13. Transformers Ⅰ
13.1. Word Embedding
A word can be represented as a vector.
-
- Using a large corpus,
- Predict the current word from neighboring words (Common Bag of Worlds; CBOW), or
- Predict the surrounding words given the current one (Skip-gram)
- Word meaning is determined by its (frequently co-occruing) neighboring words.
- Word vectors are fitted to maximize the likelihood:
- Using a large corpus,
-
- Global Vetors: global corpus statistics are directly captured.
- Ratios of co-occurrence probabilities can encode meaning components:
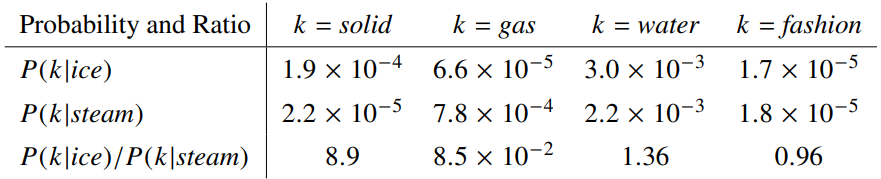
13.2. Transformers
In MLPs, CNNs, and RNNs, the output is a weighted sum (+fixed unary operations) of the input . That is, is optimized to best map the input to the output in the training set, in terms of the loss function.
-
Attention function
Attention() = Attention value -
Self-attention
Each element learns to refine its own representation by attending its context (other elements in the input). More specifically, as a weighted sum of other elements (not arbitrary weights) in the sequence.
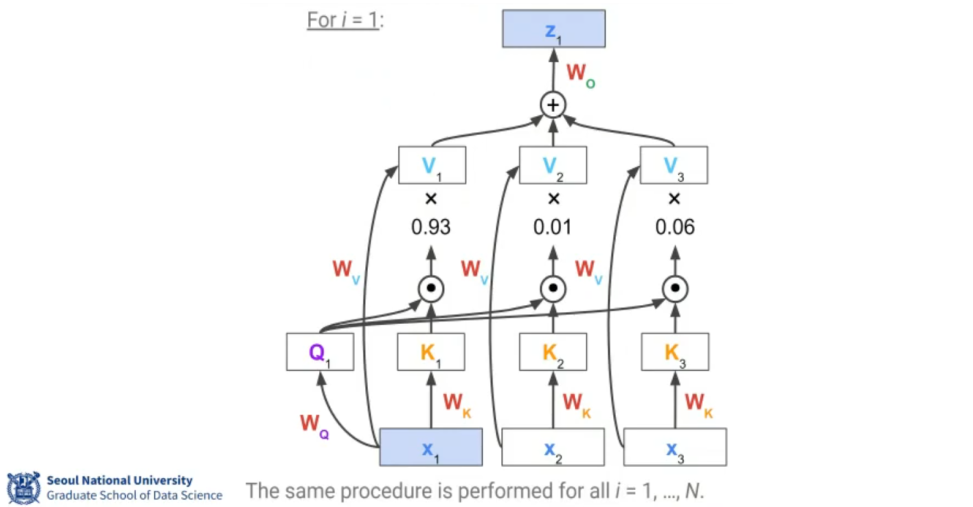
- With Transformer, we make Query, Key, and Value.
- From the input tokens
- Each token is mapped to its own Query , Key , Value vectors by a linear transformation.
- The linear weights are the learned parameters, shared by all inputs.
- learns how to represent a vector to serve as a Query (Key, Value) in general.
- We need another learnable parameter , which maps the attention value back to the original space.
- Each token becomes the Query when we learn about .
- References are all tokens in the input sequence, including itself.
- The step above figure is repeated multiple times to further contextualize.
- With Transformer, we make Query, Key, and Value.
-
Training the Transformer model
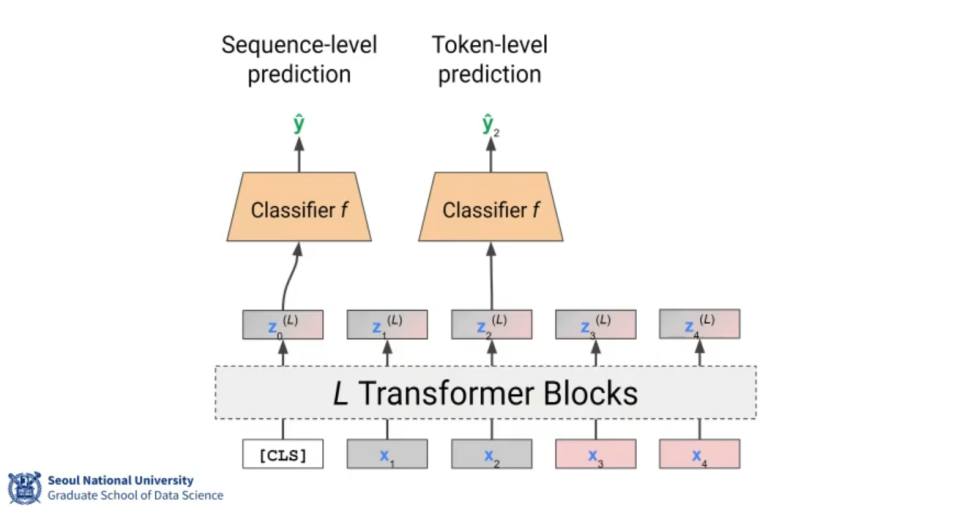
A dummy token (called classification token) is appended to the input sequence, and use it as the aggregated embedding.
-
Transformer
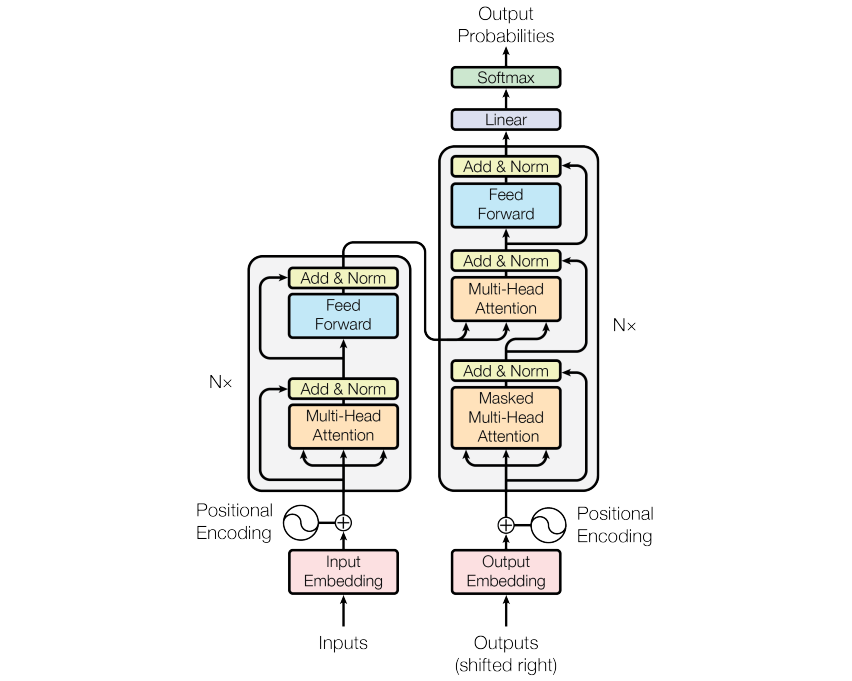
- Multi-head Self-attention
Having multiple projections to is beneficial. Because it allows the model to jointly attend to information from different representation subspaces at different positions.- Multiple self-attentions output multiple attention values . So, simply concatenate them, then linearly transform with it back to the original input size.
- Feed-forward layer
Each contextualized embedding goes through an additional FC layer. It is applied separately and identically, so there is no cross-token dependency. - Residual connection
- Layer normalization
- Positional Encoding
- Masked Multi-head Self-attention
The predictions for position can depend only on the known outputs at positions less than . - The decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack.
- Decoding steps are repeated until the next word is predicted as [EOS] (End of Sentence).
- The output sentence may be chosen greedily (always the top one), or deferred with top- choices (called beam search).
- Multi-head Self-attention
13.3. BERT (Bidirectional Encoder Representations from Transformers)
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
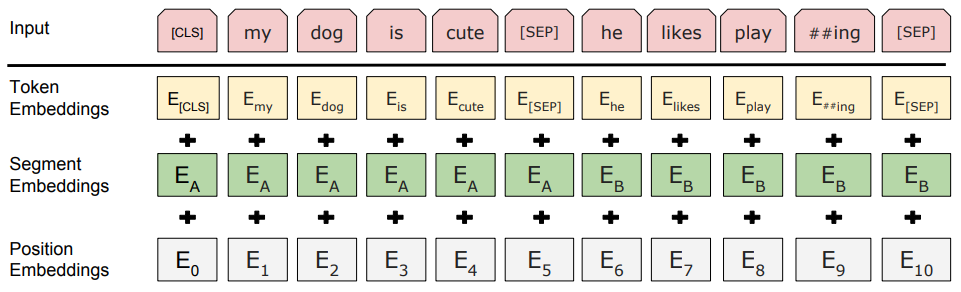
These days, the pre-trained BERT is a default choice for word embeddings.
-
BERT
- Large-scale pre-training of word embeddings using Transformer encoder
- Self-supervised: no human rating required
- Use the encoder (bi-directional; no masking) only
-
Training task 1: Masked Language Modeling (MLM)
- Masking 15% of tokens randomly (substituting it to a special [MASK] token)
- Classify the output embedding for these positions across the vocabulary.
-
Training task 2: Next Sentence Prediction (NSP)
- A binary classification problem, predicting if the two sentences in the input are consecutive or not.
- Half of training data: two consecutive sentences
- The other half: two sentences randomly chosen from the corpus
- A binary classification problem, predicting if the two sentences in the input are consecutive or not.
📙 강의
