Su, Y., Wang, X., Qin, Y., Chan, C. M., Lin, Y., Wang, H., ... & Zhou, J. (2022, July). On transferability of prompt tuning for natural language processing. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (pp. 3949-3969).
Abstract
- Prompt Tuning의 장점?: PLM의 parameter를 다 학습할 필요 없이 소수의 parameter만 학습시켜도 괜찮은 성능을 내기 때문에!
- Prompt Tuning의 단점?: 학습되는 parameter가 너무 적죠? 그래서 convergence 오래 걸리죠?
- convergence가 너무 오래 걸리는 prompt tuning을 해결하기 위해 knowledge transfer를 들고 왔음: prompt를 transfer 하는 것
- prompt transfer: 모델 사이 & task 사이
- result:
- zero shot setting에서는 similar tasks에서 학습되었으면 같은 PLM안에서 task 사이에서 prompt transfer를 하든, 서로 다른 PLM 사이에서 prompt transfer를 하든 괜찮은 성능을 낸다!
- 한 task에서 학습된 prompt를 다른 task의 prompt로 initialization할 때, 비슷한 task에서 학습된 prompt가 비슷한 task로 가건, 비슷한 task의 다른 PLM으로 가건 tuning의 속도가 빨랐다!
- interpretability:
- 왜 위 result와 같은 성능이 나왔는가?를 탐구하기 위해 2가지 metric을 이용해 계산해보고, activated neuron의 overlapping rate 이 transferability에 영향을 미침 == "show the prompts stimulate PLMs is essential"
- 향후 적용할 수 있는 방향: improving prompt tuning by prompt transfer, prompts' stimulation to PLMs
1 Introduction
-
Prompt Tuning이란?
- soft prompt 라고 하는 learnable virtual token을 input sequence 앞에 붙이는 것
- 잘만 한다면, finetuning하는 것과 비슷한 성능을 낼 수 있음
-
다만, finetuning보다 convergence가 느리다 는 게 치명적 단점
- 그래서 eficiency를 어떻게 향상할 수 있을까?
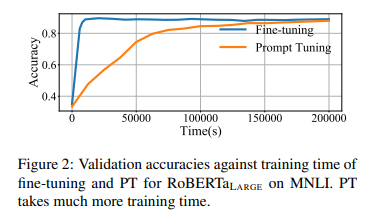
- 그래서 eficiency를 어떻게 향상할 수 있을까?
-
knowledge transfer에 눈을 돌려볼까?
- 어차피 soft prompts만 학습됐으니까 요 tokens만 똑 떼다가 붙이면 knowledge transfer가 되지 않을가?: prompt transfer
-
prompt transfer가 가능한지 task & model 수준에서 탐구해보자!
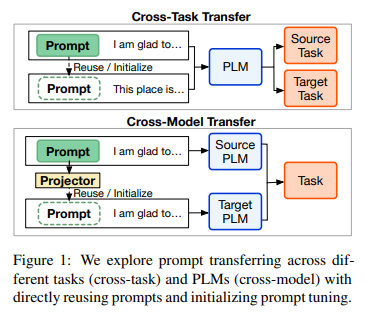
- 그래서 실험은 setting은 어떻게 했는데?
- cross-task transfer setting: 6개 category의 17 NLP tasks
어차피 task만 달라지니까 soft prompts만 source task에서 똑 떼다가 target task에 붙이는 것으로 실험 - cross-model transfer setting: RoBERTa, T5
모델이 다르니까 당연히 soft prompts를 cross-task처럼 사용할 수는 없고, prompt projectors를 사용해서 source model에서 target model로 soft prompts가 잘 이동할 수 있도록 했음
- cross-task transfer setting: 6개 category의 17 NLP tasks
- 그래서 실험은 어떻게 했는데?
- zero shot transfer performance (zero shot setting) 으로 cross-task transfer, cross-model transfer가 잘 되는지 실험!
- soft prompts를 transfer 해서 initialization 해서 얼마나 더 빠르게 학습하는지 실험!
- 그래서 결과는 어떻게 됐는데?
- task가 비슷하면 준수한 성능, task가 완전히 다르면 박살난 성능, cross-model에서도 비슷한 task라면 prompt projectors와 관계없이 괜찮은 성능!
- prompt transfer & initialization했더니 더 prompt tuning이 더 빠르고, 성능도 일부 향상
- interpretability
- 여러 가지 metric을 만들어서 transferability indicator로 사용
Contribution
- cross-task, cross-model의 soft prompts transferability 탐색
- soft prompts initialization 가능성 탐색: efficiency & effectiveness 확보
- metric을 만들어서 어떤 요소(결국에는 model stimulation)가 PLM의 soft prompts에 효과적인지
2 Related Works

- hard prompting의 단점: verbalizer가 필수적으로 따라붙어야 하는데, verbalizer setting에 따라 성능이 크게 바뀜
예컨대, sentiment analysis에서Sentence A. It was [MASK].에서[MASK]안에 들어갈 단어good/bad와 이를 label(0/1)로 바꿔주는 verbalizer로 무엇을 쓰느냐가 성능에 큰 차이를 미침 - 이하는 soft prompting
Li, X. L., & Liang, P. (2021). Prefix-tuning: Optimizing continuous prompts for generation. arXiv preprint arXiv:2101.00190.
- GPT3의 prompting에서 영감을 받아 prefix-tuning 제시: GPT3의 prompting
e.g. 다음을 번역하라대신 vector 형태의 prefix 제시 다음을 번역하라라는 형태의 prompting (task description) 은 굉장히 discrete하며, vector로 표현된 continuous prefix (or prompt)는 다양한 task + 동시에 여러 개의 task를 적용할 수 있음- low data setting (< 500) 에서는 finetuning보다 prefix tuning이 더 나았는데, 이는 더 적은 양의 정보가 prefix에 압축적으로 저장되는 반면, finetuning에서는 더 많은 parameter에 분산되어 저장되기 때문으로 이해할 수 있음
- XSum dataset 등 summarization에서 강력한 성능
Lester, B., Al-Rfou, R., & Constant, N. (2021). The power of scale for parameter-efficient prompt tuning. arXiv preprint arXiv:2104.08691.
- 상단의 prefix tuning을 잇는 prompt tuning
- T5는 prompt tuning이 적합하지 않음: span corruption objective 때문인데, sentinel token을 추가하여 극복할 수 있음
- train과 test의 domain(Bio, Wiki, Movie etc.)이 다른 domian shift에서도 prompt tuning은 robust함
- prompt ensemble했을 때 single prompt보다 전반적으로 성능이 좋았음
- prompt가 무엇을 의미하는가(interpretability)?: clustering을 했을 때 word representation을 학습하는 것과 매우 비슷함
Gu, Y., Han, X., Liu, Z., & Huang, M. (2021). Ppt: Pre-trained prompt tuning for few-shot learning. arXiv preprint arXiv:2109.04332.

- 뇌절: prompting을 large corpus에 pretraining해았다.. (few shot setting에서도 효과적으로 학습할 수 있는 soft prompt의 initialization을 위하여!)
- 왜? few-shot setting에서는 finetuning보다 prompt tuning이 더 안 좋은 성능: soft prompt가 학습하는 대상이 적어서..
- prompt tuning은 labeled data에서 여러 task를 수행하면서 prompt pretraining을 진행
- 결과가 나쁘지는 않았는데, classification에 치중되어 있어서 진짜로 universal한가?라는 의문이 있을 수는 있을 듯
Vu, T., Lester, B., Constant, N., Al-Rfou, R., & Cer, D. (2021). Spot: Better frozen model adaptation through soft prompt transfer. arXiv preprint arXiv:2110.07904.
- prompt transfer 시도 & NLP dataset이 엄청 많음 (26개)
- transfer effectiveness 탐구
3 Preliminary
- 실험 세팅에 관한 내용들
3.1 Prompt Tuning
- prompt tuning을 좀 formal하게 써보면 다음과 같음:
input sequence
soft prompts
,
- soft prompts 를 input sequence 앞에다 갖다 붙이는 것, 단 embedding dimension 가 갖게끔
- training objective: 아래 likelihood 을 maximize하는 것
- 원래 나와야 할 output 가 나올 확률을 높이는 방향으로 학습이 되어야 함: RoBERTa 같은 경우는 MLM이므로 soft prompts 앞에
[MASK]붙여서 soft prompts + PLM이[MASK]== 를 채우도록 soft prompts를 학습시킴
3.2 Investigated NLP Tasks
- 6개 category, 17개 NLP tasks
- Sentiment Analysis: IMDB, SST-2, laptop, restaurant, Movie Rationales, TweetEval
- NLI: MNLI, QNLI, SNLI
- Ethical Judgement: deontology, justice
- 윤리적 판단 (개인적으로는 reasonable한지 NLI 느낌이긴 했음)
- Paraphrase Identification: QQP, MRPC
- 주어진 선택지가 context에 대한 적절한 paraphrase인지 판단
- QA: SQuAD, NQ-Open
- Summarization: Multi-News, SAMSum
3.3 Investigated Models
- RoBERTa-large: MLM의 대표주자
- token 하나씩밖에 inference 안 돼서 QA나 Sum 같은 generation task는 실험 못함
- T5-XXL: seq2seq pretraining의 대표주자
4 Cross-Task Transfer
- 위에서 언급했던 대로 cross-task 에서 (4.1) zero shot setting에서 prompt transferability를 확인해보고, (4.2) prompt tuning with transfer의 effectiveness와 efficiency를 확인
4.1 Zero-shot Transfer Performance
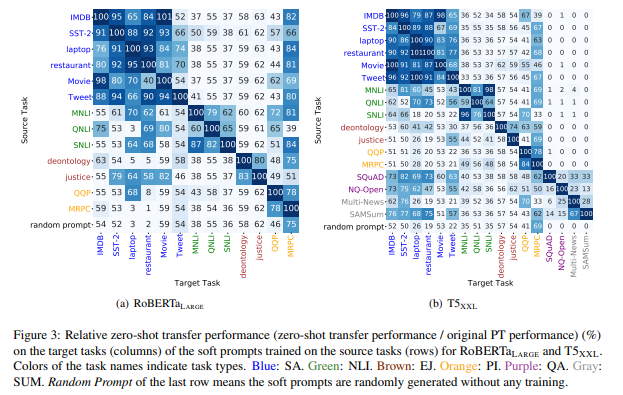
- source task에서 학습한 soft prompts를 target task에 바로 붙여서 zero shot 성능 확인
- 결과 (1) 비슷한 task이면 transfer 성능 좋고, source task의 데이터가 target task의 데이터보다 더 많으면 오히려 성능이 더 좋음
- 결과 (2) 비슷한 task가 아니면 transfer 성능 나쁘고, random initializated prompts와 비슷한 성능
- 결과 (3) 다른 type의 task임에도 transferability가 괜찮은 것들이 있었는데, 왜 이게 통했는지는 추후 설명
4.2 Transfer with Initialization
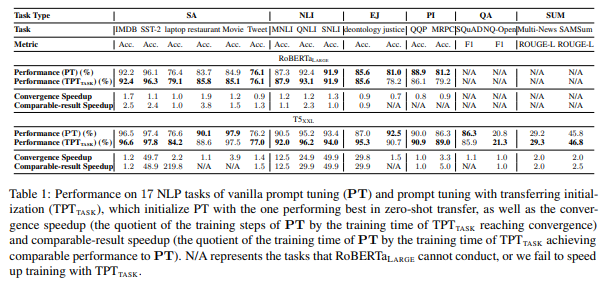

- source task에서 학습된 soft prompts를 target task에 붙이고 추가 학습 진행
- 이러한 tasnferable prompt tuning을 라 칭함
- 4.1에서 가장 zero shot setting에서 성능이 좋았던 source-target task 쌍을 이용해 soft prompt transfer + 추가학습까지 진행
- 결과 random initialization부터 시작한 soft prompts와 성능이 비슷하거나 더 좋았고, training time도 더 적었다
5 Cross-Model Transfer
- cross-model transfer의 궁극적 목표는 small PLM에서 large PLM으로 soft prompts를 옮길 수 있을지에 대한 해답을 구하는 것: 그래서 source model은 small PLM인 RoBERTa고, target model은 large PLM인 T5임
- 4 cross-task transfer처럼 soft prompt를 그대로 쓸 수 없음: PLM이 학습된 방식이 다르기 때문에 embedding space, weight 모두 다를 것임
- 그래서 prompt projection을 이용
5.1 Cross-Model Prompt Projection
- 어떻게 prompt projection을 훈련시키는 게 좋은가에 대한 파트
- 두 가지 learning objectives를 사용: distance minimizing, task tuning
- prompt projection은 formal하게 다음과 같이 정의할 수 있음
source PLM의 soft prompts (은 soft prompts의 length)
target PLM의 soft prompts (은 soft prompts의 length)
training objective: 와 의 difference를 minimize
Distance Minimizing
minimizing L2 distance
- 같은 task에 대해 source model에서 를 학습하고 이를 target model로 projection한 와 target model에서 처음부터 학습한 사이의 L2 distance를 minimize하여 prompt projector 학습
Task Tuning
- source PLM에서 task A를 대상으로 soft prompts를 학습하고, 같은 task를 대상으로 target PLM에서 또 다시 supervised learning 해서 prompt projector를 학습
- zero shot setting의 결과와 비슷하게, 다른 type의 tasks에서 좀 agnostic & generalize되지 않을까 기대
5.2 Zero-shot Transfer Performance
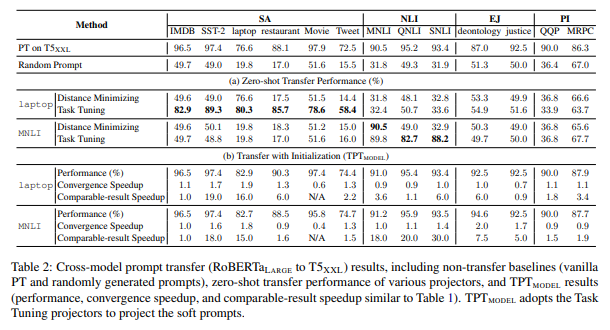
- 결론 1 distance minimizing은 projector 학습 대상 task는 잘 transfer하는데, unseen task는 random prompt 수준: not practically usable
- 결론 2 task tuning은 비슷한 type tasks에서 unseen task라 하더라도 generalize됨: cross model prompt transfer 가능할 듯
- 결론 3 그럼에도, task tuning은 다른 type tasks에는 못 써먹음 (4.1과 비슷)
5.3 Transfer with Initialization
- 5.2에서 distance minimizing보다 task tuning의 성능이 더 좋았으니, task tuning을 이용해 source model에서 학습된 soft prompts를 projection해서 target model의 soft prompts로 initialization 한 후 추가학습 진행
- 위와 같은 작업을 이라 칭함
- 결론 이 soft prompts from initialization과 비슷하거나 더 나은 performance + 더 짧은 training time, 단, 비슷한 type task일 경우
- 어쨌거나 prompt tuning의 efficiency와 effectiveness 향상의 가능성은 보인다
6 Exploring Transferability Indicator
- 4와 5에서 계속 실험을 하기는 했는데, 왜 cross-task, cross-model에서 transferability가 성립하는가? 를 설명
- 위의 질문에 답하기 위해 prompt similarity metrics를 설정하고, zero-shot transfer performance와의 관계를 확인
6.1 Prompt Similarity Metric
Embedding Similarity
- soft prompts를 그냥 embedding으로 간주하고 embedding similarity를 계산
- Euclidean similarity와 cosine similarity를 계산
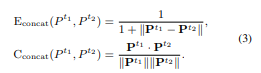
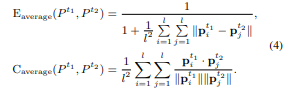
Model Stimulation Similarity
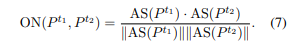
- 각각의 soft prompt가 어떻게 PLM을 stimulate하는가 (how they stimulate the PLMs)
- 위의 측정은 Transformer의 FFN layer에서 따와 ReLU 통과한 positive neuron은 activated neuron으로 간주함 (실제로는 positive neuron을 1로 간주하고 one hot encoding)
- similarity metric: overlapping rate of activated neurons
- 실제 과정: soft prompt 넣고 target y 혹은 가장 첫 token의 연산 과정을 일부 layer의 neurons 이용해 보는 것
- RoBERTa의 input soft prompts 앞에
[MASK]token을 부텨서[MASK]token의 activation state를 보고, T5는 decoder의 첫 번째 token의 activation state를 확인함 - PLM의 layer L개의 activation state를 모두 concat해서 overal activation state 계산
- 실제 모델은 top 3 layer만 task-specific하므로 으로 놓고 activation state 구했음
- 이후 task1의 prompt 과 task2의 prompt 의 overlapping activated neurons similarity metric 를 cosine similarity로 구함
- RoBERTa의 input soft prompts 앞에
6.2 Experimental Results
실험 내용
- similarity metrics가 같은 tasks에서 학습된 soft prompts인지, 다른 tasks에서 학습된 soft prompts인지 구별할 수 있는가?
- 그래서 seed만 다르게 해서 학습한 같은 task의 soft prompts, 다른 task에서 학습된 soft prompts의 metrics를 비교
- similarity metrics로 계산한 수치가 zero-shot transfer performance와 궤가 맞는가?
실험 결과: cross-task
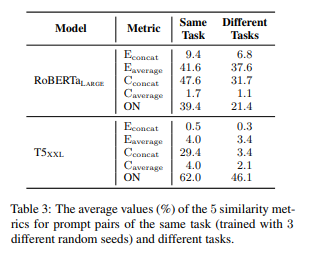
- similar/different task prompt 구별: metric이 (그럭저럭) 잘 동작한다
- euclidean distance(분모로 보내줬음)나 cosine similarity나 수치가 낮으면 덜 비슷한 것, 수치가 높으면 더 비슷한 것
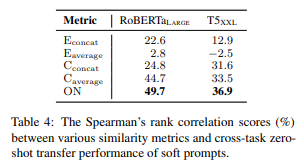

- zero-shot transfer performance 설명가능성: heatmap의 결과와 similarity score와의 상관관계를 구했을 때 ON metric이 가장 correlation 높았음
- 이걸로 봤을 때는 ON이 가장 잘 설명하는 metric이기는 함: model stimulation이 embedding 거리 계산보다 더 잘 설명한다
- T5보다 RoBERTa 더 잘 설명: 모델이 클수록 비슷한 일을 하는 neuron이 많기 때문에(redundancy) 어쩔 수 없고, 더 작은 T5 모델을 썼을 때에는 더 잘 설명함
실험 결과: cross-model
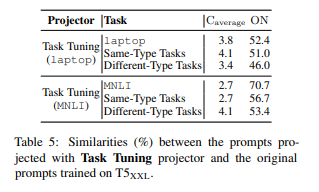
- 위 cross-task처럼 similar task에서는 ON metric이 높고, different task에서는 metric이 낮다는 대동소이한 결론
- 마찬가지로, ON metric이 metric보다 나음
7 Conclusion
- cross tasks: soft prompts는 추가학습 없이도 비슷한 task면 그대로 갖다 쓸 수 있다.
- cross model: 모델이 달라도 prompt projector가 있으면 이미 학습된 soft prompts를 사용할 수 있다.
- 이미 학습된 soft prompts를 initialized prompts로 from scratch보다 더 빠르고 비슷하거나 더 높은 성능을 내도록 학습할 수 있다.
- embedding의 거리보다는 model stimulation이 측정과 설명에 더 좋은 도구더라.
Comment
- 이전 연구들을 살펴본다면 왜 이런 실험(cross-task, cross-model)을 했는지 충분히 이해가 간다.: 그럼에도 cross-domain(이전 연구)과 cross-task는 약간 중복이 있는 감이 있지만, 그래도 cross-task가 더 큰 범주니까 ok
- 내용이 간결하고 깔끔하다.
- related works가 상대적으로 불충분해보임
- metric이 유의미하다는 해석의 근거가...?
- 한계: 결국 universal한 soft prompt는 아직 힘든가?

4개의 댓글

그 동안 프롬프트 관련된 많은 발표들을 들었는데, 이번 발표를 계기로 prompt에 대한 전반적인 taxonomy를 정리할 수 있었습니다 !
그 뿐만 아니라 cross-task / cross-model transfer라는 흥미로운 실험을 통해 prompt tuning의 가능성을 더 확장해주는 논문이었던 거 같습니다.
좋은 논문 발표 감사합니당 ( _ _ )


prompt tuning이라는 유사한 주제로 계속해서 다른 부분을 설명해주셔서 많이 도움되었습니다!! 제가 하고 있는 연구에도 적용이 가능할지 아닐지 확인해보고 싶어서! 그런 좋은 기회를 주셔서 감사합니다 ~~
prompt에 관심이 많았는데 prompt tuning이라는 새로운 개념을 알게 된 논문이었습니다 ! task/model로 나누어서 비교한 점이 인상깊고 metric으로 설명가능성을 도출한것이 인상깊네요 ~~ ! ON이라는 메트릭도 처음봤는데 흥미로웠습니다! 감사합니다 🙏🏻