11. Recurrent Neural Networks
-
Sequential Data
label y는 task에 따라 single일 수도, sequence일 수도 있다.- Image Captioning
- Visual Question & Answering (VQA)
- Visual Dialog (Conversation about an Image)
- Visual Language Navigation
-
Types of Neural Networks
- One-to-one
- Many-to-one
- One-to-many
- Many-to-many
- Sequence-to-sequence
-
Internal State
At each step, the new internal state is determined by its old state as well as the input (feedback loop). -
The same function () and the same set of parameters () are used at every time step.
- For binary classification (many-to-many)
- For regression (many-to-many)
- For binary classification (many-to-many)
-
Multi-layer RNN
-
LSTM

- cell state
- forget gate
- input gate
- output gate
-
GRU
12. RNN-based Video Models
- RNN-based Spatio-Temporal Modeling
- LRCN (Long-term Recurrent Convolutional Network)
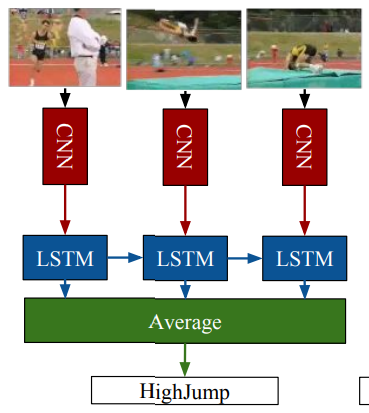
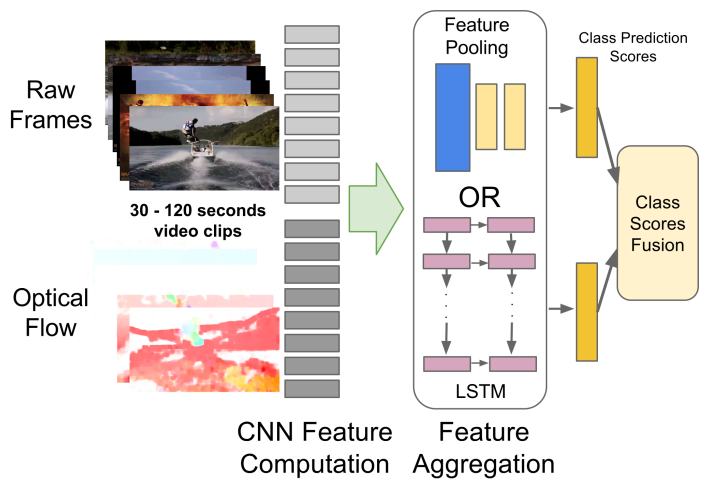
- Beyond Short Snippets
- ConvLSTM
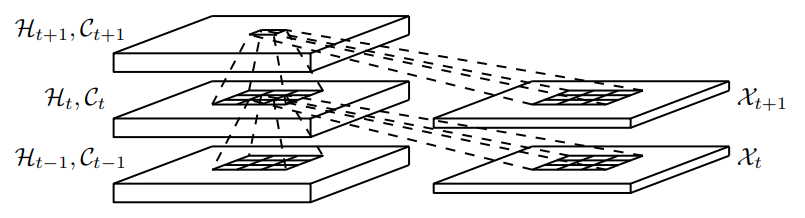
- input, hidden, cell, weight (w, u, v)가 모두 2차원
- FC 대신 CNN을 사용
- ConvGRU

- LRCN (Long-term Recurrent Convolutional Network)
Attention Mechanism
- RNN has Information Loss problem.
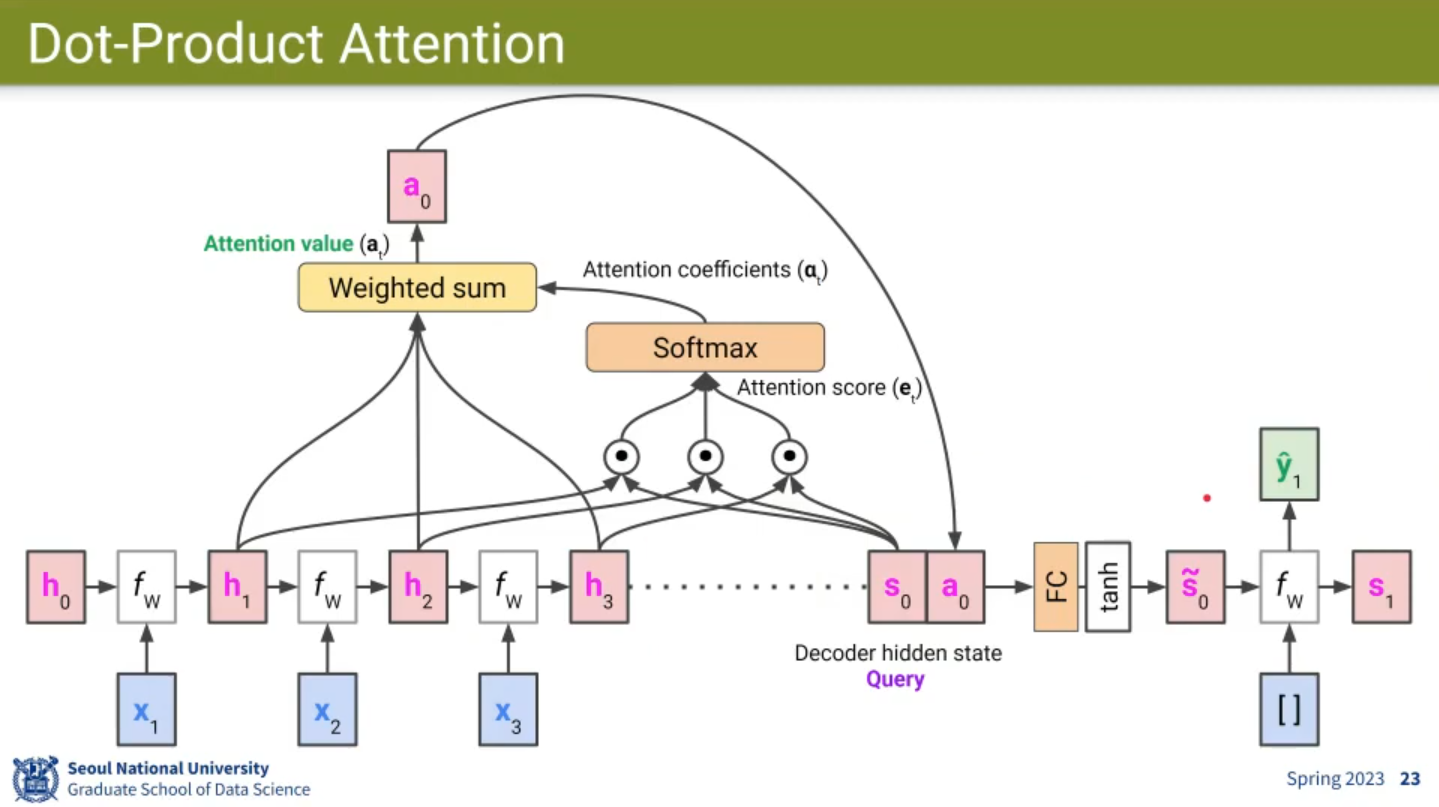
-
Attention Summary
- Query: decoder hidden state
- Key, Value: encoder hidden states
- Attention Value: weighted average of encoder hidden states
- Weights: similarity to (attention coefficients)
-
Attention-based Video Models
- MultiLSTM
- Query: previous hidden state of LSTM
- Key, Value: recent input frame features
- Attention value: weighted sum of recent frame features
- Visual Attention
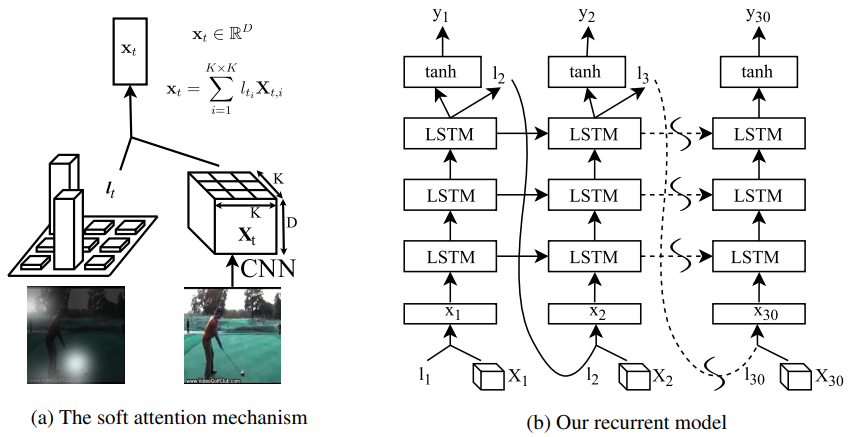
- Spatial attention
"Where should we focus on the 2D image space to classify the video correctly?"
Spatial attention provides interpretability.- : spatial attention coefficients
- : the last conv-layer representation of an input image
- Query: previous hidden state of the last LSTM ()
- Key, Value: regional features from input
- Attention value: weighted sum of region features
- Weights: proportional to relevance to
- Spatial attention
- MultiLSTM
📙 강의

JUST DO IT.