16. Segmentation
16.1. Semantic Segmentation
16.1.1. Deconvolution Network
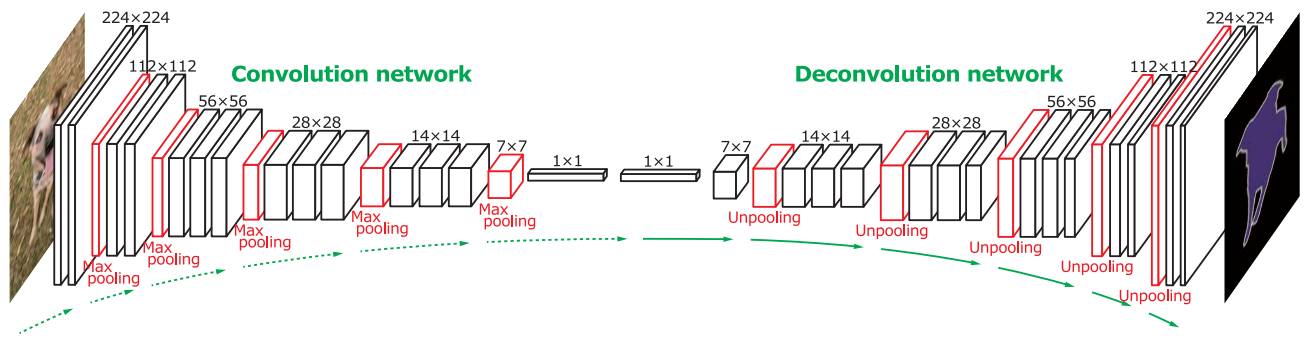
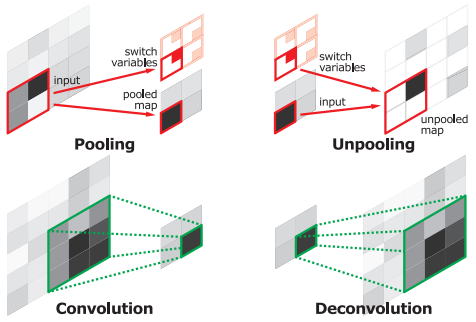
- Unpooling
- Spatial information within a receptive field is lost during pooling, which may be critical for precise localization that is required for semantic segmentation.
- To resolve such issue, unpooling layers reconstruct the original size of activations and place each activation back to its original pooled location.
- Deconvolution
- The output of an unpooling layer is an enlarged, yet sparse activation map.
- The deconv layers densify the sparse activations obtained by unpooling through conv-like operations with multiple learned filters.
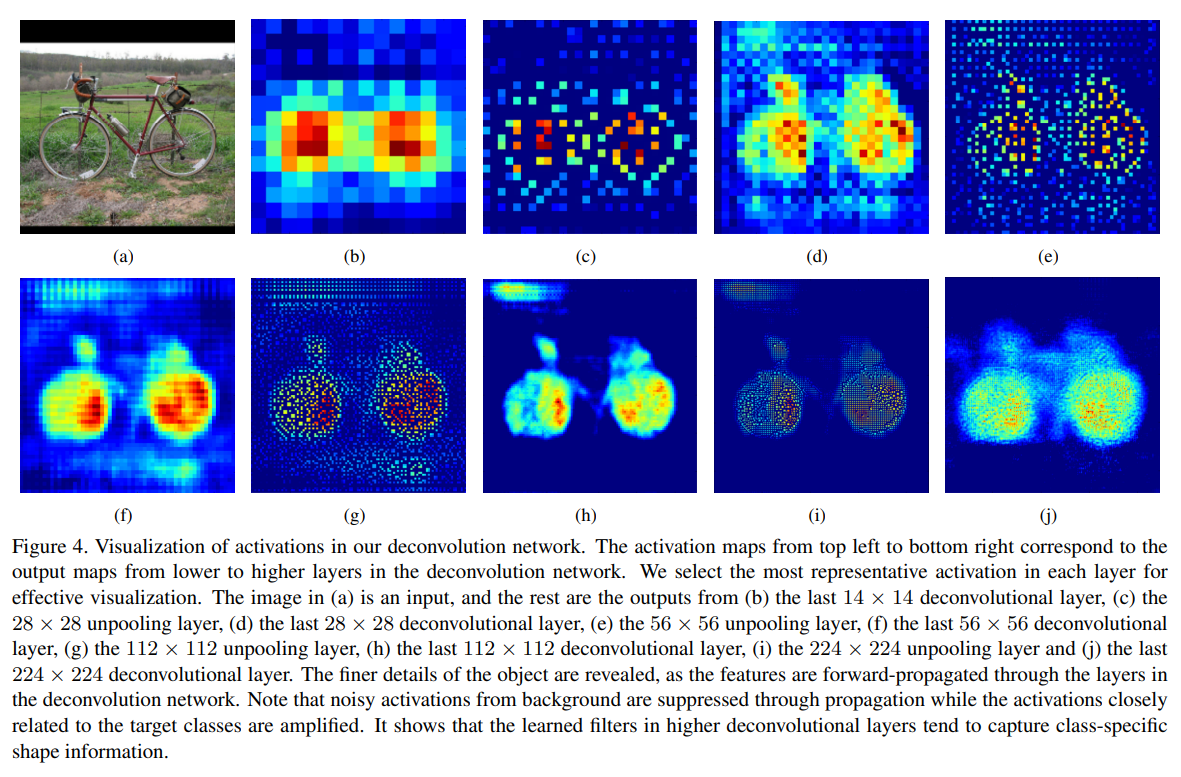
- Analysis of Deconv Net
- Since unpooling captures example-specific structures by tracing the original locations, it effectively reconstructs the detailed structure of an object in finer resolutions.
- Learned filters in deconv layers captures class-specific shapes. Through deconv, the activations closely related to the targe classes are amplified while noisy activations from other regions are suppressed effectively.
16.1.2. U-Net
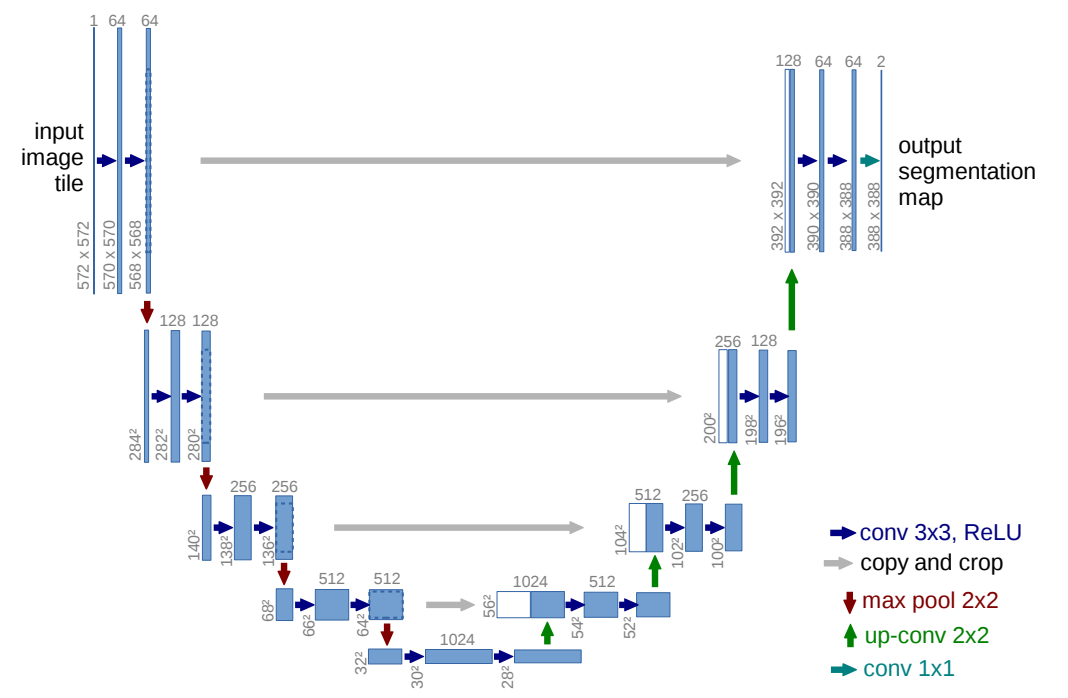
-
Network Architecture
- The network consists of a contracting path (left side) and an expansive path (right side).
- Every step in the expansive path consists of
- an upsampling of the feature map followed by a convolution ("up-convolution")
- a concatenation with the correspondingly cropped feature map from the contracting path
- two conv
-
Loss
- Softmax
- Weight mapA pixel-wise loss weight force the network to learn the border pixels.
- Softmax
16.2. Instance Segmentation
16.2.1. Mask R-CNN
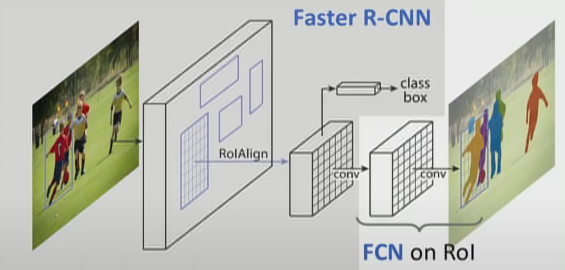
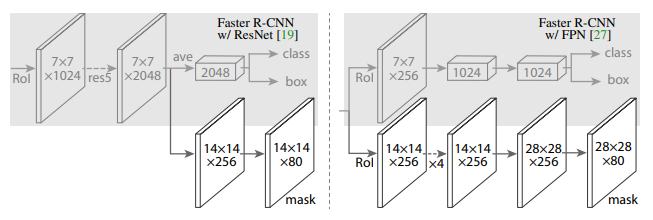
-
Network Architecture
- Faster R-CNN with FCN on RoIs
-
RoIAlign
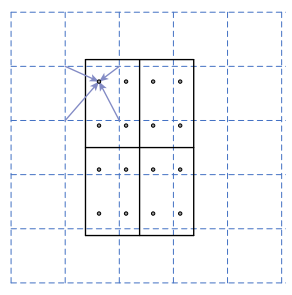
- RoIPool performs quantization which introduces misalignments between the RoI and the extracted features. While this may not impact classfication, it has a large negative effect on predicting pixel-accurate masks.
- RoIAlgin removes the harsh quantization of RoIPool, using bilinear interpolation. So, there is no information loss.
16.3. Segmentation with Transformers
16.3.1. Segmenter
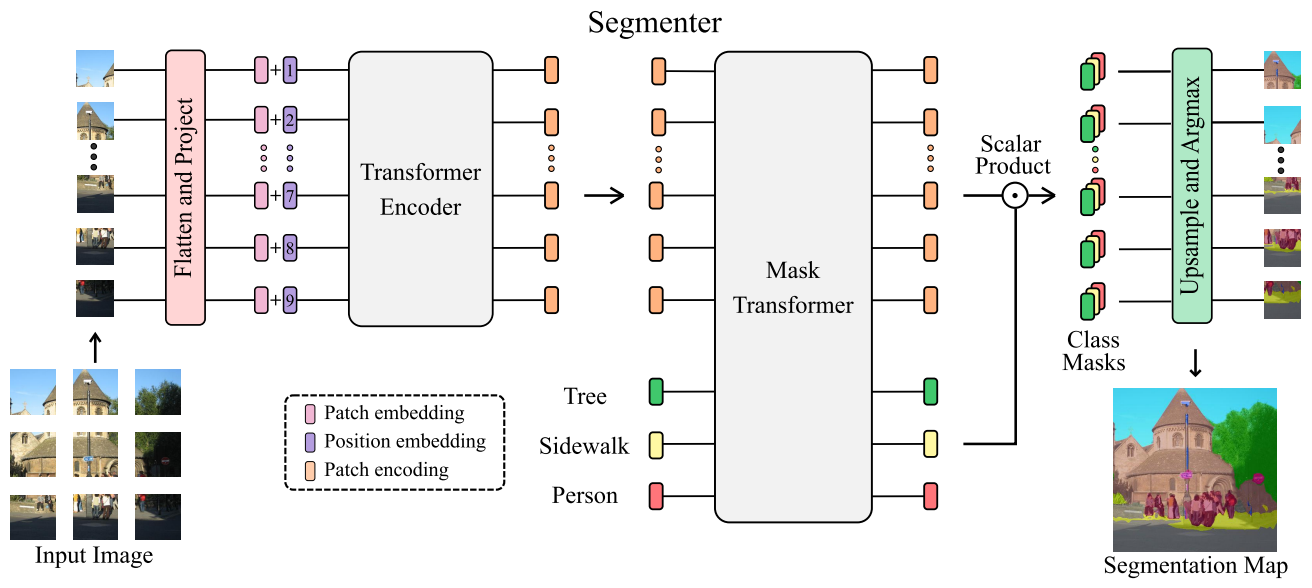
Segmenter is based on a fully transformer-based encoder-decoder architecture mapping a sequence of a patch embeddings to pixel-level class annotations. Its approach relies on a ViT backbone and introduces a mask decoder inspired by DETR.
-
Architecture
-
Encoder
- building upon the ViT (참고: zzwon1212 - ViT)
-
Decoder
-
The sequence of patch encodings is decoded to a segmentation map: where is the number of classes.
-
Flow
- patch-level encodings coming from the encoder
↓ (are mapped by learned decoder) - patch-level class scores
↓ (are upsampled by bilinear interpolation) - pixel-level scores
- patch-level encodings coming from the encoder
-
Mask Transformer
- -normalized patch embeddings output by the decoder
- Class embeddings output by the decoderThe class embeddings are initialized randomly and learned by the decoder.
- The set of class masks
- Reshaped 2D mask
- Bilinearly upsampled feature map
- Final segmentation map is obtained after softmax.
- -normalized patch embeddings output by the decoder
-
-
16.3.2. DPT (Dense Prediction Transformer)
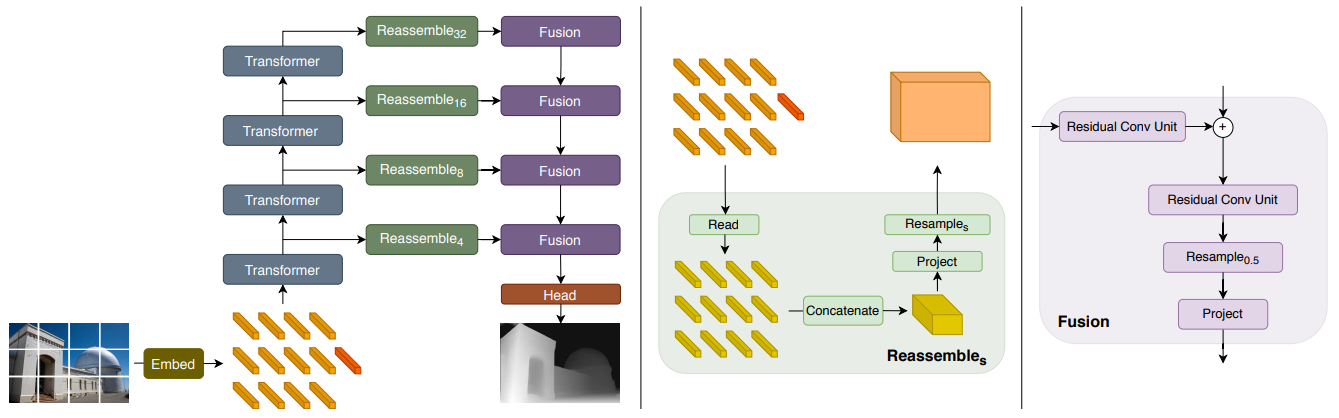
-
Overview
Contextualized tokens at specific transformer layers are reassembled by convolution. Then, reassembled feature maps are fed into fusion block which performs convolution. Finally, a task-specific output head is attached to produce the final prediction. -
Receptive field
- CNNs
progressively increase their receptive field as feature pass through consecutive layers. - Transformer
has a global receptive filed at every stage after the initial embedding.
- CNNs
-
Transformer Encoder
- DPT use ViT as a backbone architecture.
- image
- # tokensis the resolution of image patch. ( in the paper)
- sequence of flattend 2D patches
- trainable linear projection
- patch embedding
- (for ViT-Base)
Feature dimensions > # pixels in an input patch
↓
Embedding procedure can learn to retain information if it is beneficial for the task.
-
Convolutional Decoder
- Reassemble operation
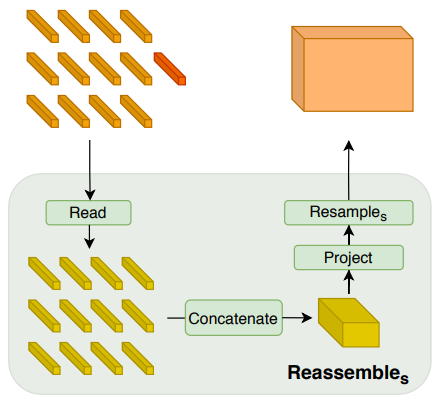 Features from deeper layers of the transformer are assembled at lower resolution.
Features from deeper layers of the transformer are assembled at lower resolution.
Features from early layers are assembled at higher resolution.- Stage 1: ReadThere are three different variants of this mapping, (ignore, add, proj)
- Stage 2: ConcatenateReshape tokens into an image-like representation (Recall )
- Stage 3: Resample
- Use conv to project the representation to (.
- Use (strided) conv or transpose conv to implement donwsampling or upsampling.
- Stage 1: Read
- Fusion block
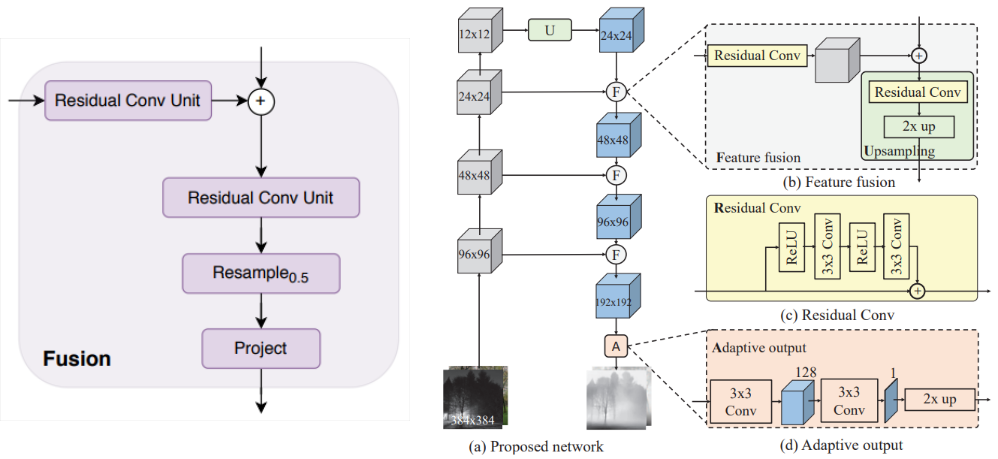
- Combine the extracted feature maps from consecutive stages using a RefineNet-based feature fusion block.
- Progressively upsample the representation by a factor of two in each fusion stage. (e.g. → → → → )
- The final representation size has half the resolution of the input image. (e.g. representation for image)
- Attach a task-specific output head to produce the final prediction.
- Reassemble operation
📙 강의
