5, mBART에서 sentencepiece tokenization으로 사용. more on https://process-mining.tistory.com/190
preset
corpus (단어, 빈도): ("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)substring로 나누기
기본 vocab: ('h', 'u', 'g', 'hu', 'ug', 'p', 'pu', 'n', 'un', 'b', 'bu', 's', 'hug', 'gs', 'ugs')vocab update
'p'+'u'+'g'의 확률과 'pu'+'g'를 사용했을 때의 loss를 비교: 0.000389 vs 0.0022679
loss가 작은 'p', 'u', 'g'는 버려지고 'pu'와 'g'가 선택되어 vocab update사전 설정한 hyperparameter p%까지 token을 버림
BPE와 WordPiece tokenizer를 사용할 때, pretraining corpus를 보고 token이 정해지기 때문에 continual pretraining 시에 LLM의 퍼포먼스 하락이 있을 수 있음. 예컨대, English corpus에 적용된 tokenizer를 사용해서 LLM pretraining 한 뒤 중국어에 continual pretraining 하면 LLM 학습이 잘 안 됨.
BPE 이후에 성능을 위해 normalization (e.g. NFKC) 을 하기도 하는데, LLM의 경우에는 performance degradation이 있다는 점에 유의.
Data Scheduling
pretraining corpus를 모델한테 어떻게 잘 줄 것이냐의 문제. 학습 데이터를 잘 섞는 data mixture, 다음 학습 때 어떤 데이터를 줄 것이냐 하는 data curriculum의 문제가 있음.
Data Mixture
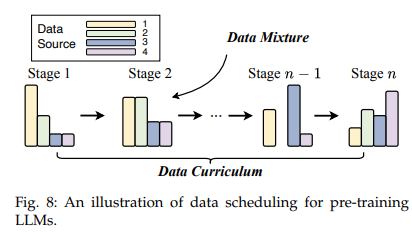
global level의 data source proportion을 추종해서 각 batch마다 data source proportion을 설정할 수 있음. 여기에 LLM 목적에 따라 upsampling & downsampling 진행.
-
Increasing the diversity of data sources: webpage 등 source 내부의 data heterogeneity가 높은 data source를 없앴을 때, LLM의 generalization capability가 하락하여 downstream performance 또한 나빠진다는 보고.
-
Optimizing data mixtures: DoReMi (NeurIPS 2023) 모델에서는 target task가 정해진 상태에서 small LM을 먼저 학습시켜서 target에 가장 적합한 pretraining corpus를 알아서 선택해 LLM을 학습시킨다는 접근을 사용.
Data Curriculum
LLM이 basic skill을 먼저 학습하고, target skill을 학습하는 게 효과적이므로 data curriculum을 잘 설정해야 함. easy & general example을 먼저 주고, challenging & specialized example을 그 다음에 학습시키는 방식으로 보통 진행. 실제로는, 학습 과정에서 key ability에 대한 specialized benchmark 성능을 확인하고, 그에 따라 data mixture를 재진행하는 형식.
- Coding
- LLaMA 2: 2T general tokens 500B code-heavy tokens
- CodeLLaMA-Python: 2T general tokens 500B code-heavy tokens 100B python-heavy tokens
- Mathematics
- Llemma (CodeLLaMA 기반의 수학 능력 향상 LLM): 2T general tokens 500B code-heavy tokens 50~200B math-heavy tokens. 단, regularaization 위해 5% 가량의 general data 도 들어감
- Long Context
- LLaMA 2: 2.5T general tokens with 4k context window 20B tokens with 10k context window
- LongLLaMA: 1T general tokens with 2k context window 10B tokens with 8k context window
Architecture
roughly, encoder-decoder, causal decoder, prefix decoder 모델로 나눌 수 있겠음. 3개 모델 외에도 parameterized state space models, long convolutions, transformer와 rnn을 합친 RWKV 등의 architecture가 제시되고 있음.
Typical Architectures
transformers recap
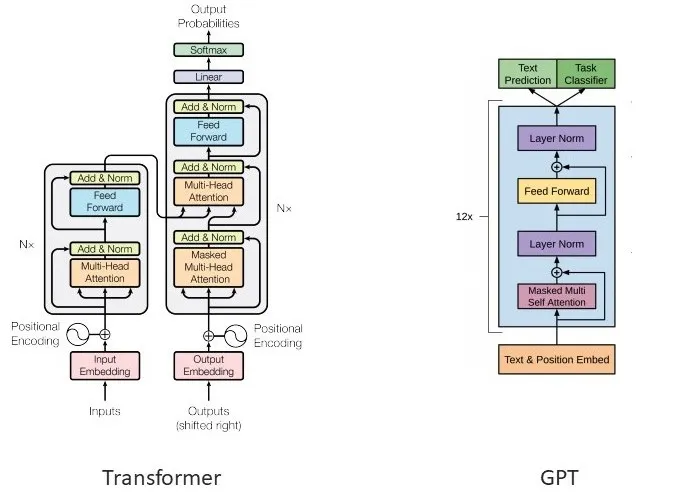
- input embedding: token을 embedding matrix 이용해 embedding으로 변환
- positional encoding: self-attention은 단어가 어떤 순서로 들어오든 같은 것으로 이해함 (permutation equivariant). 따라서, 단어의 순서에 대한 정보를 부여하기 위해 positional encoding 이 더해짐
- Encoder Block
- multi-head self-attention: 각 token이 sequence 내에 모든 단어에 대해 (self-attention) 다각도로 정보를 학습 (multi-head)
- feed forward network: ReLU (recently SwiGLU) 등 activation function을 적용
- add & norm (residual module): gradient vanishing problem (gradient가 점점 작아지면서 선행 layer가 학습이 안 됨) 을 완화
- Decoder Block
- masked multi-head attention: 생성코자 하는 token 뒤의 token들을 masking하여 sequence 앞쪽에만 attention을 줌 (미래 정보 치팅 방지)
Encoder-decoder architecture
encoder는 self-attention을 이용해 input text를 이해하여 latent representation으로 생성하고, decoder는 cross-attention을 이용하여 target sequence를 생성하는 transformer의 기본원리. T5, BART 등 encoder-decoder 기반의 PLM이 있긴 하지만, LLM은 굉장히 적음 (Flan-T% 정도)
Causal Decoder Architecture
decoder architecutre만을 사용한 대부분 LLM의 architecture
unidirectional attention을 적용한 causal decoder architecture와는 달리, bidirectional architecture를 적용. 다음에 생성해야 하는 token의 이전 token들을 bidirectional 하게 참조한다는 것이 causaul decoder와의 차이점
일부 weight만 활성화해서 처리하는 방식. MoE를 사용했을 때 computational cost를 고정하면서 모델 크기를 키울 수 있으며, expert의 수가 늘어날수록 성능이 향상된다는 장점이 있음. 하지만 routing operation과 hard switching 때문에 instability issue가 있음
Wrap-up
- Pretraining을 위한 Data Curation 작업 (Data Collection & Preparation) 과 Model Architecture Selection에 대해 살펴보았음
- 우리가 LLM을 pretrain할까? 글쎄.. 하지만 continual pretraining은 할 수도 있다는 점 + lightweight LM을 만들 때에도 data에 대한 고려는 필요하다는 점에서 pretraining data 파트, 특히 data curation이 아예 의미없지는 않음
- 대부분 LLM이 Causal Decoder Model이기는 하지만, training & inference efficiency 때문에 MoE 또한 많이 사용되고 있음 (e.g. Mistral 7B와 Mistral 7B 8에 sparse-MoE를 적용한 Mistral 8x7B). 따라서 다양한 architecture, 특히 MoE에 대한 이해를 다지는 것이 향후 논문 리딩에 도움이 되겠음

친절한 설명 감사합니다:)