Ma, F., Zhang, C., Ren, L., Wang, J., Wang, Q., Wu, W., ... & Song, D. (2022). XPrompt: Exploring the Extreme of Prompt Tuning. arXiv preprint arXiv:2210.04457.
요약
- 문제의식은? soft prompting이 성능은 괜찮은데, backbone model이 small or moderate scale이면 performance gap이 너무 커짐
- 모델핵심은? small/moderate backbone model에서 성능향상 + 경량화(Prompt Tuning)의 경량화(XPrompt)
- 어떻게? Soft Prompts 중에서 negative tokens는 제끼고 positive tokens만 남기도록 꾸림으로써
- 근거는? Lottery Tickets Hypothesis (LTH) 에 따르면, PLM 성능에 positive/negative tokens 있으니, 이걸 prompting에 접목, positive/negative token 구별은 Importance Score 계산을 통해
- 성능은? baseline prompt tuning methods보다 낫고, finetuning보다 나은 task도 몇 있었음
체크할 만한 사항들
- SuperGLUE에서는 Prefix-Tuning의 성능이 diverge함: prefix-tuning은 NLU가 아니라 NLG에 target되어있기 때문
code: https://github.com/BD-MF/XPrompt
- rewinding이 뭔지 보려고 했더만 readme.md 밖에 없음 (230620 기준)
주의: 본문의 prompt tuning은 P-Tuning, Prefix-Tuning, Prompt Tuning을 모두 포함하는 soft prompt tuning의 일반적인 지칭이며, specific model Prompt Tuning (Lester et al., 2021) 은 대문자로 앞글자를 표기하였음
0 Abstract
- Prompt Tuning
- 정의: PLM을 frozen한 뒤 downstream task에 대해 soft prompt만 학습
- model scale이 커질수록 finetuning 성능에 비견
- 11B 이하 parameter를 가지는 small/moderate size의 모델은 아직 finetuning과의 performance gap이 있음
- 본 논문에서는,
- trained prompt token이 downstream task에 negative impact를 줄 수도 있음을 보임
- XPROMPT 제안: prompt tuning with extremely small scale
- more parameter efficient prompt & competitive performance
1 Introduction
- PLM의 'pretrain-then-finetune': graident, optimizer state가 저장되어야 하기 때문에 parameter-inefficient
- 이를 개선하기 위한 시도들
- Prompt-Tuning: soft prompt를 input에다가 붙이고, 학습 과정에서 soft prompt만 학습, 다연히 parameter-efficient하다
- Adapter: Prompt-Tuning보다 못함, transformer layer에 intrusive modification을 가해야 하므로 less simple & less flexible
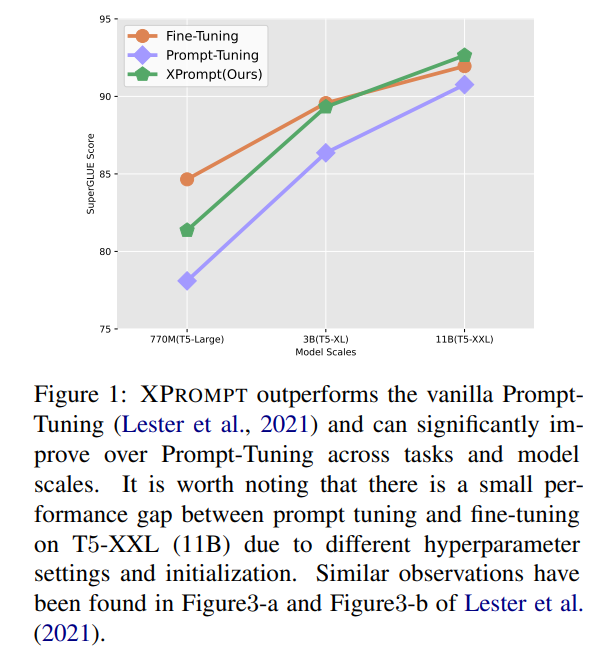
- 모델이 크면 fine-tuning이나 prompt uning이나 비슷비슷한 성능을 내지만, small models에서는 performance gap이 좀 큼 (figure 1)
- 본 논문의 해결책: Lottery Tickets Hypothesis (LTH) 를 사용
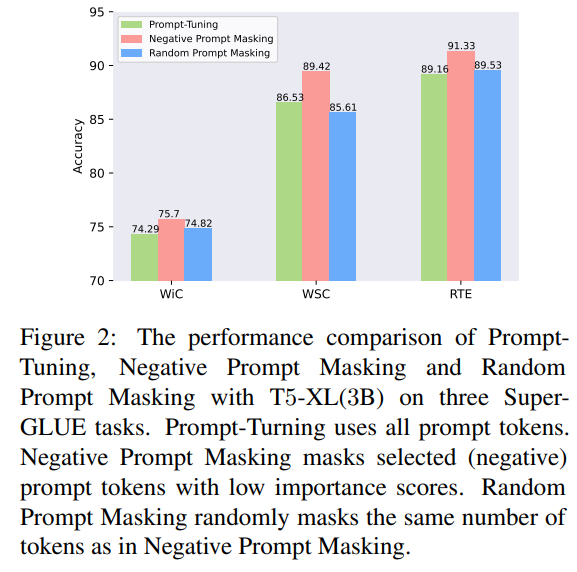
- 실제로 실험을 돌려보니까 모든 prompt token이 task performance에 동일하게 contribute하는 것도 아니고, 심지어 어떤 prompt token은 negative effect를 주기도 함: 위 figure 2를 확인하였을 때, negative prompt를 masking하였을 때 prompt tuning보다 성능이 더 높은 것을 확인할 수 있음
- LTH를 이용해 negative token을 피할 수 있다는 듯
- Lottery Tickets Hypothesis (LTH) 에 대한 간략한 설명
parameter가 너무 많은 네트워크에서 (over-parameterized) 따로 떼어놓고 같은 조건에서 학습시켜도 원래 네트워크와 비슷하거나 더 큰 성능을 보이는 sub network가 있음
LTH states that an over-parameterized network contains a sub-network that, when initialized and trained in isolation, can match or exceed the test accuracy of the original network after training for at most the same number of iterations.위와 같이 떼어놓고 학습시켜도 원 네트워크와 성능이 비슷한 sub-network를 "lottery-ticket"이라고 일컬으며, 이러한 tickets (sub-networks) 를 모아놓은 것을 "winning tickets" 라고 함
sub-network is called "lottery-tikcet", and the collection of the tickets is referred to as winning tickets in PLMs. - LTH를 prompt tuning에 접목하였을 때
- prompt tuning에서는 winning tickets을 postive tokens (entire collection of prompt tokens 사용하나 positive tokens만 사용하나 똑같은 performance를 만듦) 로 정의하고, losing tickets를 negative prompt tokens로 정의할 수 있음
- wining tickets을 identifying하는 것과 losing tickets를 eliminating하는 것
- losing tickets eliminating: hierarchical structured pruning을 통해서
- token level에서 한 번 pruing하고
- 남은 애들은 finer granularity e.g. piece-level 에서 pruning
- 이렇게 하면 effectiveness-efficiency trade-off가 있다고 함
- winning tickets identification: weight rewinding을 통해 진행
- 위와 같은 방식으로 positive prompts는 남기고, negative prompts는 제끼면 PROMPT of an eXtremely small scale, 즉 XPROMPT가 완성됨
- Experiment & Evaluation
- SuperGLUE에 실험
- moderate size model에 대해서는 finetuning에 비견할 만하고, large model에 대해서는 prompt tuning보다도 높고, 일부 task에 대해서는 finetuning보다도 높은 성능을 달성하였음
2 Related Works
2.1 Pre-trained Language Models
2.2 Prompt Learning in NLP
2.3 Lottery Ticket Hypothesis
- Frankle and Carbin, 2019
- over-parameterized network는 subnetwork가 있는데, trained in isolation에서 original network와 같은 세팅으로 학습시켜도 original network와 accuracy가 비슷한 그런 subnetwork가 있음
- 위와 같은 subnetwork를 lottery icket이라고 함
- NLP에서 위와 같은 subnetwork를 모아놓은 걸 winning tickets라고 함
- winning tickets를 이용해 transfer learning (over tasks, datasets) 을 할 수도 있고, winning tickets를 사용하면 full model 보다도 나은 성능이 나오기도 함
3 Preliminary
- prompt tuning은 input(, length는 )에 개의 soft prompt token()을 붙이고, 모든 task를 text generation으로 변경 (보통 모델은 T5 사용)
- soft prompt tokens의 parameter만 update함으로써 원래의 target y에 근접하도록 학습; 이를 수식으로 나타내면 다음과 같음
, where and
- 모델이 커질수록 prompt tuning이 effective하지만, small & moderate scale의 model에서는 prompt tuning과 finetuning 사이의 performance gap이 있음
- 연구진의 가정은 모든 soft token이 성능이 긍정적인 영향을 주지는 않을 것이고, 이를 LTH와 결합해 hierarchical pruning을 접합한 XPROMPT를 고안
4 XPROMPT
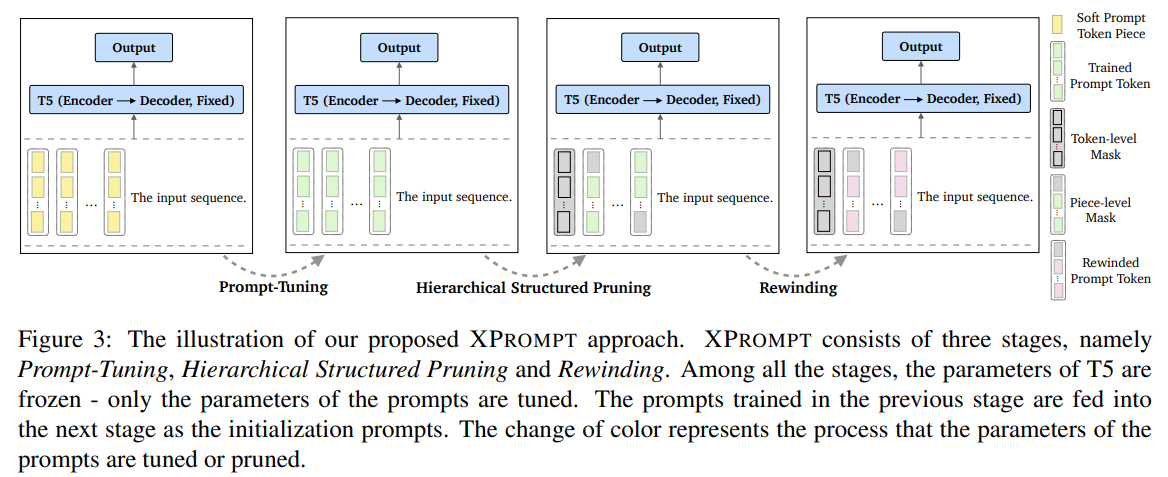
- 3단계로 구성: Prompt tuning, hierarchical structured pruning, rewinding
- prompt tuning: task에 대해 soft prompts 학습
- hierarchical structured pruning: token level pruning(soft prompt token에 해당하는 embedding 전체를 masking) 또는 piece level pruning(token의 embedding을 몇 단위로 쪼개서 각 단위마다 masking을 다르게 두는 것)을 반복적으로 진행해서 optimal soft prompt tokens & pieces identify함 (winning tickets 찾는 과정)
- rewinding: weight rewinding 이용해 soft prompt를 retrain함
4.1 Prompt Tuning
- Liang et al., 2021의 experiment setting과 거의 비슷하게 진행하여 soft prompt training 진행
4.2 Hierarchical Structured Pruning
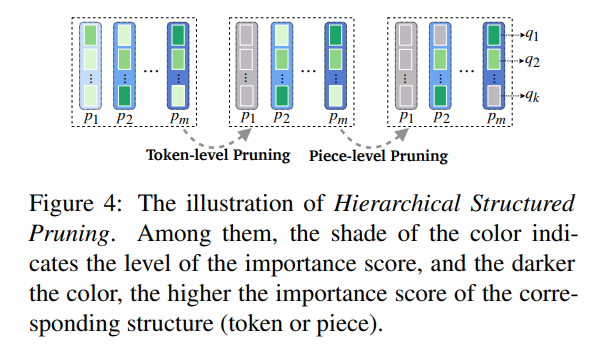
- 주의: prompt token의 embedding 전체 또는 일부분을 masking하는 것임
- Hierarchical structurd pruning의 목적: trained prompt token으로부터 (1) negative prompt token을 separate하고, (2) optimal set of soft prompts identification
- negative token을 제거하기 위해 token-level pruning을 진행하고, 남아있는 token의 piece에도 negative piece가 있을 수 있으니 piece-level pruning을 진행함
- figure 4를 확인하면, column (token-level) 과 box (piece-level) 에서 일정 수준의 importance score에 미달하면 masking (회색으로 표현) 하는 것을 볼 수 있음
- token-level과 piece-level pruning을 둘 다 함으로써 effectiveness와 efficiency 사이의 trade-off가 있음
4.2.1 Token-level Pruning
- trained soft prompt token에 mask를 씌움: where , 0d이면 mask한다는 뜻
- negative prompt token을 찾기 위해 각 token의 importance score를 계산
- Importance Score란?: expected sensitivity of the model outputs to the mask variables로, model performance에 대한 individual contribution의 영향
- low importance score는 negative token으로, high importance score는 postivie token으로 분류할 수 있음
Imporance Score
4.2.2 Piece-level Pruning
- prompt token의 embedding 를 k-pieces로 동일하게 나눠줌:
- 이후 token-level pruning과 마찬가지로 을 에 곱해 piece-level masking 진행:
- token-level과 마찬가지로 piece 단위별로 importance score 계산, 해석 또한 동일하게 진행
Imporance Score
4.3 Rewinding
- LTH에 따르면 sparse subnetworks (the unpruned prompts) can be trained in isolation to the same accuracy with the original network (all prompts) 라고 함
- pruning stage에서 선택된 optimal tokens는 weight을 reset 하고, 처음에 학습했던 strategy를 이용해 살아남은 prompt tokens 다시 학습함
5 Experiments
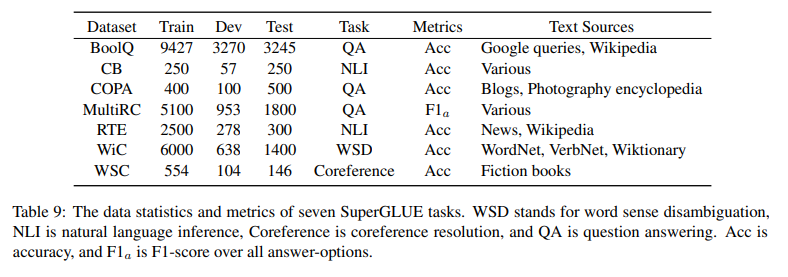
- 5.1 dataset: SuperGLUE (dataset에 대한 설명은 상단의 Appendix E table 9 참조)
- 5.2 baseline models: 여기 있는 baseline의 논문들 한 번 싸악 정리하는 게 좋을 듯!
- finetuned T5
- Prompt Tuning: 이건 안 읽어봤던 듯?
- P-Tuning, P-Tuning V2: P-Tuning V2만 읽어봤는데, P-Tuning V2의 경우 모든 layer의 soft prompts에 해당하는 attention matrix를 update하게 됨
- Prefix-Tuning: 모든 transformer layer에서 input에 prefix를 independently prepend
5.3 Implementation
Experiment Settings
나중에 내가 실험에 쓸 수도 있어서 좀 주의깊게 봤음

- 주의: Verbalizer를 사용하였음 & OpenPrompt library 사용 (상단의 Appendix E table 10 참조)
- text-totext format으로 바꾸는 과정에서 task name과 task example은 의도적으로 누락했다고 함
- backbone model은 3종류의 T5 사용:, Large(770M), XL(3B), XXL(11B)
- lester et al., 2021의 setting과 똑같이 함: 100 epochs, lr 0.3 (constant lr), batch size 16
- token 개수를 20개보다 늘려도 성능 향상이 크지 않아서 default token 개수를 20개로 설정
- piece (token embedding을 동일하게 나누는 k, 상단 참조) 개수는 16
- pruning frequencies linearly serached: {10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%}
- weight rewinding은 한 번만 적용
- validation dataset으로 early stopping 적용
- Adafactor w/ weight decay 1e-5 사용
6 Results
6.1 Results on High-resource Scenarios

XPROMPT는 다른 prompt tuning models에 비해 성능이 향상되었고, finetuned model과의 performance gap을 줄이는 데에 성공했음 (backbone model이 무엇이든 관계없이)
- XPROMPT와 vanilla Prompt Tuning을 비교하는 게 맞음
- Prompt Tuning과 P-Tuning은 비슷한 성능을 보임 (P-Tuning V2의 결과는 Appendix A의 table 8 참조)
- (WiC, CB, RTE w/ T5-X), (COPA, WiC w/ T5-Large), (WSC, CB, RTE, Boolq, MultiRC w/ T5-XXL) 에서는 finetuning보다 더 나은 성능
- model scale을 막론하고 finetuning과 prompt tuning 사이의 performance gap을 채우고 있음
6.2 Results on Low-resource Scenarios
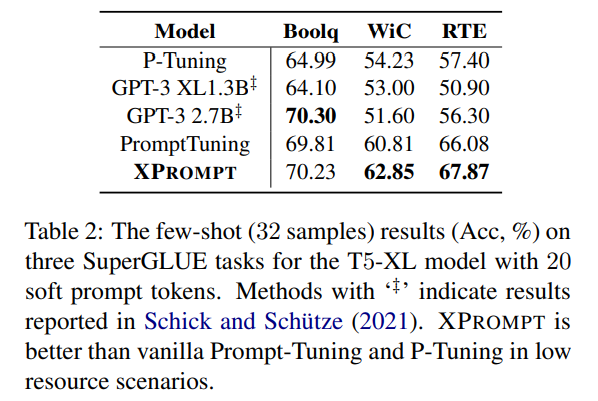
- prompt learning이 low-resource regime에서 surprisingly effective (Schick and Schuetze, 2021) 하므로, XPROMPT를 32-shot setting 하에서 실험하였음 (32 examples as the new training set for each task)
- 뉘앙스 보니까 1 epoch만 돌린 게 아니고, dev set에 대해서 multiple epoch 돌리고 best acheckpoint 사용한 듯
- Boolq, WiC, RTE에 대해 기타 prompting보다 성능향상 있었다는데 왜 3개만 했을까?: GPT-3에 실험한 결과를 Schick and Schuetze, 2021 여기서 끌어왔는데 원 논문에서 실험을 3개만 헀던 것일 수도 있고..
7 Analysis and Discussion
- 7.1 positive prompt와 negative prompt는 존재함
- 7.2 vanilla Prompt Tuning과 비교해서 parameter가 엄청엄청 줄었음
- 7.3 2-level로 pruning하는 게 성능 향상에 좋음
- 7.4 prompt length는 20이 한계
- 7.5 prompt transfer에도 XPrompt가 좋음
7.1 Do Positive Prompts and Negative Prompts Exist?
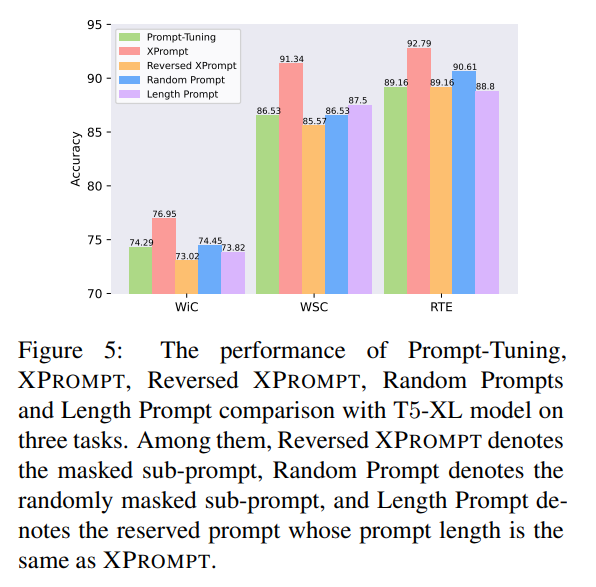
hierarhcical structured pruning을 통해 negative tokens와 positive tokens를 구별할 수 있었음
- figure 5의 'Prompt-Tuning', 'XPrompt'를 확인
- vanilla prompt tuning보다 XPROMPT가 성능이 더 좋다는 것은 positive tokens를 잘 뽑아냈다는 것을 의미
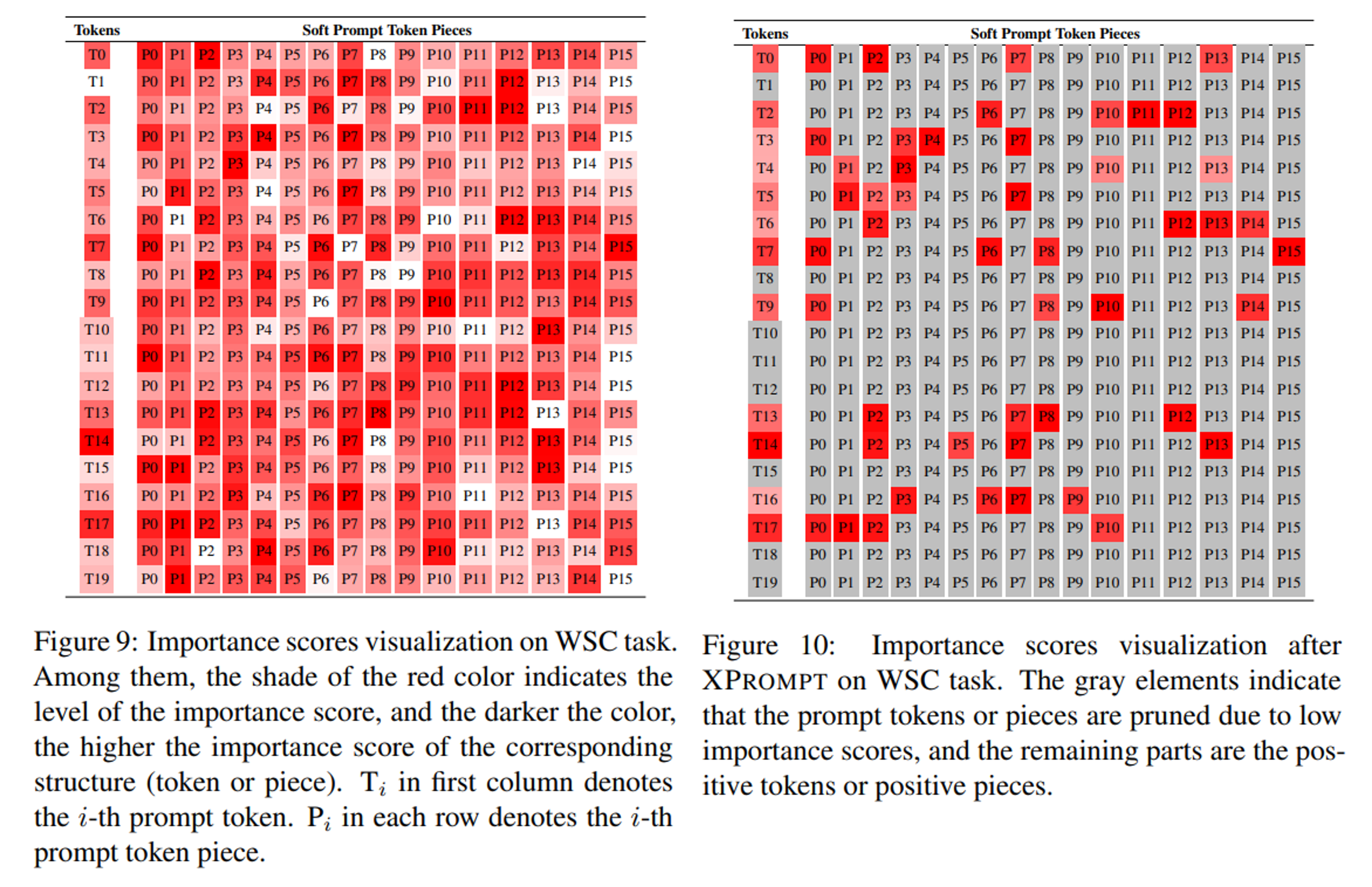
- gradient saliency map(appendix D figure 9, figure 10)을 그려보면 pruned된 파트가 회색으로 나타나서 그 결과를 확연히 알 수 있음: WSC task에 대한 XPrompt의 saliency map임
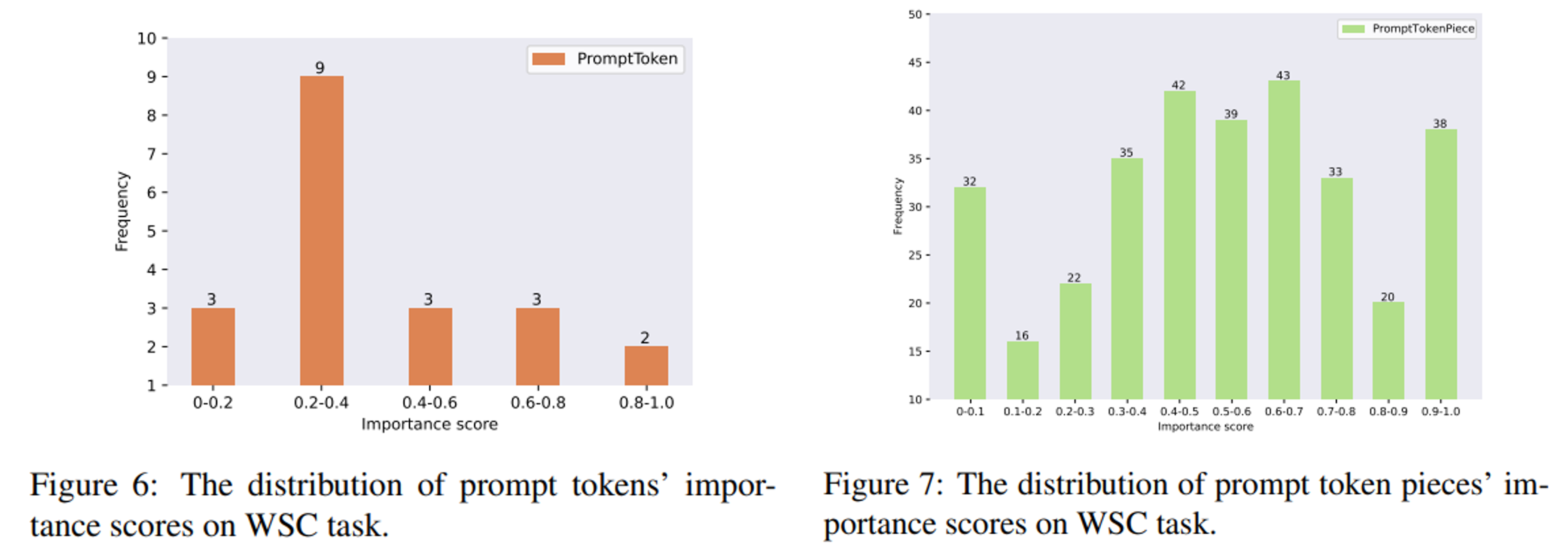
-
(Appendix B) WSC task에 적용한 XPrompt를 살펴보면, token level importance score는 low score에 몰려있고, piece level importance score도 분포가 high importance score 쪽으로 몰려있지는 않음
-
결과적으로 XPROMPT는 전체의 15%에 해당하는 positive subprompts 만 사용 (full prompting보다 +4.8% 성능 상승)
negative prompts가 존재하며, 성능에 부정적 영향을 끼침
- figure 5의 'XPrompt', 'Reversed XPrompt', 'Random Prompt', 'Length Prompt'
- 새로운 실험 세팅: Reversed XPROMPT, Random Prompt, Length Prompt
- Reversed XPROMPT: low importance score 받은 prompt만 사용
- Random Prompt: rewind stage에서 token과 piece를 randomly mask
- Length Prompt: reserved prompt whose prompt length is the same as XPROMPT (정확히 뭔지는 모르겠네)
- Reversed XPROMPT가 성능 가장 안 좋아 negative prompts의 존재를 확인할 수 있음
7.2 Parameter Efficiency
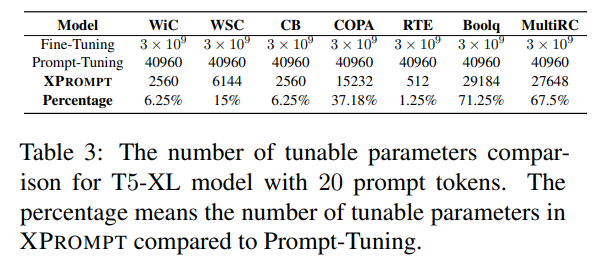
XPROMPT는 Prompt-Tuning보다 parameter-efficient함
7.3 Granularity of Pruning
Token-level과 piece-level pruning 모두 필요
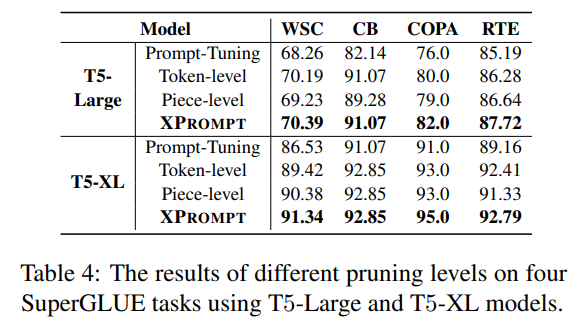
- table 4 를 확인하면, token level만 하든, piece level만 하든 one level만 하는 것보다 two level로 pruning하는 게 더 좋은 성능을 이끌어냄을 알 수 있음
- efficiency-effectiveness trade-off라고 해서 대단한 게 있나 했더니 그런 건 아니고 2-level로 진행함으로써 시간이 더 걸린다는 걸 포장한 듯
7.4 Prompt Length
prompt length 20 넘으면 성능 향상 조금밖에 없음 (이건 XPROMPT는 전부 해당되고, Prompt-Tuning의 경우에는 3/4 task에서 해당됨)
7.5 Prompt Initialization and Transfer
Prompt Initialization이 XPROMPT에서 큰 영향을 끼치며, XPrompt Transfer는 performance 향상으로 이어질 수 있음
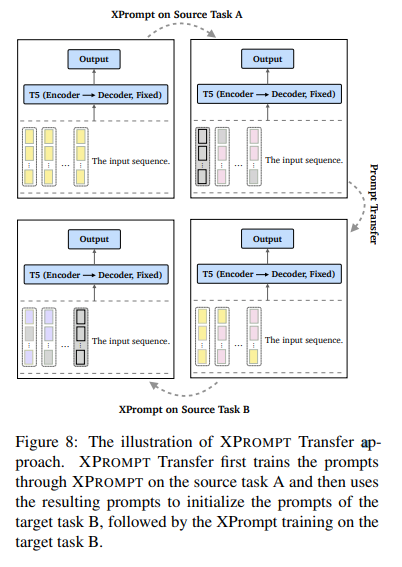
- XPrompt transfer 어떻게 했는지 (Appendix C)
- source task에 prompt 학습하고 학습된 prompt를 target task의 initialized prompt로 사용, 이후 target task에 train함
- SPoT과 다른 점으로는, "we do not use the trained prompts to initialize the prompts for the target task"라고 하는데, "XPrompt Transfer first trains the prompts through our XPrompt on the source task and then uses the resulting prompts to initialize the prompts of the target task"라고 적어놓은 것을 보면 둘이 같은 학습방법 아닌지?
- (본문) SPoT (Vu et al., 2021) 처럼 source task에 prompt initialization을 하고 target task에 접목하였음 (prompt transfer)

- 의문: RandomUniform Initialization은 실제로 어떻게 진행이 된 것이고, SampledVocab은 대체 무엇인가?
- rewinding phase가 없어도 vanilla TaskTransfer보다는 나은 성능
8 Conclusions & Limitations
Conclusions
- prompt tuning과 fine-tuning 사이의 performance gap을 메우려는 시도 especiallt with small & moderate models
- Lottery Ticket Hypothesis를 본따, hierarchical structured pruning을 사용하여 token level과 piece level에서의 positive tokens와 negative tokens를 분리 및 postive tokens를 identify함: XPROMPT 만드는 과정
- parameter efficient하고, competitive performance를 기록
Limitations
- pruning한 다음에 rewinding할 때 전체 모델을 특정 compression ratio로 줄여버리는데, 과연 trial training 없이 어떻게 optimal compression을 알 수있을까?
- 가능만하다면 efficient할텐데
- 이외 multi-task learning scenario, out-of-domian, prompt ensembling 등도 시도해볼 수 있을 듯
Idea, further readings
풀리지 않는 의문
- rewinding은 대체 어떻게 진행되는 건가?
- 왜 ablation study 및 analysis 에서 SuperGLUE의 몇몇 task에 대해서만 실험했는가?
Idea: Prompt methods on SuperGLUE처럼 prompting on legal benchmark datset? (LexGLUE 또는 lbox_open 등)
다음으로 읽을 논문들: baseline models, SPoT (Vu et al., 2021), He et al., (2021)의 multi-task learning scenario(HyperPrompt), Lester et al., (2021)의 domain shift, prompt ensembling
