1. 개요
-
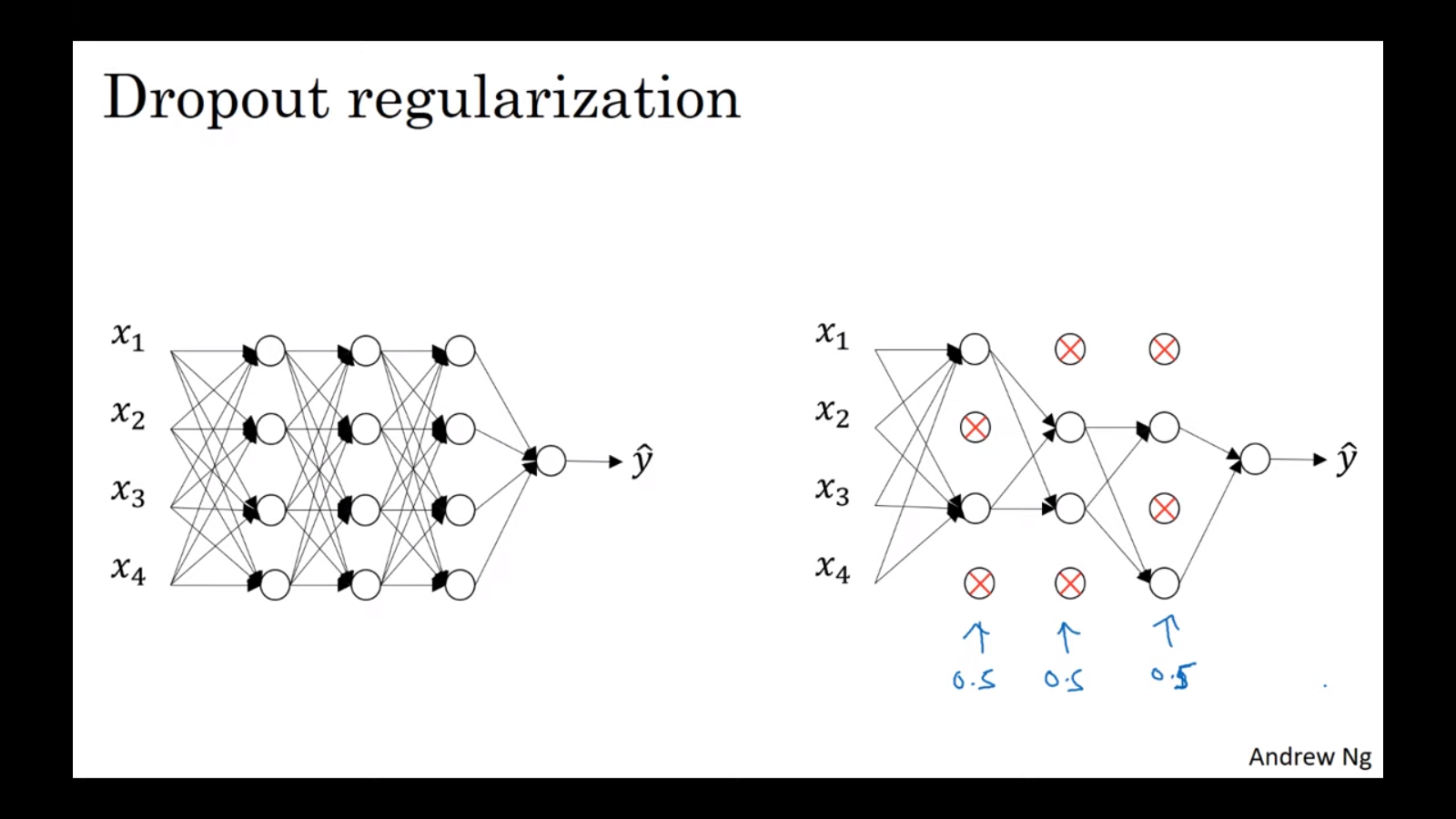
무작위로 신경망의 unit을 제거한다.
-
직관
① 각 배치에 대해 더 작은 네트워크로 train하기 때문에 overfitting을 해결한다.
② hidden unit의 입장에서 한 입력에(feature에?) 의존할 수 없게 된다. 다시 말해, 특정 입력에 유난히 큰 weight를 부여할 수 없게 된다. 따라서 가중치를 분산시킴으로써 마치 L2 regularization처럼 weights를 shrink한다. (Can't rely on any one feature, so have to spread out weights.) -
한 배치에서 같은 hidden unit을 계속 0으로 만들지 않도록 하기 위해서, 반복마다 0이 되는 hidden unit이 달라져야 한다(당연하게도).
2. Implementation of Inverted dropout
keep_prob = 0.8
d3 = np.random.rand(a3.shape[0], a3.shape[1]) < keep_prob
a3 = np.multiply(a3, d3) # a3 *= d3
a3 /= keep_prob- inverted dropout은 train과 test 간 scaling 문제를 해결한다.
- test에서는 dropout을 적용하지 않는다.
- 보편적인 방법이다.
3. Tips
-
각 hidden layer마다 keep_prob을 다르게 설정해도 된다.
- 예: size가 큰(즉, overfitting의 우려가 큰) 행렬에 낮은 keep_prob 부여
- tuning해야 하는 hyperparameter(keep_probs)가 많아지게 된다는 단점이 있다.
- 대안으로는 dropout을 적용할 층들을 고른 뒤에, keep_prob을 하나의 값으로만 사용하는 방법이 있다.
-
입력층에도 dropout을 적용할 수 있지만 자주 사용되는 방법은 아니며, 적용한다면 1에 가까운 확률(0.9 등)을 부여하는 것이 좋다.
-
Computer Vision에서는 모든 픽셀값을 사용하기 때문에 대부분의 경우 데이터가 부족하다. 따라서 거의 항상 dropout을 사용한다. 그러나 네트워크가 overfitting 문제를 가지기 전까지는 적용하지 않아야 한다(당연하게도).
-
매 반복마다 hidden unit이 제거되기 때문에 cost function이 더이상 잘 정의되지 않는다는 큰 단점이 있다. 따라서 Andrew Ng은 아래 방법을 추천한다.
① dropout을 적용하지 않은 채로 cost function이 단조 감소하는지 확인한다.
② dropout을 적용한 뒤 코드를 변경하지 않는다.
📙 참고
