Abstract
- bi-LSTM + Conditional Random Field(CRF)을 sequence tagging에 적용한 첫 번째 연구
- bi-LSTM을 이용해 과거와 미래의 정보를 모두 이용하고, CRF를 이용해 문장 전체의 tag information을 이용할 수 있음
- bi-LSTM + CRF model이 POS, chunking, NER dataset에 대해 SoTA 달성
- 위 모델은 robust & less dependent on word embeddings
1. Introduction
Sequence Tagging이란?
- Part of Speech tagging(POS), chunking, Named Entity Recognization(NER) 등을 포함하는 개념으로, classic한 NLP task임
- sequence tagging의 결과물이 downstream task로 이어질 수 있는데, NER tagging의 결과물을 이용해 search engine에서의 성능을 향상시킬 수 있음
Existing Sequence Tagging Models
- linear statistical models: Hidden Markov Models(HMM), Maximum Entropy Markov Models(MEMMs), Conditional Rnadom Fields(CRF)
- 참조: http://www.cs.columbia.edu/~mcollins/crf.pdf - CNN based model(+CRF): sequence tagging에 좋은 성과
덧) 본 논문은 CNN-CRF를 제안한 collobert et al., 2011에 많은 영향을 받음
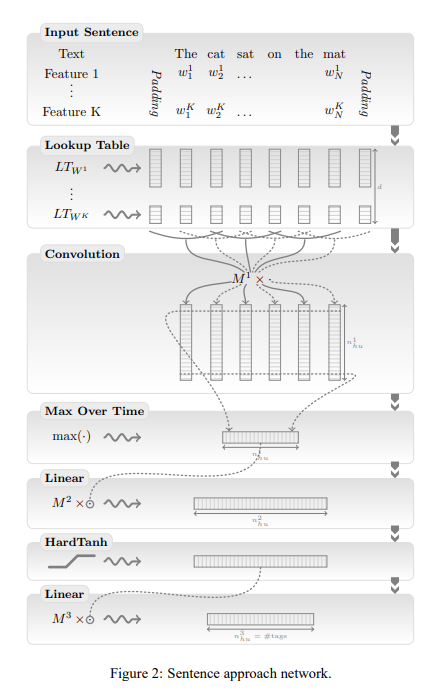
보론: Previous Sequence Tagging Models(HMM, MEMM, CRF)
Hidden Markov Models(HMM)
- reference: https://lovit.github.io/nlp/2018/09/11/hmm_based_tagger/
- Markov Model은 이전 state만으로도 현재 state를 추론할 수 있음을 보인 것(
- Hidden Markov Model은 state()가 숨겨져 있고, observation()으로 state를 추론하는 문제!
- e.g. 아이스크림 판매량()만으로 날씨()를 추정하기, 실제 단어 sequence()만 보고 sequence의 품사()를 추측하기 - HMM: sequence 에 대해 가 가장 큰 을 찾는 것
- 여기서 x는 단어, y는 label을 뜻함
- HMM에서 label 의 우도(likelihood)를 계산하기 위해 사용되는 것은 와 (first-order HMM) 또는, 추가로 (second-order HMM)
- 예시: 아이스크림의 판매량을 보고 날씨 추정하기 https://ratsgo.github.io/machine%20learning/2017/03/18/HMMs/
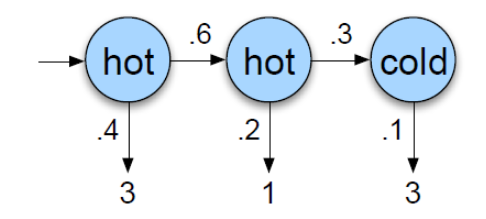
실제로 label 안에 있는 것은 hot인지 cold인지 모르고, 연쇄 연산을 통해 가장 likelihood가 높은 state의 집합을 최종적으로 선택하게 됨
state() 간 연결되는 확률을 transition probability(전이 확률), state()에서 observation()로 이어지는 확률을 emission probability(방출 확률)이라고 하며, 실제로는 matrix로 표현됨
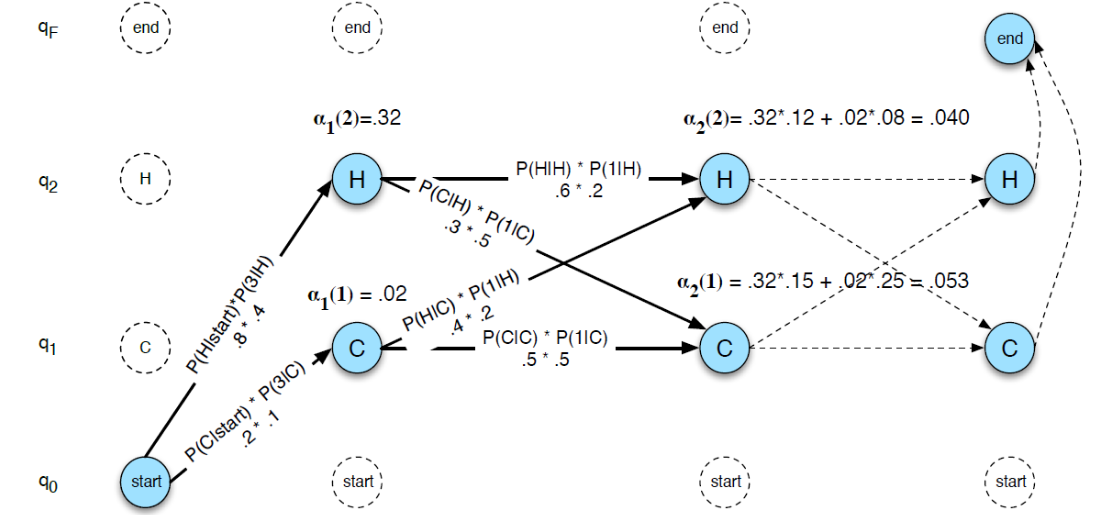
그런데 수많은 경우의 수 중 가장 likelihood 높은 것을 선택하려면 동적 프로그래밍이 강제됨: viterbi algorithm (이는 MEMMs나 CRF에서도 동일하게 사용됨) - 단점: Ungaranteed Independency Problem
'나는 말하는 감자다'
: 나 는 말하 는 감자 다
: [명사][조사] [동사][어미] [명사][어미]
'는(, observation)'에 해당하는 품사(, state)인 '어미'를 예측하기 위해 사용되는 것은 이전 state의 인 '동사'뿐이 없음!
'어미()'의 observation()인 '는'는 에서 '방출되는' observation으로, likelihood를 계산하기 위해 사용된 것이지, 가 로 타고 올라가는 루트는 없다는 것!
우리가 품사를 추측할 때 실제로 사용하는 것은 이전 낱말의 품사도 있지만, 그 '낱말()'이 무엇이냐도 큰 비중을 둠
결국 '단어 간의 직접적 관계'가 누락되었다는 얘기!
Maximum Entropy Markov Model
- reference: https://ratsgo.github.io/machine%20learning/2017/11/04/MEMMs/
- 번째 state 과 번째 observation 의 feature를 이용해 번째 state 를 추측하는 것
- feature에는 낱말의 가장 앞글자, 어미 등이 사용됨
- 단점: label bias(HMM도 공유)
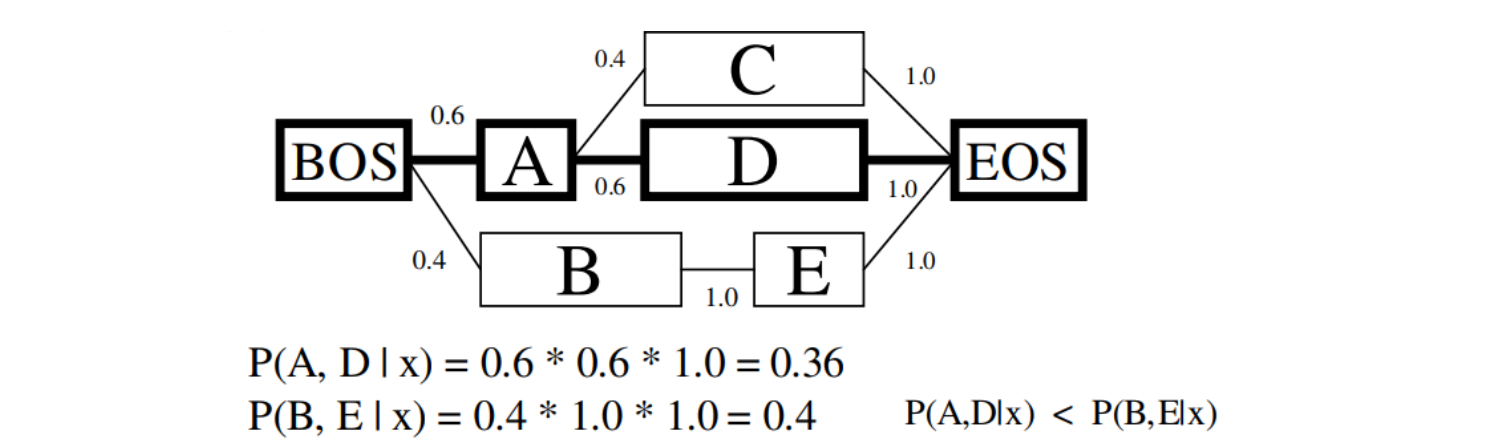
A의 frequency가 높은 탓에 여러 가지가 생겨 오히려 sparse 하게 등장하는 <B, E> 보다 실제 답안인 <A, D>의 likelihood가 더 작은 문제 발생!
Conditional Random Field
-
reference: https://lovit.github.io/nlp/machine%20learning/2018/04/24/crf/
-
unguaranteed independency problem & label bias HMM, MEMM 모두 '지엽적'인 정보만을 사용했기 때문, CRF는 이를 극복하기 위해 등장
- unguaranteed independency problem의 극복방안: state 를 예측하기 위해 사용될 수 있는 observation 의 범위를 늘리자!
- label bias의 극복방안: sequentially sequence tagging softmax 진행하지 않고, 전체 sequence의 tagging sequence 집합에서 softmax를 진행하자
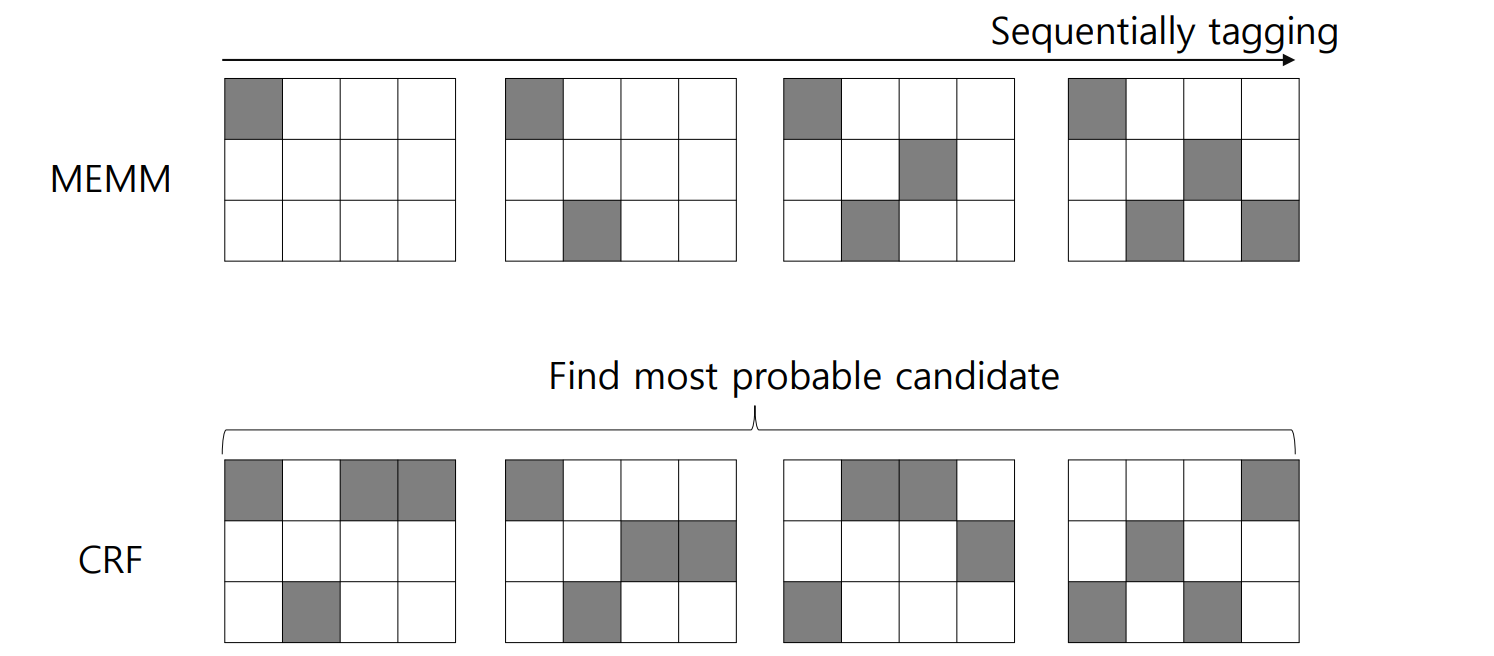
-
HMM 기반 모델이 sequence length만큼 순차적으로 softmax를 적용한다면, CRF는 sequence에 대해 한 번의 classification을 진행함
- 그러나 계산상의 문제로 인해 실제로는 가장 가능성 있는 후보 몇 개만 추려서 그 중에서 softmax를 진행함.. -
최근까지 sequence tagging의 선두주자는 CRF를 결합한 모델들이었음
In this Paper...
- 여러 sequence tagging model 제안: LSTM, bi-LSTM, LSTM+CRF, bi-LSTM+CRF
- contribution
- NLP tagging dataset에 대해 상술한 모델들을 적용하여 성과 측정
- bi-LSTM-CRF를 NLP benchmark sequence tagging dataset에 처음으로 적용: bi-LSTM으로 과거와 미래의 정보를 전부 다 열람, CRF로 문장 내의 모든 tag를 참조할 수 있음
- 상술한 모델들은 POS, chunking, NER dataset에서 SoTA를 갱신하거나, 근접한 성능 기록
- bi-LSTM-CRF 모델이 robust, less dependent on word embedding을 보임: 좋은 성능 보였던 종전의 CNN-CRF에 비해 개선됨
Models
LSTM Networks
- RNN based architecture는 history information을 저장하므로 long distance feature를 사용해 current output을 예측할 수 있음
- input layer는 one-hot-encoding이 될 수도, dense vector feature, sparse feature 모두 가능하며, input layer는 feature size와 same dimensionality
- output layer는 label size와 same dimensionality
- fc layer와 비교하여, RNN은 previous hidden state와 current hidden state의 연결이 있다는 게 다른 점
- LSTM은 hidden layer가 memory cell(input gate, forget gate, output gate, cell vector가 포함됨)을 거침으로써 long range dependencies에 더 강점을 보인다는 것
bi-LSTM Networks
- sequence tagging에 있어서는 해당 단어 주위의 단어들을 종합적으로 고려해야 하는데, 그러므로 bi-LSTM이 적합
CRF networks
- sequence tagging에는 크게 2가지가 있음
- 하나는 단어 단위: probability distribution + beam search
Maximum Entropy Classifier, Maximum entropy Markov Models(MEMMs) 등
- 하나는 문장 단위: CRF이나, vanilla CRF는 input과 output이 직접 연결되어 있으므로 중간에 memory cell이 껴있는 LSTM과는 다름
CRF가 보통 더 좋은 accuracy라고 함
LSTM-CRF networks
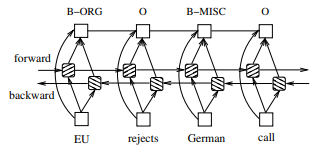
3. Training Procedure
- SGD 사용, batch size 100
- bi-LSTM을 거쳐 나온 output score 는 모든 위치의 tag에 대한 score임
- output score를 CRF layer를 bidirectional로 계산하여 state transition matrix update하고 backward pass하여 parameter update
4. Experiments
4.1 Data
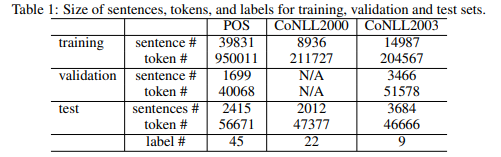
- 모델은 총 4가지: LSTM, bi-LSTM, LSTM-CRF, bi-LSTM-CRF
- task는 총 3가지: Penn TreeBank(PTB) POS tagging, CoNLL 2000 chunking, CoNLL 2003 named entity recognition
- POS는 문법요소 tagging
- chunking은 phrase를 tagging하는 것(B-NP: beggining of noun phrase)
- NER tagging은 중 1가지 entity type을 맞추는 것
- BIO2 annotation standard를 chunking & NER task에 사용
- BIO2 annotation이란?: B(Beginning)-I(Intermediate)-O(Outside)를 PER/LOC/ORG 앞에 달아줌으로써 NER/chunking을 효과적으로 진행할 수 있게 함
e.g. Alex is going to Los Angeles in California
-> Alex(B-PER) is(O) going(O) to(O) Los(B-LOC) Angeles(I-LOC) in(O) California(B-LOC)
참조: https://en.wikipedia.org/wiki/Inside%E2%80%93outside%E2%80%93beginning_(tagging)
4.2 Features
- 3개 datset에 대해 seplling features, context features 추출
- POS: 401k, chunking: 76k, NER: 341k features 추출
- features들과 word embedding을 사용하면서 점진적 성능 향상을 발견
4.2.1 Spelling Features
- 단어에 대해 다음 feature를 추출
- lower case로 바꿨을 때의 feature
- 대문자로 시작하는가?
- 전부 대문자인가?
- 전부 소문자인가?
- 첫 글자가 아닌 위치에 대문자가 들어가는가?
- 문자와 숫자가 섞여있는가?
- 문장부호가 있는가?
- window size를 2-5로 설정했을 때 prefix나 suffix가 있는가?
- apostrophe가 있는가? ('s)
- 문자만 들어가게끔 바꿨을 때의 feature (I.B.M을 IBM으로 변경)
- 문자가 아닌 글자만 들어가게끔 바꿨을 때의 feature(A.T.&T.를 ..&.로 변경)
- 원 단어를 word pattern으로 바꿨을 때의 feature: 대문자는 A, 소문자는 a, 숫자는 0으로 pattern 지정(D56y를 A00a로 수정)
- word pattern을 간략하게 수정했을 때의 feature: 반복되는 같은 word pattern은 제거(A00a를 A0a로 수정)
4.2.2 Context Features
- 기본적으로 unigram & bigram features 사용
- POS tagging을 위한 CoNLL2000 dataset, POS & chunking을 위한 CoNLL2003 dataset에는 unigram, bigram & trigram 사용
4.2.3 Word Embedding
- vocab size 130k, 50 features embedding matrix 사용
- https://ronan.collobert.com/senna
4.2.4 Features Connection Tricks
- 한 단어에 대해 word feature(word embedding), spelling features, context features가 모두 삽입됨
- spelling features와 context features의 경우 output에 직접 연결될 때 training time 줄고 accuracy는 비슷하게 유지한다는 점 발견
- 위 구조는 Maximum Entropy features와 비슷하다고 함
4.3 Results
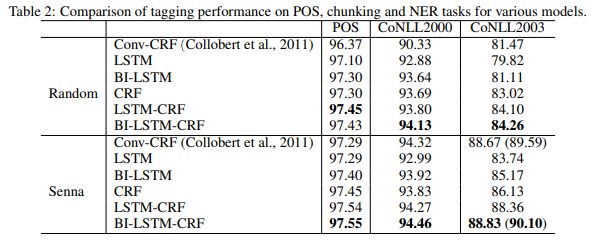
- word embedding의 경우 random, senna 두 가지를 실험함
- lr 0.1, hidden layer size는 300으로 설정했지만, hidden layer size에 not so sensitive, 모델 공통적으로 10 epochs면 convergence에 충분
- POS tagging은 word 단위의 accuracy로 측정, chunking & NER tagging은 chunk 단위의 F1 score로 측정
4.3.1 Comparison with Conv-CRF networks
- LSTM, bi-LSTM, CRF를 비교
- LSTM은 3가지 task 모두에서 weakest
- bi-LSTM은 POS와 chunking에서 CRF와 비슷했으나, NER에서는 CRF보다 낮음
- CRF는 3가지 task 모두에서 strong baseline을 형성
- random word embedding 사용시, CRF가 3가지 task 모두에서 Conv-CRF를 능가
- Senna embedding 사용시, CRF가 POS에서는 Conv-CRF보다 높은 성능, chunking과 NER에서는 낮은 성능 기록
- LSTM-CRF 모델은 random embedding 사용하든, senna embedding 사용하든 상관 없이 모든 task에서 CRF보다 높은 성능 기록하였음
- bi-LSTM_CRF 모델은 어떠한 embedding & 어떠한 task에서든 LSTM-CRF보다 높은 성능을 기록했으나, random embedding & POS에서만은 LSTM-CRF보다 미묘하게 낮은 성능(0.02%)
- bi-LSTM-CRF는 embedding에 덜 dependent
- POS: 0.12% vs 0.92%, chunking: 0.33% vs 3.99%, NER: 4.57% vs 7.20%
4.3.2 Model Robustness
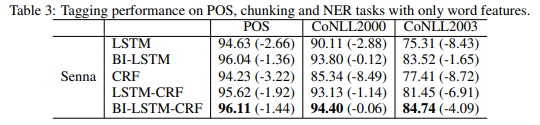
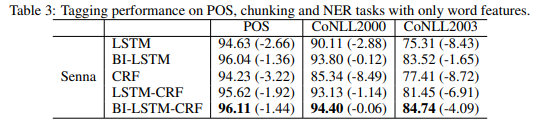
- Senna word embeddings만 사용하여 LSTM, bi-LSTM, CRF, LSTM-CRF, bi-LSTM-CRF 모델을 학습
- word embeddings, spelling features, context features 모두 사용한 모델의 결과와 비교하였음
- 결과1: CRF의 성능저하가 두드러짐 == CRF의 'engineered features'에 대한 dependency가 강조됨
- 결과2: LSTM based models(bi-LSTM, bi-LSTM-CRF)의 경우 engineered features에 대한 dependency가 감소함
- 결과3: 세가지 task에 대해 bi-LSTM-CRF가 highest accuracy 기록
4.3.3 Comparison with existing systems
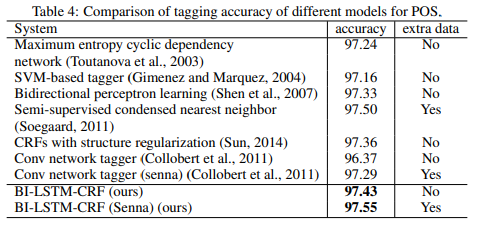
-
POS: extra data(senna embeddings)를 사용하든 않든 bi-LSTM-CRF가 SoTA 기록하였음
-
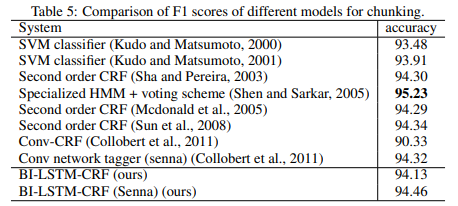
chunking: SoTA 갱신 실패하였으나, SoTA 바로 아래 수준의 performance 기록
-
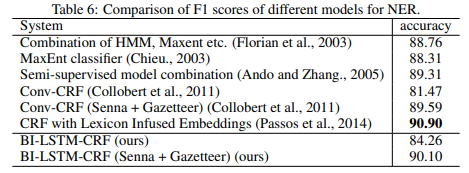
NER: SoTA 갱신에는 실패하였으나, SoTA 바로 아래 수준의 performance 기록. 아마 word embeddings의 차이였을 것으로 추정
5. Discussions
- Collobert et al., 2011에서는 DNN을 sequence tagging에 적용했다는 점에 영향을 받음
- Yao et al., 2014에서는 LSTM을 tagging에 사용했다는 점에 영향받음: forwad LSTM만 사용했다는 점에서 본 연구와 차이
- Wang and Manning, 2013에서 high dimensional discrete feature space에는 non-linear architecture가 효과 없다는 점에서 연관있음
- 동일한 feature set에서 CRF보다 bi-LSTM-CRF가 효과적임을 위 result에서 보인 바 있음
6. Conclusion
- bi-LSTM-CRF 모델을 개발해 sequence tagging에 적용
- POS에서는 SoTA, chunking, NER에서는 SoTA에 근접한 성능
- 본 모델은 robust & word embedding에 less dependent
Misc
- 오타 왜케 많냐^^
- hmm에 대해 두루뭉술하게만 알고 있었는데 다시 정리할 수 있는 좋은 기회였음
- PTB POS tagging SoTA는 SALE-BERT(IEEE 2022): 98.150 vs 97.55
- CoNLL2000의 chunking SoTA는 ACE(ACL 2021): 97.3 vs 94.46
- CoNLL2003의 NER SoTA는 ACE(ACL 2021): 94.6 vs 90.10
- ACE는 bi-LSTM-CRF를 모델의 일부로 사용중임
- LSTM-CRF가 그렇게까지 케케묵은 모델은 아닐지도..?
- chungking에서 SVM 의외로 좋은 선택(93.48 ~ 93.91)
