Pytorch 건드려보기: Pytorch로 하는 linear regression
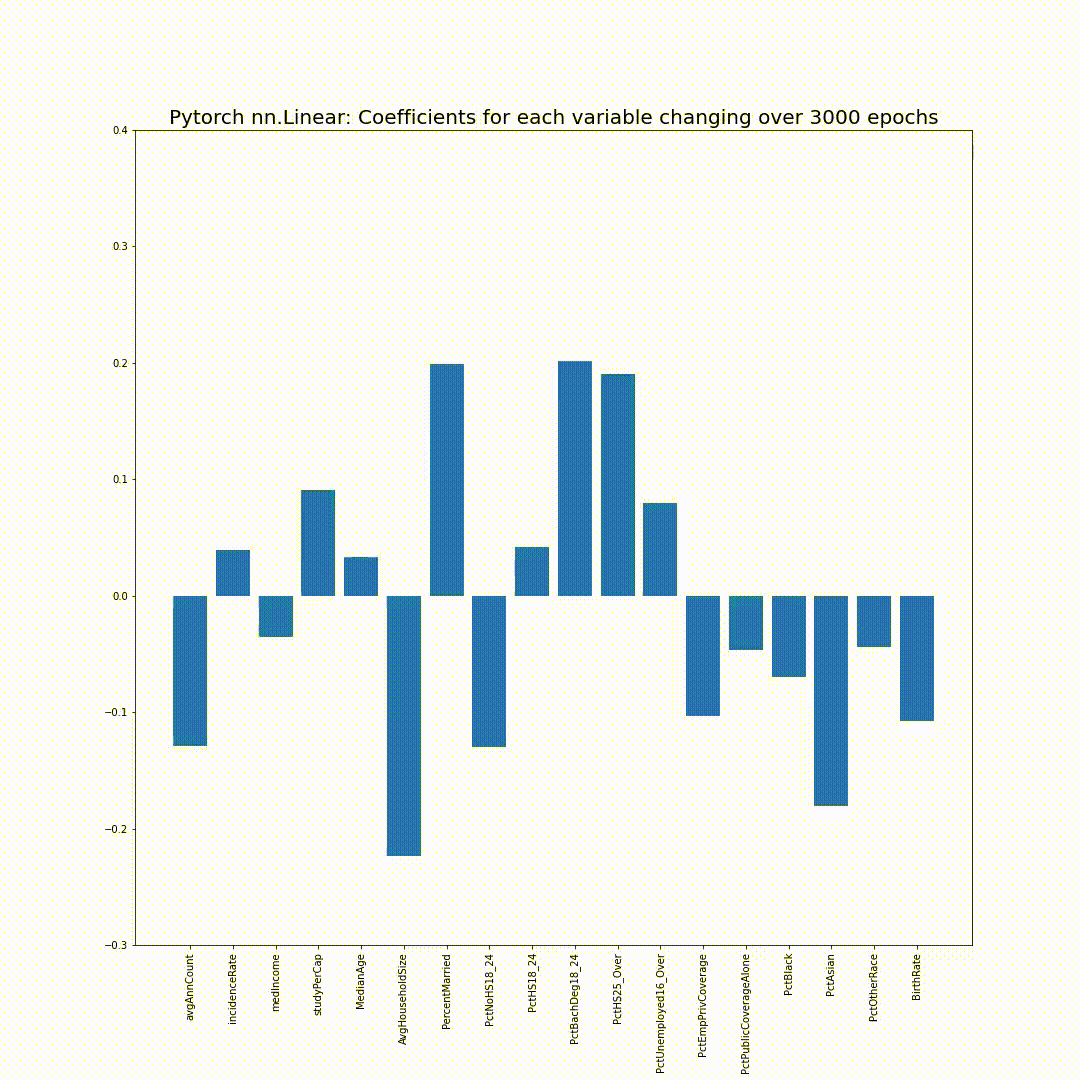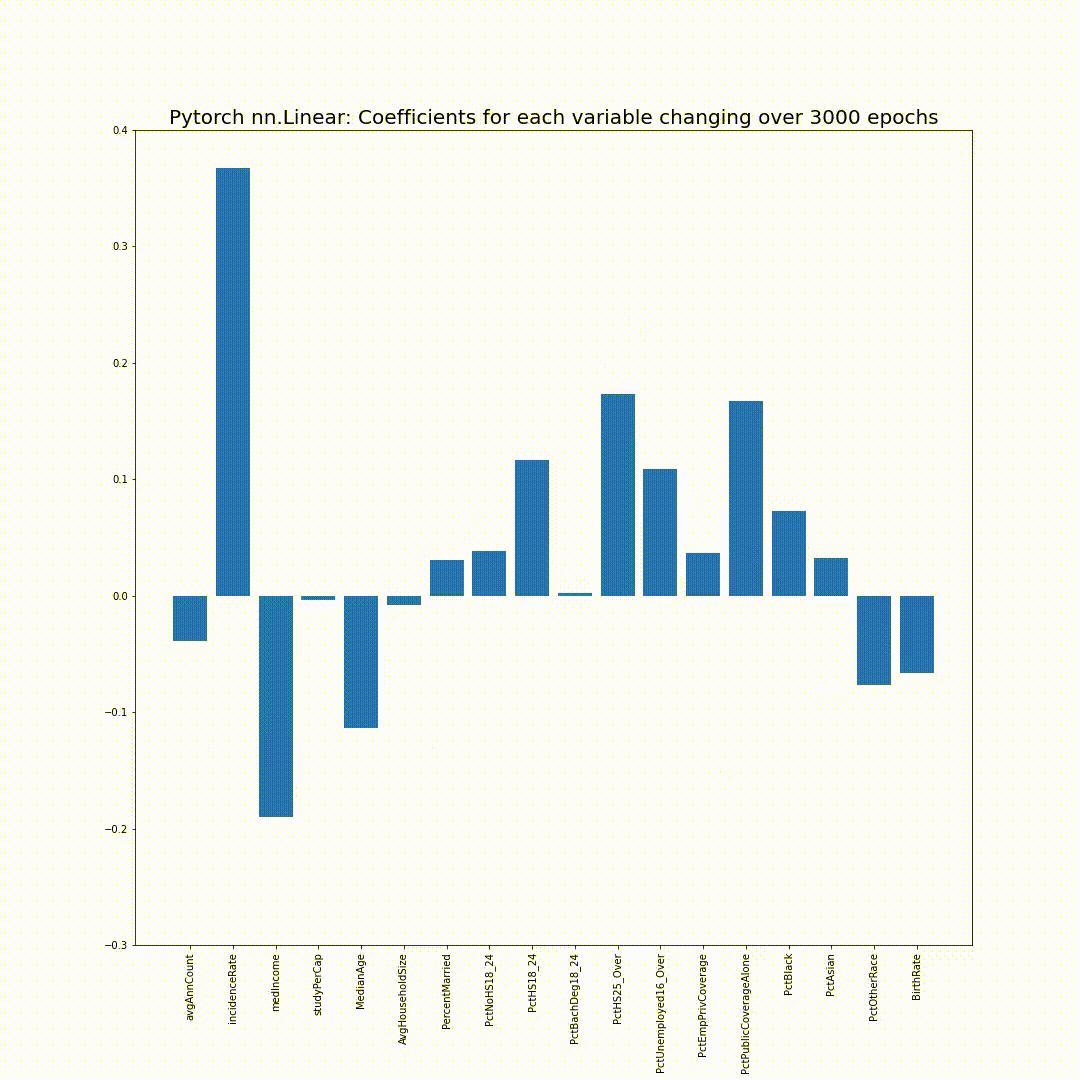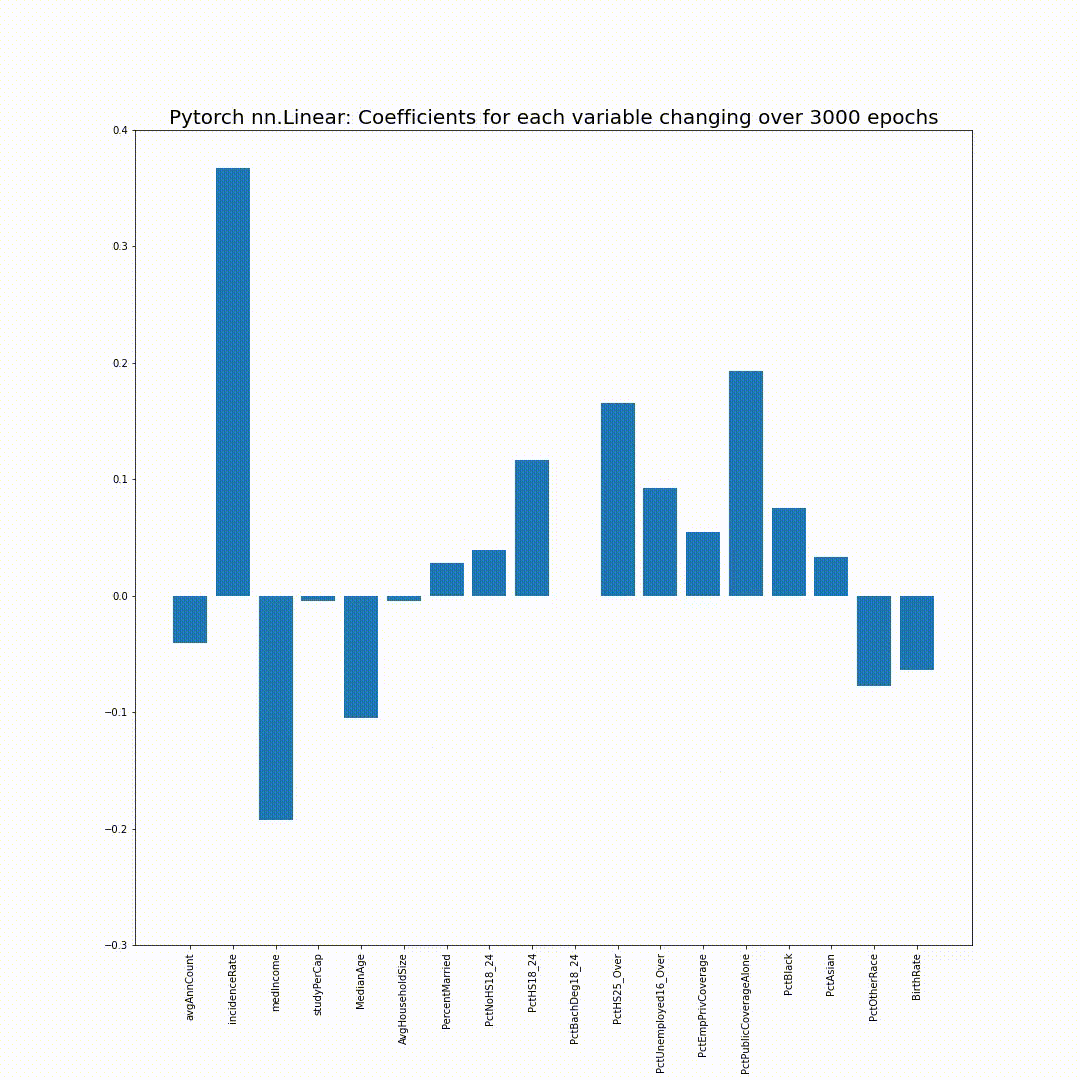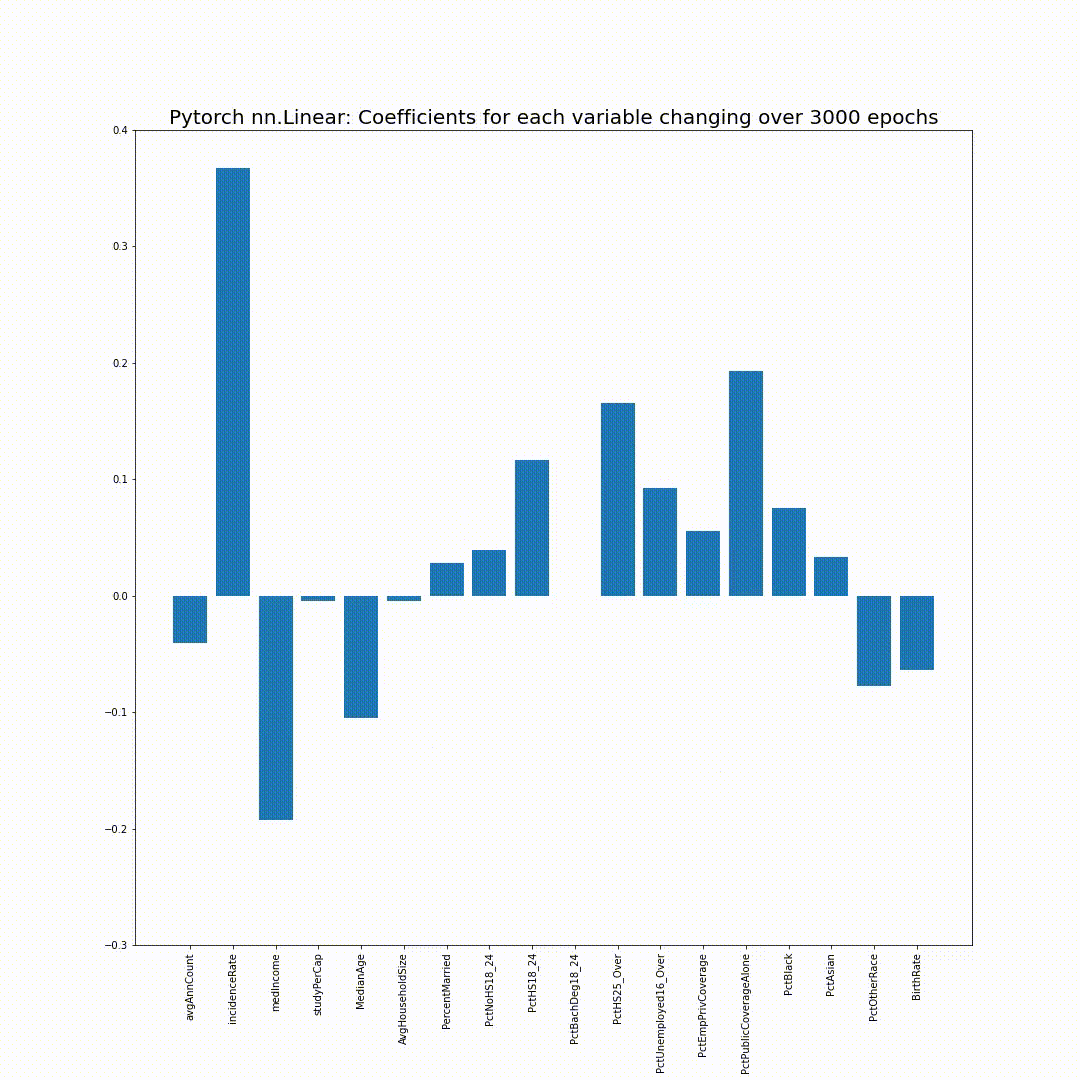 Coefficients of a Linear Regression model changing over 3000 epochs
Coefficients of a Linear Regression model changing over 3000 epochs
Pytorch 쓰는 법을 처음 배웠습니다. 복잡한 neural network도 구현할 수 있게 해주는 파워풀한 라이브러리이지만, 우선은 pytorch의 기본적인 요소들과 친해지기 위해 심플함의 왕인 linear regression을 pytorch로 흉내내보는 것이 이 글의 목표입니다 (mnist조차도 벅차서 더 쉬운 것을 해보고자 했습니다).
우선 Linear regression 복습.
Linear regression은 수식으로 나타내면 이런 형태죠:
주어진 를 가지고 를 가장 잘 예측할 수 있는 와 를 찾는 것이 linear regression의 목표입니다. 주어진 가 여러 개일 땐 multiple regression이라고 부르기도 하며 수식으로 나타내면 이런 형태죠:
한 번은 익숙한 sklearn으로, 그 다음엔 익숙치 않은 pytorch로 각각 linear regression모델을 만들어보도록 하겠습니다. Sklearn은 LinearRegressor를 이용할테니 sum of squared error를 최소화 하는 방법으로 바로 모델의 coefficient들을 찾게 될거고, pytorch는 독립변수의 갯수만큼의 node를 가지고 있는 Linear 레이어를 하나만 이용해서 각 노드의 weight(즉 model의 coefficient)를 Adam을 이용해 트레이닝시켜보려 합니다.
우선 사용할 데이터셋을 소개하겠습니다. 미국의 county지역별로 인구통계학적 지표들(연령, 중위 소득, 평균 가구원수, 인종 등)과 암에 의한 사망률(cancer mortality)을 정리해놓은 데이터셋입니다:
OLS Regression Challenge - dataset by nrippner | data.world
우리의 목표는 다른 변수들을 이용해서 TARGET_deathRate (100,000명 당 암 사망률)을 예측하는 linear regression 모델을 만드는 것입니다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv("cancer_reg.csv", encoding="ISO-8859-1")데이터 cleaning과 전처리는 대충만 했습니다 (missing value있는 column들과 multicollinearity보이는 column들, 분석에 필요없는 column들을 지우고, 중위 연령이 100 이상인 row들은 분명 데이터 오류기 때문에 지웠습니다):
df = pd.read_csv('cancer_reg.csv', encoding='ISO-8859-1')
#필요 없는 column들 지우기
df_main = df.drop(['avgDeathsPerYear', 'PctSomeCol18_24', 'PctEmployed16_Over', 'PctPrivateCoverageAlone', 'binnedInc', 'Geography', 'MedianAgeMale','MedianAgeFemale', 'PctPublicCoverage', 'PctPrivateCoverage', 'PctMarriedHouseholds', 'popEst2015', 'povertyPercent', 'PctWhite', 'PctBachDeg25_Over'])
#지역 중위 연령이 100이상인 row들 지우기
df_main = df_main.loc[df_main["MedianAge"]<100]우선 sklearn라이브러리로 linear regression 모델을 만들어보겠습니다. Sklearn의 LinearRegression은 sum of squares error를 최소화 하여 모델을 생성합니다.
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
X = df_main.drop(['TARGET_deathRate'], axis=1)
y = df_main['TARGET_deathRate']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state=1)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
y_train = np.asarray(y_train)
y_test = np.asarray(y_test)
y_train = scaler.fit_transform(y_train.reshape(-1, 1))
y_test = scaler.transform(y_test.reshape(-1, 1))
regr = LinearRegression()
regr.fit(X_train, y_train)
print("Training error: ", mean_squared_error(y_train, regr.predict(X_train)))
print("Test error: ", mean_squared_error(y_test, regr.predict(X_test)))
print(regr.coef_)
print(regr.intercept_)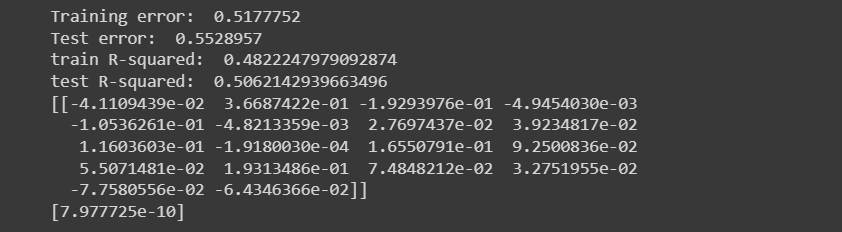
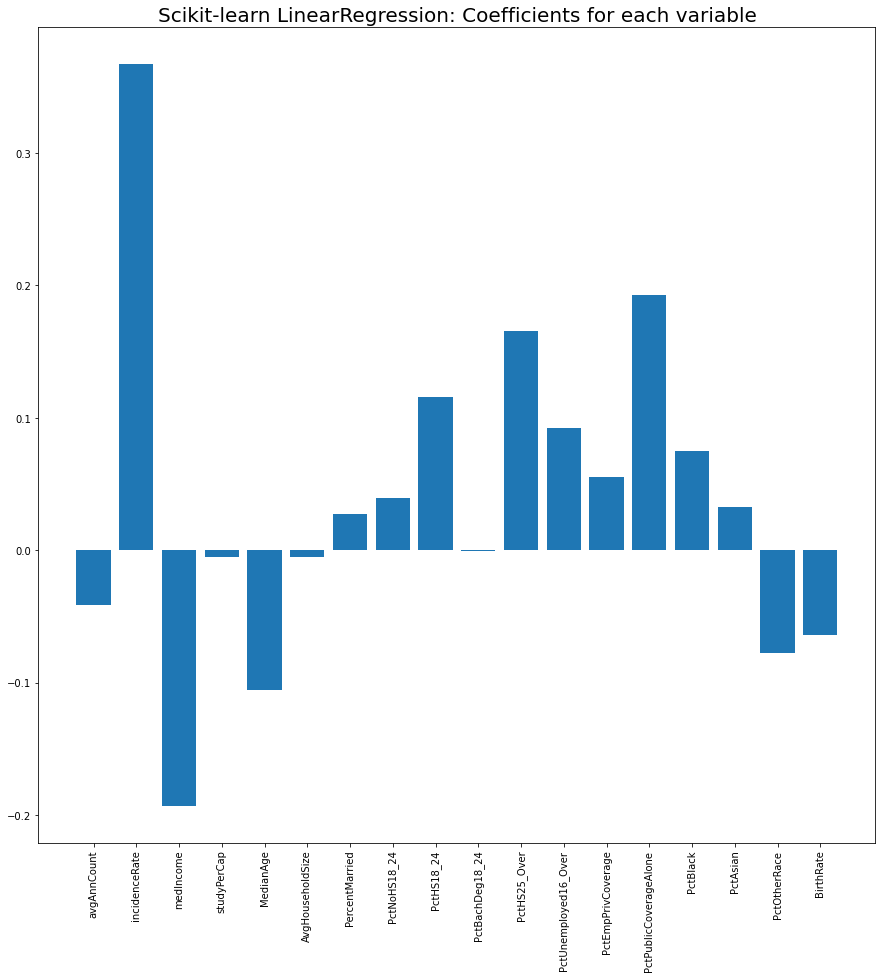
이렇게 각 변수에 대한 계수들과, y절편을 구할 수 있었습니다.
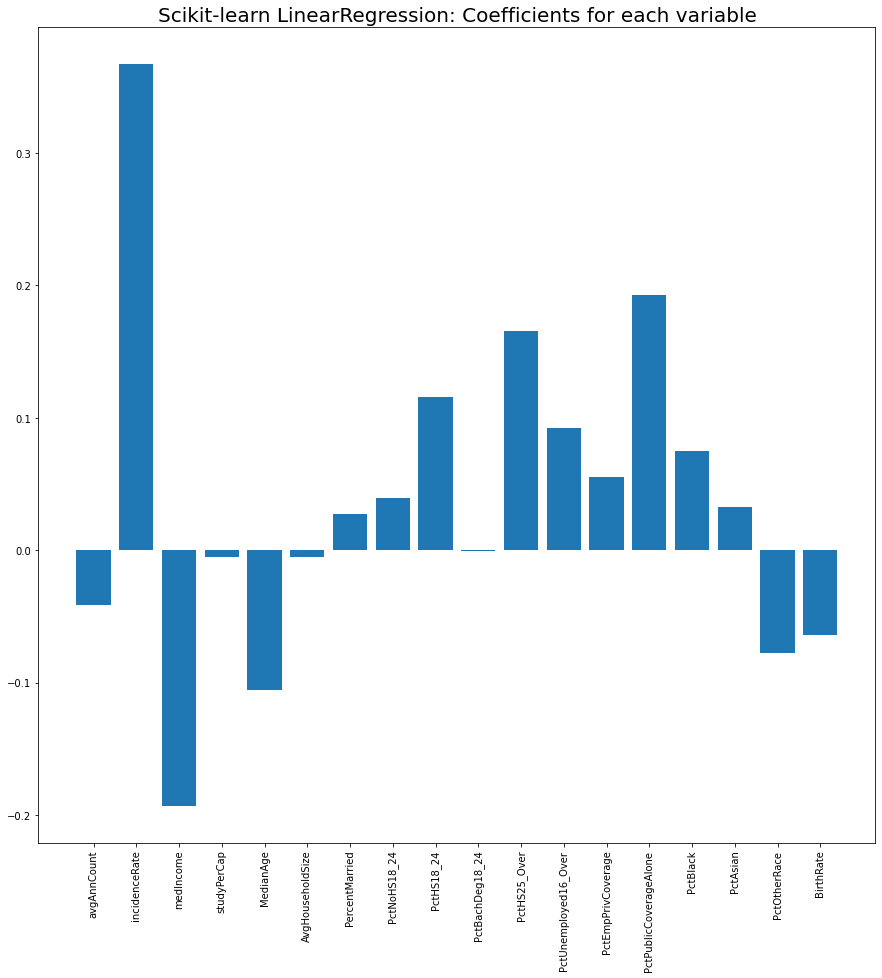
각 변수의 계수를 barplot으로 보면 incidenceRate (암의 발생률)이 암사망률에 가장 큰 영향을 주는게 보이네요 (당연한 결과지만 말이 되는 모델이라는 안심을 줍니다). 그 다음으로는 medianIncome과 PctPublicCoverageAlone인 것 같은데 중위소득(medianIncome)은 암사망률과 음의 상관관계를 가지고, 공공보험만 가지고 있는 사람들의 비율 (즉, 사보험이 없고 medicare나 medicaid만으로 의료보험을 받는 사람들의 비율)은 암사망률과 양의 상관관계를 가집니다. 돈이 암사망률과 꽤 연관성이 있다는게 씁쓸하지만서도 (미국 데이터라 더 그렇겠죠), 일반적인 암에 대해선 돈으로 생명을 연장하는 치료를 살 수 있는 시대에 산다는 것을 보여주는 것 같습니다 (돈이 아무리 많아도 그런 치료를 살 수 없는 병들도 아직 많거든요 - 예를 들어 스티브잡스의 사인인 췌장암).
그러면 이제 pytorch로 같은 모델을 만들 수 있는지 보도록 하겠습니다.
import torch
class DeathRatePredictor(torch.nn.Module):
def __init__(self, input_dimension):
super().__init__()
self.linear = torch.nn.Linear(input_dimension, 1)
def forward(self, input_dimension):
return self.linear(input_dimension)아마도 torch.nn.Module을 이용한 가장 간단한 모델이 아닐까 싶네요. init에서 우리가 만들고자 하는 뉴럴네트워크의 layer들을 명시해줍니다. 이 예시에선 Linear layer하나만 있습니다. Linear layer는 들어오는 input에 대해 linear transformation, 즉 만 하는 layer입니다. super().__init__()은 해당 class(즉 DeathRatePredictor)의 상위 class (즉 nn.Module)의 method들을 가지고 온다는 뜻입니다.
그리고 forward는 init에 명시되어있는 layer들을 바탕으로 실제로 input에 대한 계산(computation)을 진행해서 output을 출력하는 function입니다.
그 다음은 DeathRatePredictor를 이용하여 모델을 트레이닝:
X = df_main.drop(['TARGET_deathRate'], axis=1)
y = df_main['TARGET_deathRate']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state=1)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
y_train = np.asarray(y_train)
y_test = np.asarray(y_test)
y_train = scaler.fit_transform(y_train.reshape(-1, 1))
y_test = scaler.transform(y_test.reshape(-1, 1))
X_train = torch.from_numpy(X_train.astype(np.float32))
X_test = torch.from_numpy(X_test.astype(np.float32))
y_train = torch.from_numpy(y_train.astype(np.float32))
y_test = torch.from_numpy(y_test.astype(np.float32))
# TRAIN MODEL
input_dimension = X_train.shape[1] #X_train.shape is [2262, 18]
model = DeathRatePredictor(input_dimension)
criterion = torch.nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters())
n_epochs = 3000
train_losses = np.zeros(n_epochs)
test_losses = np.zeros(n_epochs)
epoch_coefs = []
for epoch in range(n_epochs):
optimizer.zero_grad()
outputs = model(X_train)
loss = criterion(outputs, y_train)
loss.backward()
optimizer.step()
outputs_test = model(X_test)
loss_test = criterion(outputs_test, y_test)
# Save loss values and model coefficients from each epoch for plotting later
train_losses[epoch] = loss.item()
test_losses[epoch] = loss_test.item()
epoch_coefs.append(list(next(model.named_parameters()[1][0].detach().numpy()))3000 epoch의 training 후 model의 coefficient들을 다음과 같이 확인해볼 수 있습니다:
next(model.named_parameters())[1][0].detach().numpy()
Sklearn의 LinearRegression과 거의 똑같은 결과가 나온 것을 확인할 수 있습니다!
그리고 epoch_coefs에 저장했던 각 epoch의 model의 coefficient를 bar chart로 plotting해보면, 점점 sklearn의 coefficient들로 만든 bar chart와 같아지는 모습을 볼 수 있습니다:
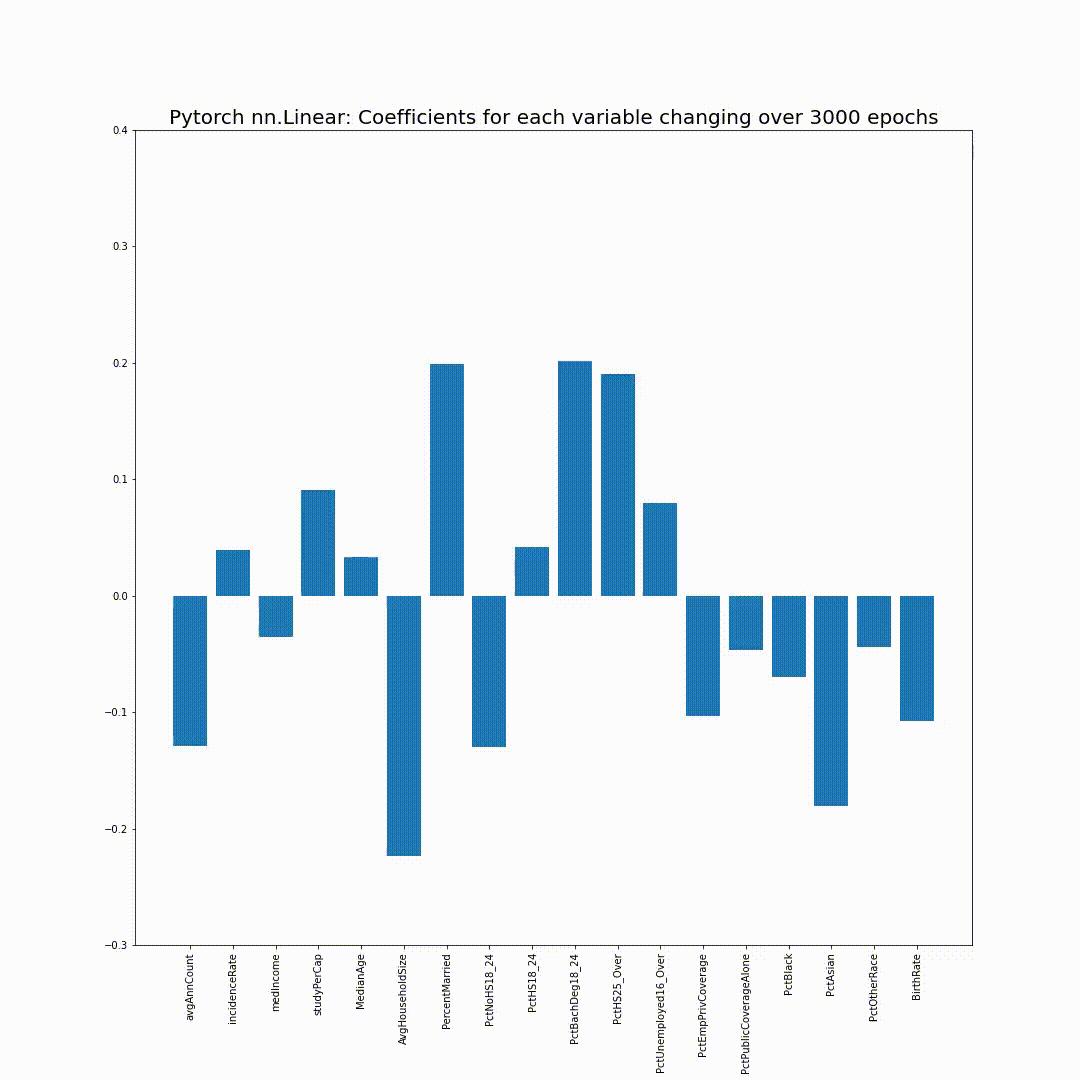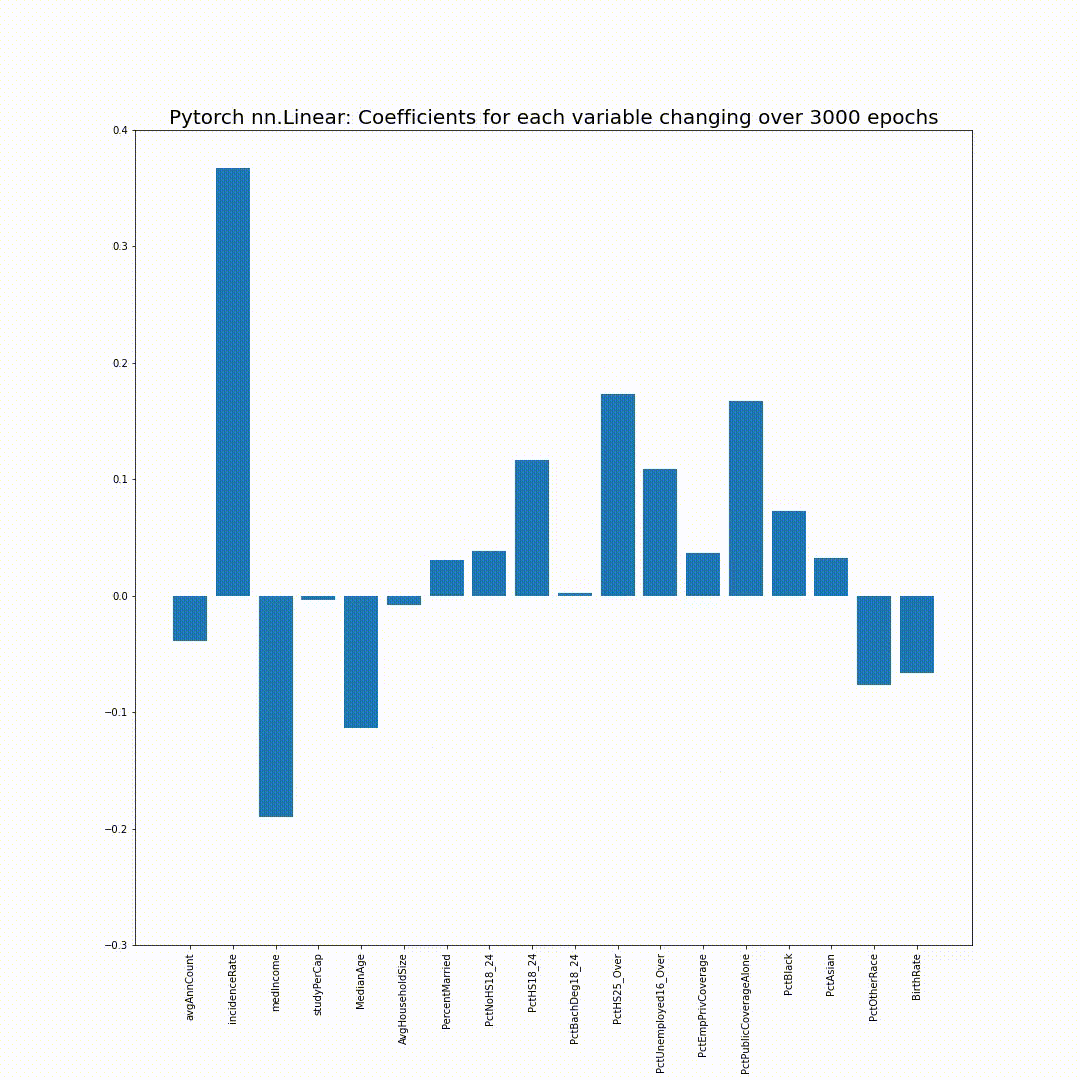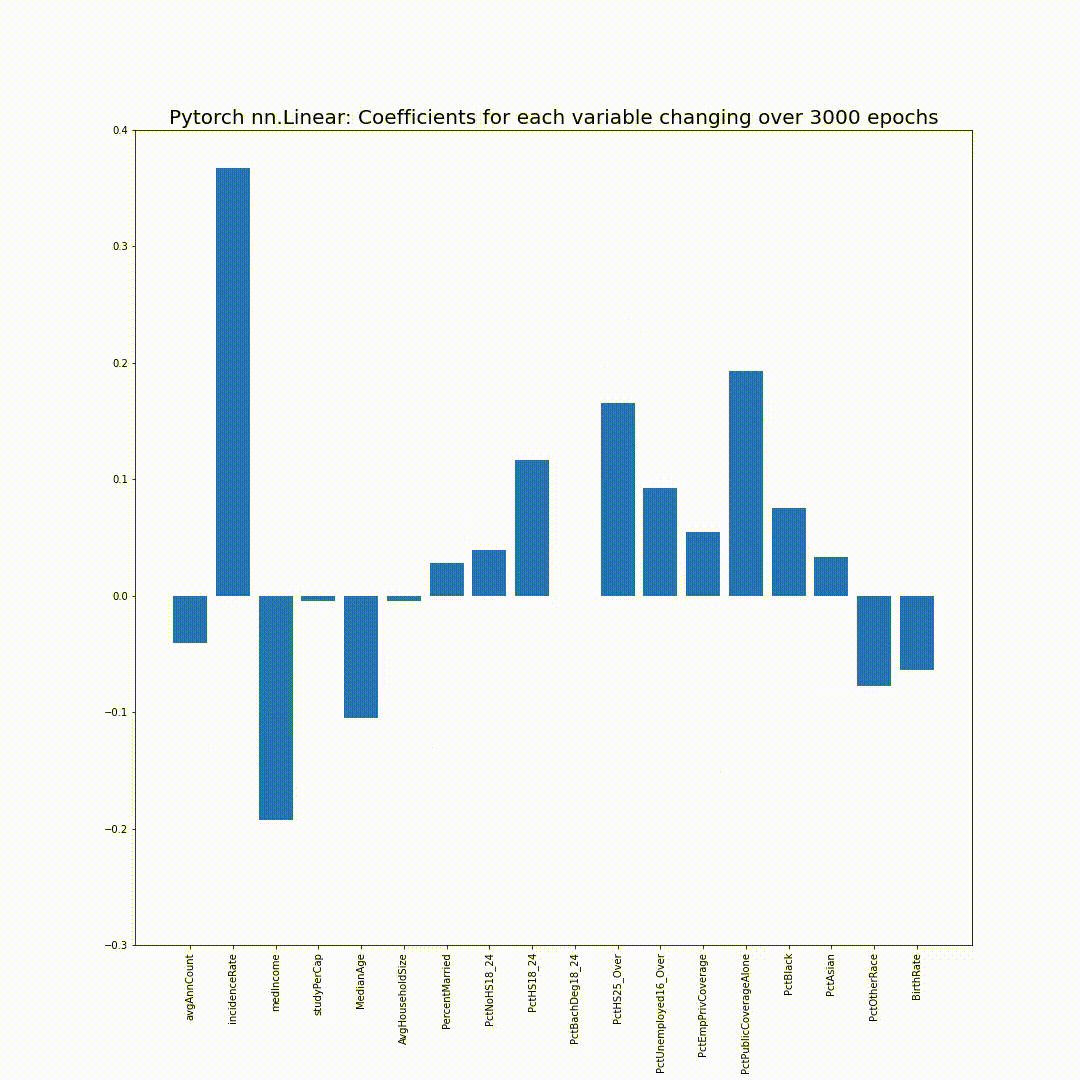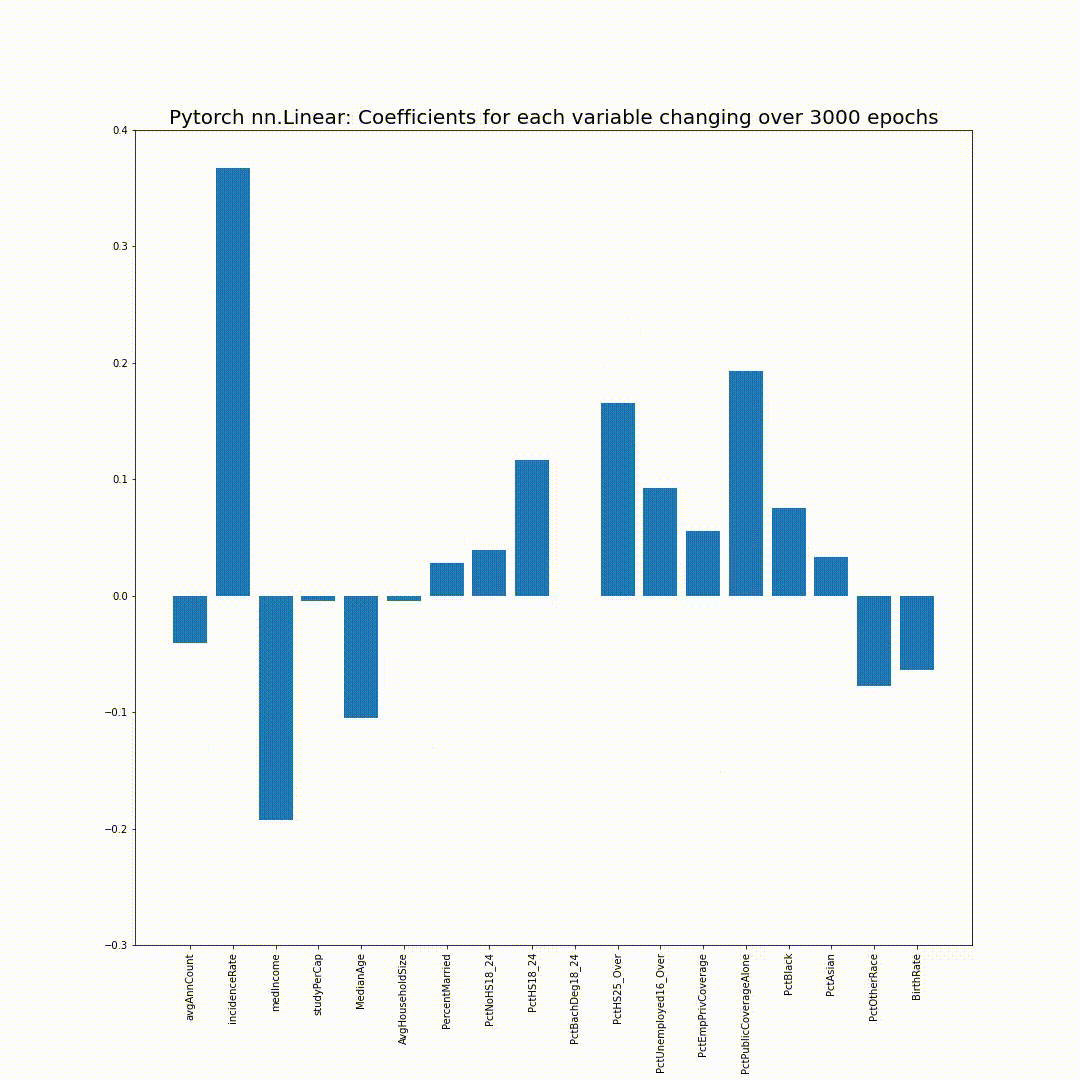
참고용: 위 애니메이션을 위한 코드입니다 (Google Colab에서 실행 시):
from matplotlib import animation
from matplotlib.animation import FuncAnimation
from matplotlib import rc
from IPython.display import HTML
rc('animation', html='jshtml')
%matplotlib inline
epoch_coefs_arr = np.asarray(epoch_coefs)
df_coefs = pd.DataFrame(epoch_coefs_arr)
df_coefs.columns = X.columns
fig = plt.figure(figsize=(15, 15))
ax = fig.add_subplot(1,1,1)
ax.set_ylim(-0.3, 0.4)
def animate(i):
ax.clear()
ax.set_ylim(-0.3, 0.4)
ax.tick_params(axis='x', rotation=90)
ax.set_title("Pytorch nn.Linear: Coefficients for each variable changing over 3000 epochs", fontsize=20)
return ax.bar(df_coefs.columns, [df_coefs[feature][i] for feature in df_coefs.columns])
ani = FuncAnimation(fig, animate, frames = [30*frame for frame in range(100)], interval=30, blit=True)
HTML(ani.to_html5_video())Linear regression을 하는 것조차도 처음 쓰는 도구로 하려다보니 생각보다 어렵고 많이 헤맸습니다. 그래도 이제 Pytorch의 기본개념은 터득한 것 같으니, 다음 주쯤엔 deep learning도 시도해 볼 수 있을 것 같네요!

미국 의료체계 지식까지 활용해서 분석하시니 인사이트가 좋은것 같습니다.
다만, incident rate는 암 발병률이 아니라 진단율로 보는게 맞지 않을까 싶습니다. 올려주신 사이트의 데이터 설명을 봐도 mean per capita cancer diagnosis라고 써있네요 :)
그렇게 되면 (A)암이었지만 암인지 모른 상태로 지내다 사망한 케이스, (B)암이라는 것을 어떠한 계기로든 진단 받아서 알아차린 케이스로 구분이 될 것이고, 예측 정확도와는 크게 상관 없을수도 있지만 분석 측면에서는 더 풍성한 스토리가 만들어질 것 같습니다. 예를 들면, 소득수준과 암 진단의 상관관계도 볼 수 있겠네요.