RLHF
이 글은 RHLF를 공부하기 위한 정리 노트입니다.
Reference link: https://ebbnflow.tistory.com/382
Referecne paper: Direct Preference Optimization:
Your Language Model is Secretly a Reward Model
Direct Preference Optimization, DPO
Neurips 2023, Direct Preference Optimization: Your Language Model is Secretly a Reward Model
-
이전 RLHF 방법론에서 Reward model을 학습시키는 과정을 없애므로써 RLHF을 cross entropy training으로 바꾼 논문
-
우리는 LM을 학습시키면서 LM이 데이터셋의 퀄리티까지 구별해, 좋은 퀄리티의 데이터셋 쪽으로 학습하길 원한다
-
하지만 LM은 dataset maximum likelihood로 학습되므로, preferred response, behavior를 선택하여 모델에게 입력해주어야 똑똑한 LM이 학습될 수 있음.
-
따라서 가지고있는 데이터셋 이상의 좋은 LM을 만들기 위해서는 RL-based approach를 사용해야함
-
하지만 기존 RL 방법들은 preference dataset으로 Reward Model을 fitting애햐 했기때문에 학습 파이프라인이 복잡
-
DPO는 RL objective를 간단한 binary cross entropy objective로 풀어 preference learning을 단순화시킴.
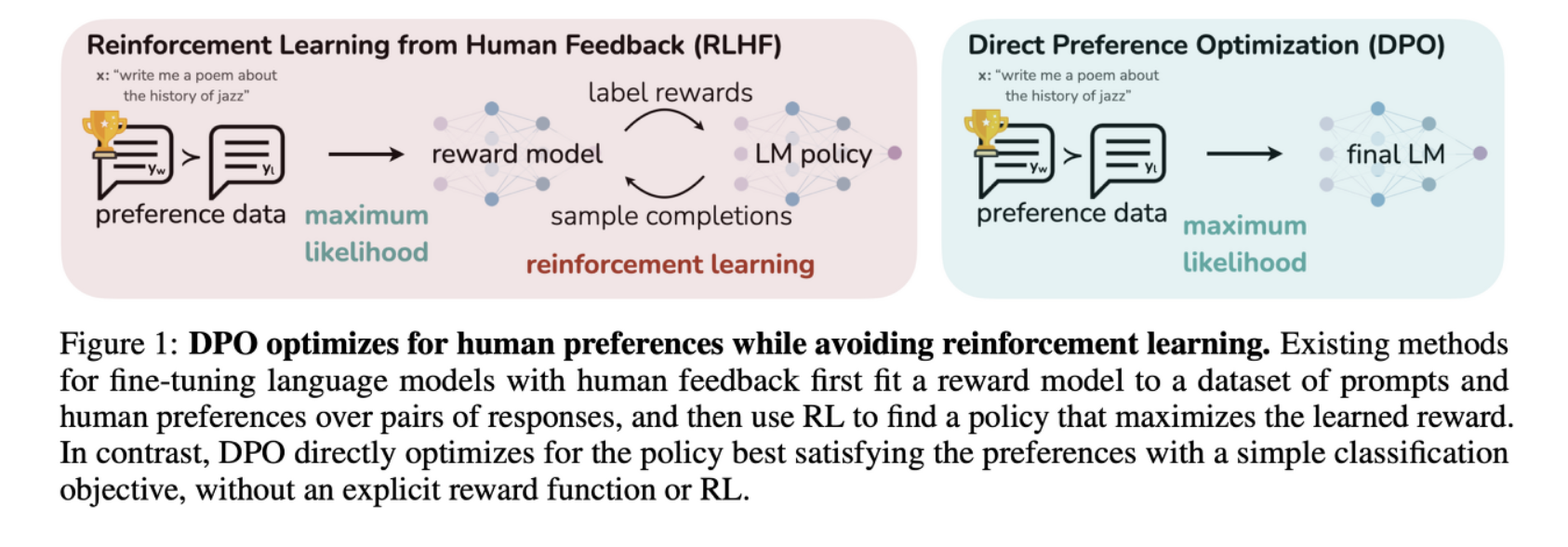
- 이전 RLHF가 pre-trained LM (supervised fine tuning까지 거친)이 response를 생성하고, 사람이 preference로 순위를 매긴뒤 다시 이 preference loss로 Reward Model을 학습한 뒤, RL-tunning 진행
RLHF (Reinforcement Learning with Human Feedback)
출처: https://eair.tistory.com/66
- LLMs는 인간의 피드백을 통한 강화학습으로 이루어짐
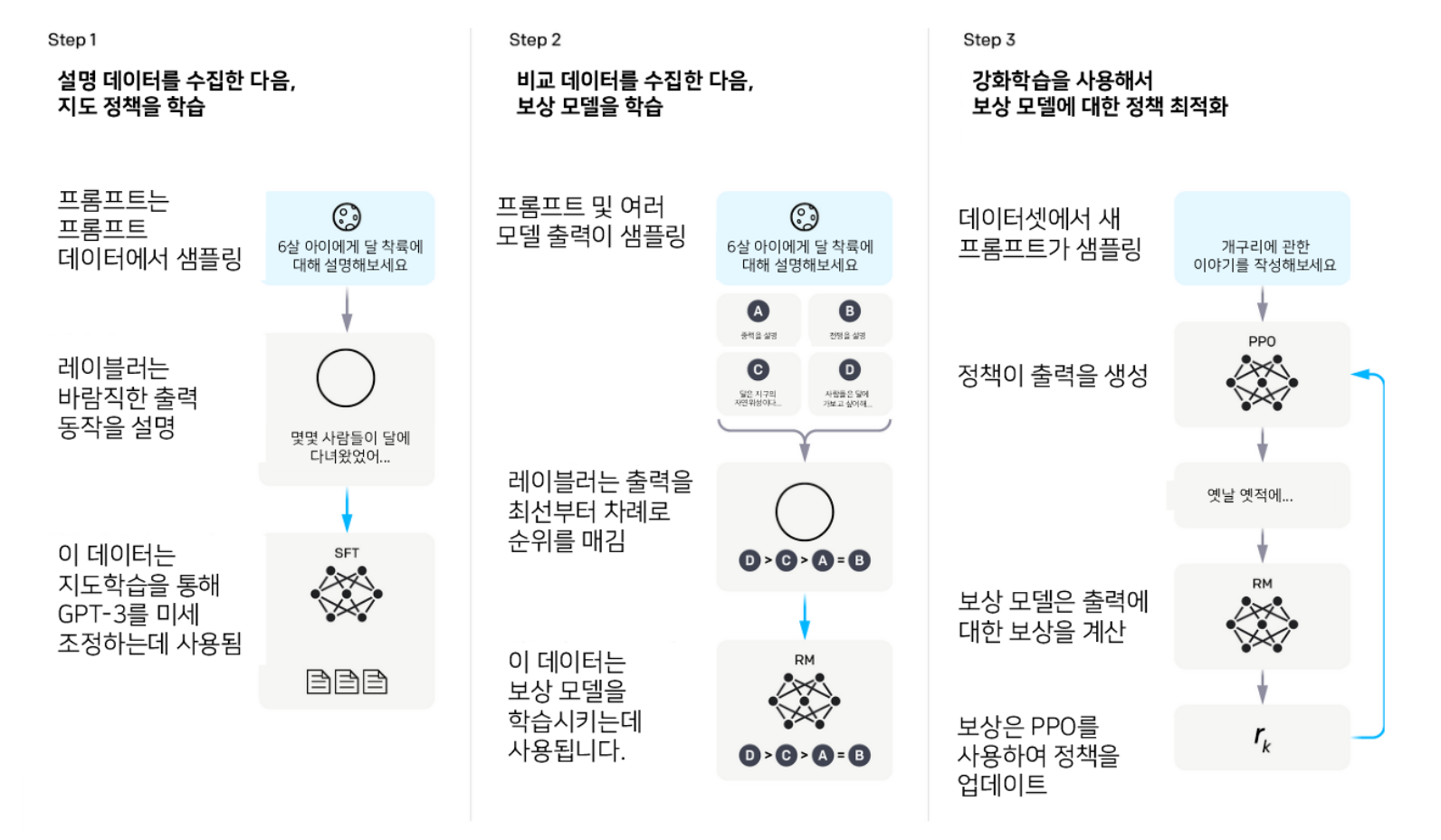
- RLHF는 사람의 피드백, 특히 피드백간의 비료를 통해 보상 함수를 학습한 다음에 RL을 적용하여 학습된 보상 함수를 최적화하여 문제를 해결함
- Supervised Fine-Tuning Stage: 사전 학습된 모델은 고품질 데이터셋에서 확률에 의해 가능한 답변을 생성하여 사람의 쿼리에 응답하는 방법을 학습
- pre-trained LM이 있으면, 특정 task에 대한 데이터셋으로 supervised fine-tuning하는 단계에서 SFT를 얻을 수 있음
- Reward modeling Stage: SFT 모델에서 x라는 프롬프트와 한쌍의 답변 y1과 y2를 생성. 이렇게 생성된 응답들은 다른 답변보다 어느 한 답변에 대한 선호도가 인간의 의해 표시되며, 이를 통해 비교 손실을 사용하여 보상모델을 학습 시킴
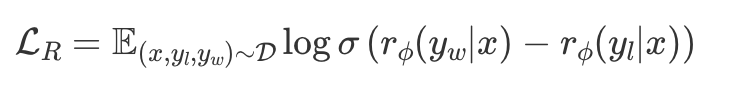
- 1단계에서 얻은 SFT 모델에 prompt x를 넣고 y 2개를 생성하여 human labeler가 더 선호는 하는 쪽은 y_w, 덜 선호하는 쪽은 y_l이라고 라벨링한다.
- human preference probability를 위해 각 pair에 대한 선호가 있을 때 전체 선호도를 모델링할 수 있는 Bradley-Terry 모델을 주로 사용함
- 그리고 y_w, y_l이 있을 때, negative log-likelihood로 reward model을 학습시킴
- RL Fine-Tuning Stage: SFT 모델은 본 단계의 초기화 역할을 하며, RL 알고리즘은 초기 정책과의 편차를 제한하면서 보상을 극대화하는 방향으로 정책을 최적화함
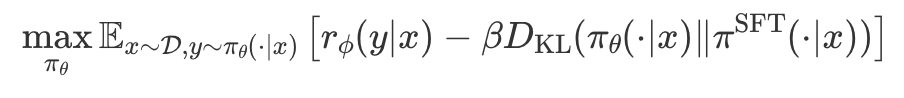
DPO
해당 논문에서는 RL policy를 optimize하기 위해 사용되었던
KL-conatrained RL objective을 아래와 같은 objective로 바꿔줌
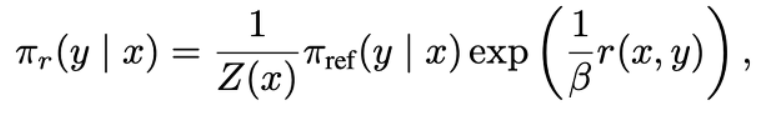
유도 과정은 생략.
이렇게 유도된 DPO objective에 gradient에 대한 분석을 하면,

- L_DPO에 theta에 대한 gradient를 취하면, 선호하는 라벨에 대한 log likeihood는 높이고, 선호하지 않은 likelihood는 낮추는 동시에 리워드가 잘못 추정되면 큰 penalty를 줄 수 있다.
Conclusion
- GPT와 같은 대규모 모델을 개인이 학습하기 어려움. Reward model을 학습할 수 있다하더라도 대량의 데이터를 확보하기도 어려움
- Reward model을 fitting하는 것도 어렵고, reward model 학습 후 RL 학습도 복잡하기 때문에 많은 어려움이 있음
- DPO는 이런 문제들을 해결할 수 있음
