일러두기
- 본 논문은 그 유명한 "Prompt Tuning"을 제시한 논문임
- 본 논문에서 "model tuning"이라 함은 "fine-tuning"을 의미함
0 Abstract
- "prompt tuning" to learn "soft prompts"
- few shot setting에서 GPT-3를 사용한 discrte prompt보다 더 좋은 성능
- 여러 크기의 T5를 사용했을 때, 모델 크기에 따라서 soft prompting이 finetuning과 비교하여 competitive할 수 있음
- 그런데 parameter size가 11bln 이상일 때나 그렇겠지..
- 사용처
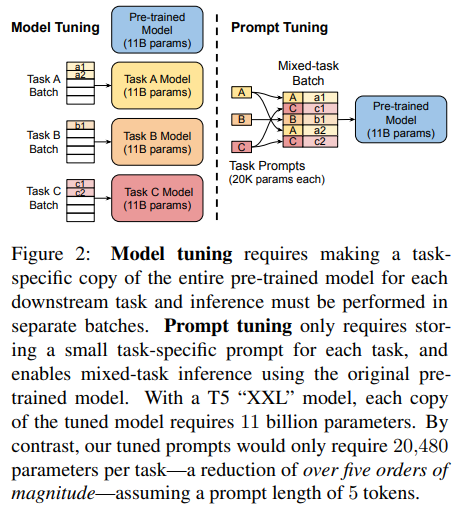
- 모델이 워낙 무거우니 쉽게 배포
- 하나의 frozen LLM을 이용해 여러 개 downstream task 수행 가능
- 본 논문의 "prompt tuning"은 Li and Liang (2021)의 "prefix tuning"의 간략화된 버전이라고 볼 수 있음
- soft prompting이 domain transfer와 efficient "prompt ensembling"에 긍정적으로 사용될 수 있음
1 Introduction
- BERT, GPT 이후 dominant adaptation은 finetuning
- GPT-3 논문에서 prompt design (priming) 제시
- 그러나, 위와 같은 prompt-based adaptation (priming) 은 단점이 있으며, finetuning보다 성능이 낮음 (finedtuned T5-XXL 89.3 vs GPT-3 few shot 71.8 on SuperGLUE)
- task description is error-prone
- requires human involvement
- effectivness of a prompt is limited by how much conditioning text can fit into the model's input
- prompt based approach 를 개선하기 위한 시도
- AutoPrompt (Shin et al., 2020): search algorithm over the discrete space of words guided by the downstream application training data
- Prefix Tuning (Li and Liang, 2021): generative task에 괜찮은 성능
모델은 input layer를 포함한 encoder stack의 각 layer에 prefix activation을 붙인 것 - WARP (Hambardzumyan et al., 2021): input & output subnetwork에만 trainable parameter를 두었는데, classification task에서 reasonable result를 냈음

- 본 논문의 "Prompt Tuning"
- token k 개만 downstream task에 학습시킴
- end-to-end로 학습이 가능하며 full labeled dataset에 대해 condense the signal이 가능함
- 위와 같은 이유로 few-shot prompt setting에서 finetuning보다 성능이 좋고 성능 차이를 줄였음
- 또한 downstream 하나당 모델 하나를 학습하는 게 아니고, 여러 개의 task에 대해 하나의 PLM을 사용하므로 효율적임
- Experiment Results
- prompt tuning (prefix tuning처럼 intermediate-layer prefixes를 사용하거나 WARP처럼 task-specific output layer를 사용하지 않고도) 만으로 finetuning과 유사한 성능을 도출하였음
- backbone PLM 의 성능이 좋으려면 모델의 크기가 커야 함
- Analysis
- general NLU를 위한 "generalist" parameters와 "task-specific" parameters가 있음
- generalist parameter를 고정하고 task specific parameters만 잘 포착해도 domain shift에 resilience를 보일 수 있음
- prompt ensembling: "multiple prompts" on "same task" 가 classic model ensemble보다 더 높은 성능과 효율을 달성할 수 있음
- interpretability of soft prompts를 investigate
- Contribution
- Prompt Tuning과 finetuning과 비교했을 때의 우위
- PLM scale이 커질수록 quality와 robustness 상승
- domain shift problem에서 prompt tuning이 finetuning보다 나음
- prompt ensmebling과 그 효과를 제시
2 Prompt Tuning
T5의 등장 이후 모든 task를 text generation으로 치환 가능
- classification을 예시로 들자면, 통상적인 classification model을 다음과 같을 것임
where is a series of tokens, is a single class label
- 위와 같은 traditional classification 대신, conditional generation model로 바꿀 수 있음
where is a sequence of tokens that representa a class label
stands for parameterized weights of transformers (T5를 사용했을 시)
Prompting in Traditional Manner
- Prompting은 의 generation 과정에서 condition으로 작용할 수 있는 extra information을 추가하는 것이라고 할 수 있음
추가 정보는 로 표현할 수 있으며, input 에 덧붙여(prepend)지게 됨
model은 correct 의 likelihood를 maximize하게 됨:
이 와중에 상술한 model parameters 는 fixed됨
- In case of GPT-3 (hard prompting 내지 priming을 겨냥한 듯)
- representation of prompt tokens are part of the model's embedding table ('part of the model's embedding table'이라는 게 정확히 뭘 의미하는지 모르겠는데, 이후의 문장들을 보면 vocab의 일부라고 생각하면 될 듯)
- optimal prompt를 찾기 위해 manual selection과 non-differential (그러므로 gradient update를 이용한 학습이 불가능하다는 말이겠지) method (Jiang et al., 2021, AutoPrompt (Shin et al., 2020)) 를 사용할 수밖에 없었음
- 위와 같은 경우를 본 논문에서는 "restriction that the prompt be parameterized "라고 표현하고 있음
Prompt Tuning
- prompt tuning은 위와 같이 prompts가 model parameter 에 parameterized되지 않으며, own parameters 를 갖게 되며, trainable함
- prompt design은 fixed vocabulary에서 단어를 가져오는 것이나, prompt tuning은 fixed length of special tokens를 사용하면서 special tokens의 embedding만 update하게 됨
- 따라서 수정된 conditional generation 모델은 다음과 같음
maximizes likelihood of Y via backpropagation, __while appying gradient updates to
- 실제로 처리되는 과정은 다음과 같음
<Notation>
original input sequence 는 T5를 통과하면 embedding matrix 가 됨
soft prompts 는 다음과 같은 parameter 로 표현될 수 있음
where stands for embedding dimension
concat한 embeding 은 원래의 T5와 같이 encoder-decoder를 통과하게 됨
는 의 probability를 maximize하면서도, 업데이트 되는 것은 prompt parameters 밖에 없음
2.1 Design Decisions
(Soft) Prompt Representation Initialization
- random initialization
- prompt token embedding을 model이 갖고 있는 vocabulary의 embedding으로 initialize
- class labels ()initialize prompt with embeddings that enumerate the output classes (PET (Schick and Schuetze, 2021))
"Since we want the model to produce these tokens in the output, initializing the prompt with the embeddings of the valid target tokens should prime the model to restrict its output to the legal output classes."
- SPoT 에서는 target task의 soft prompt는 source task의 prompt로 initialization했는데, source prompt는 어떻게 initialization했더라?
Length of Prompt
- parameter cost를 로 설정
- denotes for token embedding dimension
- denotes for prompt length
- prompt가 짧을수록 더 적은 수의 parameter가 tune되므로 perform well하는 minimal length를 탐색함
2.2 Unlearning Span Corruption
T5의 학습방식
- span corruption이란? T5 training 시 사용된 objective로, BERT에서 MLM을 objective로 가져갔듯이 1개 이상의 token으로 구성된 sequence (span) 를 mask한 것

- span corruption에 sentinel tokens 사용되는데, 아래의
<extra_id_1>,<extrai_id_2>등 span을 의미함 (from huggingface T5 document)
input_ids = tokenizer.encode('The <extra_id_1> walks in <extra_id_2> park', return_tensors='pt')
lm_labels = tokenizer.encode('<extra_id_1> cute dog <extra_id_2> the <extra_id_3> </s>', return_tensors='pt')
# the forward function automatically creates the correct decoder_input_ids
model(input_ids=input_ids, lm_labels=lm_labels)T5의 학습방식과 Prompt Tuning과의 부적합 & 실험
- T5 모델 중 T5.1.1의 경우에는 span corruption만을 사용해 학습되었는데, sentinel token이 없는 문장은 아예 경험하지 않았고, natural targets를 predict하도록 학습되지도 않았음(sentinel token이 같이 있는 상태에서만 predict하도록 학습됨)
- finetuning하면 이런 pretraining objective가 잊혀질 수 있을 것 같긴 한데, prompting으로는 약해서 잘 모르겠다고 함
- 3가지 setting으로 실험
- span corruption: T5를 추가적인 학습 없이 (off-the-shelf) 바로 downstream task에 사용
- span corruption + sentinel: downstream targets 앞에 sentinel token을 붙임으로써 pretraining의 학습 방식과 비슷하게 가져감
- LM Adaptation: T5를 조금 더 pretraining
- objective를 T5 논문에서 논의된 것으로 바꿔서 가져감: natural text prefix를 input으로 넣고 natural text continuation을 output으로 생성하게끔 함
- 이렇게 LM Adaptation한 모델을 multiple downstream tasks의 frozen LM으로 사용함
- LM Adaptation은 빠르게 T5를 GPT-3와 비슷하게끔 만들 것: realistic text를 output으로 가져가고, few-shot learner가 될 것으로 예상됨
- 실제로 얼마나 효과가 있을지는 미지수이고, 학습 step을 100k까지 다양하게 가져갔음
3 Results
Experiment Setting
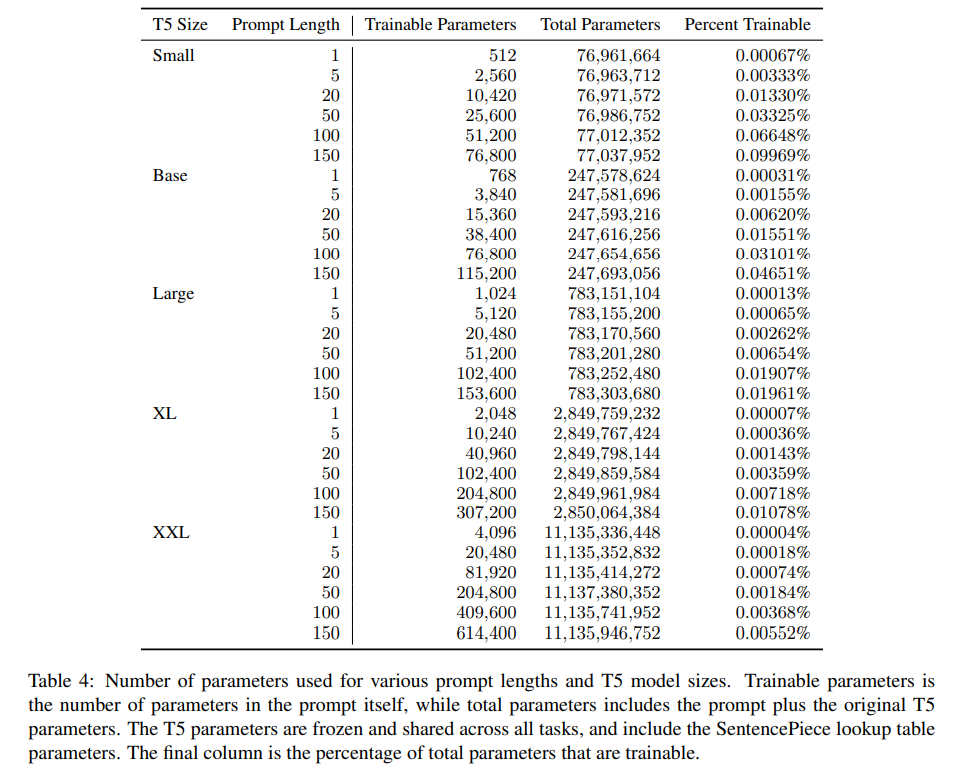
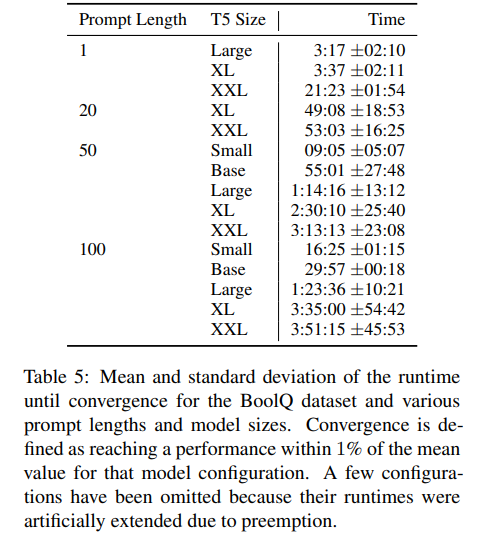
- T5 small, base, large, XL, XXL에 대해 실험, T5.1.1 checkpoint (T5에서 pretraining 시 supervised learning을 제외하고, hyperarameter adjustments, ReLU 대신 GeGLU 사용) 사용
- default config: LM-adaptation for 100k steps, class labels(후술)을 사용해 initialization, prompt length 100
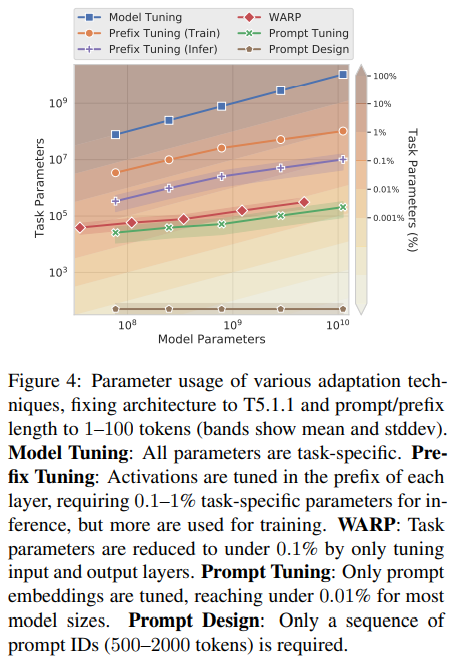
- Li and Liang (2021) 의 Prefix-Tuning의 경우에는 token length가 10이라서 Prompt Tuning의 token length 100보다는 훨씬 짧지만 그래도 Prompt Tuning의 trainable parameter (task-specific parameter로 표현) 가 더 적음
- dataset은 SuperGLUE를 사용, no multi-task setup, no mixing training data cross tasks
- t2t format을 맞추기 위해 T5의 형식을 따라감, 다만 input 가장 앞에 어떤 task인지를 밝히던 부분은 제외함
- 30,000 steps training, constant learning rate 0.3, batch size 32
- dev set으로 checkpoint 설정
- JAX, Adafactor optimizer with weight decay 1e-5, decay 0.8, parameter scaling off
- Flax 사용
3.1 Closing the Gap
- 비교군
- finetuned T5: (1) source task-target task를 같게 한 finetuned T5 (2) input 가장 앞에 task 이름을 명시한 single model tuned on all tasks jointly
- GPT-3 few shot
- parameter size 11bln 이상 (T5-XXL) 이면 finetuning과 비슷해지거나 더 높아짐
- GPT-3 few shot setting 보다는 확실히 더 나아짐 (T5-large가 GPT-3 175 bln 보다 나음)
3.2 Ablation Study
Prompt Length
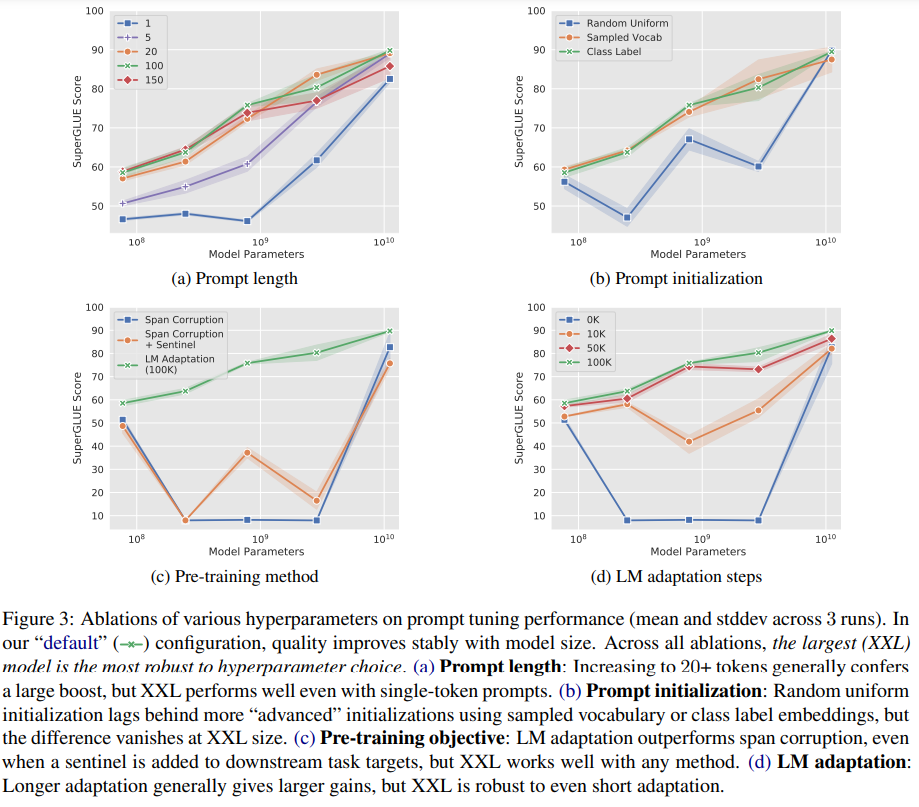
- setting: prompt length를 {1, 5, 20, 100, 150} 으로 다르게 설정하고 나머지는 동일하게 함
- 어쨌거나 prompt length가 1보다는 커져야 좋은 성능을 낼 수 있음
- 모델이 커질수록 target behaviour 달성에 필요한 token의 개수가 적어짐 (본문에서는 less conditioning signal is needed to achieve a target behavior 라고 서술)
Prompt Initialization
- setting
- random initialization: uniform sample [-0.5, 0.5]
- vocabulary sampling: 5000 most common token으로 제한, pretraining corpus에서 likelihood에 따라 정렬
- class label: downstream task의 class name의 representation을 initialization으로 활용하였음 (downstream task의 class name 하나의 representation을 하나의 token의 initializaed representation으로 활용), 만약 class label이 multi-token일 경우, token embedding을 avg하였으며, token length가 downstream task의 class name representation보다 길 경우, 2의 vocab sampling을 이용해 나머지를 채웠음
- 전체 모델에서 (3) class based initialized 가 가장 좋은 성능을 보이기는 함
- 모델 크기가 작을수록 initialization 간 성능 차이가 큰데, 모델 크기가 커지면 큰 차이 없음
- (3) class label의 경우 학습과정이 끝나고 prompt에 initialization의 흔적이 있는 것 같음
Pre-training Objective
- T5의 training objective였던 span corrpution이 prompting과 그다지 맞지 않았음: sentinel token과 함께 read & write 헀으므로 sentinel token이 없는 상황에서 read & write이 잘 되지 않았음
- LM Adaptation의 step 수를 다르게하였을 때, 100k까지는 증가하는 경향
- T5-XXL는 non-ideal configuration에서도 잘 작동하는 것을 확인할 수 있었음
- 특이사항
- non-optimal span corruption setting에서 model size와 performance 사이의 instability
- mid-sized model이 legal class label을 전혀 학습하지 못함: legal class label이 있나???
- LM Adaptation으로 100k 학습한 T5 1.1 공개했음
4 Comparison to Similar Approaches
Prefix Tuning (Li and Liang, 2021)
- Prefix Tuning은 every transformer layer에 붙여진 prefixes를 학습하며, 이는 transformer 각 layer의 activation을 학습하는 것과 같음
- 반면, Prompt Tuning은 single prompt representation을 사용하며, 이 prompt representation은 embedded input에 붙여짐 (prepend)
- parameter가 더 적게 필요한 것과 별개로, "our approach allows the transformer to update the intermediate-layer task representations"라는데, intermediate-layer라는 게 정확히 뭘 의미하는지 모르겠음
- Prefix Tuning은 GPT-2와 BART (encoder와 decoder 모두에 prefix를 붙여줘야 함) 를 사용, Prompt Tuning은 T5를 사용 (encoder에만 붙여주면 됨)
- Prefix Tuning은 learning stabilization을 위해 reparameterization이 필요 (parameter 더 필요) 하지만 prompt tuning은 필요하지 않음
WARP (Hambardzumyan et al., 2021)
- input layer에서 prompt parameter를 덧붙임
- [MASK] token과 output layer를 사용하며, output layer에서 [MASK]의 class logit을 계산함
- 따라서 classification 말고는 거의 불가능하닥 ㅗ봐야
- 반면 Prompt Tuning은 input에 대한 change나 task-specific head가 필요없음
P-Tuning (Gpt Understands, too. Liu et al., 2021)
- input 사이사이에 continuous prompts (soft prompts) 를 끼워넣고, human-designed pattern을 사용함
- 준수한 성능을 내려면 P-Tuning이 들어간 상태에서 finetuning까지 진행되어야 함
- "soft words"를 사용해 LM에서 knowledge를 추출
- input이 hand-designed prompt prototypes에 based, 정확히는 못 알아들었는데 어쨌건 모델이 깊어질수록 parameter cost가 커짐
- prepended tokens를 사용해 transformer model을 다양한 task에 adapt하였음
- 하지만, 소규모의 synthetic datasets를 합쳐서 compositional task representation으로 만들었는데, 이는 real-world dataset과는 차이가 있음
- base model은 task representation과 함께 학습시킨 small transformer model
Adapters (Rebuffi et al., 2017; Houlsby et al., 2019)
- adapter의 구조는 기본적을 frozen PLM 사이사이에 small bottleneck layer를 끼워넣은 것
- Pfeiffer et al. (2020) 에서는 multilingual context에 multiple adapters 달아서 language understanding과 task description을 분리하려는 시도를 했음
- Adapters modify the actual function that acts on the input representation, parameterized by the neural network, by allowing the rewriting of activations at a ny given layer (while Prompt Tuning은 new input representation을 갖다붙이는 것이고, functions are fixed)
5 Resilience to Domain Shift
- Prompt Tuning은 General Understanding of Language를 해치지 않음
- Prompt Tuning은 input representation을 indirectly 조절(modulate)함으로써 dataset의 specific lexical clues, spurious correlation을 학습해 overfitting하는 것을 막음
- 따라서 domain shift에도 robust함
Zero shot Domain Transfer
-
QA
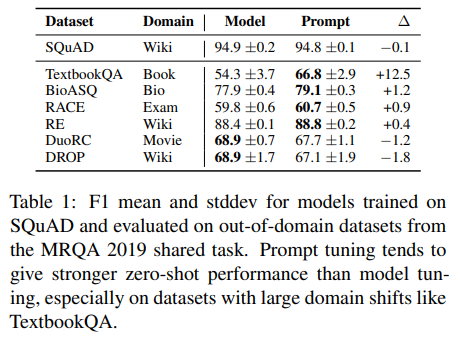
- setting: SQuAD에서 학습한 뒤, MRQA의 out-of-domain에서 evaluation
- 결과:
- 대다수의 out-of-domain dataset에서 prompt tuning이 finetuning을 능가 (table 1)
- ource task의 domain과 target task의 domain이 더 클수록 (Wiki & Bio, Wiki & Textbook) 더 높은 효과
- domain의 차이가 작으면 finetuning이 더 나았음
-
Paraphrase Detection
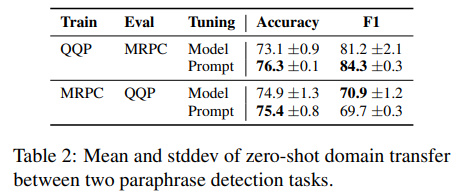
- setting: GLUE의 QQP, MRPC를 사용하고, checkpoint는 in-domain의 dev set으로 측정하고 evaluation은 out-domain으로 측정
- 결과:
- QQP에서 train하고 MRPC에서 evaluate한 prompt tuning이 finetuning보다 더 높은 성능
- MRPC에서 train하고 QQP에서 evaluate한 경우 accuracy가 약간 상승하고 F1이 약간 하락함
- 위와 같은 결과에서 추론할 수있는 점은, finetuning이 training task에 overfit되어 similar task임에도 domain이 달라지면 성능이 하락할 수 있다는 것
6 Prompt Ensembling
- why ensemble?
- to improve task performance
- useful for estimating model uncertainty
- why can't ensemble on NN models?: as model size increases, ensembling being impractical
Ensemble with Prompt Tuning
- train N separate prompts on same task
- reducing storage cost & inference more efficient
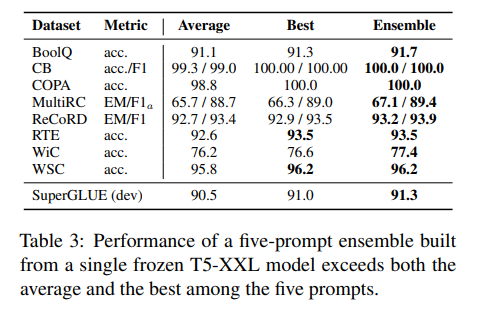
Experiment
- trained 5 prompts for each SuperGLUE task, T5-XXL with default hyperparameter
- ensemble로는 majority voting 사용
- result: ensemble beats single-prompt average, beats or compete best single-prompt (table 3)
7 Interpretability
- 아무래도 soft prompt가 continuous embedding space에서 작동하다보니 interpretability를 확보하는 게 쉽지 않음
- 각 prompt의 embedding으로부터 가장 가까운 vocabulary를 cosine distance 이용해 계산
- 각 prompt token마다 top-5 neighbors는 lexically similar cluster 또는 strongly related cluster를 형성
(e.g. Technology/technology/Technologies/technological/technologies 등) - 위와 같은 실험에서 알 수 있는 점은, prompt가 "word-like" representation을 학습한다는 점을 알 수 있음
- prompt initialization을 달리 하였을 각 경우 (3가지) 의 실험 결과
- class label: training 이후에도 class label의 정보가 남아있음, 상세하게는 token의 nearest neighbor 중 하나로 해당 class label 정보가 남아있음
- random uniform, sampled vocab: class label 정보가 prompt token에 남아있으나, 1개가 아니라 다수의 prompt token의 neighbor로 나타남
- 위와 같은 실험에서 알 수 있는 점은, expected output class를 prompt에 reference로 저장하고 있으며, output class로 initialization하는 게 centralization에 더 나음
- prompt length가 길어지면 (e.g. size 100) 복수의 prompt tokens가 같은 nearest neighbors (vocabulary) 를 공유하는데, 이는 두 가지로 생각해볼 수 있음: (1) prompt의 공간이 불필요하게 많음 (excess capacity), (2) prompt representation에 sequential structure가 없어서 localize information to a specific position이 불가능
- 추가적으로 생각해보았을 때, prompt의 역할 중 하나는 input을 specific domain or context로 interpret할 수 있도록 보조하는 것으로 생각해볼 수 있음
8 Conclusion
- Prompt Tuning이 frozen PLM을 downstream task에 잘 adapt할 수 있다는 점을 밝혔음
- finetuning과 비교하였을 때 모델의 크기가 커질수록 performance gap이 줄어듦
- zero-shot domain transfer 실험에서 improved generalization을 확인
- Prompt Tuning이 specific domain에 PLM이 overfitting되는 것을 막는다는 점을 확인
- efficient multi-task serving & efficient high-performing prompt ensembling
Misc
- Prompt Tuning이 overfitting을 막고, domain shift에 robust하다는 점을 어필할 수 있을듯
- T5 model size에 따른 parameter 숫자 변화, converge까지 소요되는 시간 등은 appendix에 있음