1. Naive Convolution
-
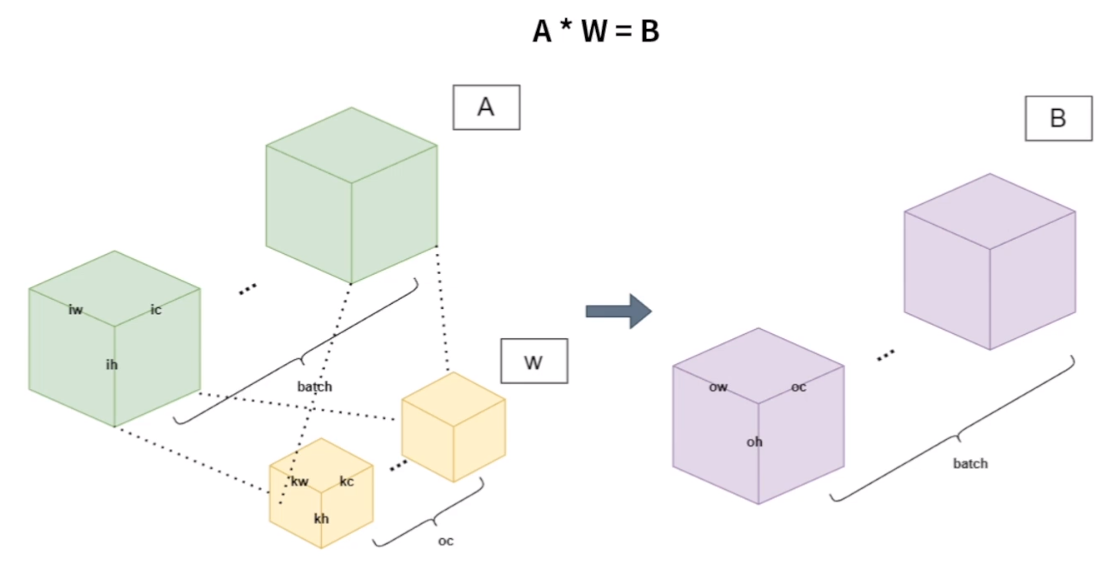
Shape
- A: [batch_size, in_channel, in_height, in_width]
- W: [out_channel, kernel_channel, kernel_height, kernel_width]
- B: [batch_size, out_channel, out_height, out_width]
-
Weight sharing between images in the same batch -
MAC (Multiply Accumulation operation)
- 아래에서 볼 수 있듯이 convolution 연산을 naive하게 구현하는 것은 비효율적이다.
- 7 Loops
# 7 Loops in convolution operation for b in batch: for oc in out_channel: for oh in out_height: for ow in out_width: for kc in kernel_channel: for kh in kernel_height: for kw in kernel_width:
-
구현
def conv(self, A, W): B = np.zeros((self.batch, self.out_c, self.out_h, self.out_w)) for b in range(self.batch): for oc in range(self.out_c): # each channel of output for oh in range(self.out_h): for ow in range(self.out_w): # each pixel of output shape a_j = oh * self.stride - self.padding for kh in range(self.k_h): if not self.check_range(a_j, self.in_h): B[b, oc, oh, ow] += 0 else: a_i = ow * self.stride - self.padding for kw in range(self.k_w): if not self.check_range(a_i, self.in_w): B[b, oc, oh, ow] += 0 # TODO 그냥 pass 하면 안 돼? else: B[b, oc, oh, ow] += np.dot(A[b, :, a_j, a_i], W[oc, :, kh, kw]) a_i += self.stride a_j += self.stride return B
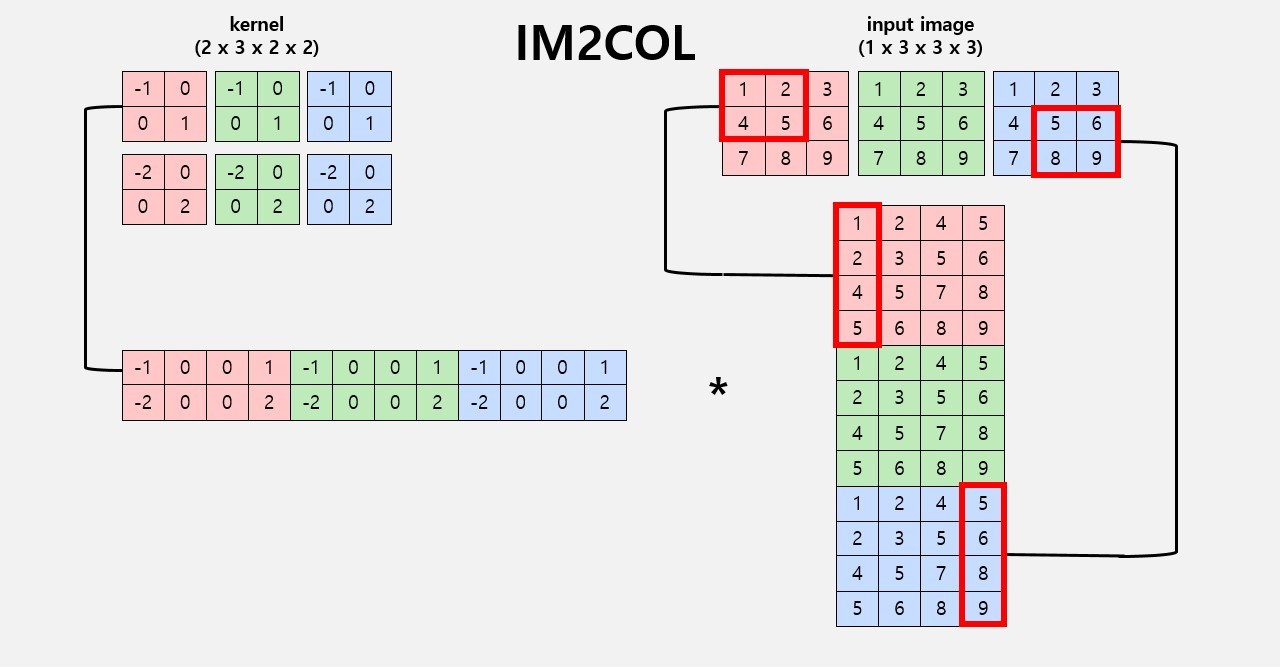
2. IM2COL & GEMM
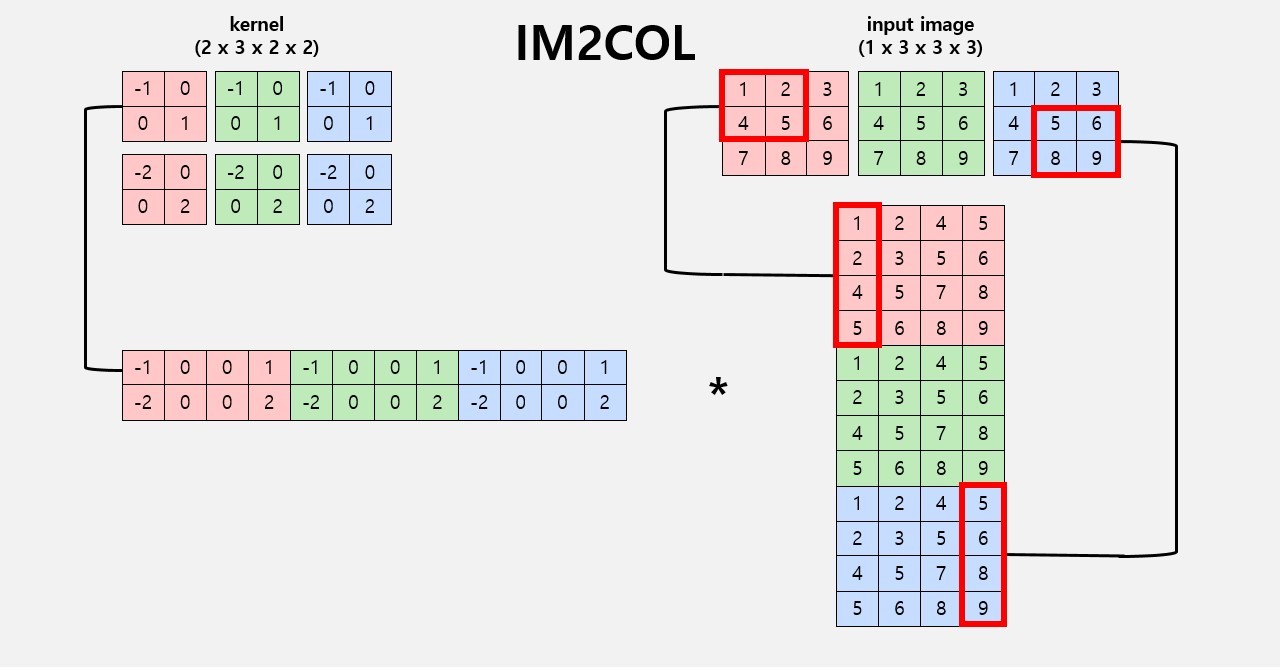
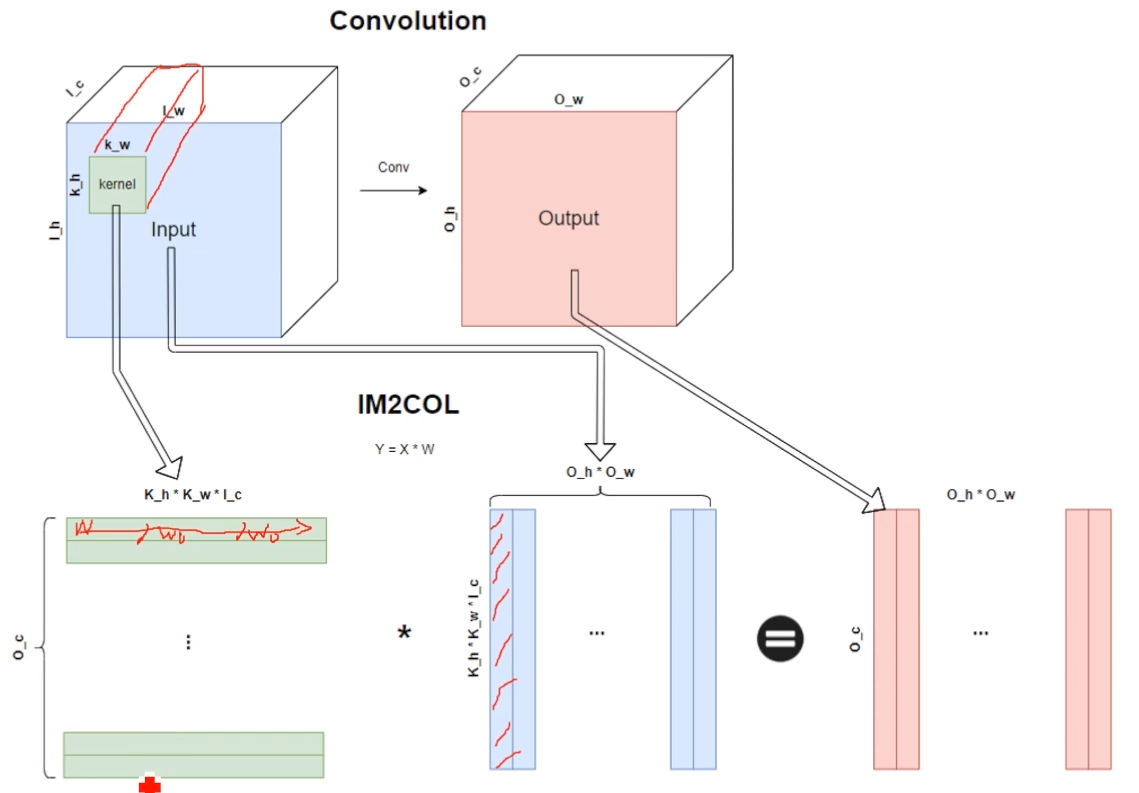
-
loop를 7번 도는 Naive Convolution의 비효율적인 연산을 효율적으로 해결
-
IM2COL
- Transform n-dimensional data into 2D matrix data
- more efficien operation
-
GEMM
- General Matrix to Matrix Multiplication
-
구현
# IM2COL. change n-dim input to 2-dim matrix def im2col(self, A): mat = np.zeros((self.in_c * self.k_h * self.k_w, self.out_h * self.out_w), dtype=np.float32) mat_i = 0 mat_j = 0 for c in range(self.in_c): for kh in range(self.k_h): for kw in range(self.k_w): in_j = kh * self.dilation - self.padding for oh in range(self.out_h): if not self.check_range(in_j, self.in_h): for ow in range(self.out_w): mat[mat_j, mat_i] = 0 mat_i += 1 else: in_i = kw * self.dilation - self.padding for ow in range(self.out_w): if not self.check_range(in_i, self.in_w): mat[mat_j, mat_i] = 0 mat_i += 1 else: mat[mat_j, mat_i] = A[0, c, in_j, in_i] mat_i += 1 in_i += self.stride in_j += self.stride mat_i = 0 mat_j += 1 return mat # GEMM. 2d matrix multiplication def gemm(self, A, W): a_mat = self.im2col(A) w_mat = W.reshape(W.shape[0], -1) b_mat = np.matmul(w_mat, a_mat) # print(a_mat) # print(a_mat.shape) b_mat = b_mat.reshape([self.batch, self.out_c, self.out_h, self.out_w]) return b_mat
3. 연산 소요 시간 비교
| Method | Time |
|---|---|
| Naive | 54.14ms |
| IM2COL & GEMM | 2.72ms |
| PyTorch | 2.19ms |
- Convolution 연산을 10번 반복하여 측정한 시간을 비교한 결과이다.
- IM2COL & GEMM이 Naive보다 월등히 빠르지만, PyTorch보다는 약간 느리다.
- PyTorch IM2COL & GEMM Naive
📙구현 코드 GitHub

JUST DO IT.