경희대학교 황효석 교수님의 2021-2 로봇 프로그래밍 수업을 듣고 공부한 것입니다.
Map
로봇의 map 이란 landmark 들의 집합이다.
Filter Cycle
- State Prediction
- Measurement Prediction
- Measurement
- Data association
- Update
Definition of the SLAM Problem

Extended Kalman Filter Algorithm

2,3 : Prediction Step
- mean 은 그냥 mean 값을 더해 줌으로써 구한다. (스칼라)
- Covariance 의 경우, 앞에 곱해지는 Transition Matrix 가 선형성을 가지게 하기 위해서, non-linear 한 function 에 Talyor Series Expansion 을 구해서 1차 미분값까지를 사용한다.
4 : Update Step
EKF SLAM
- Application of the EKF to SLAM
- Estimate robot's pose and locations of landmarks in the environment
- Assumption : known correspondences
known correspondences
Correspondence : 어떤 것을 보았을 때, 이거를 예전에 봤던 건지 아니면 완전 처음 보는 건지 어떻게 판단할까?
Data Association : 이게 내가 예전에 봤던 어떤 것이랑 동일한 것인가? 어떻게 매칭할 것인가?
이런 문제는 주로 Computer Vision 의 Feature Matching 이나 3D point cloud 의 Registration 등으로 해결한다.
-> correspondence 를 EKF SLAM 에서는 원래 알고 있다고 가정한다.
State
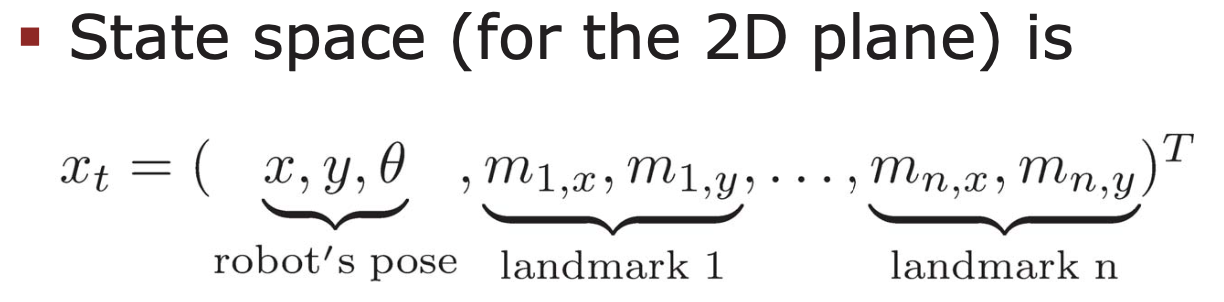
state 는 로봇의 pose 와 랜드마크들의 정보를 모두 포함하고 있다.
따라서 이를 3 + 2N 의 길이를 가진 벡터로 표현할 수 있다.

노란색 : pose 끼리의 covariance
초록색 : pose 와 landmark 간의 covariance
파란색 : landmark 끼리의 covariance
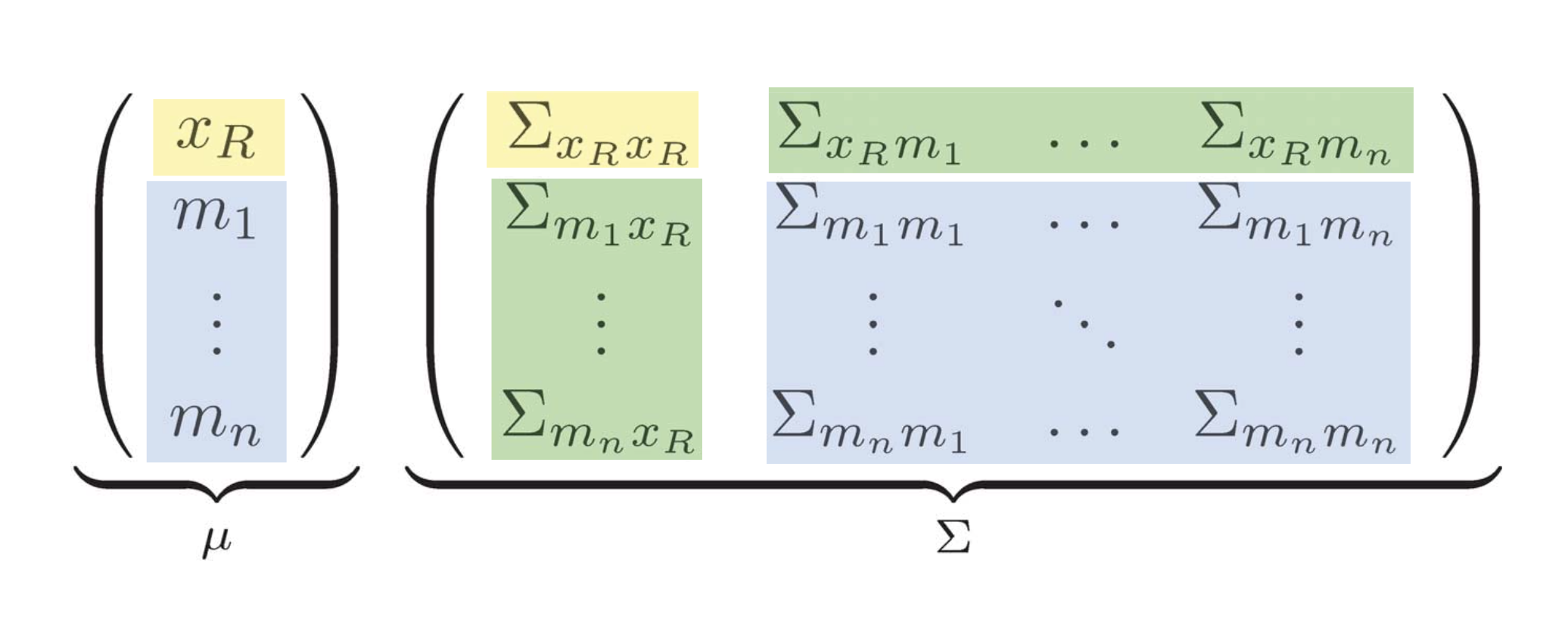
Map : 랜드마크들의 집합.
state = robot pose + landmarks
EKF SLAM : Filter Cycle
- State Prediction
- Measurement Prediction
- Measurement
- Data Association
- Update
1. State Prediction
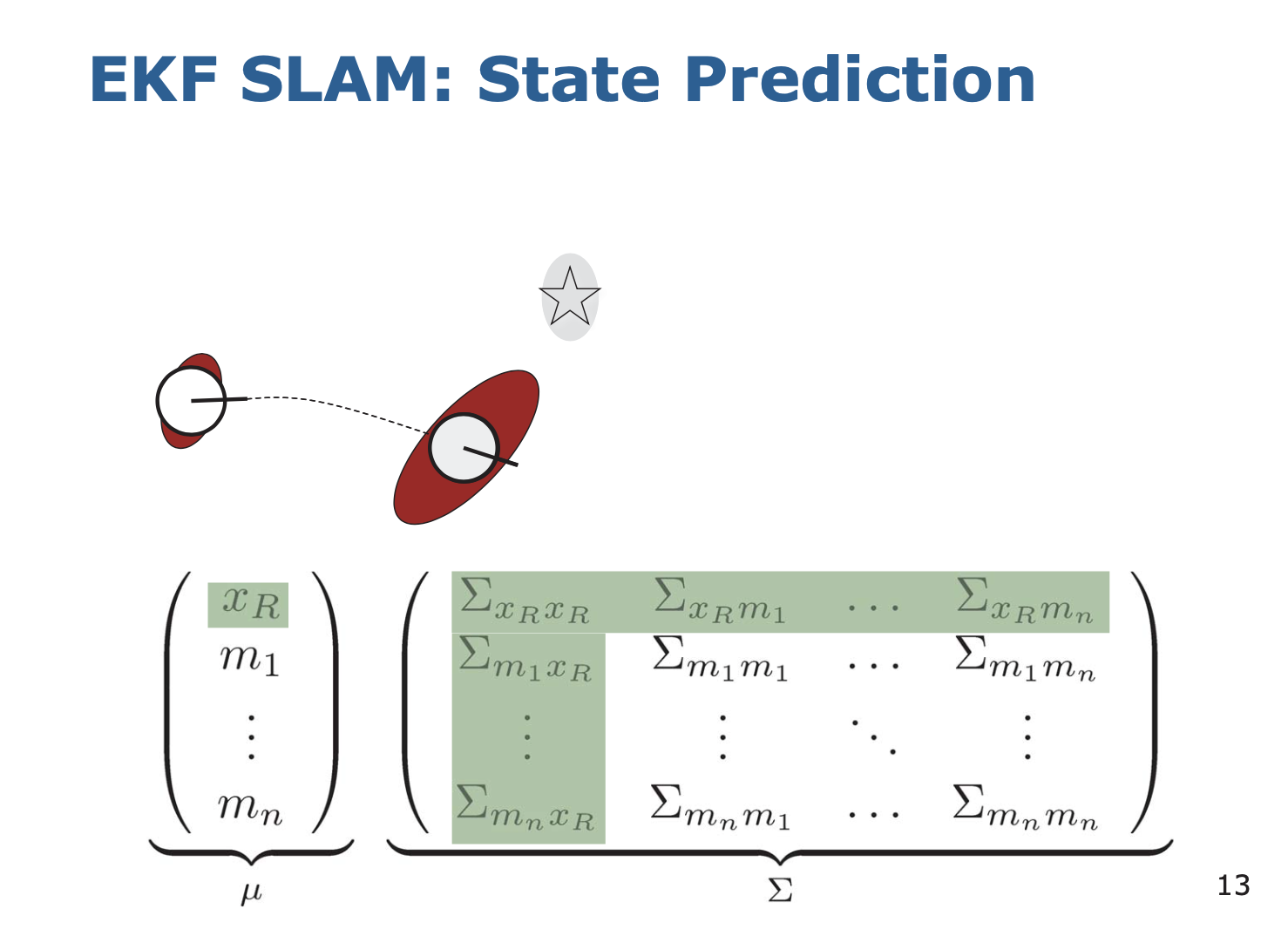
이전의 state 와, 이전 state 에서 현재 state 로 올 때 까지의 control 을 가지고
현재 state 를 Predict 한다.
1) 먼저 로봇의 pose (얼만큼 돌아갔고 얼만큼 이동했나?) 를 계산한다.
2) Covariance 에서 pose 와 관련된 것은 전부 계산한다.
2. Measurement Prediction
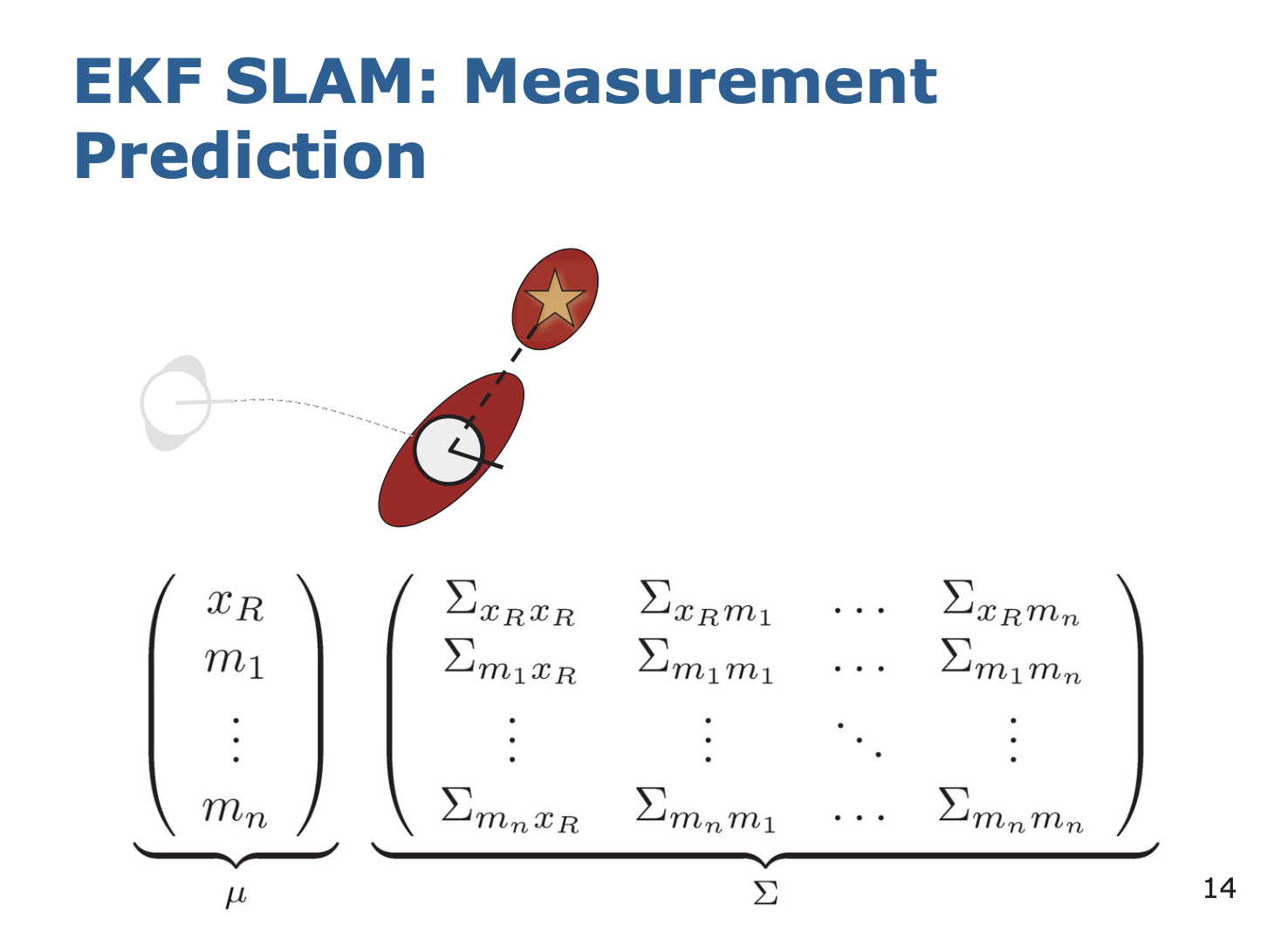
내가 자리를 옮겼으니까, 랜드마크도 옮겨지게 관측된 것과 비교해보니 이쯤에 있을 것이다- 라고 예측을 해보는 것이다.
3. Measurement
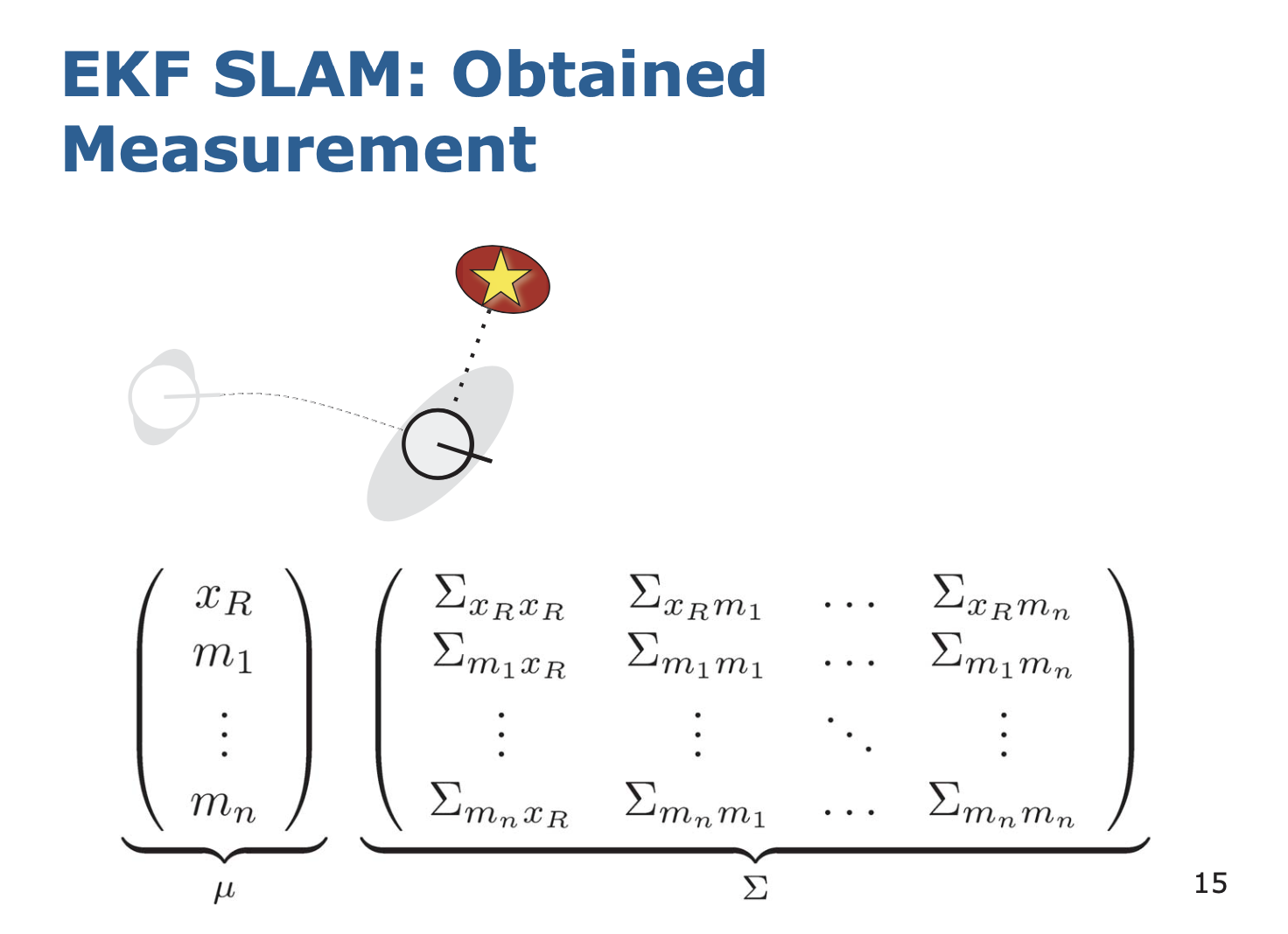
그런데 실제 관측해보니 쪼금 다른 곳에 있는 것이었다.
내가 예측한 위치의 랜드마크와 실제 관측된 위치의 랜드마크를 어떻게 다룰 것인가?
-> 확률분포를 서로 곱하면 된다.
4. Data Association
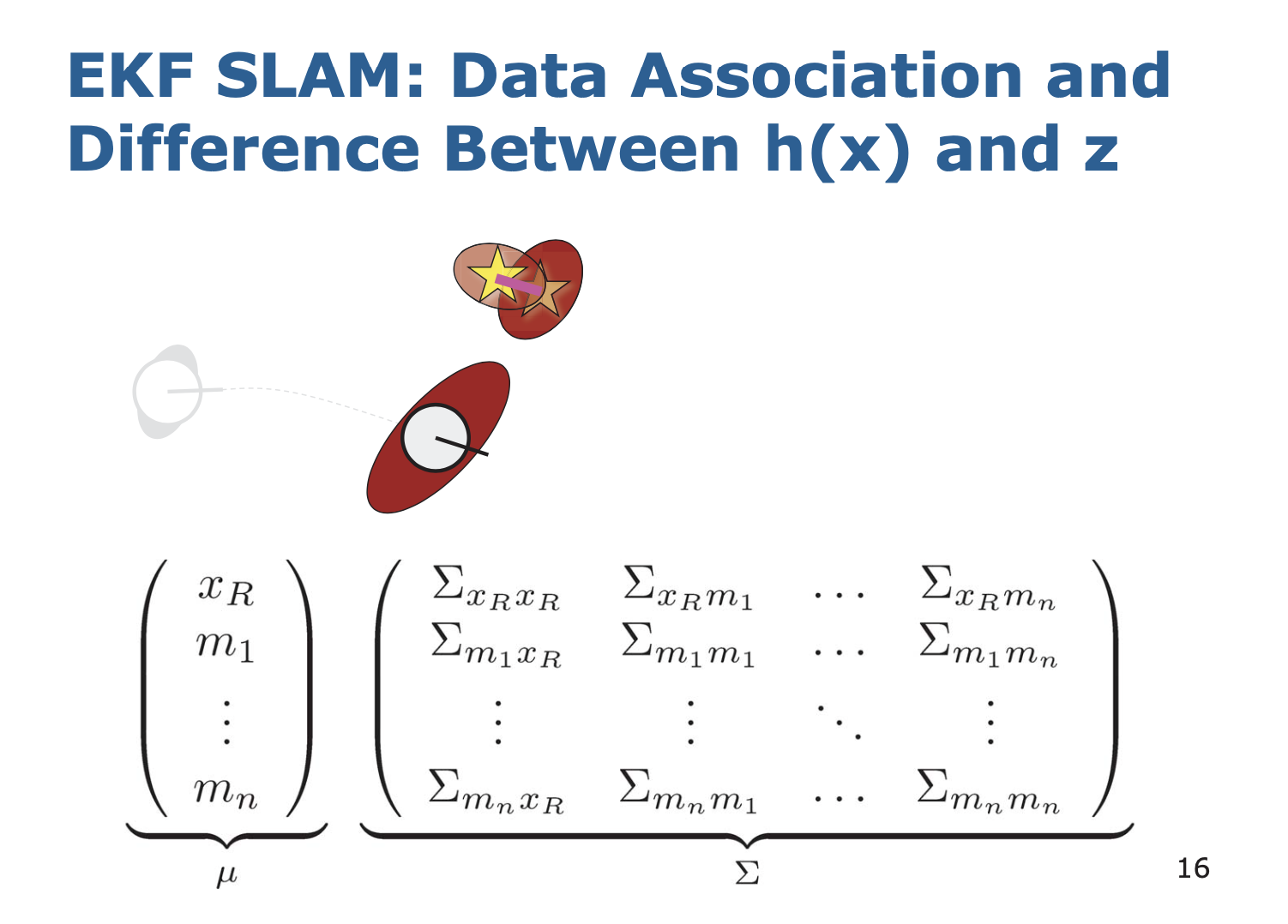
5. Update
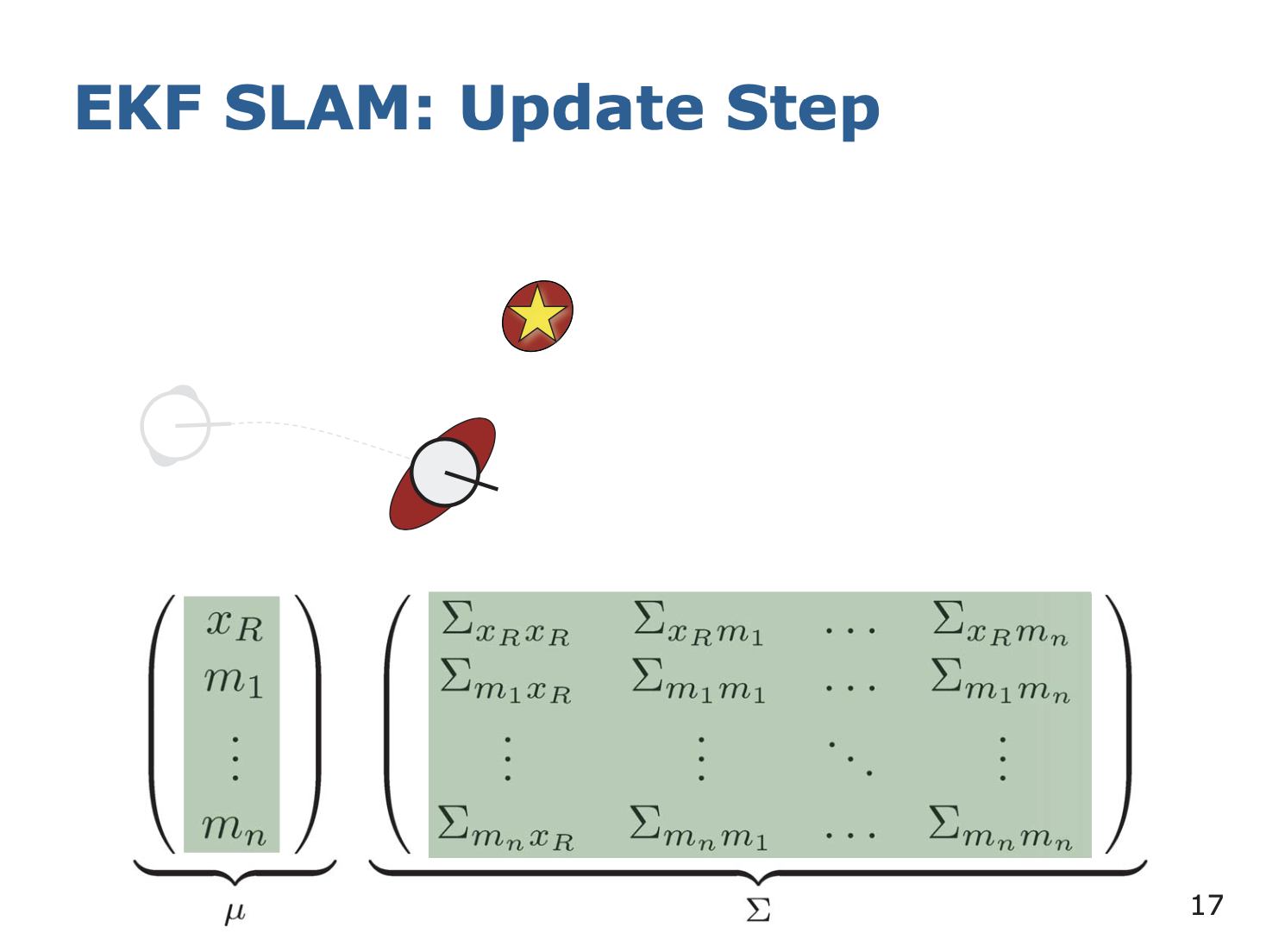
최종적으로 하나의 평균과 covariance 로 나타내지는 랜드마크를 정하는 것이다. 이렇게 함으로써 자신의 pose 의 covariance 도 줄인다.
Concrete Example
2차원 평면에서 움직이는 로봇을 가정해 보자.
초기화 Initialization
Robot starts its own reference frame : All landmarks unknown
