1. Introduction

- Word2Vec, GloVe 등 word representation은 NLP의 model에 key component
- 그러나, high quality representation은 challenging
- high quality representation이 있을 때 word의 complex characteristics를 반영하여 모델을 짜거나(semantics & syntactics), 문맥에 따라서 다른 word use를 이용해 model을 만들 수 있음(다의어, 동음이의어 문제) - new deep contextualized word representation can handle both challenges, can be integrated into existing models
- above new model improves SoTA of NLP tasks
what's the difference?
- ELMo representation: Embeddings from Language Models
- 각 token에 대해 전체 문장 안에서의 representation이 구해짐
- 문장 전체를 읽는 model은 biLM, trained with a coupled LM objective on a large text corpus - ELMo representation is deep: biLM 내부의 모든 layer의 output을 linear combination한 것이므로, rich word repsentation임
- 복수 갯수(논문에서는 2개)의 LM에 노출시킴으로써 low level LM은 syntactics, high level LM은 semantics를 잡아냄
- 위와 같은 특성을 이용하여 disambiguation task, POS tagging 등 범용적으로 사용 가능함
experiment results
- ELMo representations can be easily added to existing models for 6 NLP understanding problems
- addition of ELMo representations improves SoTA of all cases
- ELMo outperforms CoVE
- CoVE: computes contextualized representations using neural machine translation encoder
2. Related work
-
제일 중요한 논문: Jozefowicz et al. (2016): char CNN + bi-LSTM, Kim et al. (2015): character-wise neural LM
위 두 논문 안 읽으면 구조를 이해 못함 -
word representations e.g. word vectors(2010), Word2Vec(2013), GloVe(2014) became component of SoTA NLP architectures
- above word vectors allow a single context independent representation for each word -
previously proposed methods tried to overcome by enriching with subword information or learning separate vectors for each word sense
- enriching with subword information: CHARAGRAM(Wieting et al., 2016) incorporating character based n-gram with word vectors, FastText(Bojanowski et al., 2017) associates skip gram of word basis n-gram with word vectors
- learning separate vectors for each word sense: Neelakantan et al., 2014 utilizes skip gram for multiple embeddings per word type -
상술한 subword units, multi-sense information의 아이디어를 차용
3. ELMo: Embedding from Language Models
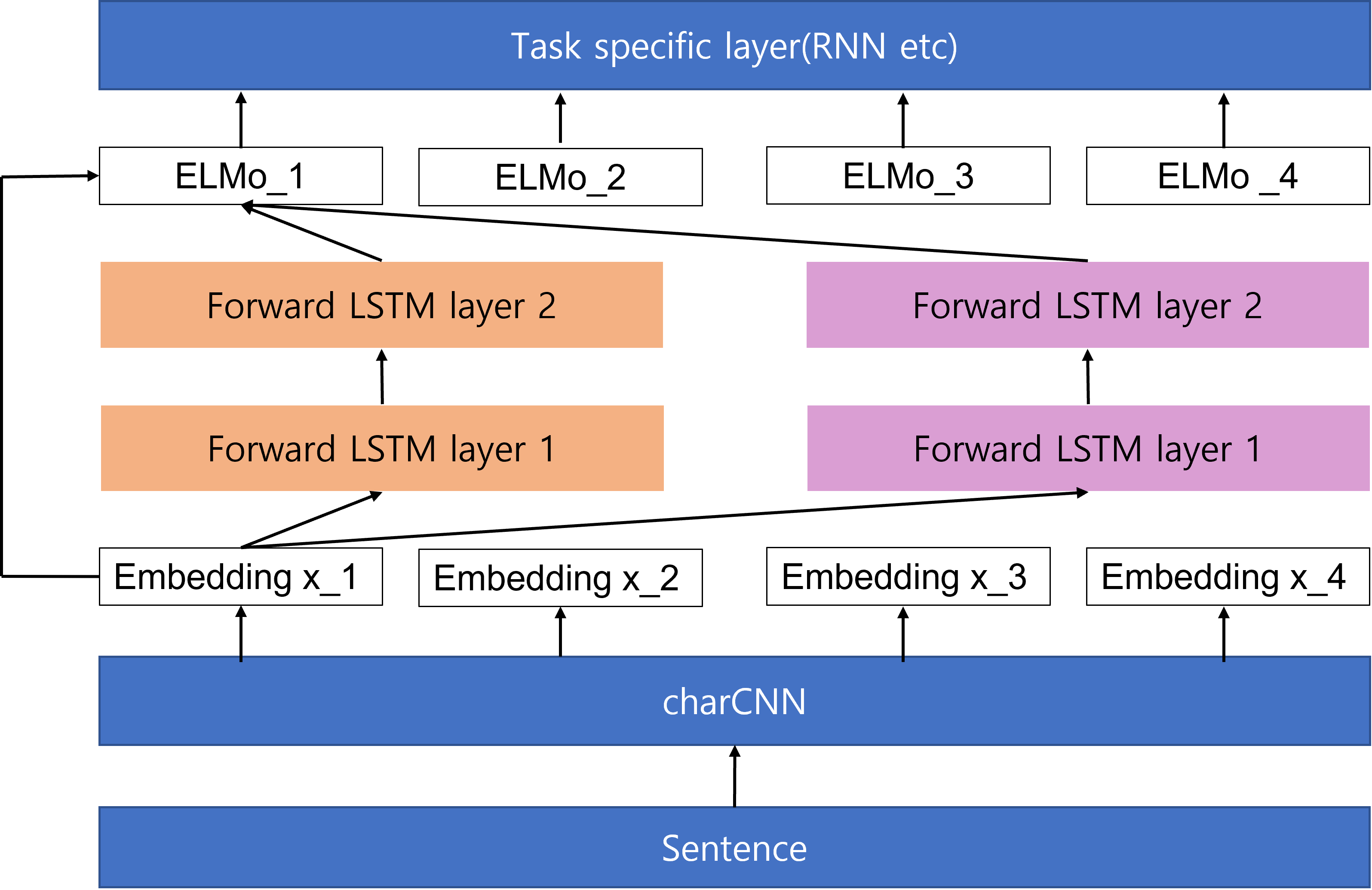
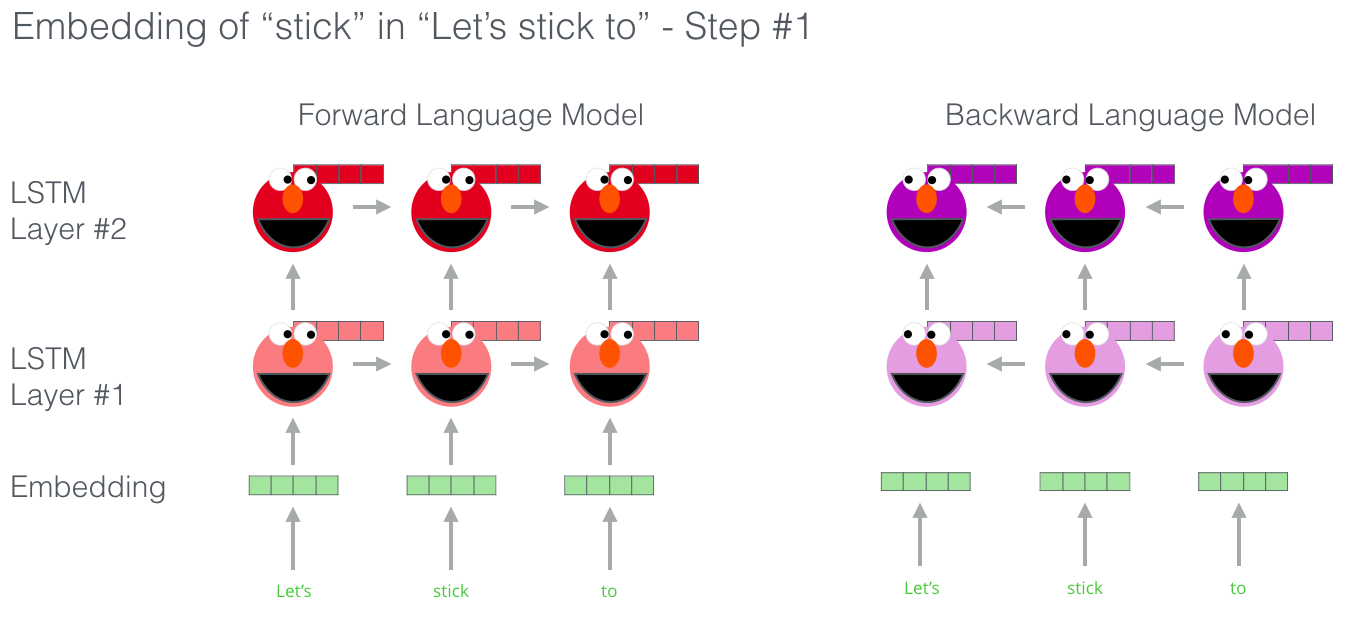
- ELMo word representations are functions of the entire input sentence
- computed on top of two-layer biLMs with character convolutions
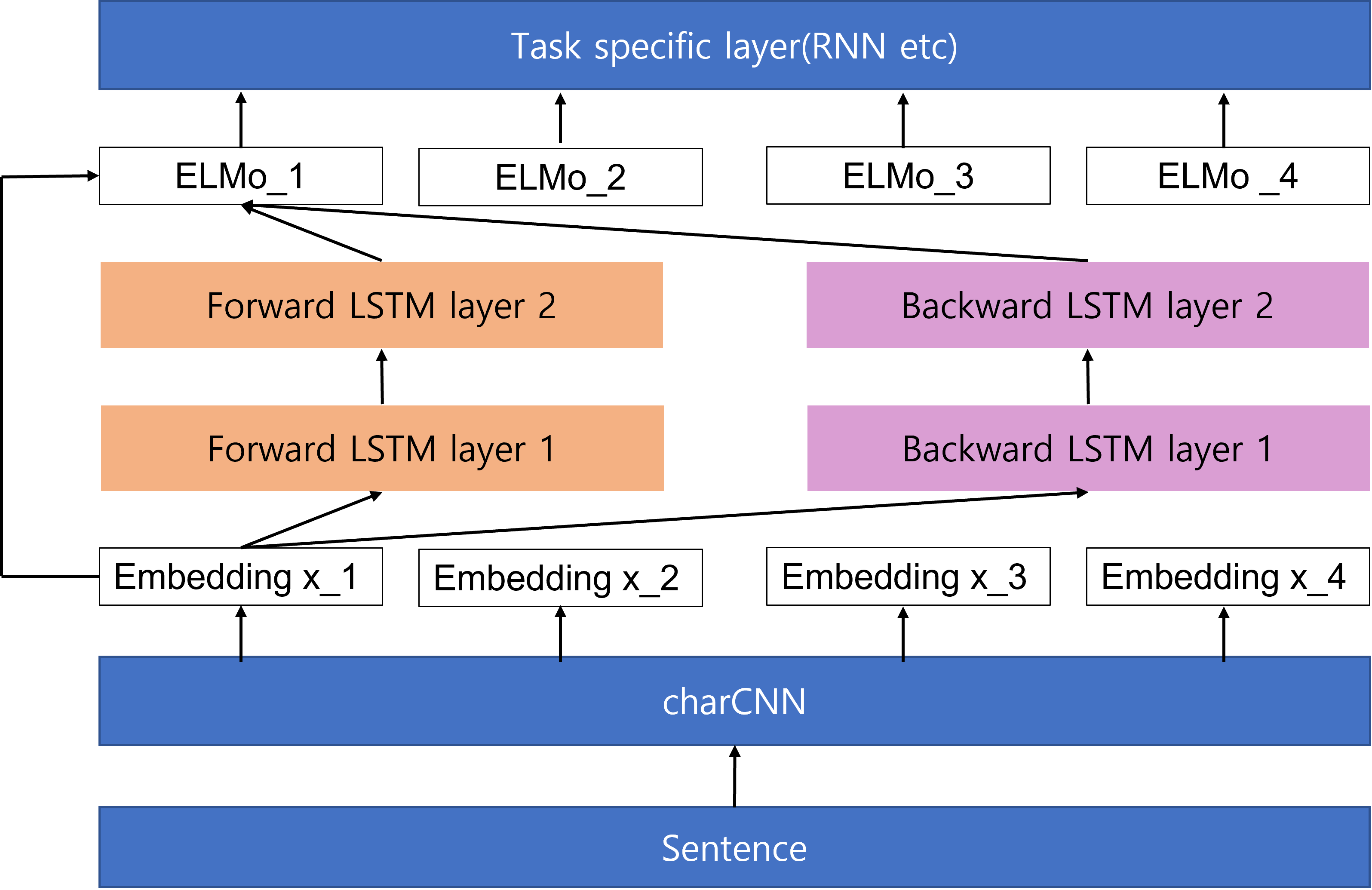
3.1 Bidirectional Language Models
- language model computing the probability of the sequence(tokens, ) is below
where is givenforward LSTM:
backward LSTM: - L-layer forward LSTM에서 각 position() 마다 context-dependent representation()이 발생
- 해당 논문에서 제시하는 biLM의 log likelihood는 아래와 같으며, forward LM과 backward LM의 log likelihood의 합을 maximize함
log likelihood of biLM:
: parameters for token representation, : parameters for softmax layer
3.2 ELMo
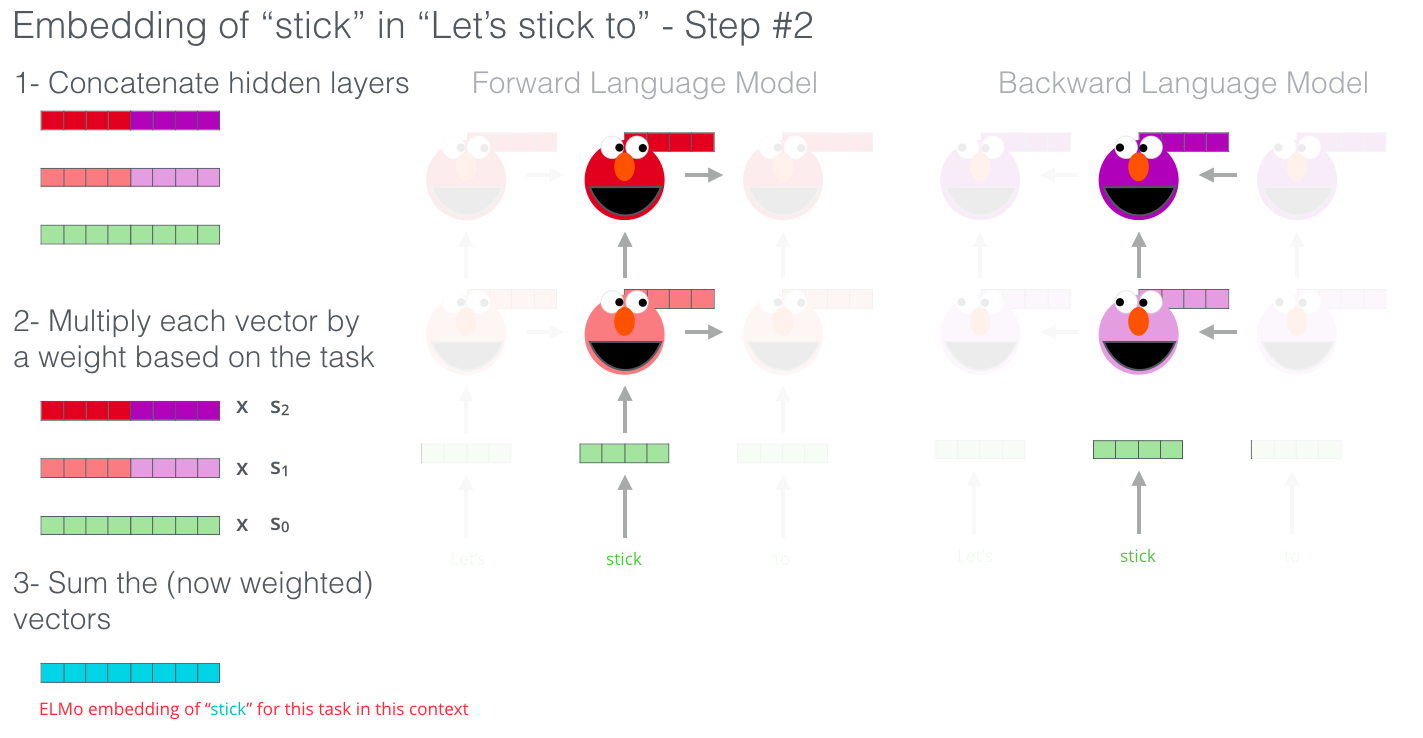
- ELMo is a task specific combination of intermediate layer representations in the biLM
- biLM은 forward-only LM & large scale training corpus보다 더 효과적임(Peters et al. (2017))
(: content independent representation, : position output by layer ,
: task-specific weight, : layer-representation-level weight)
3.3 Using biLMs for supervised NLP tasks
- word마다 biLM의 layer representation(+token representation)을 모두 기록하고(), representation의 linear combination()를 end task model이 학습하게끔 함
- 본 논문에서 제시된 model 구조는 ELMo(biLM) -> end task model의 모양새
- ELMo enhanced representation 를 end task model로 넣음 - 이전 모델들은 개개의 context-independent representation 을 모델에 넣고 layer(RNN, CNN, FFN etc)를 거치며 context-dependent representation 를 구하는 방식
3.4 Pre-trained biLM architecture
- Jozefowicz et al. (2016), Kim et al. (2015)의 모델을 차용
- 각 input token마다 3 layers of representation 제공
- 이전 모델은 1 representation layer(tokens of fixed vocabulary) - biLM이 pretrained 된 이후 specific task 위해 fine tuned
4. Evaluation
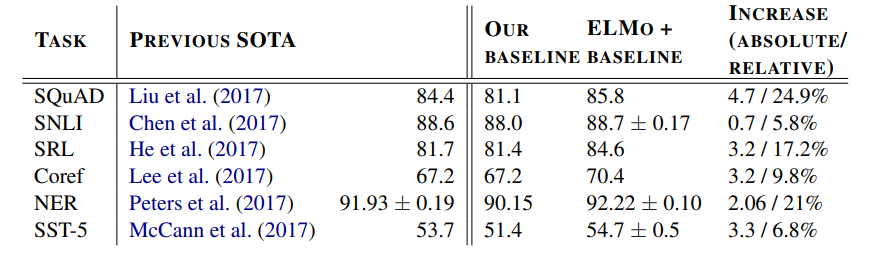
- 6 task에 대해 단순히 ELMo를 더하는 것만으로도 SoTA 갱신(6~20% error reduction)
QA
- 24.9% relative error reduction, 4.7% F1 score improvement, 1.4% SoTA improvement
- SQuAD 사용: 100k+ crowd sourced QA pairs, answers in Wikipedia paragraph
- baseline model (Clark and Gardner. (2017)): improved version of Bidirectional Attention Flow model
Textual entailment
- 전제(premise)가 주어졌을 때, 가설(hypothesis)의 참거짓 여부 판단
- model: ELMO + ESIM
- Stanford Natural Language Inference (SNLI) corpus: 550k hypothesis/premise pairs
- baseline model (Chen et al. (2017)): ESIM model, biLSTM(ecoding premise/hypothesis)-matrix attention(local inferece)-biLSTM(inferece compisition)-poolig-output
Semantic role labeling(SRL)
- predicate-argumet structure of a sentennce, answering "Who did what to whom"
- baseline: He et al. (2017), 8-layer deep biLSTM with forward and backward directiosn interleaved
Coreference resolution
- clustering mentions in text that refer to the same underlying real world enntities
- baseline: Lee et al. (2017), biLSTM & attention(compute span representations)-softmax(finnnd coreference chains)
Named etity extraction
- CoLL 2003 NER task: Reuters RCV1 corpus tagged with 4 different enntity types(PER, LOC, ORG, MISC)
- baseline: Peters et al. (2017), word embeddings & character-based CN representations-2 biLSTM-conditioal random field(CRF) loss
- differennce with out model: baseline use top biLM layer while our model uses weighted average of all biLM layers
Sentiment analysis
- SST-5: Socher et al. (2013), Stanford Sentiment Treebank involves 5 labels(very negative ~ very positive) on movie review
- baseline: biattentive classification network(BCN, McCann et al., 2017), CoVE
- difference: replaced CoVe with ELMo in the BCNs
5. Analysis
- deep contextual representations(모든 layer의 output 모두 사용하는 것)이 top layer output만을 사용하는 것보다 더 높은 성능(5.1)
- lower layers는 sysntactic information, higher layers는 semantic information을 잡아냄(5.3)
- CoVe보다 ELMo representation이 richer representation
5.1 Alternate layer weighting schemes
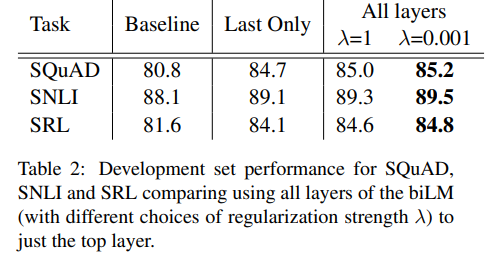
- our model VS only last layer(CoVe, MT encoder)
(simple average over the layers) VS (varying layer weights) - 전체 layer output & varying layer weights 모두 사용하는 것이 가장 높은 성능
- 단, NER w/ small dataset에서는 예외적으로 에 대해 insensitive
5.2 Where to include ELMo?
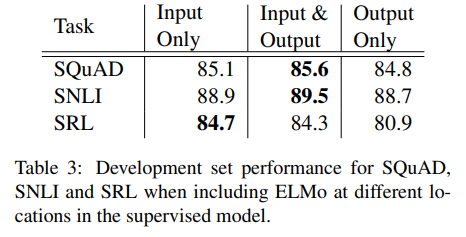
- 상술한 architecture는 모두 아랫단에 ELMo가 들어감 그렇다면 윗단에 넣는다면 어떨까?
- including ELMo at the output of the biRNN in task-specific architectures improves overall results(in some tasks)
- SNLI, SQuAD의 경우, attention layers after biRNN 있으므로 해당 단에서 ELMo 집어넣으면 biLM's internal representations을 바로 참조하므로 성능이 더 높게 나올 수 있다고 생각할 수 있음
- 대조적으로 SRL은 task-specific context representation이 biLM의 context representation보다 더 중요하므로 output단에 ELMo 삽입이 효과적이지 않았다고 판단
5.3 What information is captured by the biLM's representations?
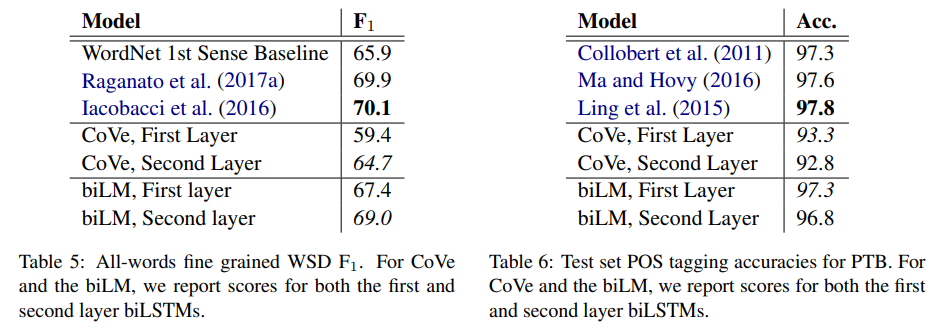
- CoVe, GloVe 등에 비해 context & POS 모두 잘 잡아냄
- Word sense disambiguation(WSD)는 semantic, POS는 syntactic인데, 그 두 부분을 검증한 결과, lower layer는 WSD(semantic), higher layer는 POS(syntactic)에 효과적인 것으로 드러남
5.4 Sample efficiency
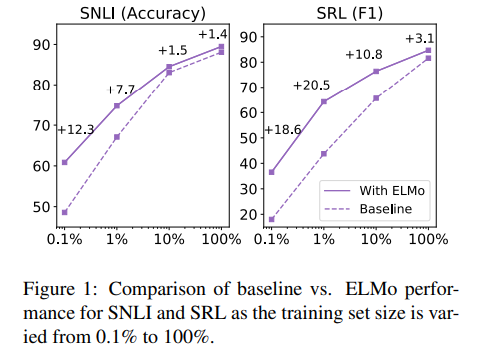
- ELMo를 추가함으로써 training efficiency의 비약적 향상 가능했음
- smaller training set에서도 efficient training 가능했음
5.5 Visualization of learned weights

- input layer에 ELMo 있는 경우 coreference, SQuAD는 lower biLSTM에 큰 weight을 주나, 다른 task는 비교적 balanced
- output layer에 ELMo 있는 경우 전체적으로 balanced, lower layer에 약간 더 큰 weight
6. Conclusion
- deep context dependent representation from biLMs가 여러 task에 대해 performance 개선 제시
- 각기 다른 biLM layer가 semantics, syntactics에 대해 정보를 포착하므로 전체 layer를 쓰는 것이 나음을 보였음
Embedding(CharCNN)
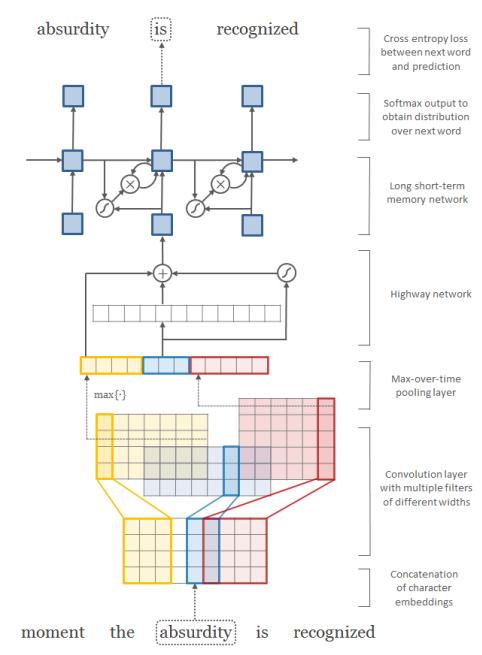
참고할 만한 포스팅: 왓챠R&D 팀의 부적절 포스팅 필터링 모델
Code Review
Model
class BidirectionalLanguageModel(nn.Module):
def __init__(self, emb_dim: int, hid_dim: int, prj_emb: int, dropout: float=0.) -> None:
super().__init__()
self.lstms = nn.ModuleList(
[nn.LSTM(emb_dim, hid_dim, bidirectional=True, dropout=dropout, batch_first=True),
nn.LSTM(prj_emb, hid_dim, bidirectional=True, dropout=dropout, batch_first=True)]
)
self.projection_layer = nn.Linear(2*hid_dim, prj_emb)
def forward(self, x: torch.Tensor, hidden: Tuple[torch.Tensor]=None):
first_output, (hidden, cell) = self.lstms[0](x, hidden) # [Batch, Seq_len, # directions * Hidden_size]
projected = self.projection_layer(first_output) # [Batch, Seq_len, Projection_size]
second_output, (hidden, cell) = self.lstms[1](projected, (hidden, cell)) # [Batch, Seq_len, # directions * Hidden_size]
first_output = first_output.view(first_output.size(0), second_output.size(1), 2, -1)
first_output = first_output[:, :, 0, :] + first_output[:, :, 1, :]
second_output = second_output.view(second_output.size(0), second_output.size(1), 2, -1) # [Batch, Seq_len, # directions, Hidden_size]
second_output = second_output[:, :, 0, :] + second_output[:, :, 1, :] # [Batch, Seq_len, Hidden_size]
return first_output, second_output # [Batch, Seq_len, Hidden_size]nn.ModuleList 안에 lower LSTM layer, higher LSTM layer를 모두 넣고, lower, higher 모두 bidirectional = True로 줌으로써 forward-backward LSTM을 구현
first_output: lower layer의 forward-backward LSTM 통과한 representation, (hidden state, cell state)
projection_layer에서 biLSTM을 통과해 2*hidden_dim을 다시 hidden_dim(=proj_dim)으로 만들어줌
second_output: forward-backward LSTM을 한 번 더 통과시킨 후 forward output + backward output하여 first_output과 second_output의 shape을 같게 함
class ELMo(nn.Module):
def __init__(self, scalar_mixes, vocab_size, output_dim: int, emb_dim: int, hid_dim: int, prj_dim, kernel_sizes: List[Tuple[int]],
seq_len: int, n_layers: int=2, dropout: float=0.):
super().__init__()
#self.embedding = CharEmbedding(vocab_size, emb_dim, prj_dim, kernel_sizes, seq_len)
self.embedding = nn.Embedding(vocab_size, prj_dim)
self.bilms = BidirectionalLanguageModel(hid_dim, hid_dim, n_layers, dropout)
#self.enhance = weighted layer sum 구하는 layer (hid_dim, hid_dim)
self.predict = nn.Linear(hid_dim, output_dim)
def forward(self, x: torch.Tensor):
emb = self.embedding(x) # [Batch, Seq_len, Projection_layer] # proj_dim == emb_dim == hid_dim
first_output, last_output = self.bilms(emb) # [Batch, Seq_len, Hidden_size]
# ELMo_representaton = allennlp의 scalar_mix() 이용, weighted layer sum 구하는 단계
# y = self.predict(ELMo_representation)
# y = self.predict(last_output) # [Batch, Seq_len, VOCAB_SIZE]
return y
def get_embed_layers(self, x: torch.Tensor): # for check
emb = self.embedding(x) # [Batch, Seq_len, Projection_layer (==Emb_dim==HId_dim)]
fisrt_output, last_output = self.bilms(emb) # [Batch, Seq_len, Hidden_size]
return emb, (fisrt_output, last_output)embedding layer(charEmb 실패) -> 2biLSTMS -> weighted sum of all layers(scalar_mix 이용하려 했으나 실패) -> prediction의 구조(를 의도)
...총체적 난국...
