[논문]Dynamic Routing Between Capsules

-
Object Recognition
기존의 object recognition에는 Convolution Network를 사용하였다.
Feature Extracting + max pooling -
Object Segmentation
기존 CNN의 Maxpooling과정의 문제점으로 인해 새로운 기법인 Dynamic Routing 기법 제시
들어가기 전에
Convolution Network의 단점
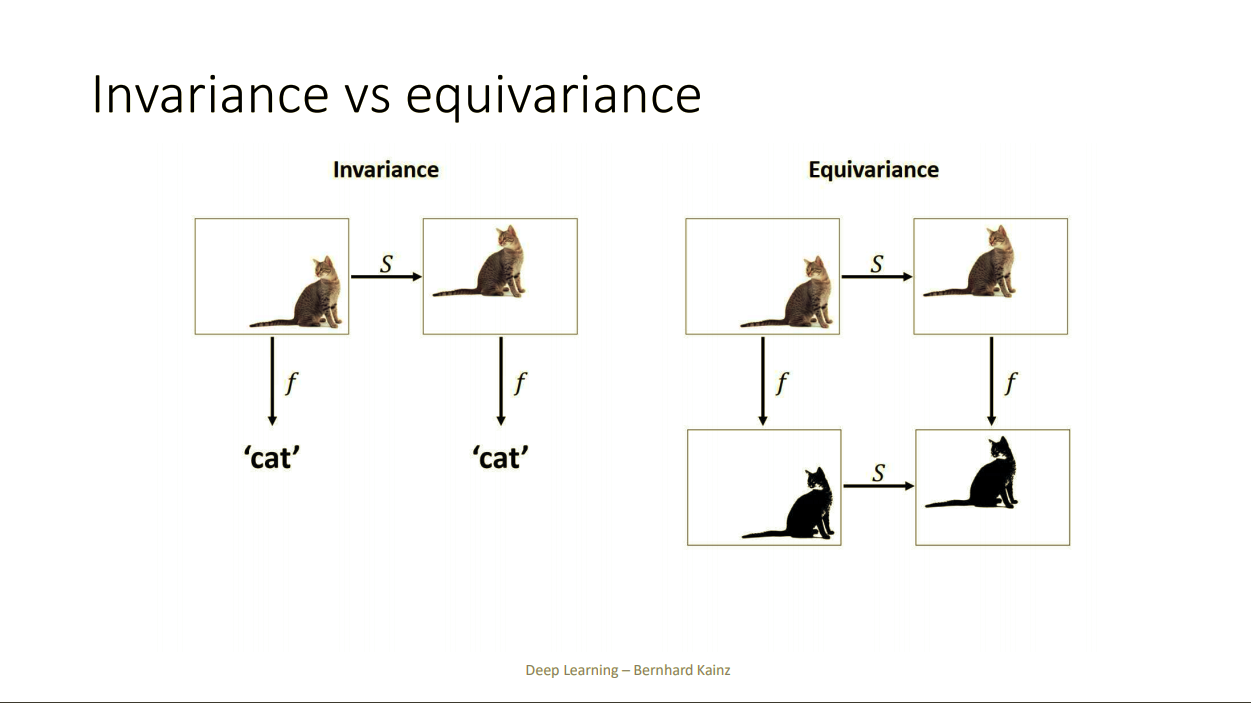
-
Invariance: input X에 변형을 가해도 같은 output을 출력해주는 함수
-
Equvariance: input X를 입력으로해서 나온 ouput에 변형을 가하고, 그 변형과 똑같은 변형을 input X에 가해서 나온 결과가 같도록 하는 함수
CNN = translation invariance(같은 label이면 위치나 구성의 변형 상관없이 똑같이 잘 분류하기 때문)
-> Maxpooling 때문
CNN 한계
subsampling이 "local" invariance를 보장하지만, local 범위를 벗어나면 spatial relationship을 파악 못한다.
즉, Convolution network는 translation invariance를 얻기 위해 정보들을 버려서 spatial relationship을 고려하지 않는다는 단점이 있다
Contributions
- MNIST dataset에서 sota를 달성
- CNN에선 고려하지 못했던 Feature 간에 Spatial relationship고려
- CNN에선 해결하지 못했던 Highly overlapping object recognition에 강하다
Abstract
Capsules?
1. What is entity? : instantiation parameter
2. is there entity? : lengh of vector
Instantiation parameter?
모형이나 물체 실재(entity)를 vector로 표현하는데 parameter개수와 어떤 의미인지 정확하게 알 순 없지만 entity를 설명, 표현하기위한 vector
논문의 제목이 Routing Between Capsule이기 때문에 결국 capsules 끼리의 connected layer로 문제를 푸는 구조
Capsule을 사용시 layer가 깊어지면?
- layer간 차원이 다른 capsule의 forward propagation이 어려움
- capsule의 길이가 확률을 의미하므로 [0,1] 사이의 값을 가져야하는데 layer 가 깊어질수록 연산을 거치면서 그 이상의 값을 가질 수 있음.
->이 두 문제를 해결하려고 나온게 바로 Dynamic Routing
How the vector inputs and outputs of a capsule are computed
(capsule) vector의 이전 layer와 다음 layer의 차원이 다름
Affine Transform
1. 이전 layer의 차원을 다음 layer의 차원으로 높여주기
2. 결국 차원을 높인다는 것은 현재의 capsule이 다음 layer에서 어떤 모양일지를 예측하는 것이고, 예측을 잘하도록 Affine Transform을 학습시키는 것.
Squash
capsule은 vector이므로 activation function으로 ReLu나 Sigmoid를 사용할 수 없음.
-> "squash"는 capsule의 activation function
-> capsule vector의 길이를 [0,1]로 mapping 해주는 역할
