Character-Aware Neural Language Models (2015) a.k.a. Character CNN
2nd semester 2022 NLP study
(1) word-based embedding(word2vec, GloVe)
(2) character-based embedding(FastText)
(3) character-based w/ word-based embedding(Character-Aware Neural Language Models -> charCNN)
Abstract
- relies only on character-level inputs
- while predictions are at word-level - character-level CNN + highway network -> LSTM
- English Penn Treebank, outperformed SoTA, having 60% fewer parameters
- morphology-rich language(German, Russian, Arabic etc): outperformed SoTA w/ fewer parameters
- Contribution: encode from characters semantic orthographic(철자법상, syntactic보다 더 작은 개념인 듯) information
Introduction
- 태고의 NLP method은 statistical이었다.. n-gram probability에 의존했지만, rare n-gram은 poorly estimated 되는 한계..
- 이후 Neural Language Modeling이 등장하며 word embedding(2003, 2010)이 사용되었으나, subword information(e.g. morpheme)에 대해서는 그다지 좋은 성능 보이지 못함
- eventful, eventfully, uneventful.. etc
- rare words에 대해서는 high perplexities
- morphologically rich language(german etc) & domains with dynamic vocabularies(e.g. social media)에서는 치명적인 문제 - 본 논문에서는 subword level을 character로 끌어내려서 character-level CNN을 만들고, 그 output이 RNN에 사용될 수 있도록 모델 구성
- 본 논문의 contribution
- English Penn Treebank(PTB)에서 60% fewer parameter로 SoTA와 동등한 성능 달성
- Arabic, Czech, French, German, Spanish, Russian 등 morphologically rich language에 적용한 결과에서도 fewer parameter로 SoTA 경신
Model
notation
- : "word-level" word representation of word k
- "absurdity"를 w2v, GloVe 등으로 만든 representation - : "character-level" word representation of word k
- "absurdity"를 철자 "a", "b", "s", "u", "r", "d", "i", "t", "y"로 나눠서 각각의 character를 character representation 만들고 재구성해서 단어 "absurdity"의 representation으로 만든 것
Recurrent Neural Network
- conventional Neural LM(NLM)에서는 word embedding을 input으로 받지만, 우리 모델에서는 character-level CNN + max pooling으로 구성된 single layer의 output을 layer의 input으로 받음
- 원문에서는 max pooling over time으로 표기하였으나, over time을 굳이 적은 이유는 1d array(temporal dimension w/ sequential input)에서 max pooling임을 강조하기 위한 표현이라고 함(참조) - RNN 등장: 이론상으로는 hidden state 를 이용해 현재 time step 까지의 모든 정보를 sum up할 수 있으나, 실제로는 vanilla RNN은 gradient vanishing/exploding 때문에 long range dependency 문제가 발생
- LSTM 등장: RNN + memory cell of each time step()
- LSTM의 memory cell()는 덧셈으로 이루어져 gradient vanishing problem을 경감하나 완벽히 해결하지는 못함
- in practice, gradient clipping같은 optimization trick을 사용하여 해결하고 있(었)음
Recurrent Neural Network LM
- sequence 의 단어 를 예측하기 위해 필요한 정보는
- 단어 를 embedding matrix()의 th column으로 look-up한다면, input embedding 로 표현할 수 있음 ( = )
- 이 모델은 input embedding matrix 를 character-level CNN의 output으로 바꾼 것에 불과함
- 학습과정은 negative log-likelihood를 minimize하는 것을 목표로 함
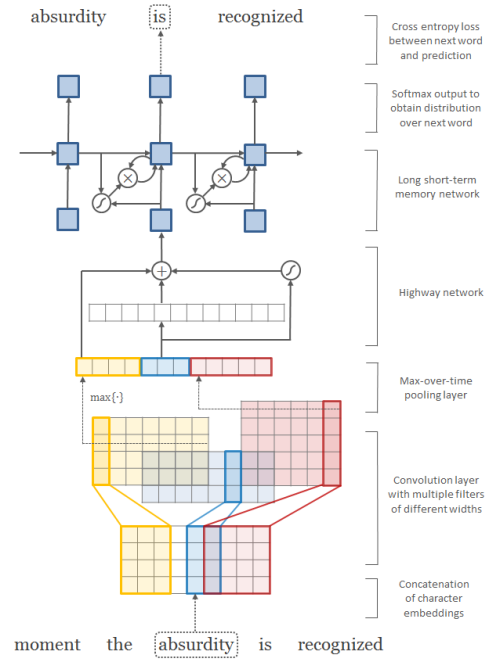
Character-level CNN
- 상술한 character-level CNN(CharCNN)을 서술함
- 단어 가 character sequence []로 이루어져있다고 할 때(e.g. absurdity -> a, b, s, u, r, d, i, t, y), 각각의 character 는 character embedding matrix()에서 해당하는 column으로 look-up될 수 있음
따라서, 단어 k의 character-level representation: (where : dimension of character embedding matrix, : character-level length of work k)
- character embedding matrix에서 one-hot encoding보다는 character 갯수보다 작은 dimension으로 lower dimensional representation() 만드는 것이 성능 좋게 나왔다고 함(nn.embedding()이용)
- 실제로 각 단어의 양 끝에 'start-of-word', 'end-of-word'라는 character를 붙여서(sos, eos token과 비슷) 실제로는 단어의 character-level length가 가 됨
- 단어마다 character-level max length 설정하여 zero-pading 설정 - 에 다양한 width()의 kernal() narrow convolution 적용해 feature map() 생성
- narrow convolution: 가장자리에 filter 적용할 때 padding 안 넣는 것(참조) - 여러 feature map 에서 max pooling: "The idea is to capture the most important feature-the one with the highest value-for a given filter"
- max pooling한 여러 값을 concatenate해서 word 에 대한 character-based representation
Highway Network
- 기본적으론 residual network와 비슷한 역할: non-linearity를 거치지 않은 raw information의 일부를 carry
- 를 input embedding으로 받고 위로 MLP 올리는 모델, 와 highway를 사용하지 않은 모델, 에 highway layer 적용한 모델 중 highway 적용한 모델이 가장 성능 좋았음
- output of highway layer :
는 transform gate, 는 carrying gate라고 불림
Result

English PTB
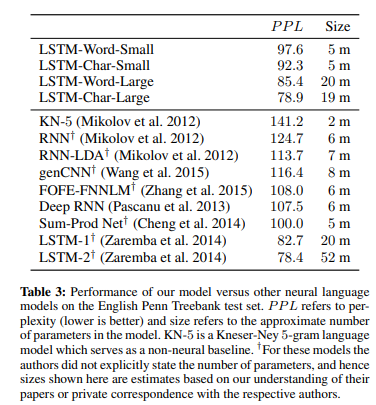
- large model(LSTM-Char-Large)가 SoTA와 거의 동등한 성능 with 60% fewer parameters(52m -> 19m)
- small model(LSTM-Char_Small)는 비슷한 크기의 model과 비교했을 때 더 나은 성능
Other Languages
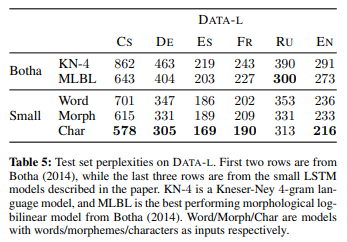
- morphological long bilinear(MLBL) model (Botha and Blunsom, 2014.)을 baseline으로 설정
- morpheme embeddings를 subword information으로 사용하여 input단과 output단에서 합해짐 - russian 제외하고 czech, german, spanish, french, english에서 baseline보다 높은 성능: 비슷한 architecture에 word embedding/morpheme embedding 설정했을 때보다 character embedding이 더 나은 성능
Discussion(Ablation study)
Learned Word Representations
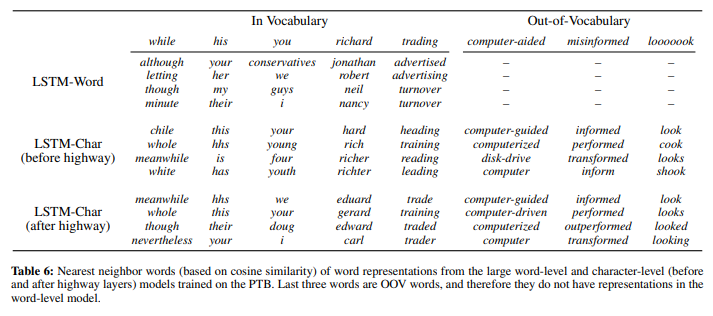
- highway layer가 없으면 생긴 것만으로(surface form) representation 구성하는 것을 볼 수 있음
- highway layer는 semantic feature 학습에 도움을 주는 것으로 추정
- OOV problem(including mis-spelling)에서도 좋은 성능
- 추후 text normalization에도 사용할 수 있을 것(한국에서 욕설 검출에 사용한 바 있음)
Learned Character N-gram Representation

- 원래는 CNN의 filter가 semantic 측면에서의 morpheme 잡아낼 것으로 예측하였으나, 그것은 실패하였음
- prefix, suffix 등의 검출에는 기능하였음
Highway Layers
- highwya layer 없이는 성능 하락, CNN과 결합했을 때 가장 높은 성능 향상, 3개 이상은 무쓸모, CNN 여러 개 하고 max-pooling 한 것에는 무쓸모 etc
Effect of Corpus/Vocab Sizes
- German에 대해 실험한 결과, corpus size 커질수록 perplexity 감소분은 점점 체감하나, 모든 scenario에서 word-level model보다는 나은 성능
Further Observations
- charCNN + word embedding을 결합했을 때 약간이나마 성능 저하 있었음: charCNN + word embedding은 이전 논문들의 architecture임(글쓴이 주)
- 학습할 때 word embedding 이용할 때와 비교해 속도는 절반(3000 tokens/s -> 1500 tokens/s)이나, test/validate에서는 성능 차이 없음
Conclusion
- "only character level input-word level prediction" model 개발
- fewer parameters, outperforms baseline models
- character만으로 semantic/orthographic(syntactic) feature 잡아내기 가능
Our work questions the necessity of word embeddings (as iputs) for neural language modeling
- 글쓴이 주1: minor language(우르두 어 etc) 말고는 요즘 잘 안 쓰이는 듯
- 글쓴이 주2: 한국어에도 charCNN 사용되었음- 넥슨, 왓챠, 한국어 자모에 CharCNN 적용한 논문
- '시발': 'ㅅㅂ', '쉬,,,벌,,,', '시1발', 'ㅅ1발' 등 금칙어 설정된 욕설을 우회하는 변형된 형태의 비속어 탐지에 효과적이었다고 함
Code Review
import torch
import torch.nn as nn
import torchvision.models as models
import numpy as np
class HighwayNetwork(nn.Module):
def __init__(self, input_size,activation='ReLU'):
super(HighwayNetwork, self).__init__()
#transform gate(t)
self.trans_gate = nn.Sequential(
nn.Linear(input_size,input_size),
nn.Sigmoid())
#highway
if activation== 'ReLU':
self.activation = nn.ReLU()
self.h_layer = nn.Sequential(
nn.Linear(input_size,input_size),
self.activation)
self.trans_gate[0].bias.data.fill_(-2)
def forward(self,x):
t = self.trans_gate(x)
h = self.h_layer(x)
z = torch.mul(t,h)+torch.mul(1-t,x)
return z
class LM(nn.Module):
def __init__(self,word_vocab,char_vocab,max_len,embed_dim,out_channels,kernels,hidden_size,batch_size):
super(LM, self).__init__()
self.word_vocab = word_vocab
self.char_vocab = char_vocab
#Embedding layer
self.embed = nn.Embedding(len(char_vocab)+1, embed_dim,padding_idx=0)
#CNN layer
self.cnns = []
for kernel in kernels:
self.cnns.append(nn.Sequential(
nn.Conv2d(1,out_channels*kernel,kernel_size=(kernel,embed_dim)),
nn.Tanh(),
nn.MaxPool2d((max_len-kernel+1,1))))
self.cnns = nn.ModuleList(self.cnns)
#highway layer
input_size = np.asscalar(out_channels*np.sum(kernels))
self.highway = HighwayNetwork(input_size)
#lstm layer
self.lstm = nn.LSTM(input_size,hidden_size,2,batch_first=True,dropout=0.5)
#output layer
self.linear = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(hidden_size,len(word_vocab)))
def forward(self,x,h):
batch_size = x.shape[0]
seq_len = x.shape[1]
x = x.view(-1,x.shape[2])
x = self.embed(x)
x = x.view(x.shape[0],1,x.shape[1],x.shape[2])
y = [cnn(x).squeeze() for cnn in self.cnns]
w = torch.cat(y,1)
w = self.highway(w)
w = w.view(batch_size,seq_len,-1)
out, h = self.lstm(w,h)
out = out.view(batch_size*seq_len,-1)
out = self.linear(out)
return out,hdata preprocessing
#Hyper Parameters
batch_size = 20
max_len = dic['max_len']+2 # character level length, real max length(19) + start, end
embed_dim = 15 # character embedding dimension
kernels = [1,2,3,4,5,6]
out_channels = 25
seq_len = 35 # word level
hidden_size = 500#train_input_data
to_char(data,char_vocab,max_len)
data = np.array(data)
data = torch.from_numpy(data)
data = data.view(batch_size,-1,max_len)to_char는 단어를 character vocabulary(char_vocab) 참조하여 character level로 분리하고, max_len(19)까지 zero-padding하는 custom 함수
model
data.shape # torch.Size[20, 46797, 21] = (batch size, total word length, characters by word)
input_ = data[0] # test용 input data
input_ = input_[0:0+seq_len, :]
input_ = input_.view(1, input_.shape[0], input_.shape[1])input_ shape: [1, 35, 21] == [batch_size, word sequence, characters by word]
embedding
# view(batch size * seq_len(# of words), max_len(character-level))
input_ = input_.view(-1, input_.shape[2])
input_.shape
embed = embed.view(batch_size * seq_len, 1, max_len, emb_dim)
embed.shape #[35, 1, 21, 15]before embed input_ shape: [1, 35, 21]
after embed input_ shape: [35, 1, 21, 15] -> [batch_size * word sequence, 1, characters by word, character embedding dimension]
CNN layers
out_channels = 25
kernels = [1, 2, 3, 4, 5]
embed_dim = 15
max_len = 21
_cnns = []
for kernel in kernels:
_cnns.append(nn.Sequential(
nn.Conv2d(1,out_channels*kernel,kernel_size=(kernel,embed_dim)),
nn.Tanh(),
nn.MaxPool2d((max_len-kernel+1,1))))
cnns_ = nn.ModuleList(_cnns)small model에서는 kernel size를 1, 2, 3, 4, 5로 설정(output channel size = 25)
각각 conv2d의 output shape
- kernel = 1: torch.Size([35, 25, 21, 1])
- kernel = 2: torch.Size([35, 50, 20, 2])
- kernel = 3: torch.Size([35, 75, 19, 3])
cnn_output = [cnns(embed) for cnns in cnns_]
print([cnn_output[i].shape for i in range(0, 5)])max pooling까지 한 결과: 좌측에서부터 kernel = 1, kernel = 2, ..., kernel = 5
[torch.Size([35, 25, 1, 1]), torch.Size([35, 50, 1, 1]), torch.Size([35, 75, 1, 1]), torch.Size([35, 100, 1, 1]), torch.Size([35, 125, 1, 1])]
cnn_squeeze = [i.squeeze() for i in cnn_output]
print([cnn_squeeze[i].shape for i in range(0, 5)])[torch.Size([35, 25]), torch.Size([35, 50]), torch.Size([35, 75]), torch.Size([35, 100]), torch.Size([35, 125])]
cnn_squeeze_cat = torch.cat(cnn_squeeze,1)
print(cnn_squeeze_cat.shape)torch.Size([35, 375]): 375 = 25 + 50 + 75 + 100 + 125
highway layer
class HighwayNetwork(nn.Module):
def __init__(self, input_size,activation='ReLU'):
super(HighwayNetwork, self).__init__()
#transform gate(t)
self.trans_gate = nn.Sequential(
nn.Linear(input_size,input_size),
nn.Sigmoid())
#highway
if activation== 'ReLU':
self.activation = nn.ReLU()
self.h_layer = nn.Sequential(
nn.Linear(input_size,input_size),
self.activation)
self.trans_gate[0].bias.data.fill_(-2) # linear layer에 bias 설정
def forward(self,x):
t = self.trans_gate(x)
h = self.h_layer(x)
z = torch.mul(t,h)+torch.mul(1-t,x)
return z# transform gate
transform_ = highway.trans_gate(cnn_squeeze_cat)
# highway gate
highway_ = highway.h_layer(cnn_squeeze_cat)
shape: both [35, 375] == [batch_size * seq_len, squeezed_size]
