[논문 리뷰] What Makes Training Multi-modal Classification Networks Hard?
이 글은 2020년 CVPR에 게재된 "What Makes Training Multi-Modal Classification Networks Hard?" 논문에 대한 리뷰입니다.
Background
Why Multimodal??
-
Uni-Modal Model (Vision-Only)
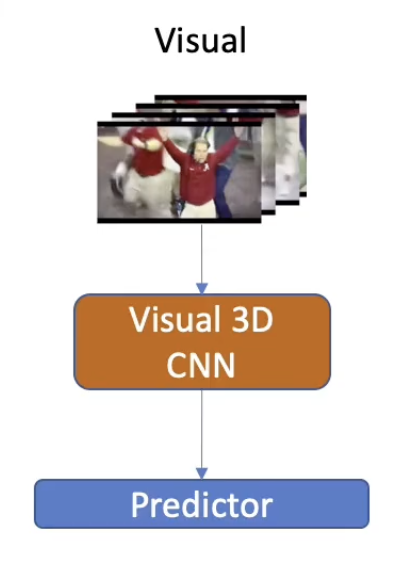
-
Bi-Modal Model (Audio-Vision)
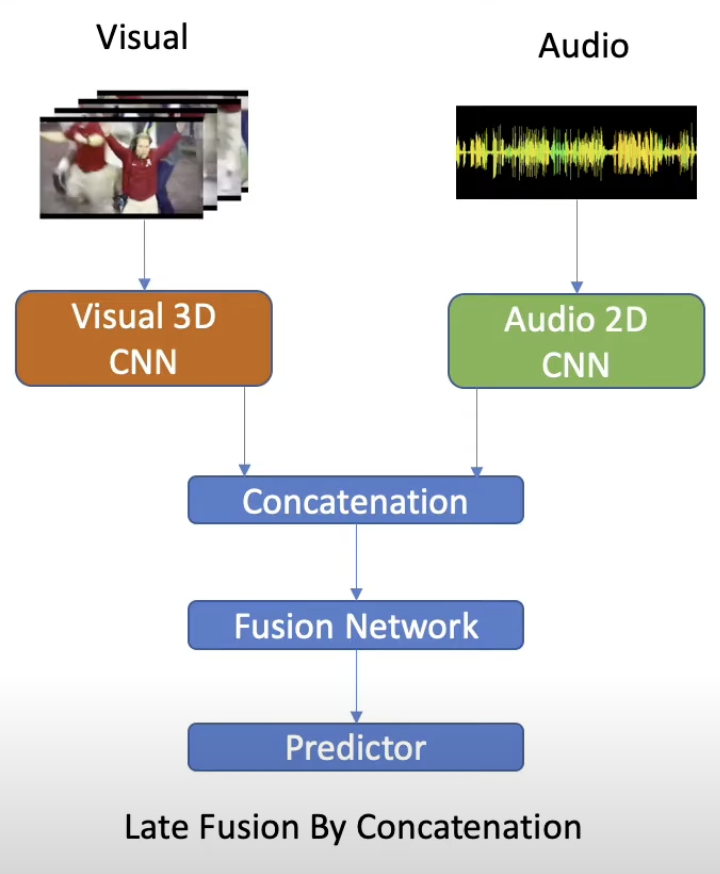
Q. Multi-modlity를 사용하는 이유?
- 더 잘 학습하고 단일 모달리티보다 풍부한 정보로 쉽고, 정확하게 모델의 성능을 높이기 위해
In Theory: More modalities should boost model easy
In Practice: Best Uni-modal model performs better
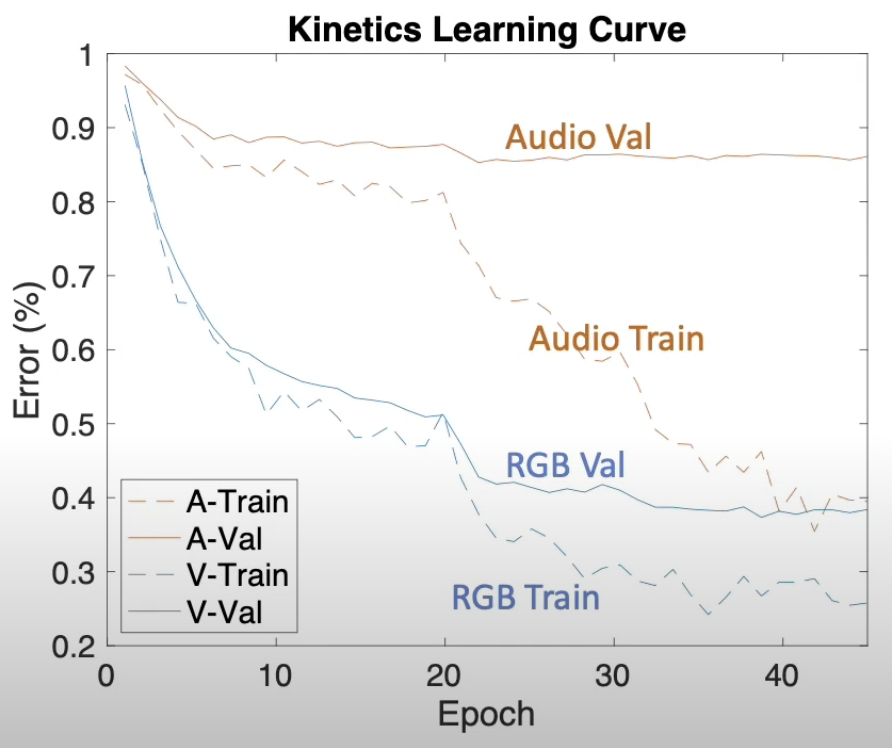
-> 실제 학습 과정을 보면, Audio feature와 Visual feature(RGB)가 각각 다른 epoch에서 overfitting이 일어나고, overfitting도 다른 rate으로 일어난다.
Deep-learning training
딥러닝 학습과정에서 가장 중요한 것은 뭐?
1. Optimization
2. Generalization
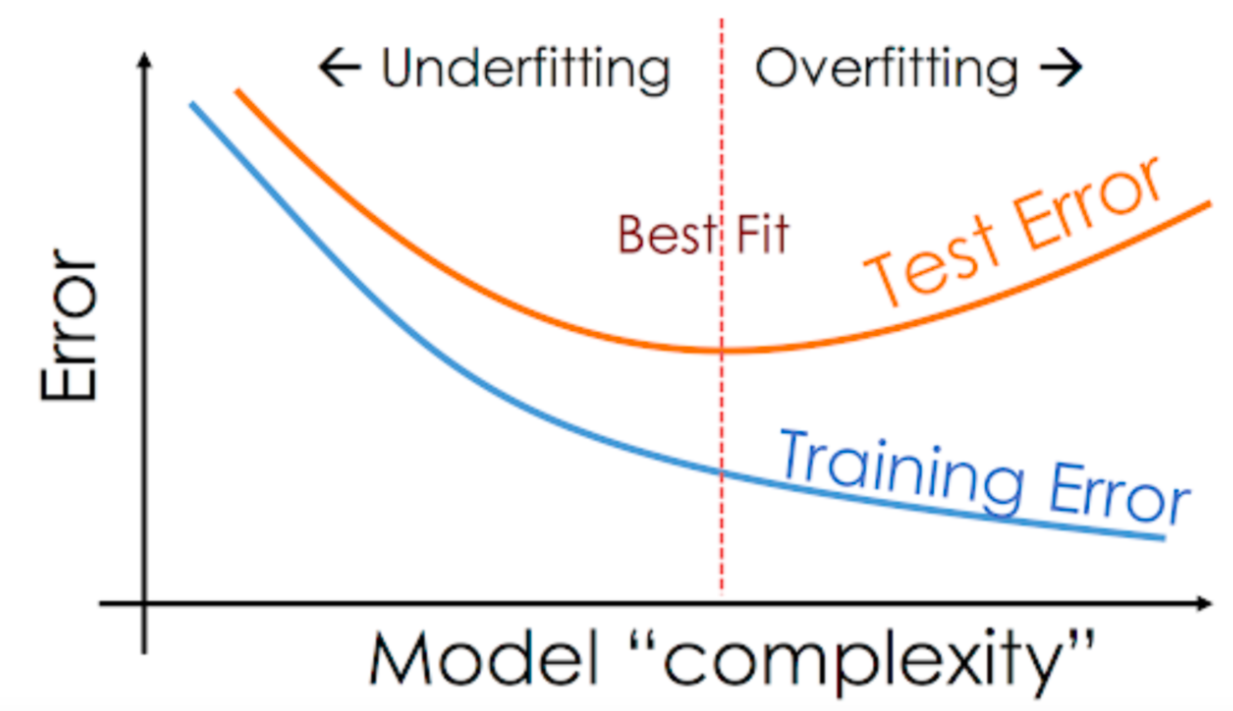
-> Overfitting과 Underfitting이 일어나지 않는 정도에서 Optimization과 Generalization의 균형을 잘 잡는 것이 중요
Introduction
Theory: 이론상으로는 모달리티가 추가됨에 따라 정보가 더 늘어남으로 모델이 더 잘 학습해야한다.
Problem in reality: 실제 학습을 해보면 단일 모달을 썻을 때의 모델의 성능이 멀티 모달을 썼을 때의 성능보다 더 좋을 때가 있다.
Solution: 실제로 Multimodal을 썻을 때 성능이 더 안좋은 경우를 보여줌으로 문제를 정의하고, 그 문제를 해결할 수 있는 Metric을 제안하여 SoTA를 달성한다.
Contribution:
-
Empirically demonstrate the significance of overfitting in joint training of multi-modal networks, and we identify two causes for the problem.
-
Propose a metric to understand the problem quantitatively: the overfitting-to-generalization ratio (OGR)
-
Propose a new training scheme which minimizes
OGR via an optimal blend of multiple supervision signals. -
Proposed Gradient-Blending (G-Blend) method gives significant gains in ablations and achieves state-of-the-art (SoTA) accuracy on benchmarks including Kinetics, EPIC-Kitchen, and AudioSet by combining audio and visual signals.
문제 정의 및 검증
1. Unimodal이 더 좋은 경우
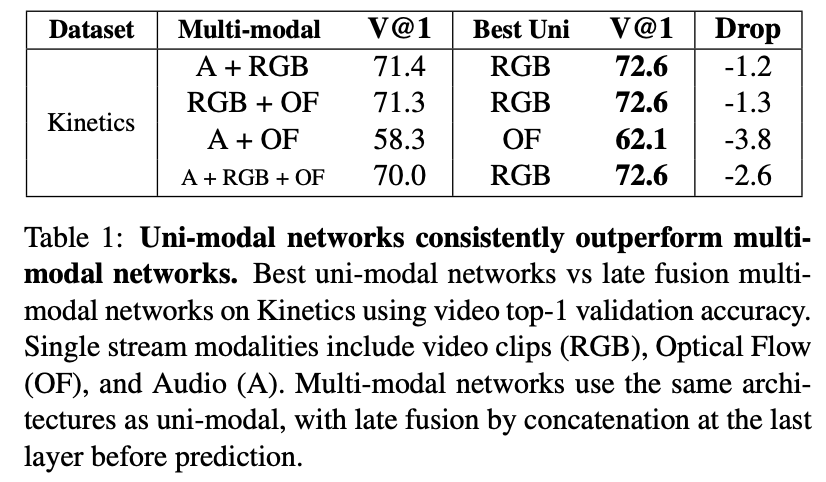
-> Best Unimodal이 더 높은 성능을 보임을 알 수 있음
Why?
Multimodal의 Late fusion과정에서 parameter의 수가 unimodal보다 훨씬 더 많아졌기 때문에 overfitting이 발생하는 것이 원인이다.
*여기서 잠깐!! Optical flow란?

참고: https://velog.io/@yoorachoi/%EC%BB%B4%ED%93%A8%ED%84%B0-%EB%B9%84%EC%A0%84-Optical-Flow-Lukas-Kanade-Method-%EC%A4%91%EC%8B%AC%EC%9D%98-%EA%B0%9C%EB%85%90-OpenCV-%EA%B5%AC%ED%98%84
2. Overfitting을 줄이기 위한 시도들
1. 대안책: Pretraining, Early-stopping, Dropout
2. 구조적 관점에서 대안책: Mid-concatenation, SE-gate, NL-gate
*구조적 관점?
SE-gate: Squeeze-and-Excitation Networks
https://arxiv.org/abs/1709.01507
NL-gate: Non Local Netorks
https://arxiv.org/abs/1711.07971
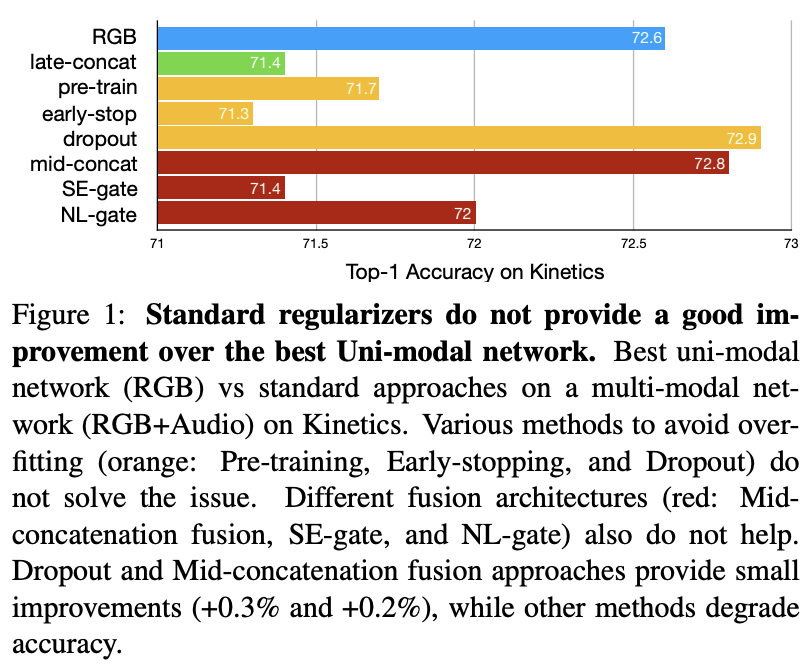
-> 여기서 중요한 point! Dropout을 썼을 때가 가장 좋다? parameter수가 적어야 잘된다! Multimodal인데!
결론: multimodal은 문제가 있는데 그것은 파라미터 수가 늘어남에 따라서 overfitting이 일어나서이고 이것을 정량화해서 해결하는 방안을 제시하겠다.
Multi-modal training via Gradient-Blending
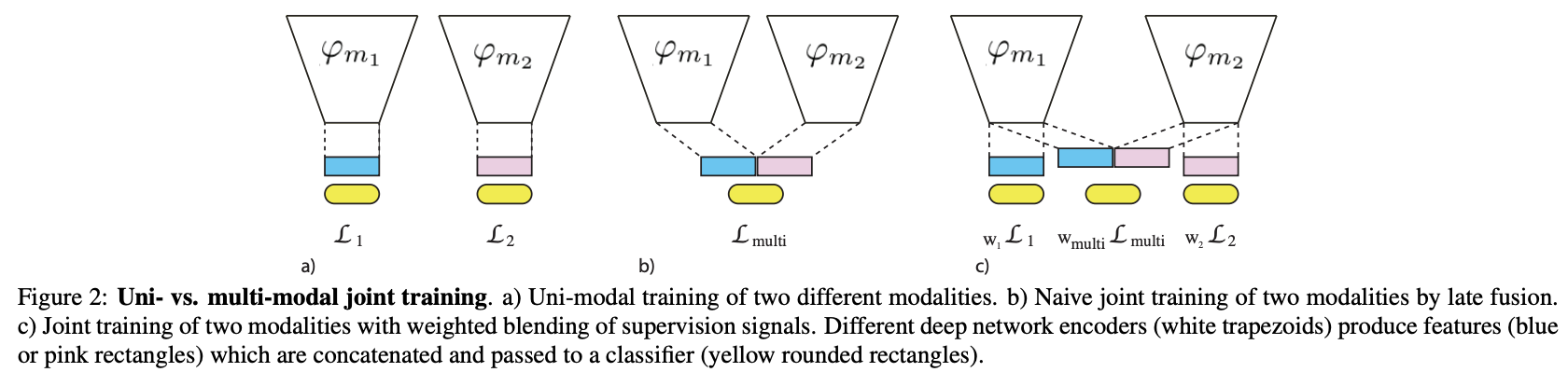
Uni-modal vs Multi-modal
Unimodal loss function
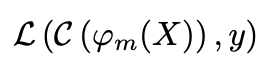
Multimodal loss fuction
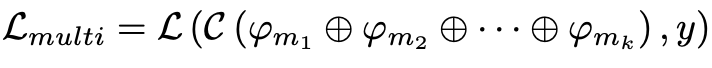
Overfitting-to-Generalization Ratio (OGR)
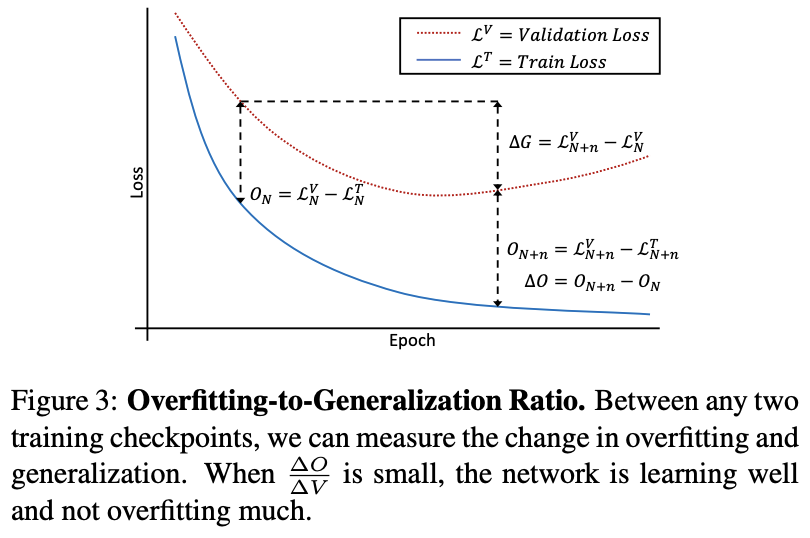
T: Training
V: Validation
Overfitting vs Generalizing
*Overfitting: Learning in a training set that do not generalize to the target distribution.
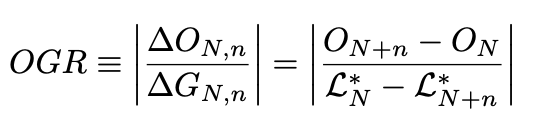
L* = Ground True Loss, True Label
-> True loss를 구하는 건 어렵기 때문에 val loss로 하는 거임
G = 각 체크포인트에서 val loss 변화
O = 각 체크포인트에서 train loss와 val loss의 차이
-> 이 OGR은 학습과정의 품질, 즉 Overfitting과 Generalizing의 품질을 측정함.
-> 논문에서는 이 OGR을 최소화하면서 학습하는 Metric과 scheme을 제안함.
-> 그러나 underfitting의 경우 O의 값 자체가 작아서 여러 gradient를 혼합하는 아래 수식으로 극소값을 최소화하는 방법으로 진행됨.
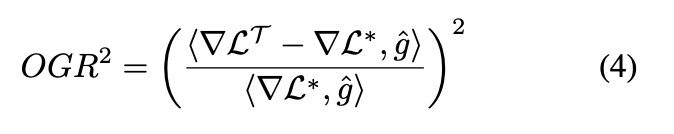
How to use in Practice?
Unimodal + Multimodal loss의 총합을 사용
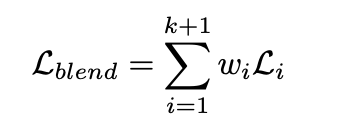
k+1= k개의 단일 modality + 하나의 multimodal rep.
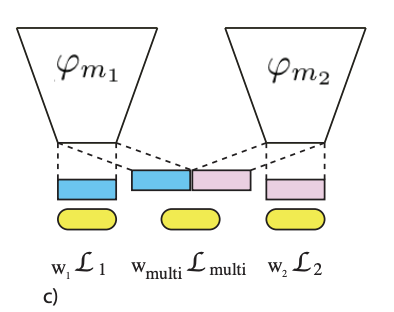
Modality m1, m2에서 각각 나온 feature와 그 둘을 concat해서 fusion한 multimodal feature를 각각의 loss를 구한 후, 이 loss들을 blending한다고 해서 Gradient Blending임.
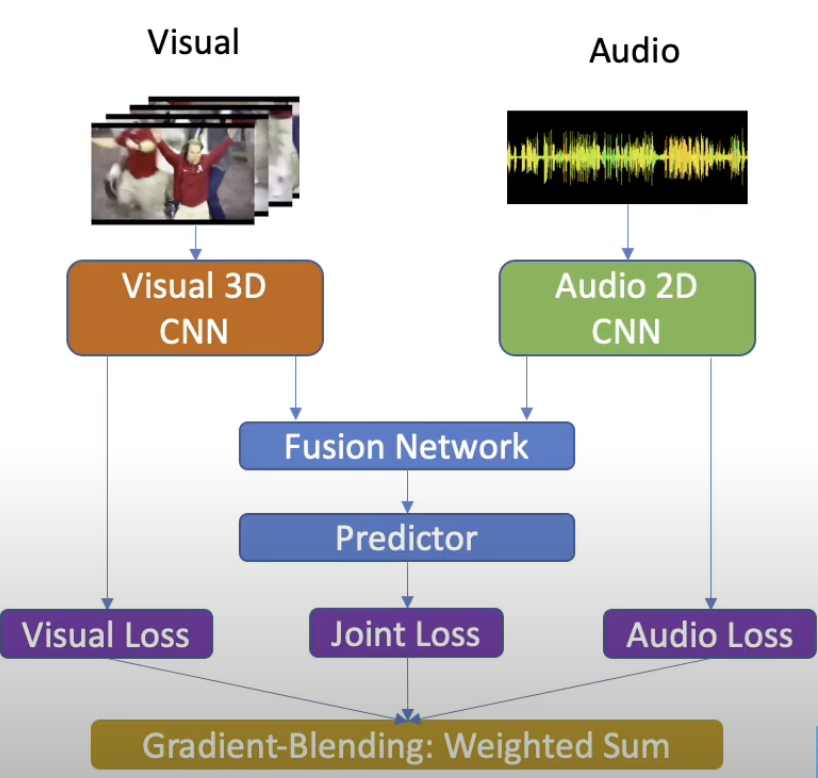
*Blending? 믹서기 블랜딩 생각해보면 됨! 하나의 vector로 혼합한다는 것.
Code review
Official code가 없다! 근데 code보다 method를 제안하는 것이기 때문에 코드보다 pseudocode를 살펴보는 것이 논리를 파악하기 더 좋을 거 같다.
Measuring OGR
1. G-B Weight Estimation

2. Weight측정 방식에 따른 두가지 버전
2.1 Offline G-B

-> 전체 N epoch에 대해서 측정
2.2 Online G-B

-> 전체 N epoch에서 작은 n에폭마다 측정
Result
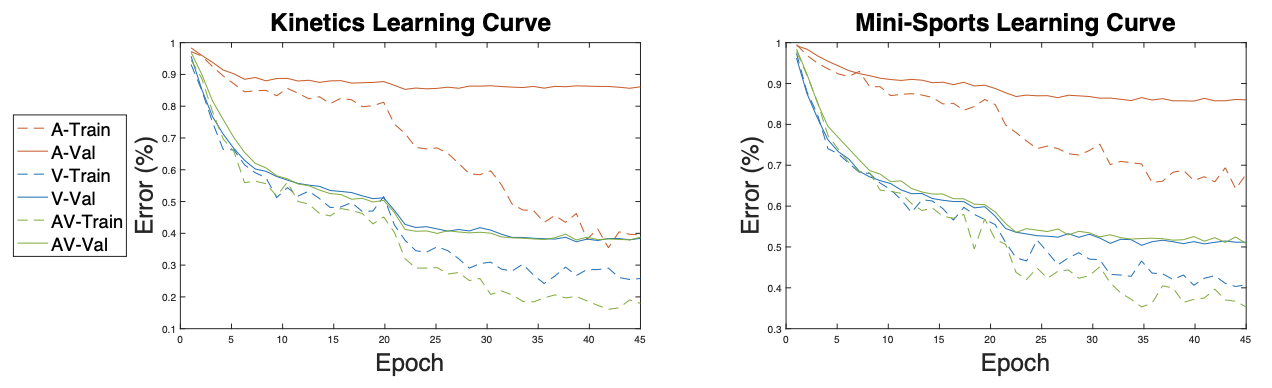
먼저, 하나의 modal을 썼을 때보다 multiple modal을 썼을 때 overfitting이 더 빠르게 일어난다를 보여주는 실험. (Backbone: ResNet50)
-> 앞서 말한 논문의 전체 문제 정의와 동일.
각 Epoch마다 modality를 반영하는 weight이 어떻게 달라지는지를 보여줌.(멋진 실험...)
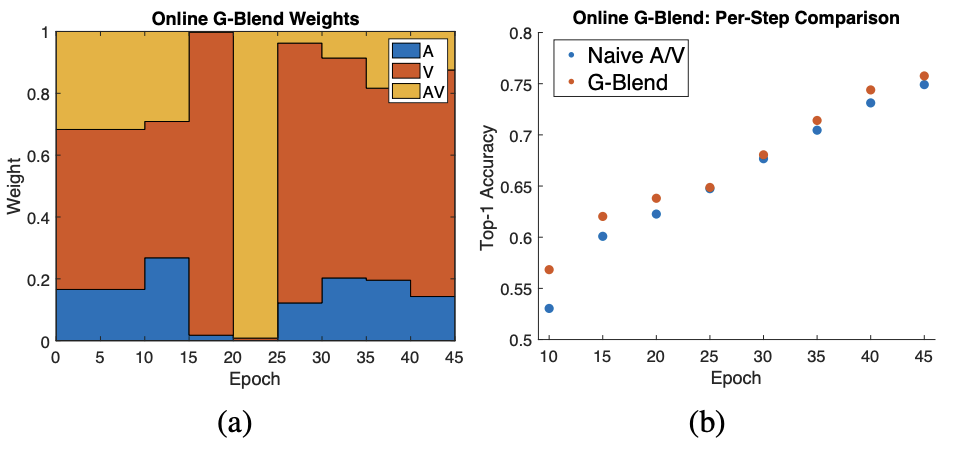
Online Offline두개를 한 이유?
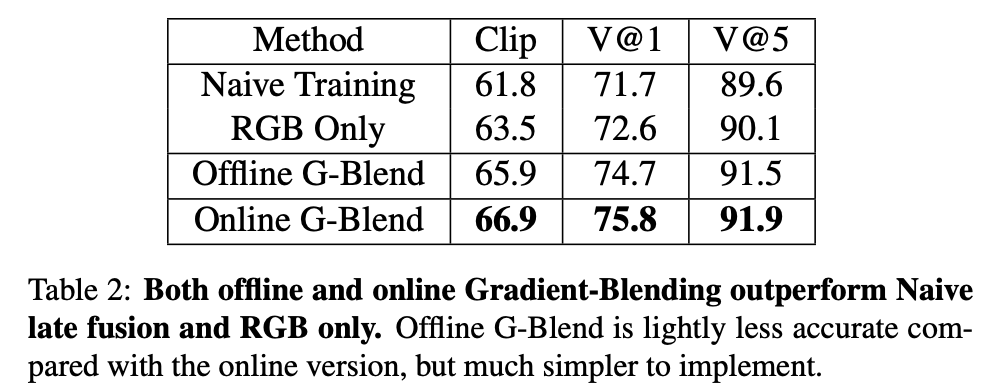
*다른 모달리티를 사용
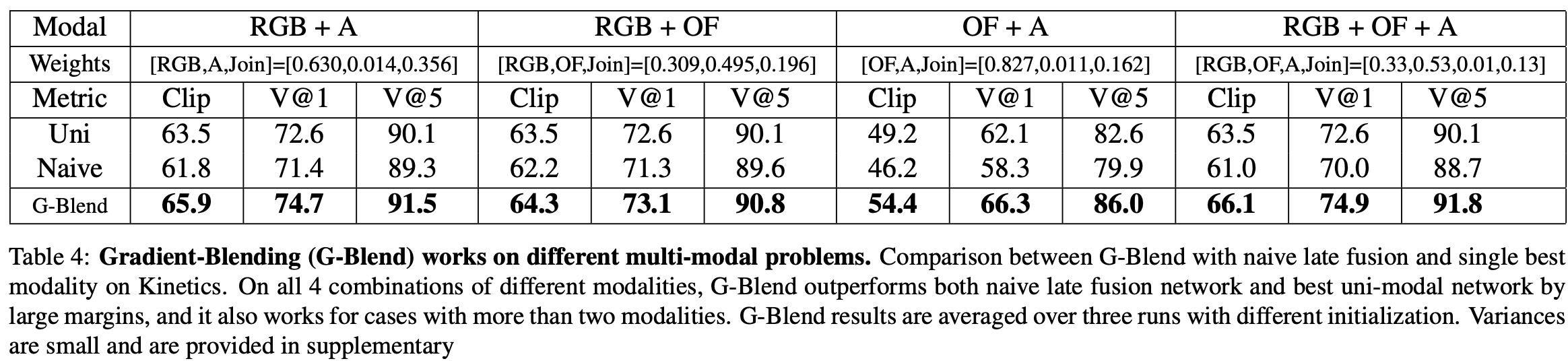
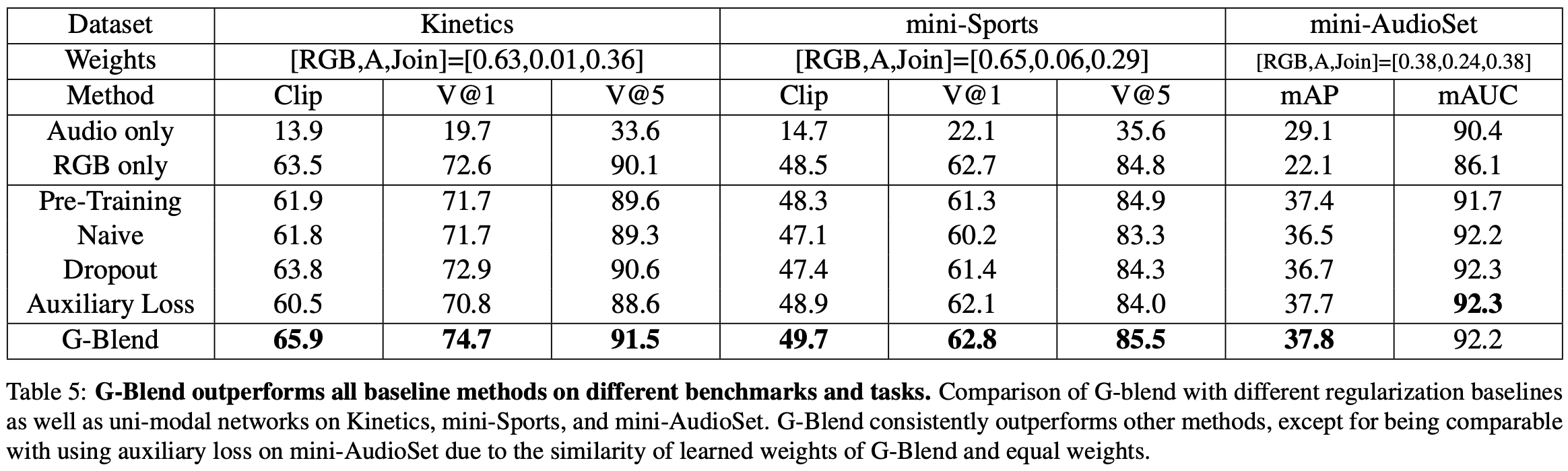
*다른 task에서 사용
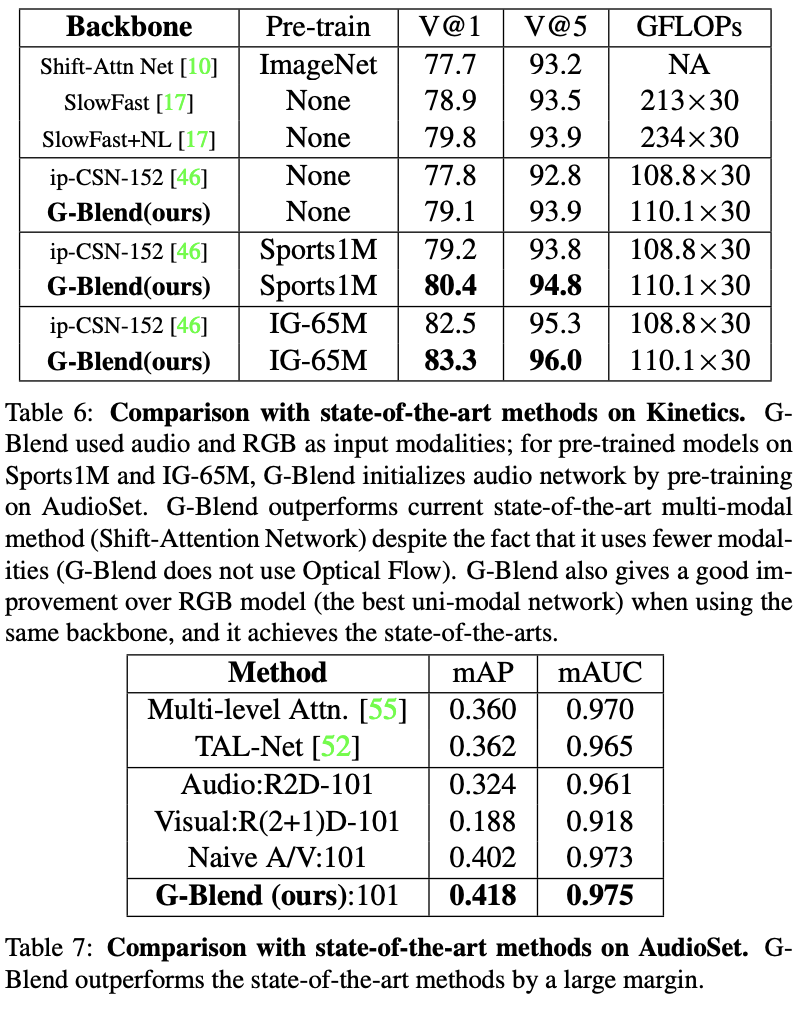
*State-of-the-arts
Conclusion
- Multimodal에서 당연히 생기는 문제를 정확히 짚었다
- Multimodal에서 생기는 overfitting을 측정하는 OGR과 그것을 minimize함으로써 해결하는 방법을 제안함
- unimodal, multimodal loss를 하나로 Blending을 해도 된다는 것을 보여줌
- Multi-Task, Multi-modal, Multi-level Fusion 전부에서 SoTA를 달성
느낀점
-
장점: 문제 정의가 확실함. 구체적으로 이전까지는 multimodal representation으로 total loss를 구해서 사용하고, 이 논문 이전에는 multimodal이 unimodal보다 성능이 안좋은 경우와 이유에 대해서 규명하지 않았는데 이 논문이 그 문제를 규명하고 해결함. 그리고 gradient를 blending해도 됨을 수학적으로 증명하고 실험적으로 검증하는 과정이 매우 논리적임..
-
한계점: (1) 모달리티를 처리하는 방법을 한줄도 설명하지않아서 개인적으로 궁금함(ex. modality shape, 각 modality의 loss function 등) (2) 실험에서 G-Blend모델의 성능이 더 떨어지는 경우에 있어서는 Audio-Visual relevant가 적어서 그렇다고 하는데 (즉 모달리티끼리 상관관계가 없어서 모델이 잘못됐다기 보다는 겹치는 정보량의 문제) 뭔가 조금 이상함..
-
소감: 저번 CVPR논문 발표와 마찬가지로 문제정의랑 문제 해결방안이 너무 논리적이다. 코드를 어떻게해서 성능을 올리거나 그런 것이 아니라 멀티모달에서 중요한 문제를 정의하고 그것을 해결하는 방안을 제시함. 훌륭하다.

4개의 댓글


멀티모달, 멀티태스크 훈련할 때 오버피팅이 나도 그냥 왜 이러지~ 하고 끝났는데, 오늘 발표를 듣고 간과하고 있던 점들을 알게 되어서 너무 좋았습니다!!! 나중에 멀티태스크에도 한 번 적용해보면 좋지 않을까 생각합니다. OGR 값이 weight랑 같이 시각화 되었으면 더 좋았을 것 같다는 아쉬움이 있네용

엄청엄청 재밌었어요 !!!!!!!!!!!!!!!!!!!!!!!!! 멀티모달해보면 정말 단일모달일 때보다 성능이 안 좋을 때가 있어서 왜 그런걸까 ? 굳이 멀티모달 해야 할까 ? 이걸 해결할 방법은 없을까 ? 이런 생각을 했었는데 이 논문이 그 궁금증을 해결해줘서 너무 재밌었습니다 ! 정의한 문제를 증명하는 것부터 논문의 구성이 좋았던 것 같아요