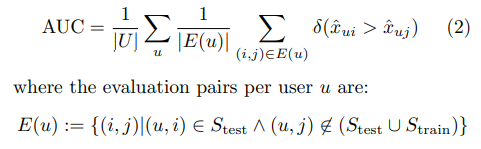과거의 정보를 통해 맞춤 아이템을 제공하는것이 중요해졌다. 이러한 과정에서 implicit feedback을 잘 활용하는것이 중요하다는 내용이다. 아래는 본 논문의 Contribution이다.
BPR-OPT라는 새로운 Optimization을 제시한다. 이것을 최대화 하는 과정은 ROC 커브의 AUC와 비슷함을 보인다.
BPR-OPT를 빠르게 계산하기 위한 LEARN BPR이라는 Algorithm을 제시한다.
BPR-OPT를 LEARN BPR을 이용해서 MF, KNN에 적용하는 방법을 소개한다.
실험적으로 더 좋은 성능을 냈음을 확인한다.
2. Related Work
추천을 위한 과거의 다양한 연구들을 소개한다. 그런데 과거 연구들은 죄다 "어떤 모델이 좋은지" 에만 집중을 해놨다. 이러한 논문들에서는 대부분 아이템에 대해서 점수를 매기고, 이후에 이를 정렬해서 상위 몇가지를 추천한다. 근데 우리의 근본적 목표는 점수를 매기는게 아니라, 더 좋은 아이템을 추천 하는것이다.
그래서 이번 논문에서는 "어떻게 최적화 할 지" 에 대한 연구를 진행했고, 결과가 좋았다. 핵심만 이야기 하면 점수를 비교하여 최적화 하는것이 아니라, 단순히 등수를 비교하여 최적화를 진행한다. 기존에 있는 모델들에 이 방법을 사용하면 성능이 향상된다.
3. Personalized Ranking
Personalized ranking을 한다는것은 각각의 user에 대해서 그들이 좋아할만한 item들을 줄세워서 상위 몇개를 추천 해주는 것이다. 여기서 주의 할 사항은 대부분의 정보는 implicit 하기 때문에 explicit data를 분석할 때와는 다른 접근이 필요하다. 핵심적으로는 negative feedback이 없는것인데, 간단한 예를 들어보자.
내가 쿠팡에서 초콜렛을 사 먹은 기록이 없다는 것은, 내가 초콜렛을 싫어할수도 있는거고, 그냥 단순히 살 생각을 안해서 안 샀을수도 있는 것이다. explicit data였다면 내가 초콜렛을 사서 별점을 1점을 줬으면 싫어하는 것이고, 아직 산 적이 없으면 그냥 단순히 산 적이 없는 것이다. 이렇게 호 불호에 대한 표시가 명확한 explicit data와는 달리, implicit data는 분석이 더 어렵고, 복잡하다. 하지만 당연히 더 중요하다. 자세히 알고싶으면 이전 포스팅 을 참고하자.
3.1 Formalization
이제 우리의 언어를 수학적으로 표현해보자.
U : 모든 user들의 집합 I : 모든 item들의 집합 S : 반응이 있는 implicit feedback 들, S⊆U×I
>u : 아이템들의 순위를 비교하는 연산자, >u⊂I2
u1가 i1을 i2보다 좋아한다면 i1>u1i2로 표현한다. 이 연산자는 아래 3가지 특성을 만족한다.
totality 는 서로 다른 어떠한 아이템 i,j에 대해서 i>uj든, j>ui든 둘중 하나의 방식으로 >u가 정의될 수 있음을 의미한다.
antisymmetry 는 순서가 있음을 의미한다. i>uj에서 i,j의 순서가 바뀌면 의미가 달라진다.
transitivity 는 i를 j 보다 좋아하고 j를 k보다 좋아하면 i를 k보다 좋아한다는 뜻이다.
마지막으로 편의상 아래 두 집합을 정의한다.
Iu+ : user u가 평가한 아이템들의 집합 Ui+ : item i를 구매한 유저들의 집합
다시 써보면 아래와 같다.
Iu+:={i∈I:(u,i)∈S}Ui+:={u∈U:(u,i)∈S}
3.2 Analysis of the problem setting
implicit feedback dataset에서 0 (평가되지 않은 항목)을 처리하는건 굉장히 중요하다. 여러가지 방법이 있을 수 있다. 몇가지 예시를 들어보도록 하자.
0을 무시해버리기
가장 쉬운 방법은 그냥 0을 무시해버리고 학습하는 경우다. 이렇게 0을 배제하면 positive feedback만 남기 때문에 당연히 문제가 생기고, 그냥 말도 안되는 소리다.
0들도 모두 학습해보기
위에 설명한것처럼 0을 무시하면 안되니까 0을 모두 학습하면 될까? 또 문제가 생긴다. 우리가 예측하고자 하는것은 빈칸 0에 대해 유저가 몇점을 줄지 예측하고 싶은 것인데, 0을 이미 부정적인것으로 학습한 꼴이 된다. 추가적으로 과적합 문제도 발생할 수 있다.
위의 두가지 방법을 보면 0을 무시해서도 안되고, 무작정 학습해서도 안됨을 알 수 있다. 이에 본 논문에서는 새로운 방법을 제시한다.
단순히 차이만 학습하기
이미 구매 한 아이템은 구매하지 않은 아이템보다 선호도가 높다.
구매 한 아이템 끼리의 선호는 구분할 수 없다.
구매하지 않은 아이템 끼리의 선호는 구분할 수 없다.
이제 우리는 이 차이만을 가지고 학습을 진행할 것이기 때문에, 이를 통해 새로 데이터 셋을 만든다. 이렇게 만든 데이터 셋을 DS 라고 한다.
(u,i,j)∈DS로 나타낼 수 있는데, 설명하자면 user u가 item i를 item j보다 더 좋아한다는 뜻이다.
이렇게 하면 두가지 장점이 있다.
0끼리의 비교를 하지 않으니, 예측하고자 하는 값들이 DS에 포함되지 않는다.
우리가 하고자 하는 목표(점수를 매기는것이 아닌, 더 좋아할만한 아이템을 추천하는것)랑 즉시 일치해버린다.
4. Bayesian Personalized Ranking (BPR)
앞으로 우리가 할 것을 정리해보면 아래와 같다.
새로운 방식인 BPR-OPT를 이용해 최적화 하는 방법 설명
p(i>uj∣Θ),p(Θ) 를 알아야한다.
이 과정이 ROC의 AUC와 유사함을 보인다. (흐름상 중요하지 않다고 판단해 포스팅에선 생략한다.)
더 효과적인 수렴을 위한 LEARN BPR 알고리즘을 제안
이 방법을 MF, kNN에 적용
하나씩 차근차근 확인해보자.
4.1 BPR Optimization Criterion
추천 시스템의 대표 주자인 MF와 kNN 방식이 각 유저 u에 대해서 item i의 랭킹을 매기는 상황에서 필요한 것은 각각 아래와 같다.
MF : Latent factor 찾기
kNN : similarity matrix 찾기
즉 MF의 경우는 Latent factor가, kNN에 대해서는 similarity matrix가 parameter Θ가 된다.
아무튼 모델들에 따라서 다른데, 주어진 >u 에 대해서 p(Θ∣>u) 를 최대화 하면 된다. 여기서 Bayesian 을 이용한다.
MF의 경우를 예시로 들어 조금 풀어서 설명을 해보자. 3.1 Formalization을 보면 새로운 연산자 >u가 정의되었고, 이를 통해 학습을 할 계획이다. MF에서 학습의 대상은 각각의 user와 item들에 대한 Latent factor들 이다. 즉 우리는 주어진 >u를 가장 잘 설명할 가능성이 높은 Θ 를 찾는것이 목표고, 이것을 수식으로 나타내보면 p(Θ∣>u) 이다.
정리한 결과를 보면 p(>u∣Θ)를 수치화 해야한다는 것을 알 수 있다. p는 결국 확률이고, 0~1 사이의 값을 갖는다. 이를 가장 잘 나타내는 것은 우리가 잘 아는 sigmoid 함수다. 따라서 해당 값을 아래처럼 정의한다.
p(>u∣Θ):=σ(x^uij(Θ))
이렇게 임의의 새로운 함수 x^uij(Θ)에 대해서 그냥 시그모이드로 나타내버렸다. >u 가 u,i,j의 관계에 대한 연산자이므로 의미상 문제는 없다. 이제 임의의 함수인 x^uij(Θ)를 알아내는것이 새로운 목표가 됐다. 참고로, 앞으로의 수식 전개에서 편의상 x^uij(Θ)를 x^uij로 Θ를 생략해서 사용한다.
위에서는 p(>u∣Θ) 를 x^uij로 바꾸어 나타내는 과정을 진행했다.
이제 나머지 하나인 p(Θ)를 수치화 해보도록 한다.
수식을 진행하기에 앞서 몇가지 가정을 한다. Θ는 우리가 구하고자 하는 parameter다. 이게 어떻게 분포되어 있는지 알 수 없으므로, 일반적으로 그냥 Normal distribution이나 Uniform distribution을 따른다고 가정한다고 한다. 이 논문에서는 아래와 같은 정규분포를 따른다고 가정했다. 계산의 용이성을 위해 variance-covariance matrix도 간소화 했다.
d,λΘ가 모두 상수이므로 새로운 상수 C1,C2로 나타낼 수 있다. 여기서 우리의 목적은 p(Θ∣>u)의 정확한 값을 구하는 것이 아닌, 최대화를 하는 것이다. 따라서 C1은 무시할 수 있다. 또한 λΘ 도 하나의 hyperparameter일 뿐이므로 lnp(Θ)를 아래처럼 나타낸다. 수식적으로는 명백히 오류지만, 흐름상으론 문제가 없다...
lnp(Θ)=−λΘ∥Θ∥2
과정이 조금 이상하긴 했지만 결과적으로 식을 정리하면 논문과 동일한 결과를 얻을 수 있다.
SGD를 하게 되면 보통 user나 item을 하나 고정시키고 고르게 되는데, 이러면 잘 안된다. 왜냐면 유저 u가 아이템 i를 샀다고 해보자. 그러면 당연히 사지 않은 아이템이 비교할 수 없을만큼 많기 때문에 (u,i,i′) pair가 너무 많이 나온다.
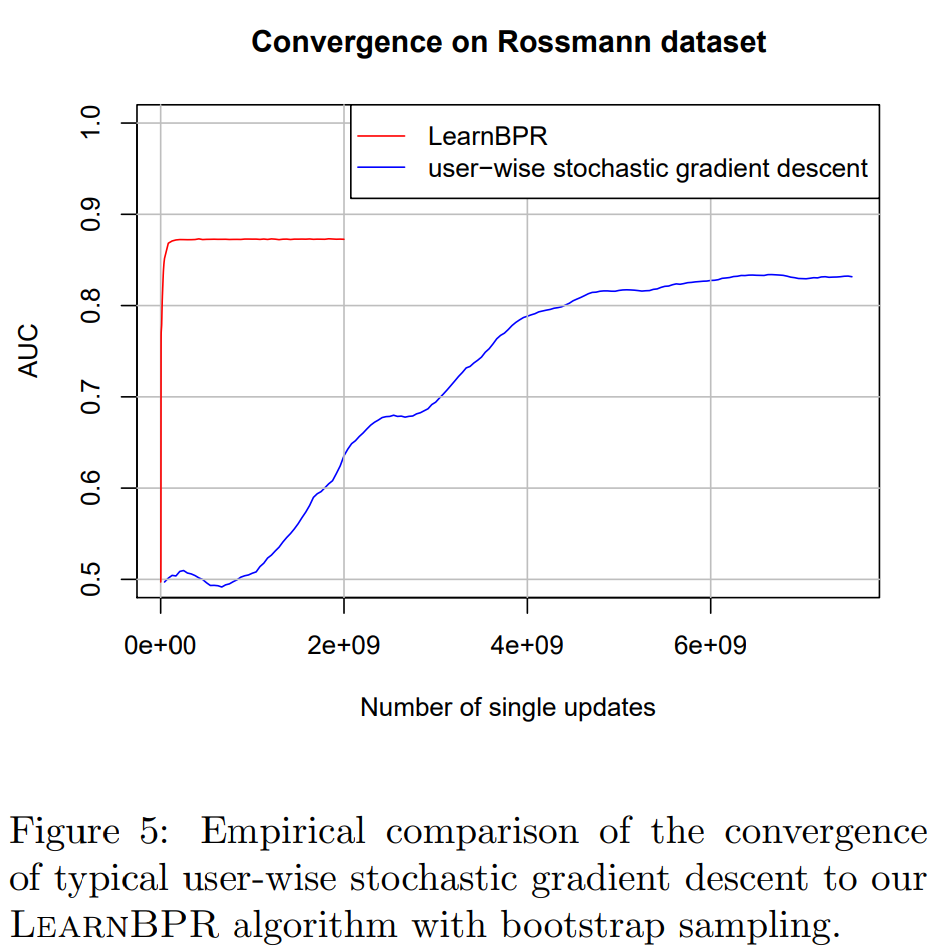
이를 해결하기 위한 방법이 LEARN BPR 이다. 특별한건 아니고 그냥 uniform distribution처럼 뽑는것이다. 원래는 데이터 셋에 u,i가 너무 많아 랜덤 추출을 할 때 많이 나오는것이 문제였는데, 개수에 따라서 뽑는게 아니라 동일 확률이라고 하고 뽑으면 된다. 또한 이 논문에서는 여기에 bootstrap sampling 방법도 적용했는데, 두가지 이유가 있다.
데이터가 충분히 많기 때문에 적은 양으로 수렴이 가능하다.
따라서 수렴 했으면 그냥 중간에 꺼버릴 수 있으면 좋다.
아래 Figure 5를 보면 실제로 굉장히 빨리 수렴함을 확인할 수 있다.
4.3 Learning models with BPR
이제 앞에서 나온 내용 BPR-OPT 을 LEARN BPR을 통해 어떻게 하는지 MF랑 kNN에 적용해보도록 한다.
먼저
x^uij:=x^ui−x^uj
로 재 정의한다. 왜냐면 대부분의 기존 model은 u,i,j 3개를 다 보는게 아니라 u,i 간 관계만 보기 때문이다.
다시한번 강조하지만, 이 논문은 점수를 매기는데 초점을 맞추던 원래 방안을
차이를 이용해서 rank를 매기는것으로 변경한다.
논문에서는 두가지 방법을 모두 다뤘지만, 포스팅은 MF에 대해서만 설명하도록 하겠다.
4.3.1 Matrix Factorization
MF의 경우를 보자.
MF는 기본적으로 X^=WHt 두 행렬의 곱으로 나타낸다. 그러면 Θ는 두 행렬 W,H다. 그러면 이것들에 대해서 미분 한 값을 구할 수 있으면 된다.
식을 좀 정리해보면 아래와 같다.
X^ : 예측하고자 하는 값들 U×I W : user들의 latent factors, ∣U∣×k H : item들의 latent factors, ∣I∣×k
wuf,hif 는 W,H 에서의 행벡터다.
따라서 하나의 value x^ui는 아래와 같다.
x^ui=⟨wu,hi⟩=f=1∑kwuf⋅hif
4.2 BPR Learning Algorithm를 보면 결국 우리가 해야 할 것은 ∂Θ∂x^uij 를 계산하는 것임을 알 수 있다. 4.3 Learning models with BPR에서 x^uij:=x^ui−x^uj 라고 재정의 했음을 떠올리면 쉽게 계산할 수 있다. 결과는 아래와 같다.
이제 ∂Θ∂BPR−OPT 계산에 필요한 모든 수치를 구할 수 있다. 그냥 값 구해서 넣으면 그만이다.
5. Relations to other methods
MF 기본형 말고 좀 바뀐 다른 방법들에 대해서 간략히 소개한다. 별로 흐름에 중요하진 않고 BPR-OPT가 좋다는걸 보여주기 위한 엑스트라 느낌이다. WR-MF(Weighted Regularized Matrix Factorization)와 MMMF(Maximum Margin Matrix Factorization)이 소개되었지만, 그냥 넘어간다.
6. Evaluation
MF, kNN, WR-MF, MMMF 등등 평가, 비교해볼 예정이다. Rossmann이랑 Netflix에서 데이터를 가져왔다.
6.2 Evaluation Methodology
평가를 하는 기준이다. 흐름상 넘어간 AUC를 곧 정확도라고 판단한다.
6.3 Results and Discussion
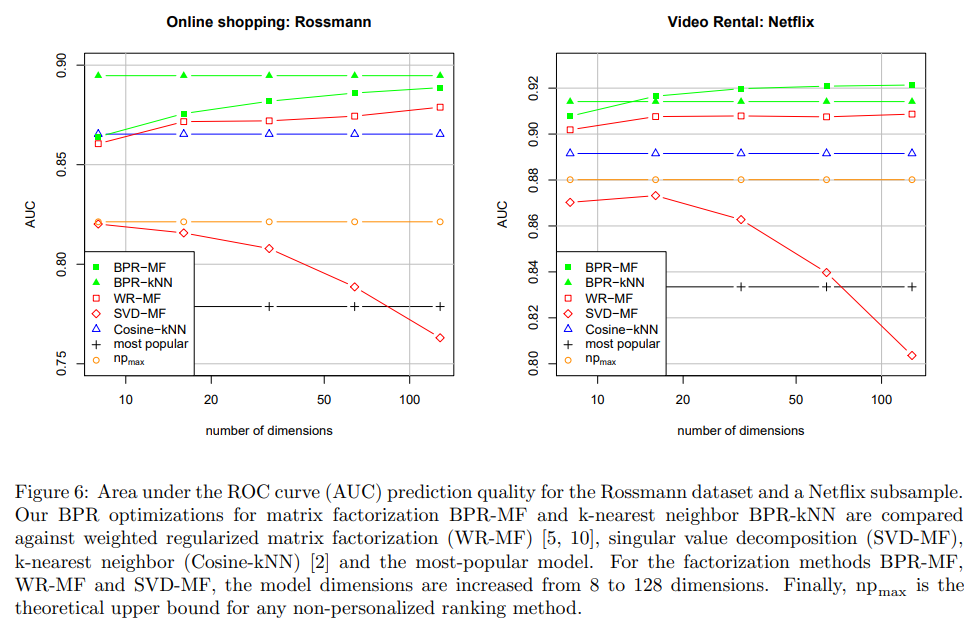
각각의 방법들과 비교해본 표는 아래 Figure 6과 같다.
그냥 내가 짱이다. 어떠한 경우에도 BPR을 사용한 경우가 좋다.
추가적으로 Test-set을 학습한 non-personalized data (그래프에서 npmax)은 BPR-OPT를 사용하지 않은 다른 개인화 추천 방법들보다도 안좋았다.