No Time to Waste: Squeeze Time into Channel for Mobile Video Understanding
이 글은 논문 "No Time to Waste: Squeeze Time into Channel for Mobile Video Understanding"에 대한 리뷰글입니다.
Abstract
- 최근 video understanding methods는 3D blocks나 2D convolutions with additional time modeling을 사용함
- 하지만 이 방법들은 모두 temporal axis(시간축)을 separate dimension으로 계산하기 때문에 large computation and memory budgets가 요구되어 mobile devices에서 사용하는데 한계가 있음
-> 본 논문에서는 time axis를 channel dimension으로 squeeze하는 SqueezeTime에 대해 제안함
- Kinetics400, Kinetics600, HMDB51, AVA2.1 and THUMOS14에서 SoTA
- Codes are publicly available at https://github.com/xinghaochen/SqueezeTime and https://github.com/mindspore-lab/models/tree/master/research/huawei-noah/SqueezeTime.
Introduction
기존 연구 방법들
-
Traditional 3D convolutional networks: 3D ConvNets, I3D and SlowFast
- can jointly learn spatial and temporal features from videos but consume large amounts of memory and computation
- not suitable for mobile usage
-
Improvement of the 3D convolutional network by 2D decomposition or approximation manually
- However, searching for such 3D architectures on a video benchmark is also time-consuming -
Incorporating 2D CNN with temporal learning: Temporal Shift Module, Temporal Difference Moudle, Temporal Adaptive Module, Adaptive Focus, Temporal Patch Shift, Temporally-Adaptive Convolutions
- Though these methods have improved running speed, the accuracies are not quite satisfactory in mobile settings.
-
Transformer-based Video analysis
- not friendly to mobile devices.
SqueezeTime
- 위의 모든 방법들이 temporal axis를 extra dimension으로 사용하기 때문에 computational cost가 큼
- 본 논문에서는 이렇게 temporal axis를 따로 둘 필요가 없다는 것을 발견
- 따라서 temporal axis를 spatial channel dimension으로 squeeze하는 SqueezeTime을 제안
- 이러한 Squeeze연산으로 생기는 부작용을 보완하기 위한 방법을 제안
- Channel-Time Learning Block (CTL): learn the temporal dynamics embedded into the channels
- First branch: Temporal Focus Convolution (TFC) - concentrates on learning the potential temporal importance of different channels
- Second branch: leveraged to restore the temporal information of multiple channels and to model the Inter-temporal Object Interaction (IOI) using large kernels.
- Channel-Time Learning Block (CTL): learn the temporal dynamics embedded into the channels
- Contributions
- SqueezeTime 제안: squeeze the temporal dimension of the video sequence into spatial channels, which is much faster with low memory-consuming and low computation cost.
- The CTL can learn the potential temporal importance of channels, restore temporal information, and enhance inter-temporal object modeling ability, which brings 4.4% Top1 accuracy gain on K400.
- Extensive experiments demonstrate the proposed SqueezeTime can yield higher accuracy (+1.2% Top1 on K400) with faster CPU and GPU (+80% throughput on K400) speed.
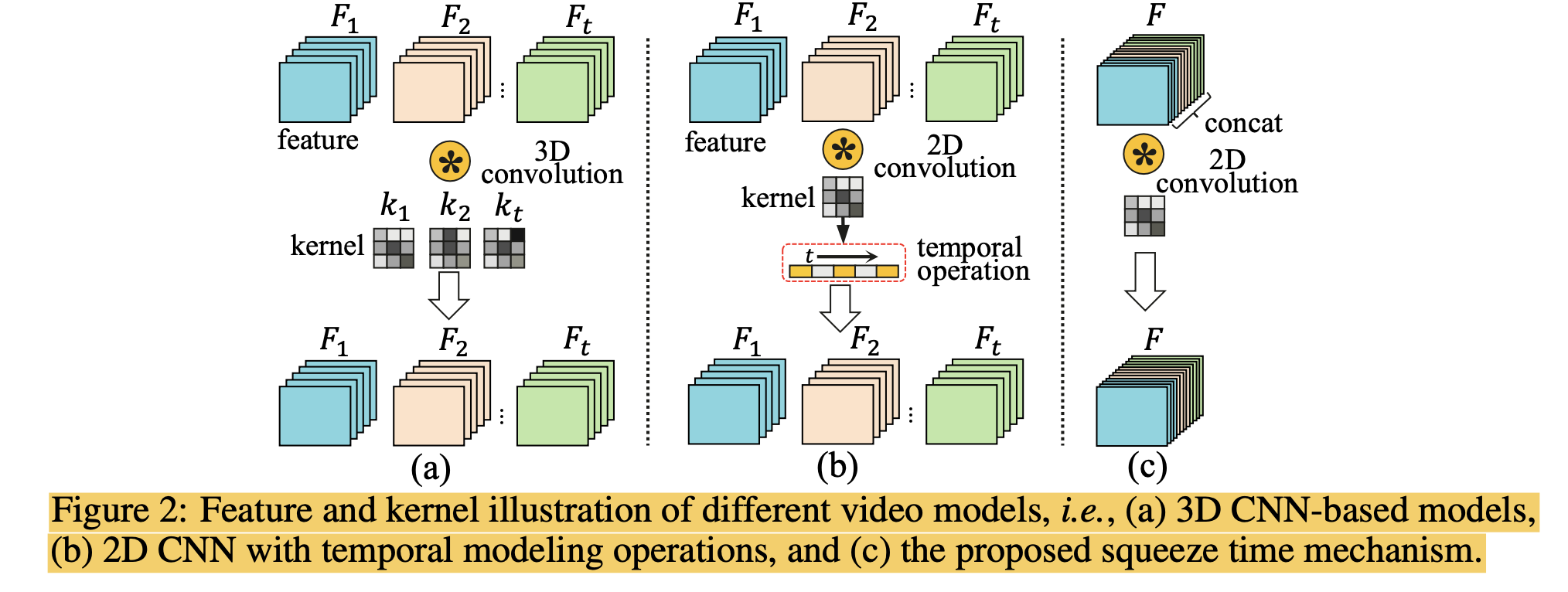
SqueezeTime Network (SqueezeNet)
Squeeze and Restore Time
Comparing Cost Time
- 3D CNN: 2c_out x c_ink x 3 x h x w x t
- 2D CNN with temporal modeling: 2c_out x c_ink x 2 x h x w x t + O(t)
- SqueezeNet: 2c_out x c_ink x 2 x h x w
squeeze mechanism
Formula 1
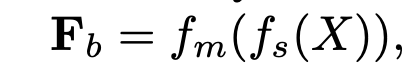
- fs is the squeeze function, fm is the mix up function, and Fb is the squeezed feature without temporal dimension.
Formula 2
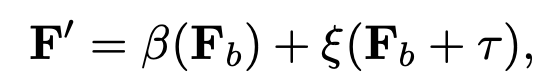
- β is the temporal importance learning function, ξ is the inter-temporal interaction function,
and τ is the injected temporal order information. F′ is the restored feature.
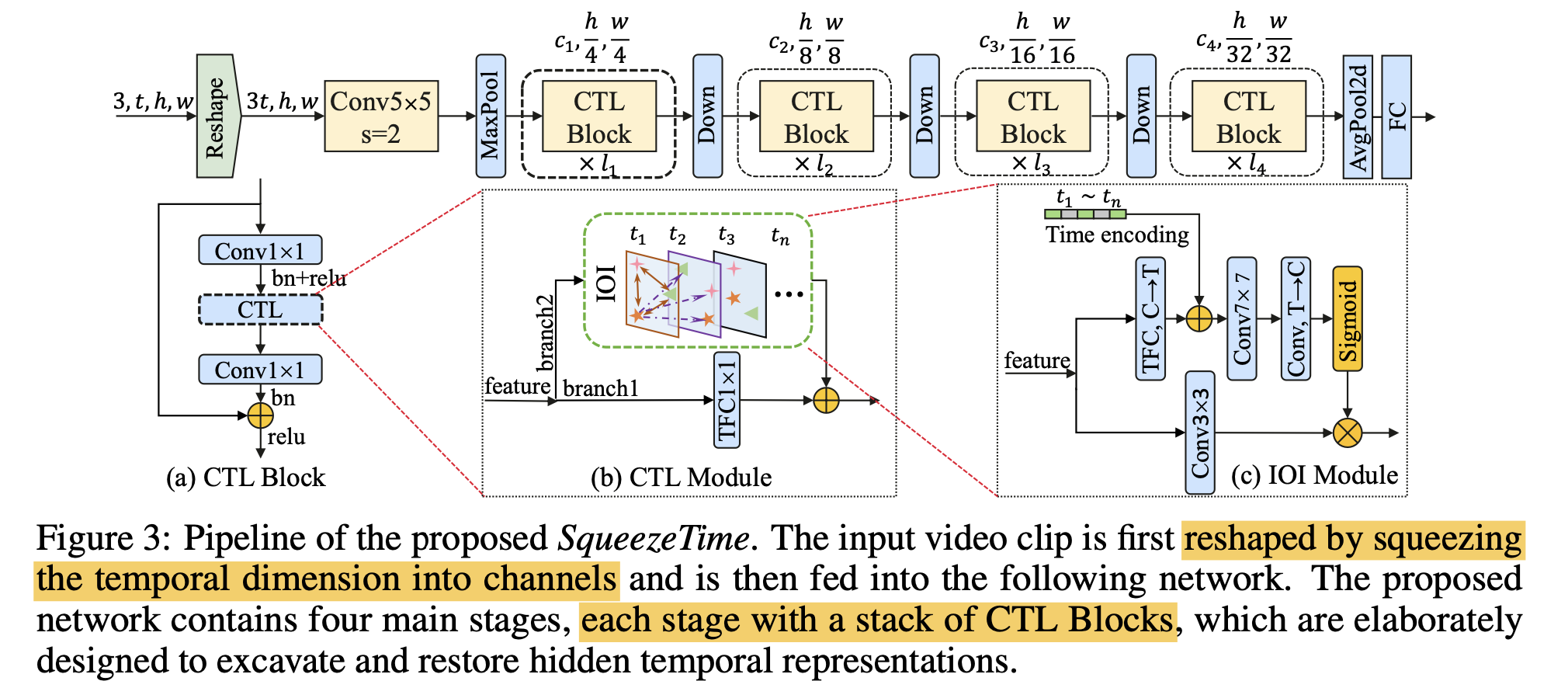
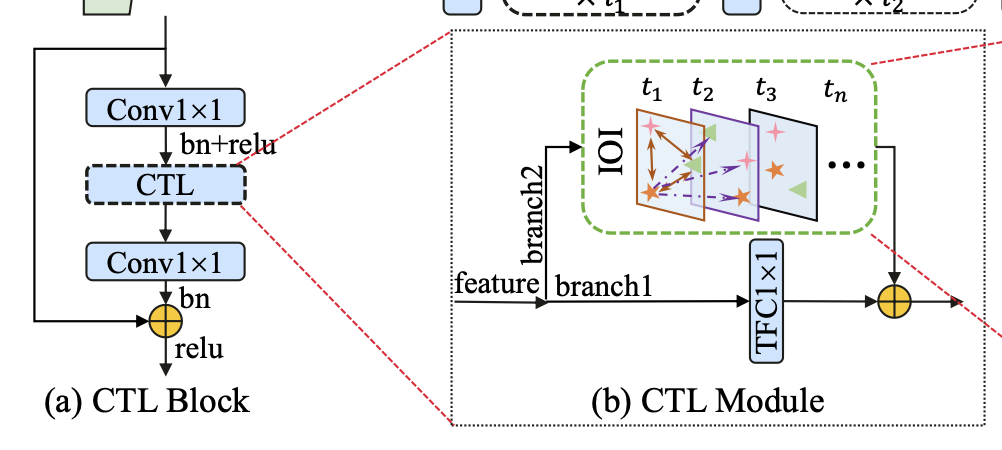
Channel-Time Learning (CTL) Block
- CTL block은 SqueezeNet의 기본 요소이자 Formula 2를 이해하기 위한 기본 단계
- CTL block 구성 요소 (Figure3-(a))
- 1 × 1 convolution : to reduce the channels
- CTL module: to learn temporal and spatial representations
- another 1 × 1 convolution: to restore the channel number
CTL module (Figure3-(b))
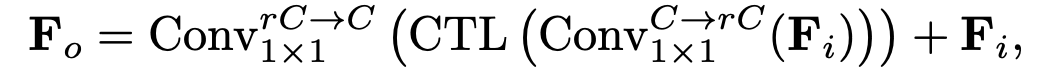
- Fi and Fo are the input feature and output feature of the CTL block, and r is the ratio controlling the channel expansion.
- set the reduction factor r to 0.25 as the default.
Figure3-(b)
- Branch1: Temporal Focus Convolution (TFC)
- TFC with 1 × 1 kernel size: to especially concentrate on capturing the temporal-channel importance.
- Branch2: Inter-temporal Object Interaction (IOI) module
- restore the temporal position information and model the inter-channel spatial relations using large kernels.
- Final ouput: summation of the two branches
Temporal Focus Convolution (TFC)
temporal dimension을 channel로 squeeze할 때 중요한 질문: 과연 Original 2D convolution 연산이 서로 다른 channel에 있는 temporal representation을 모델링하기 적합한가?
- Original 2D Convolution
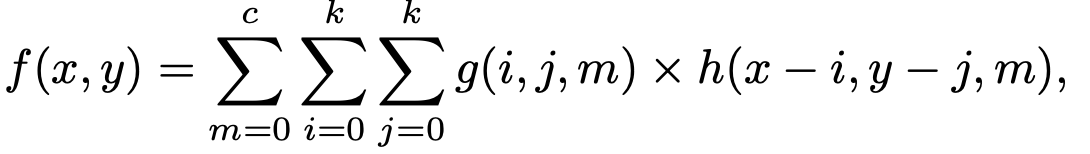
-> 이런 기존의 2D Convolution연산은 서로 다른 channel간의 중요도가 동일하게 연산됨
-
하지만 저자들은 temporal information을 channel로 squeeze하면, 각 channel간의 temporal importance를 구분해야한다고 주장하며, improved Temporal Focus 2D Convolution (TFC)를 제안
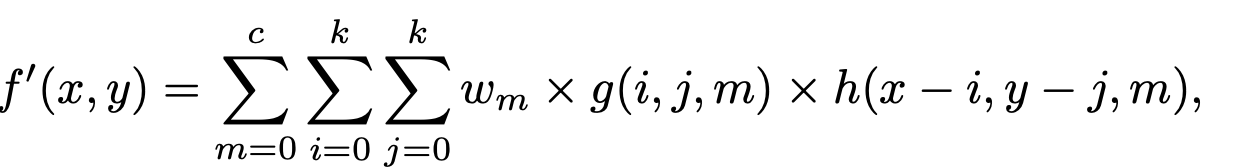
-
wm: the temporal-adaptive weights calculated according to the input features, it models the temporal importance of different channels.
-
wm: can be computed using a lightweight module, i.e., weight computation module.
-
In this paper, authors simply use the modules as a global MaxPool2d followed by a two-layer MLP as the WCM.
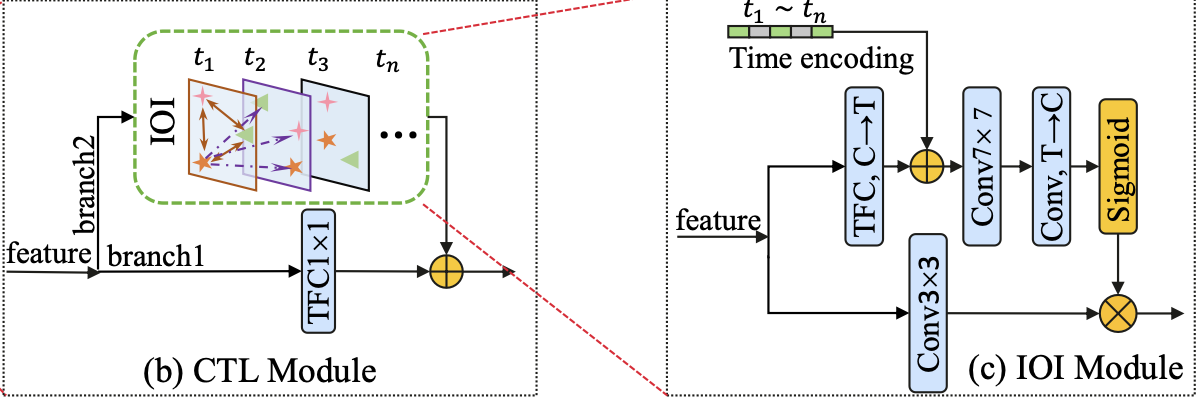
Inter-temporal Object Interaction (IOI) module
- IOI Module이 필요한 이유
- temporal information of a video clip이 channel로 squeeze될 때와 temporal order information of channels이 mixed up될 때 중요한 정보 손실이 일어날 수 있음
-> 이런 temporal details 정보 손실을 복구할 수 있어야함 - 서로 다른 multiple objects간의 관계를 모델링할 수 있어야함
- temporal information of a video clip이 channel로 squeeze될 때와 temporal order information of channels이 mixed up될 때 중요한 정보 손실이 일어날 수 있음

Figure3-(c)
- Top branch
- 3 × 3 TFC: to reduce the number of channels (C) to the number of frames (T) and to capture the temporal importance
- temporal position encoding information: to restore the temporal dynamics
- 7 × 7 convolution: to model the object relations between T frames
-> 다른 모듈로 변경 가능: to capture the cross-temporal object interactions
- Bottom branch:
- 3 × 3 convolution: to get the output number of channels
- direct mapping from input channels to output channels.
Experiments
Conclusion
In this paper, we concentrate on building a lightweight and fast model for mobile video analysis.
- Different from current popular video models that regard time as an extra dimension, we propose to squeeze the temporal axis of a video sequence into the spatial channel dimension, which saves a great amount of memory and computation consumption.
- To remedy the performance drop caused by the squeeze operation, we elaborately design an efficient backbone SqueezeTime with a stack of efficient Channel-Time Learning Block (CTL), which consists of two complementary branches to restore and excavate temporal dynamics.
- Besides, we make comprehensive experiments to compare a quantity of state-of-the-art methods in mobile settings, which shows the superiority of the proposed SqueezeTime, and we hope it can foster further research on mobile video analysis.
