모든 강의 이미지 출처는 [인프런] 쿠버네티스 어나더 클래스(지상편) - Spring 1,2 입니다.
Section 8. Application 기능으로 이해하기 -Probe
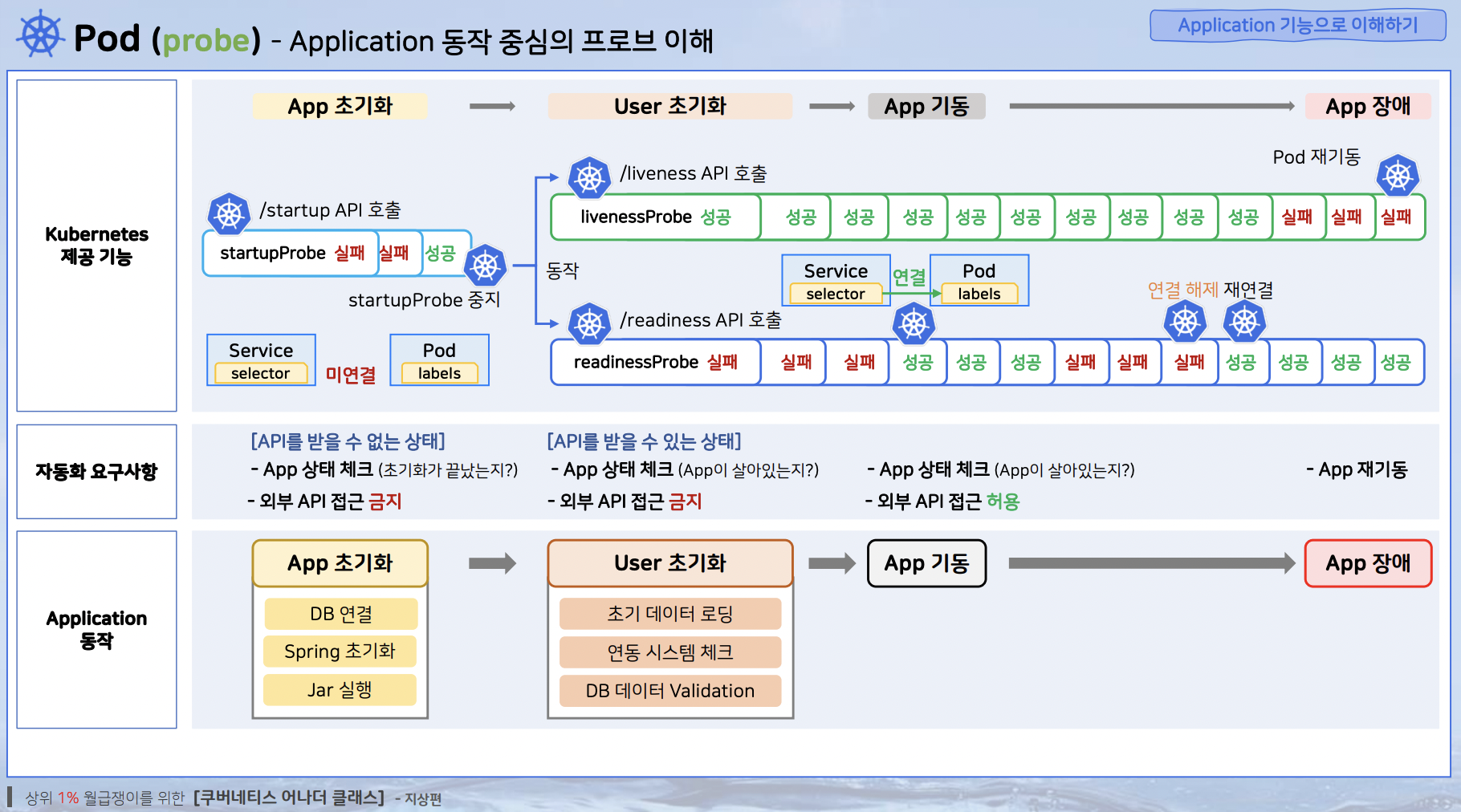
Probe의 기본 개념
- 애플리케이션 구동 시점과 실행 과정 속에서 정상적으로 트래픽을 받을 수 있는지 애플리케이션의 상태를 검사한다.
- Probe를 구성하는 주요 설정값은 다음과 같다.
initialDelaySeconds: Probe가 시작되기 전 대기 시간으로 default는 0초이다.periodSeconds: Probe를 수행하는 빈도(초)로 기본값은 10초이다.timeoutSeconds: Probe 타임아웃 시간(초)으로 기본값은 1초이다.successThreshold: Probe가 실패한 후 성공으로 변경되기 위한 연속 성공횟수이다. 기본값은 1이다.failureThreshold: Probe가 실패하면 Kubernetes는 failureThreshold 횟수 만큼 Container 재시작을 시도한다. 기본값은 3이다.
- Probe는 용도에 따라 Startup, Liveness, Readiness Probe로 나누어져 있다.
Startup Probe
- 느리게 구동되는 컨테이너를 관리하기 위한 대안으로, 해당 프로브가 성공할 때 까지 다른 프로브를 활성화하지 않는다.
- Liveness, Readiness Probe와 다르게, 애플리케이션 구동 시점에 단 한번만 수행된다.
Liveness Probe
- 애플리케이션이 구동된 이후 주기적으로 애플리케이션이 정상 구동되고 있는지 확인하는 Probe.
- Liveness Probe가 실패한 경우, 파드의 재시작 정책(Restart Policy)에 따라 컨테이너를 재시작한다.
- 재시작에도 실패하는 경우, kubelet 은 5분으로 제한되는 지수 백오프 지연(Back-off delay) 을 통해 재시작을 시도한다.
Readiness Probe
- 파드가 새로 띄워진 후, 애플리케이션이 트래픽을 받을 수 있는 정상 상태가 되었음을 보장하기 위한 Probe.
- Readiness Probe가 실패한 경우, NotReadyAddr 로 분류되어 서비스 로드밸런서에서 제외된다. 해당 상태 검사를 통해, 준비되지 않은 애플리케이션으로 사용자 요청이 들어오는 것을 방지할 수 있다.
- Liveness Probe와 동일하게 한번만 수행되는 것이 아닌, 설정된 periodSeconds 주기마다 컨테이너의 상태를 검사한다.
API 날려보며 프로브 동작 확인하기
▶ startup probe 동작 확인


[System] App is started로그 출력 이전에는 startupProbe가 실패하고, API 호출 시에도 응답없음.[System] App is started로그 출력 이후에는 startupProbe가 성공하고, API 호출 시에도 정상응답이 출력됨.
▶ liveness & readeness probe 동작 확인


- startup probe 성공 이후, readiness & liveness probe가 호출되며 readinessProbe가 성공하기 전에는 내부 호출은 성공해도 외부 호출이 실패함. → 서비스 대상에서 제외되기 때문이다.


- readinessProbe까지 성공하면 내부 호출과 외부 호출 모두 성공하는 것을 확인할 수 있다.
[미션] startupProbe 실패와 Pod 무한 재기동
Quiz) startupProbe가 실패 되도록 설정해서 Pod가 무한 재기동 상태가 되도록 설정해 보세요.
▶ Startup Probe의 failureThreshold 값을 1로 설정하여 /startup API 호출이 1회만 실패해도 파드가 재시작하도록 한다.
startupProbe:
httpGet:
path: "/startup"
port: 8080
periodSeconds: 5
failureThreshold: 1▶ 결과
# pod에 발생한 event 내용 확인
[root@k8s-master ~] kubectl events --for pod/{파드명} -n anotherclass-123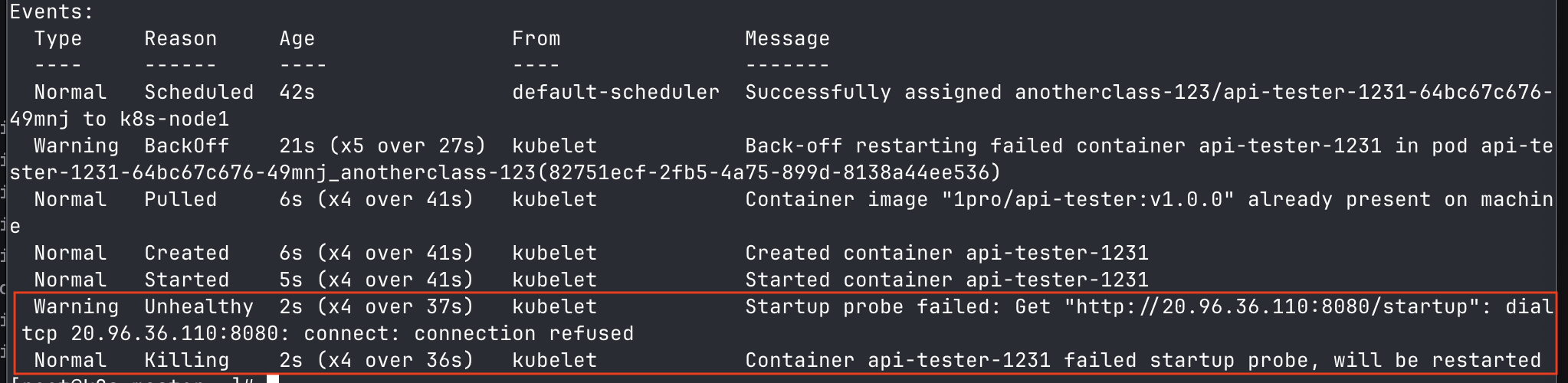

- startup probe 실패로 인해, 5번 재시작되는 파드를 확인할 수 있다.
[미션] 일시적 장애 상황
Quiz) 일시적 장애 상황(App 내부 부하 증가)가 시작 된 후, 30초 뒤에 트래픽이 중단되고, 3분 뒤에는 App이 재기동 되도록 설정해 보세요.
▶ Readiness Probe의 periodSeconds 값을 10, failureThreshold 값을 3으로 설정하여 30초 후, 서비스 대상에서 파드가 제외되도록 한다.
▶ Liveness Probe의 periodSeconds 값을 60, failureThreshold 값을 3으로 설정하여 3분 후, 파드가 재시작하도록 한다.
readinessProbe:
httpGet:
path: "/readiness"
port: 8080
periodSeconds: 10
failureThreshold: 3
livenessProbe:
httpGet:
path: "/liveness"
port: 8080
periodSeconds: 60
failureThreshold: 3▶ 결과
# pod 목록 변화를 지속적으로 출력 (-w 옵션)
[root@k8s-master ~] kubectl get pods -n anotherclass-123 -w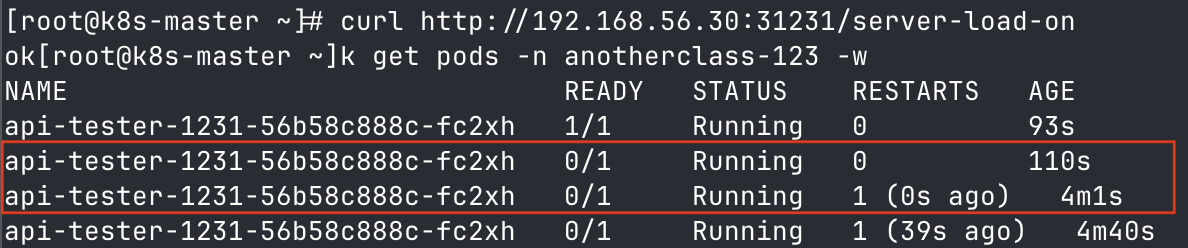
- liveness probe 실패로 인해, 재시작되는 파드를 확인할 수 있다.
[미션] Secret 파일이 존재하지 않는 경우
Quiz) Secret 파일(/usr/src/myapp/datasource/postgresql-info.yaml)이 존재하는지 체크하는 readinessProbe를 만들어 보세요.
▶ 기존 파드에 /usr/src/myapp/datasource/postgresql-info.yaml 파일은 존재하기 때문에 readiness probe가 정상적으로 수행되는 것을 확인할 수 있다.
# pod 내 특정 파일 출력
kubectl exec -n anotherclass-123 -it {파드명} -- cat /usr/src/myapp/datasource/postgresql-info.yaml
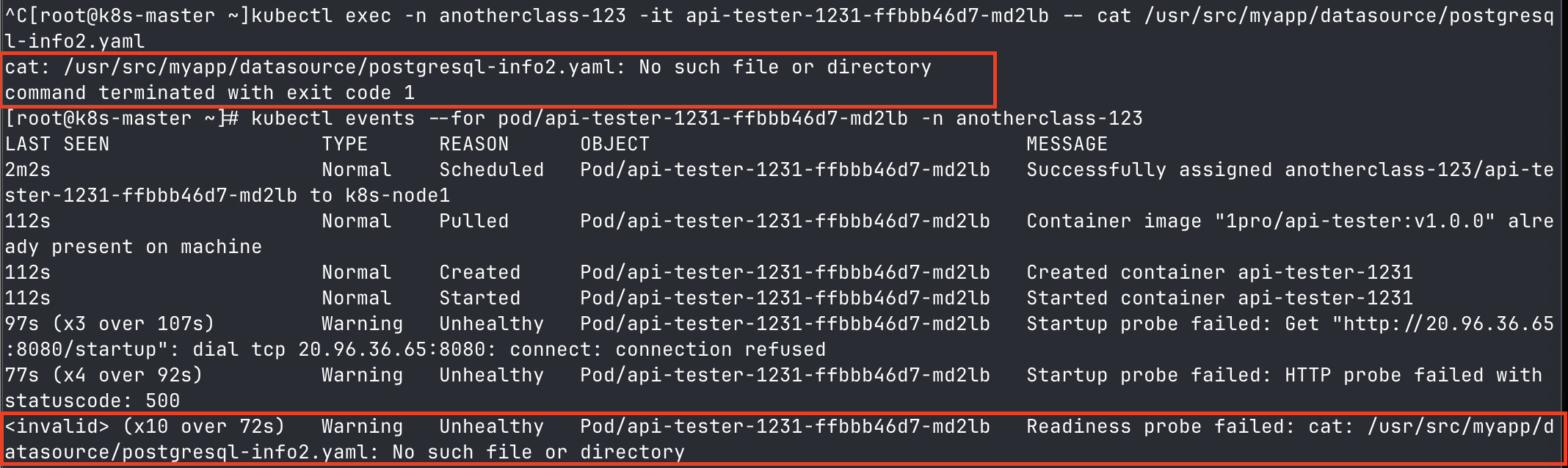
▶ 따라서 존재하지 않는 /usr/src/myapp/datasource/postgresql-info2.yaml 파일로 readiness probe command를 변경하면 아래와 같이 실패하는 것을 확인할 수 있다.
# pod 내 존재하지 않는 파일 출력
kubectl exec -n anotherclass-123 -it {파드명} -- cat /usr/src/myapp/datasource/postgresql-info2.yaml
# pod에 발생한 event 내용 확인
[root@k8s-master ~] kubectl events --for pod/{파드명} -n anotherclass-123▶ 결과