[LLM study] 5.2 Alignment Tuning
alignment의 background와 definition, criteria, human feedback data를 어떻게 모을 것인지, alining을 어떻게 할 것인지, RLHF에 대한 설명
Background and Criteria for Alignment
Background
- instruction tuning까지만 진행하면 LLM이 unintended behaviour를 보일 수 있음 (e.g. fabricating false information (a.k.a. hallucination), pursuing inaccurate objectives, ahrmful, misleadning, biased expression producing etc.)
- 이는 LLM의 학습 과정에서 word prediction에만 초점을 맞춰 파라미터를 학습시켰기 때문으로, human value나 preference에 대한 고려가 미흡했기 때문임
- 따라서, alignment tuning은 pretraining이나 instruction tuning과 달리, 굉장히 다른 criteria (e.g. helpfulness, honesty, harmlessness) 에 대해서 학습을 하게 됨
- 다만, alignment tuning 시 pretraining 및 instruction tuning 때 학습했던 내용을 잊어 general ability를 깎아먹는 alignment tax가 발생하기도 함
Alignment Criteria
- 지금까지는 3개의 representative alignment criteria에 대해서 alignment tuning을 진행: helpful, honest, harmless
- 다만, correctness 등 다른 criteria를 적용하기도 함
- 이러한 criteria를 충족했는지 확인하는 가장 기본적인 기법은 red teaming이 있겠음: 수동 및 자동으로 adversarial prompt를 제공해 criteria를 충족하는지 확인하는 기법
- Helpfulness
- 사용자의 task solving 시 간결 (concise) 하고 효율적 (efficient) 으로 도움을 줄 수 있어야 함
- 추가 설명이 필요할 때, 민감성 (sensitivity), 통찰력 (perceptiveness), 신중함 (prudence) 를 겸비하여 추가적인 정보를 제공할 수 이썽야 함
- 하지만 설명이 굉장히 모호하죠? 따라서 LLM한테 helpfulness를 학습시키는 것은 매우 힘듦
- Honesty
- 정확한 정보 전달에 초점을 두는 criteria
- LLM 자신이 작성한 결과의 uncertainty를 아는 것이 중요함 (know unknowns)
- Harmlessness
- 공격적 (offensive) 이거나 차별적 (discriminatory) 이지 않아야 하는 criteria
- 악의적 질문과 목적을 파악할 수 있어야 하고, 악의적 질문과 목적이 식별되면 질문을 거부 및 회피하여야 함
- 그러나, 어떠한 행동이 harmful인가? (what behaviours) & 어디까지가 harmful인가? (to what extent) 는 개인과 사회마다 굉장히 다른 기준을 갖고 있으므로 정의하기가 어려움
Collecting Human Feedbacks
Human Labeler Selection
- qualified human annotators가 필요함: 보통 대학교 학사 수준의 학력을 갖는 집단으로 설정
- researcher와 labeler 사이의 간극을 메우기 위해 human labeler와 researcher 간 agreement score 계산해서 labeler를 filter하기도 (InstructGPT)
- sample data 에 대해서 researcher group & labeler group 간 agreement score 계산
- 높은 수준의 agreement score 보인 labeler만 이후 labeling 작업에 데리고 가는 것
Human Feedback Collection
- Ranking-based approach:
- model generation 중 가장 좋은 답변만 선택하는 것
- finegrained evaluation이 아님
- 좋지 않은 답변은 모두 버림으로써 모델의 학습 기회가 좁아짐
- Elo rating system은 best-pick 대신 preference ranking을 사용: more reliable & safer 답변에 대한 학습 가능
- Question-based approach
- useful한지 등에 대한 더 detail한 feedback을 제공하는 방안
- Rule-based approach
- rule이란 criteria를 model output이 충족했는지 판단하는 checklist와 유사한 것
- preference ranking과 ruleviolation feedback을 모두 취하는 방식
Reinforcement Learning with Human Feedback (RLHF)
- LLM에게 3 criteria (helpfulness, honest, harmlessness) 를 학습시키기 위해 강화학습 알고리즘을 사용한 방식
RLHF system
- system의 구성: pretrained LLM, human feedback을 학습하는 reward model, LLM을 학습시키는 RL algorithm
- pretrained LLM: 생략
- RM: scalar value로 LLM output이 human preference에 얼마나 걸맞는지를 판단
- finetuned LM
- human preference data로 처음부터 학습한 (de novo) LM
- 보통 학습시킬 LLM보다 파라미터가 더 적은 LM을 RM으로 사용 (GPT-3 6B, Gopher 7B 수준)
- RL alrogithm: Proximal Policy Optimization (PPO) 를 보통 사용
Key Steps for RLHF
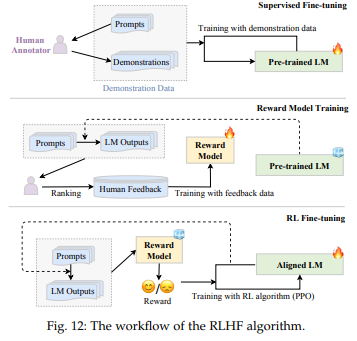
Supervised Finetuning (SFT), Reward Model training, RL Finetuning으로 구성됨
- Supervised Finetuning (SFT)
- instruction tuning과 유사 (desired output이 나오게끔 학습한다는 면에서) 하며, optional
- openQA, brainstorming, chatting, rewritting 에 대해서 SFT 진행
- e.g.
Query: List five ideas for how to regain enthusiasm for my career
- Reward model training
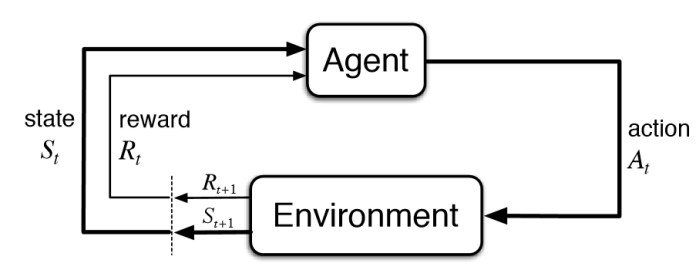
- 강화학습
- agent: action을 선택하고, environment에서 reward를 받아 학습
- environment: agent action에 반응하여 reward를 제공
- RLHF에의 적용
- agent: pretrained LLM
- environment: text generation process (추상적)
- state: 현재까지 생성된 token sequence
- action: next step에서 생성하는 토큰
- reward: RM에서나오는 reward
- LM이 input prompt에 대한 output text를 생성하도록 함 (하나의 input에 multiple output이 나오도록)
- human labeler가 output에 대해서 ranking (다른 approach 사용 가능) 매김
- RM이 human-preferred output을 예측하도록 학습됨
- 강화학습
- RL finetuning
- LM aligning을 RL problem으로 치환
- penalty term을 적용해 pretraining & instruction tuning 에서 학습한 내용을 너무 많이 잊지 않도록 함
- 최근 연구에서는 RL tuning 이후에 가장 높은 reward를 받은 output을 SFT로 한 번 더 학습시켜 RL algorithm 상의 instability를 줄이도록 함

multidisciplinary
개괄 설명 감사합니당