1. 기계학습
-
경험을 통해 작업의 성능 향상
- Traditional Programming
Input + Program → Computation → Results - Machine Learning
Input + Desired result → Computation → Program
- Traditional Programming
-
예측
- 회귀(regression)
- 분류(classification)
-
목표
training set을 활용하여 주어진 문제에서 최적의 성능을 도출하는 매개변수를 찾는다. training set에 없는 새로운 데이터에 대한 오류를 최소화하기 위해 generalization이 잘 되어야 한다. -
차원의 저주
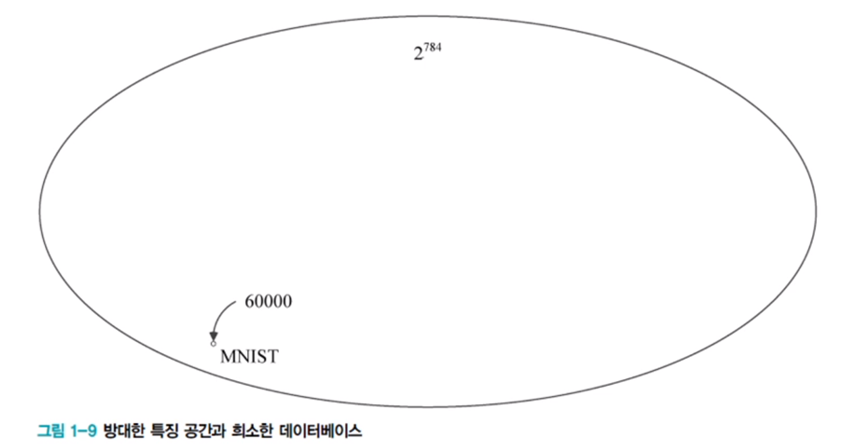
차원이 커짐에 따라 공간이 커지고, 공간 내 데이터의 밀도가 급격히 감소한다. 공간 내 모든 경우를 다 채우려면 지수적으로 더 많은 데이터가 필요하다. 그러나 고차원의 데이터는 관련된 낮은 차원의 manifold에 가깝게 집중되어 있다. -
특징 공간 변환과 표현 문제(represetation)
- 특징 공간 변환

기존 특징 공간에 적절한 변환을 적용하면 데이터를 쉽게 선형으로 분류할 수 있다. representation learning은 좋은 특징 공간을 자동으로 찾는 작업이다. - 표현 학습
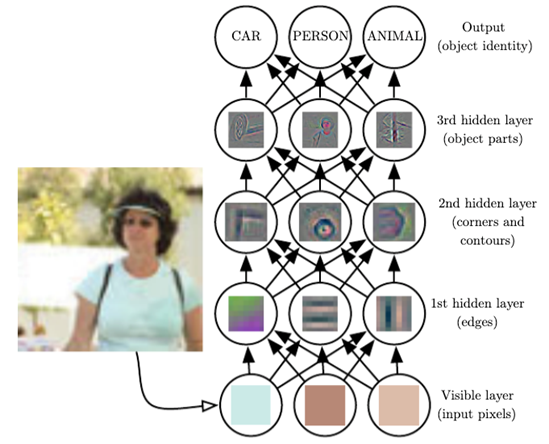
딥러닝은 표현 학습의 하나로 다수의 은닉층을 가진 신경망을 이용하여 최적의 계층적인 특징을 학습한다. 머신러닝과 딥러닝의 주요 차이는 feature 추출에서 사람의 개입 여부에 있다.
- 특징 공간 변환
-
Cost function
- 단순 회귀에서는 MSE(Mean Squared Error)를 사용한다.
- cost function을 task에 맞게 적절히 설정하여 cost를 최소화하도록 매개변수를 최적화해야 한다.
-
과소적합과 과대적합
- 편향과 분산
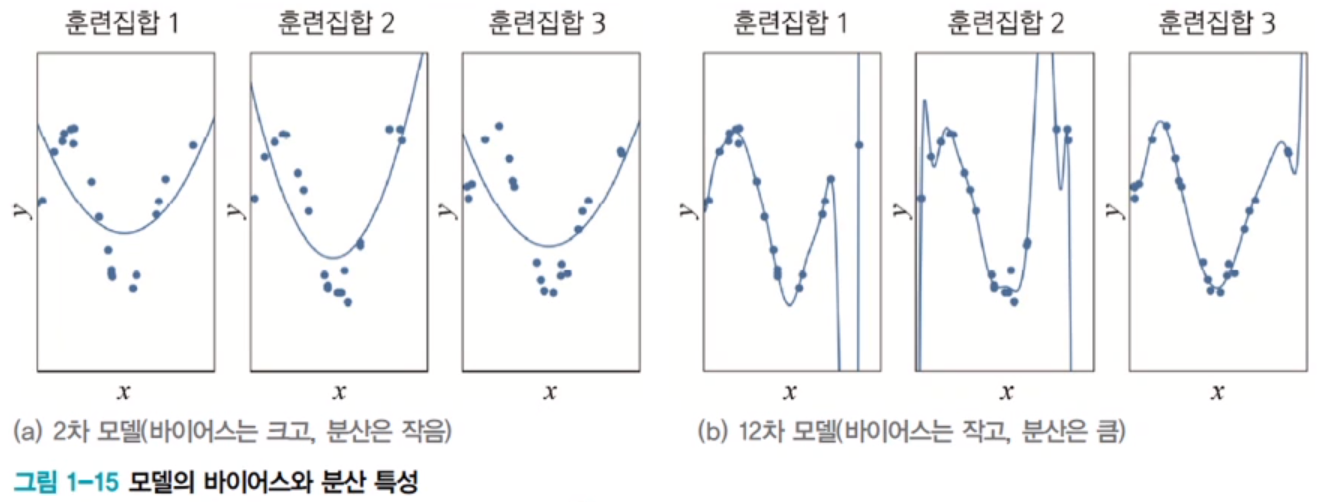
- 과소적합
모델이 너무 단순하여 훈련 데이터에 적절히 적응하지 못하고 성능이 낮은 상태 - 과대적합
모델이 훈련 데이터에 지나치게 적응하여 새로운 데이터에 대한 일반화 성능이 떨어지는 상태 - 모델의 하이퍼파라미터를 튜닝하며 일반화 성능을 평가하기 위해 데이터를 Train, Validation, Test set으로 나누어 모델을 개발한다. cross validation을 활용할 수도 있다.
- 현대 기계 학습의 전략
충분히 큰 모델을 선택한 후, 모델이 정상을 벗어나지 않도록 여러 regularization을 적용한다.
- 편향과 분산
-
generalization 능력 향상(regularization)
- 더 많은 데이터를 확보(추가 수집, data augmentation 등)
- Weight decay(L1, L2, Elastic 등)
- Dropout
- Batch normalization
- Early stopping
2. 다층 퍼셉트론
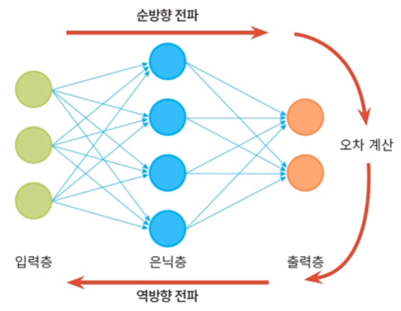
-
신경망의 종류
- 결정론(deterministic) 신경망
모델의 매개변수와 조건에 의해 출력이 완전히 결정되는 신경망 - 확률론적(stochastic) 신경망
고유의 임의성을 가지고 매개변수와 조건이 같더라도 다른 출력을 가지는 신경망
- 결정론(deterministic) 신경망
-
퍼셉트론의 동작
- 선형 연산 → 비선형 연산
입력값과 가중치를 내적한 값에 활성화 함수를 적용한다.
- 선형 연산 → 비선형 연산
-
bias term 사용 이점
식을 0으로 보내서 활성화 함수의 을 threshold로 활용할 수 있게 된다. -
일반적인 분류기의 학습 과정
① 과업 정의와 분류 과정의 수학적 정의(가설 또는 모델 설정)
② 해당 분류기의 비용 함수 정의- 퍼셉트론 비용 함수의 상세 조건
- 가 최적이면, 즉 모든 샘플을 맞히면 이다.
- 틀리는 샘플이 많은 일수록 는 큰 값을 가진다.
③ 를 최소화하는 를 찾기 위한 최적화 방법 수행
- 최적화에는 보통 gradient descent 방법을 사용한다. 의 편미분값을 이용하여 을 찾으며, 이때 learning rate로 그 속도(또는 스텝)을 조절할 수 있다.
- 퍼셉트론 비용 함수의 상세 조건
-
활성화 함수(activation function)
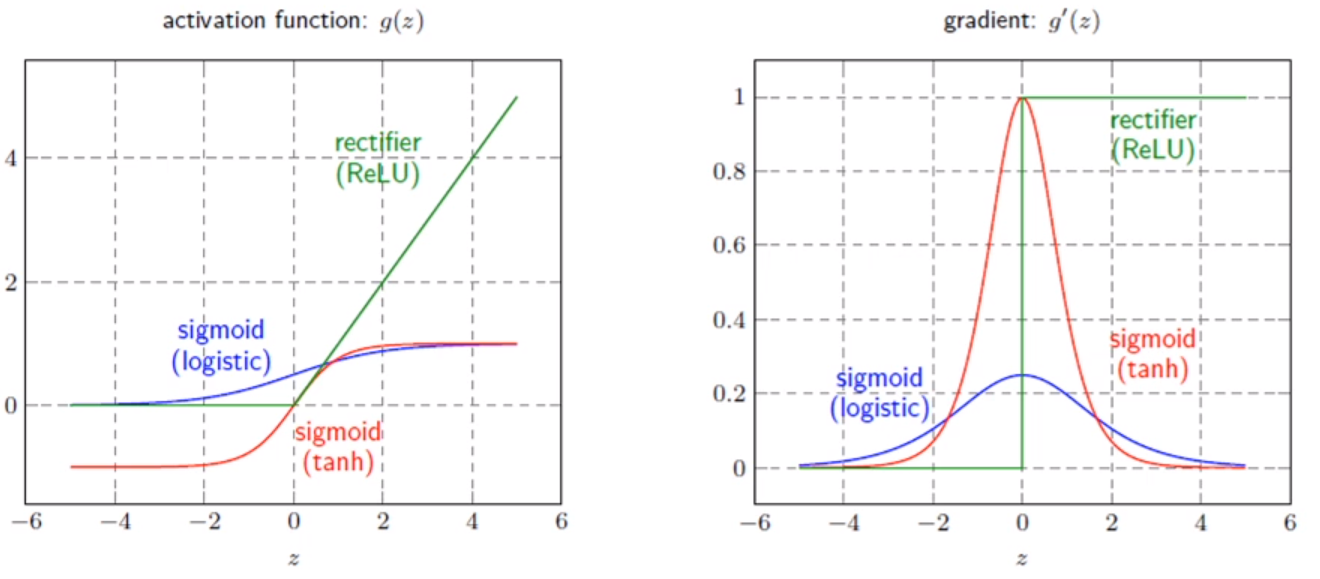
- ReLU를 사용하는 이유(특히 깊은 신경망에서)
- 비선형성
- 계산 효율성
- Gradient Vanishing 문제 완화
- Sparsity 유도: 특정 입력을 가지는 특정 뉴런을 비활성화하여 모델의 일반화 성능을 향상
- ReLU를 사용하는 이유(특히 깊은 신경망에서)
-
은닉층(hidden layer)
- 특정 벡터를 분류에 더 유리한 새로운 특징 공간으로 변환
- 일반적으로 넓은 구조보다는 깊은 구조가 좋은 성능을 가진다.
-
신경망 개발에 중요한 경험적 요소
- 아키텍처
- 초깃값
- 학습률
- 활성화 함수
- 등...

JUST DO IT.