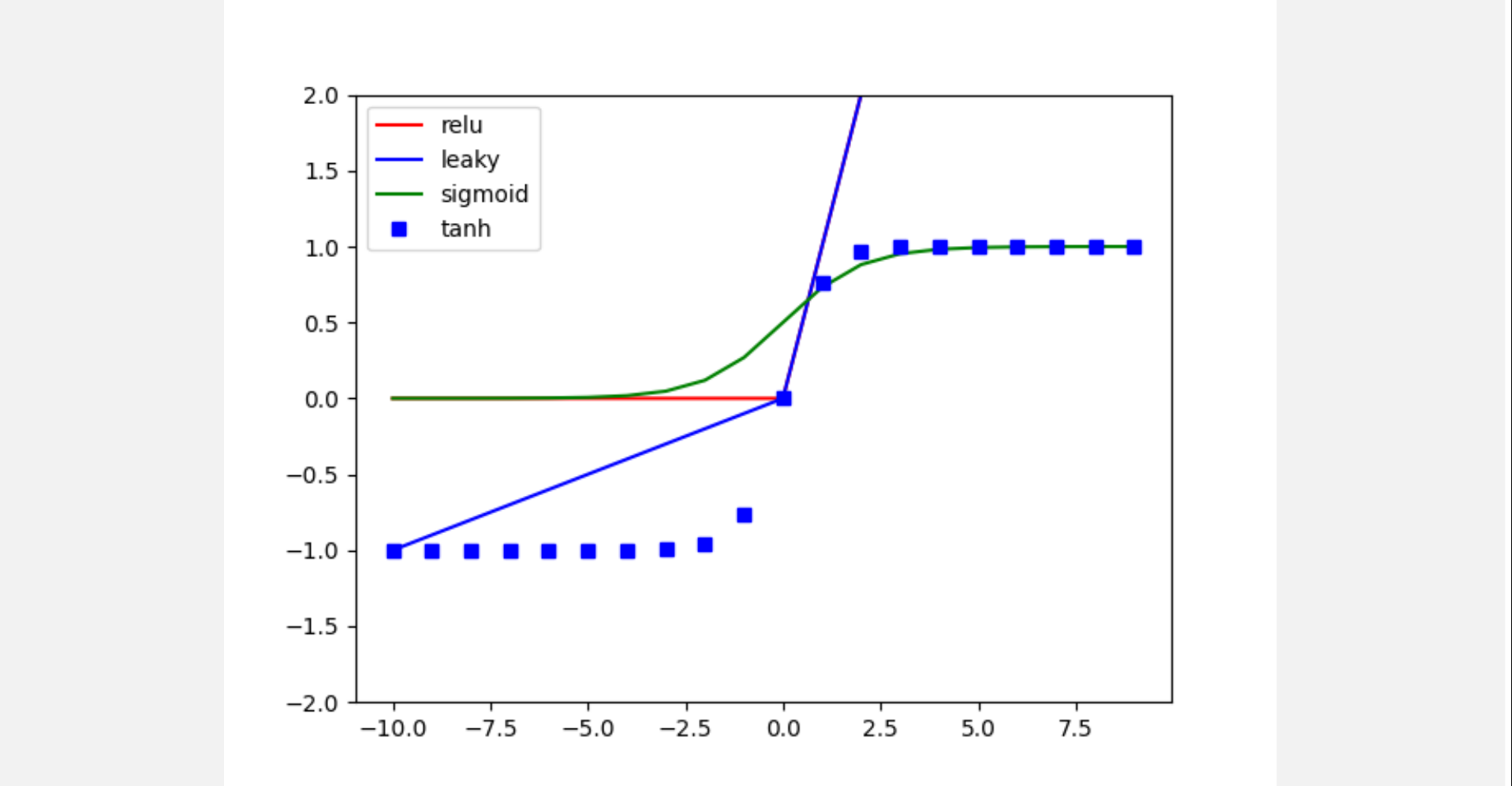
1. Activation
def relu(x):
x_shape = x.shape
x = np.reshape(x, [-1])
x = [max(v, 0) for v in x]
x = np.reshape(x, x_shape)
return x
def leaky_relu(x):
x_shape = x.shape
x = np.reshape(x, [-1])
x = [max(v, v*0.1) for v in x]
x = np.reshape(x, x_shape)
return x
def sigmoid(x):
x_shape = x.shape
x = np.reshape(x, [-1])
x = [1 / (1 + np.exp(-v)) for v in x]
x = np.reshape(x, x_shape)
return x
def tanh(x):
x_shape = x.shape
x = np.reshape(x, [-1])
x = [np.tanh(v) for v in x]
x = np.reshape(x, x_shape)
return x
def plot_activation():
x = np.arange(-10, 10, 1)
out_relu = relu(x)
out_leaky = leaky_relu(x)
out_sigmoid = sigmoid(x)
out_tanh = tanh(x)
plt.plot(x, out_relu, 'r', label='relu')
plt.plot(x, out_leaky, 'b', label='leaky')
plt.plot(x, out_sigmoid, 'g', label='sigmoid')
plt.plot(x, out_tanh, 'bs', label='tanh')
plt.ylim([-2, 2])
plt.legend()
plt.show()
plot_activation()2. Pooling
class Pool:
def __init__(self, batch, in_c, out_c, in_h, in_w, kernel, dilation, stride, padding):
self.batch = batch
self.in_c = in_c
self.out_c = out_c
self.in_h = in_h
self.in_w = in_w
self.kernel = kernel
self.dilation = dilation
self.stride = stride
self.padding = padding
self.out_w = (in_w + padding*2 - kernel) // stride + 1
self.out_h = (in_h + padding*2 - kernel) // stride + 1
def pool(self, A):
B = np.zeros([self.batch, self.out_c, self.out_h, self.out_w], dtype=np.float32)
for b in range(self.batch):
for c in range(self.in_c):
for oh in range(self.out_h):
a_j = oh * self.stride - self.padding
for ow in range(self.out_w):
a_i = ow * self.stride - self.padding
B[b, c, oh, ow] = np.amax(A[b, c, a_j : a_j+self.kernel, a_i : a_i+self.kernel])
return B
Pooling = Pool(batch=batch,
in_c=1,
out_c=1,
in_h=4,
in_w=4,
kernel=2,
dilation=1,
stride=2,
padding=0)
# L1 shape: [1, 1, 4, 4] mat -> L1_MAX shape: [1, 1, 2, 2]
L1_MAX = Pooling.pool(L1)3. Fully-Connected layer
class FC:
# def __init__(self, batch, in_c, out_c, in_h, in_w):
# self.batch = batch
# self.in_c = in_c
# self.out_c = out_c
# self.in_h = in_h
# self.in_w = in_w
def __init__(self, batch):
self.batch = batch
def fc(self, A, W):
# A shape: [b, in_c, in_h, in_w] -> [b, in_c * in_h * in_w]
a_mat = A.reshape([self.batch, -1])
B = np.dot(a_mat, np.transpose(W, (1, 0)))
return B
# L2 shape: [b, 1]
W2 = np.array(np.random.standard_normal([1, L1_MAX.shape[1] * L1_MAX.shape[2] * L1_MAX.shape[3]]), dtype=np.float32)
Fc = FC(batch=L1_MAX.shape[0])
L2 = Fc.fc(L1_MAX, W2)📙구현 코드 GitHub

JUST DO IT.