What is LLM Utilization?
- pretraining 및 adaptation tuning (instruction tuning & alignment tuning) 이후의 step
- various tasks를 수행하기 위해 prompting strategy를 잘 사용하여야 함
- 대표적인 prompting strategy
- Prompting: task-specific prompt를 구성하기 위해 manual creation 또는 automatic optimization 을 이용
- In-Context Learning: task description 및 demonstration을 natural language text로 제시하는 것
- Chain-of-thought prompting: ICL을 향상하는 방안으로, 복수의 intermediate reasoning step을 추가하는 것
- Planning: complex task를 해결하기 위해 하나의 큰 task를 복수의 subtask로 쪼갠 후, sub-task를 하나씩 해결하는 action plan 을 생성하는 것
Prompting
Prompt Creation
manual prompt creation 은 prompt engineering 이라고도 불림
Key Ingredients
- 4 key ingredients: task description, input data, contextual information, prompt style

- Task description:
- LLM이 따라야 하는 specific instruction
- input output이 special format을 갖고 있는 경우, 자세한 clarification이 필요
- keyword를 사용해 special setting을 강조하거나 LLM의 task completion을 더 잘 가이드할 수 있음
- Input data:
- LLM의 input을 의미
- 보통 자연어로 표현되지만, knowledge graph나 표와 같이 special input data인 경우 다른 조치가 필요함
- structured data의 경우, simplicity를 추가하기 위해 linearization (component를 순차적으로 제시하는 것) 을 적용하거나, programming language 를 사용하기도 함
- Contextual information:
- task description과 input data와는 별개로 contextual 또는 background information 을 줄 수 있음
- e.g. document retrieval, in-context exemplars
- task goal을 더 잘 설명하거나, special output format, input과 output 사이의 관계를 더 잘 매핑함
- Prompt style:
- prompt를 짧은 clear question으로 작성하거나, detail instruction으로 작성할 수 있음
- prefix나 suffix를 추가할 수도 있겠음
- prefix 예시: "Let us think step by step", "You are an expert on this task (or in this domain)"
- 길거나 어려운 task를 한 번에 주는 대신, sub-task로 multiple prompt를 decompose한 뒤 multi-turn conversation으로 original taks를 해결할 수 있음
Design Principles
- Expressing the task goal clearly
- Decomposinginto easy, detailed sub-tasks
- Providing few-shot demonstrations
- Utilizing model-friendly format: e.g.
###or"""as a stop symbol to separate the instruction and context - and other useful tips
Prompt optimization
- prompt를 손수 만드는 것 대신 automated prompt creation 하는 것
- discrete prompt와 continuous prompt creation으로 나눌 수 있겠음
- discrete prompt optmization: 자연어로 작성된 prompt
- Gradient-based approaches: Auto-Prompt etc.
- RL-based approaches: discrete prompt creation은 gradient backprop으로는 학습이 어려우므로 제안된 approach. RLPrompt, TEMPERA etc.
- Edit-based approaches: 큰 모델이나 api에서는 사용이 불가능하므로 나온 approach. GPS etc.
- Continuous Prompt Optimization: LLM에 접목한 시도는 많이 없음
- Prompt learning with sufficient data: Prefix Tuning, P-tuning, context tuning etc.
- Prompt transferring with scarce data: SPoT etc.
In-Context Learning
Demonstration Design
Demonstration Selection
- 예시로 제시하는 것들에 따라 ICL의 결과가 많이 달라짐
- Heuristic approaches: knn-based retrieval etc.
- LLM-based approaches: BM25 dense retriever approach etc.
Demonstration Format
- 예시 및 demonstration을 어떻게 잘 줄 것이냐의 문제
- AutoPrompt, least-to-most prompting etc.
Demonstraton Order
- LLM에 recency bias (근처에 있거나 가장 끝의 demonstration을 반복하는 것) 이 있으므로 example의 순서를 잘 주는 것
Underlying Mechanism
How Pretraining affects ICL?
- large model에서만 가능한 것은 아니고, pretraining 및 finetuning을 speially designed training task에 적용하면 small model에서도 ICL이 가능하므로, training task에 따라서 ICL의 능력이 확보되는 것으로 보임
- long-range coherence나 compositional structure에 대한 NSP를 학습하면서 확보된다고 보기도
How LLMs Perform ICL?
- task recognition: LLM은 task description으로부터 새로운 task를 해결하기 위해 prior knowledge를 사용한다는 것 (learning이 아니라 recognition) 으로 보임 (Probably aApproximately Corrrect framework)
- task learning: unseen task에서는 forward computation을 통해 implicit gradient descent를 수행한다는 관점
- task recognition은 350M 정도의 LM으로도 가능하지만, task learning은 66B 정도는 되어야 가능
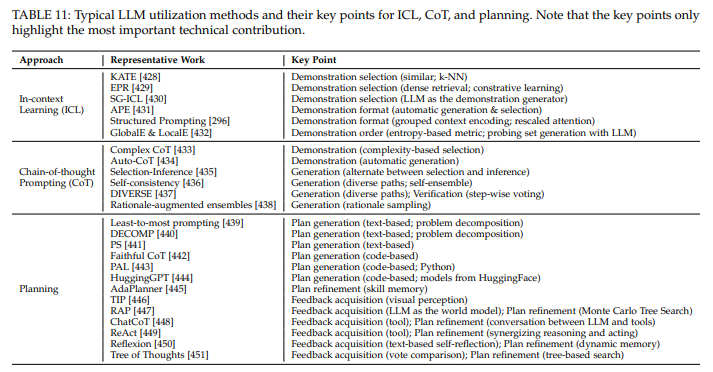
Chain-of-Thought Prompting
complex task를 수행하기 위해 단순히 예제를 넣는 대신 intermediate step을 추가하는 방식
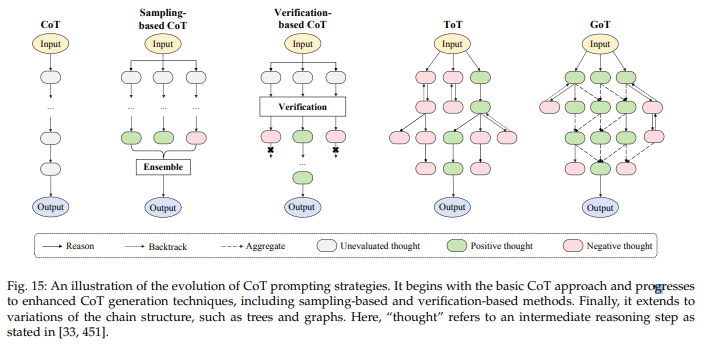
Basic CoT prompting Approach
- "Let's Think step-by-step"
- "Take a deep breath and work on this problem step-by-step"
Improved CoT Prompting Stretegies
Enhanced CoT Generation
- reasoning step에서의 부정확성과 generation process에서의 instability가 제기됨
- sampling-based methods: 하나의 reasoning path 대신 multiple reasoning path 사용. self-consistency, k-most complex reasoning path sampling, MCR etc.
- verification-based methods: 각 단계에서 문제가 없는지 확인. DIVERSE etc.
Reasoning Sturcture Extension
- "더 어려운" task를 수행하기 위해 CoT reasoning structure의 개선 진행
- Tree structured reasoning: ToT, TouT etc.
- Graph-structured reasoning: GoT, XoT etc.
Further Discussion on CoT Prompting
- When CoT Prompting Works for LLMs?
- 10B 이상의 LLM에서만 사용 가능
- standard prompting이 낮은 성능을 기록할 때에만 사용 가능
- Why LLMs can Perform CoT Reasoning?:
- code data에 대한 학습 & instruction tuning의 영향이라고 보는 듯
- pattern & text는 performance에 큰 영향을 주지만, symbol & pattern은 그다지 critical하지 않으며, text는 useful pattern 생성에 도움을 주고 LLM이 task를 해결하는 데에 도움을 주게 됨
Planning for Complex Task Solving
math나 multi-hop QA 같은 경우 planning으로 원래의 task를 더 작은 subtask로 나누는 경우가 필요할 수 있음
The Overall Framework
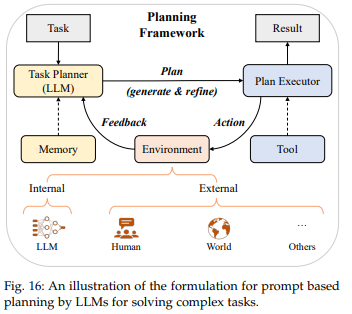
- components: task planner, plan eeexecutor, environment
- task planner: target task를 위한 whole plan을 생성하는 LLM (natural language, programming language 등으로 표현)
- plan executor: LLMs for textual task, code interpreter tool etc.
- environment: plan executor가 실제로 구동되는 환경이자 task planner에게 feedback을 제공하는 환경, LLM이 되거나, external virtual world (e.g. Minecraft) 가 되기도 함
Plan Generation
- text-based approaches: Plan-and-Solve, DECOMP, Self-planning, Toolformer etc.
- Code-based approaches: 확실한 plan execution을 위해 code를 사용. FaithfulCoT, PAL, PROGPROMPT, LLM+P etc.
Feedback Acquisition
- internal feedback: LLM 자체를 feedback provider로 사용. RAP, Reflexion etc.
- external feedback: programming code를 사용할 경우.
Plan Refinement
- feedback을 받아 수정하는 과정
- Reasoning: feedback으로부터 critical info를 추출하는 과정. React, AuoGPT, ChatCoT etc.
- Backtracking: short term 관점에서 local optimal plan 수정. DEPS, TIP etc.
- Memorization: long-horizon task 관점에서 feedback 반영 (vectorDB 사용 등). Reflexion, MemoryBank etc.

multidisciplinary