Ensemble
- 여러 개의 분류기를 생성하고 그 예측을 결합함으로써 보다 정확한 예측을 도출하는 기법
- 강력한 하나의 모델을 사용하는 대신, 보다 약한 모델 여러 개를 조합하여 더 정확한 예측에 도움을 주는 방식
voting vs bagging
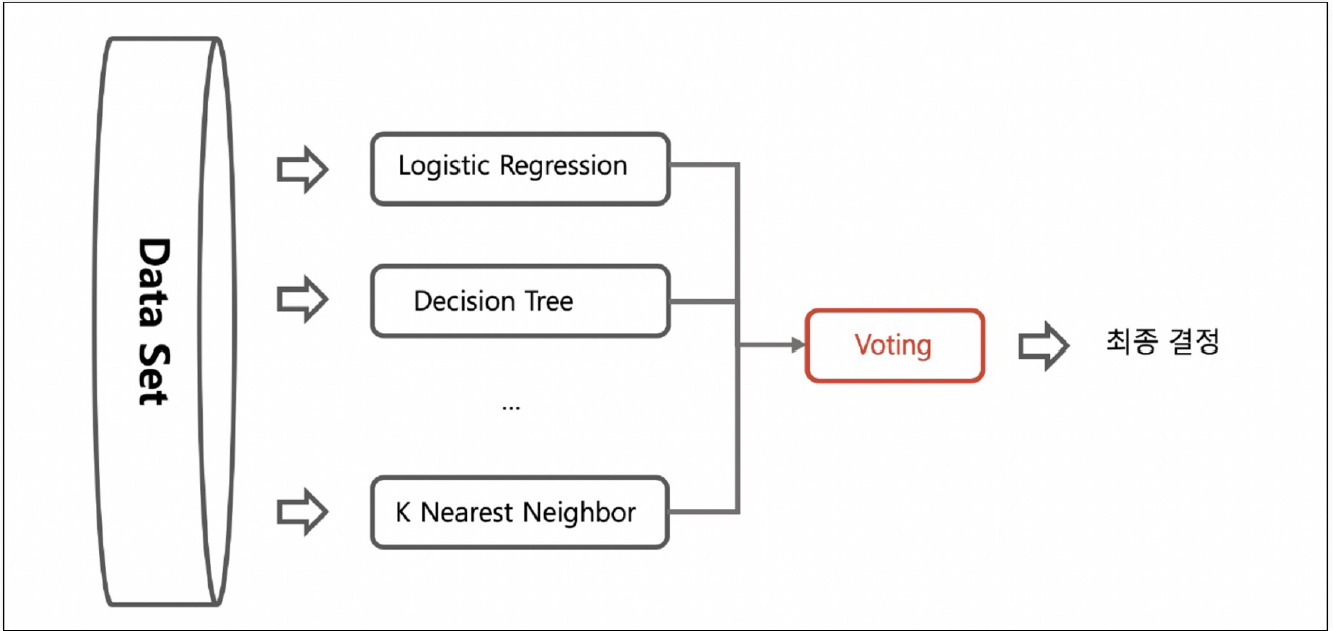
voting
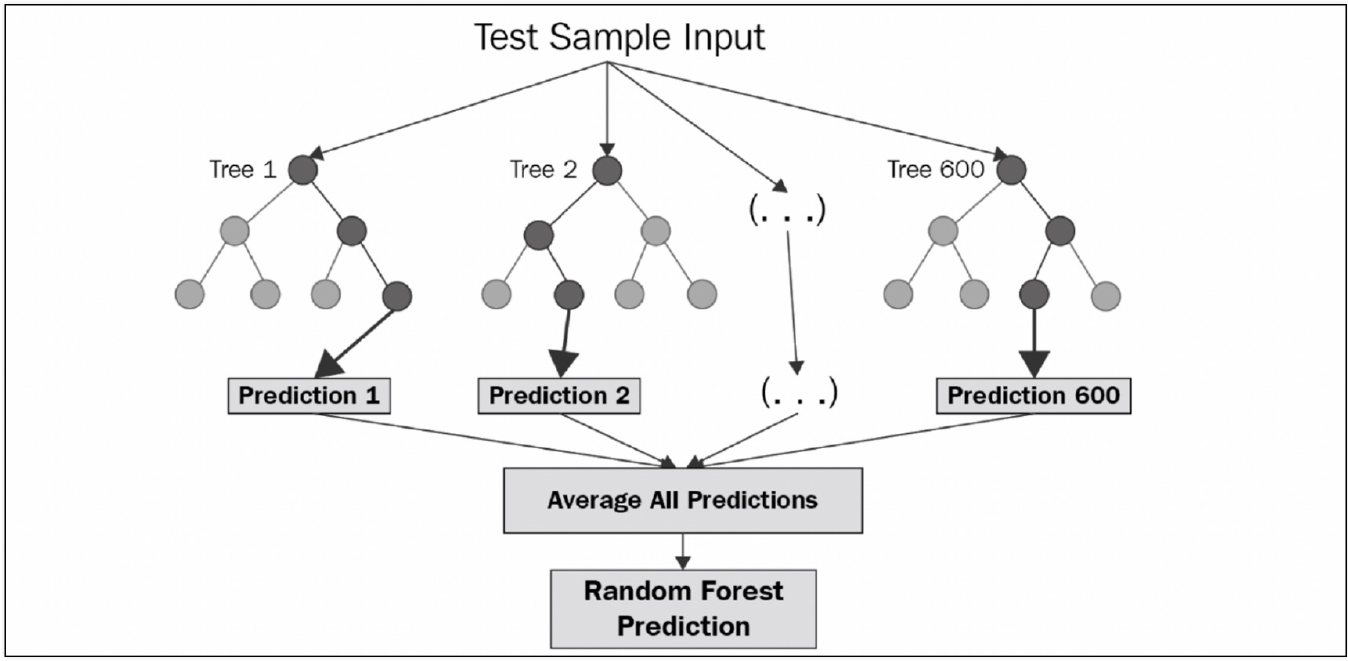
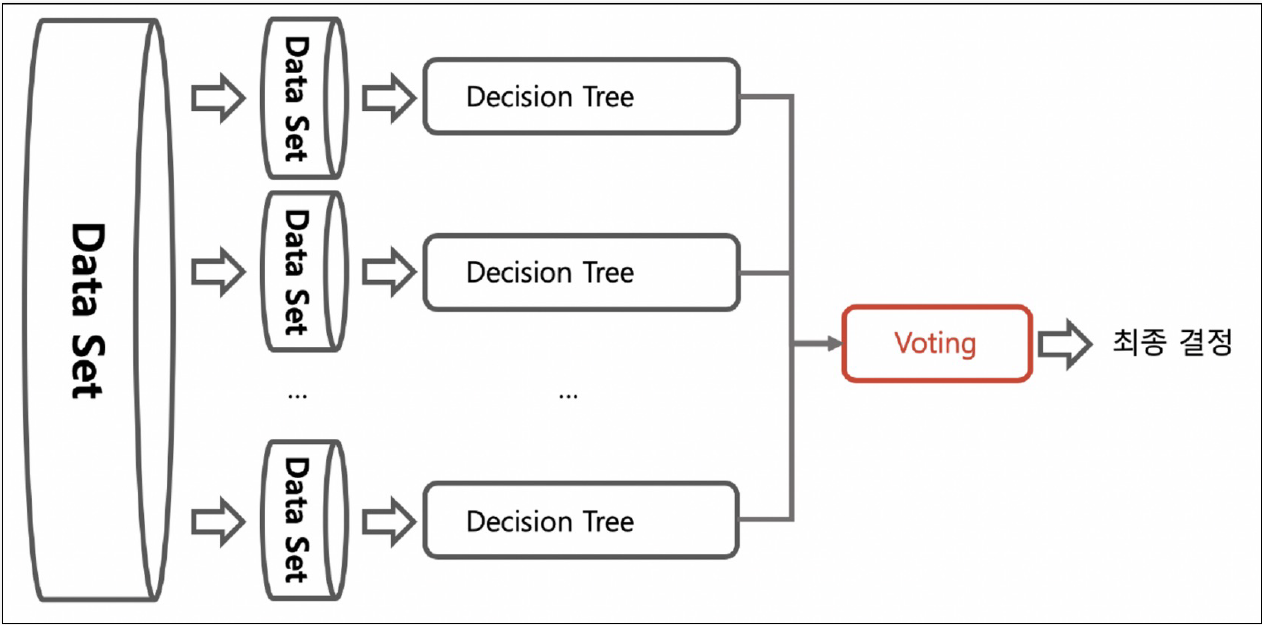
- 여러 개의 동일한 모델을 병렬적으로 학습시켜 결과를 결합하는 방식
- 각 모델은 원본 데이터셋에서 무작위로 복원추출(Bootstrap)된 부분집합을 사용하여 학습
- 학습된 모델들은 독립적으로 예측을 수행하고, 이 예측 결과를 결합하여 최종 예측
- 대표적인 알고리즘으로 랜덤 포레스트(Random Forest)
bagging
- 서로 다른 종류의 모델(알고리즘)을 결합하여 다양한 시각에서의 예측을 활용하는 방식
- 다양한 모델(로지스틱 회귀, 결정 트리, 서포트 벡터 머신 등)을 병렬적으로 학습시켜 결과 결합
- 하드 보팅 : 각 모델의 예측 결과 중 가장 많이 나온 클래스를 최종 예측으로 선택(다수결의 원칙)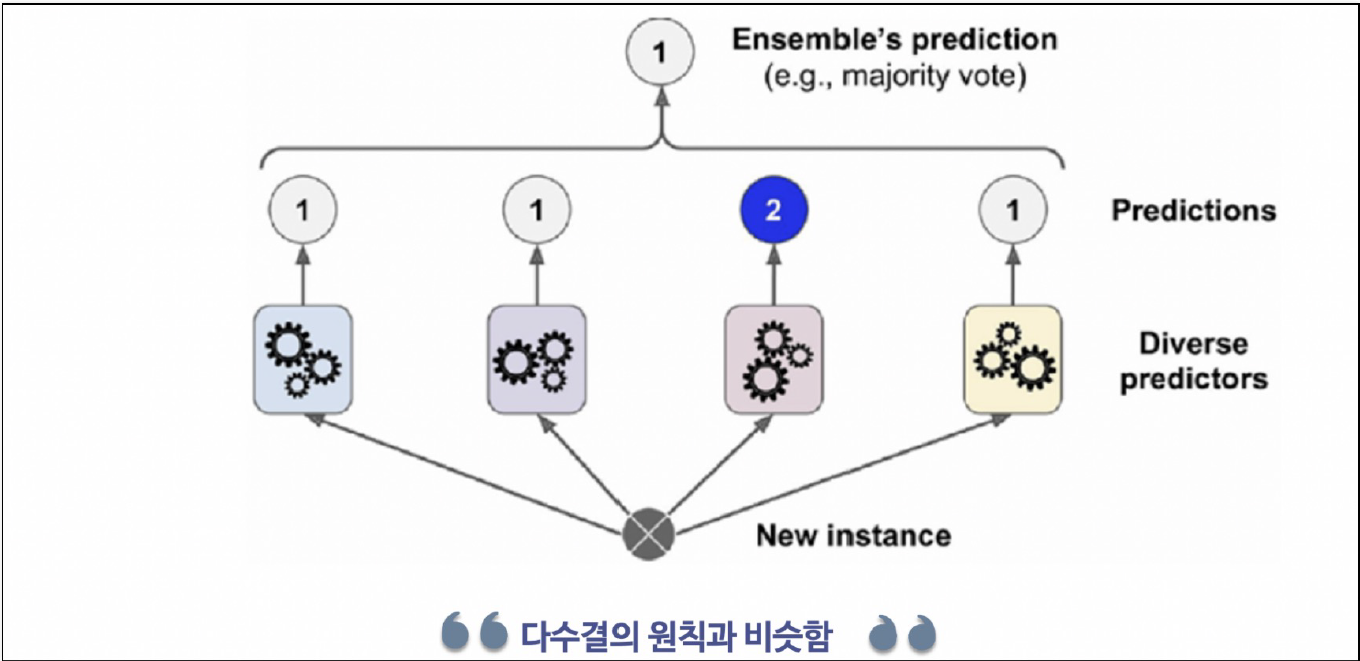
- 소프트 보팅 : 각 모델의 예측 확률을 평균하여 가장 높은 확률을 가진 클래스를 최종 예측으로 선택(확률의 평균값으로 결정)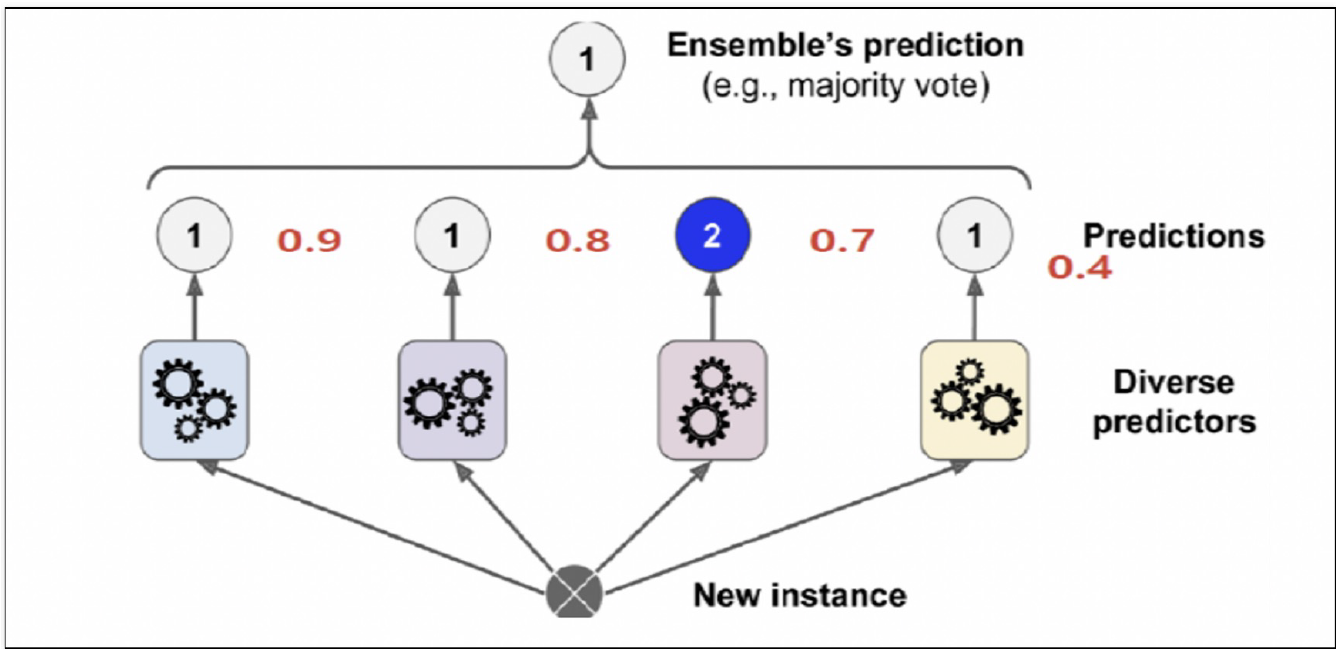
Random Forest with HAR(Human Activity Recognition)
HAR 데이터 확인
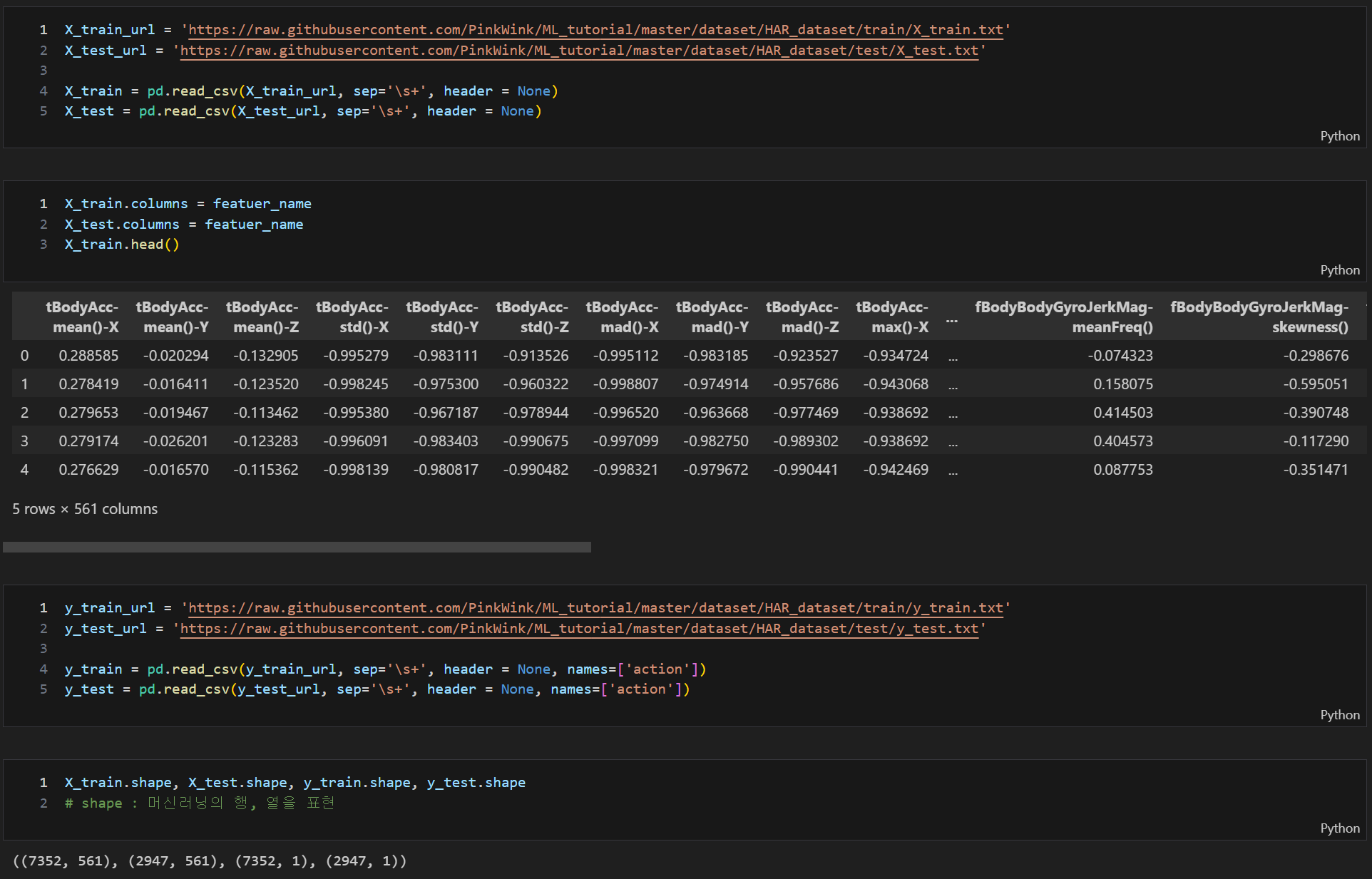
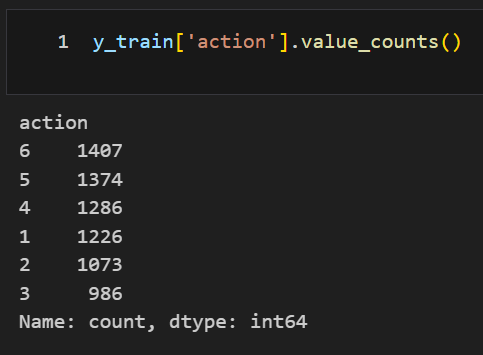 | 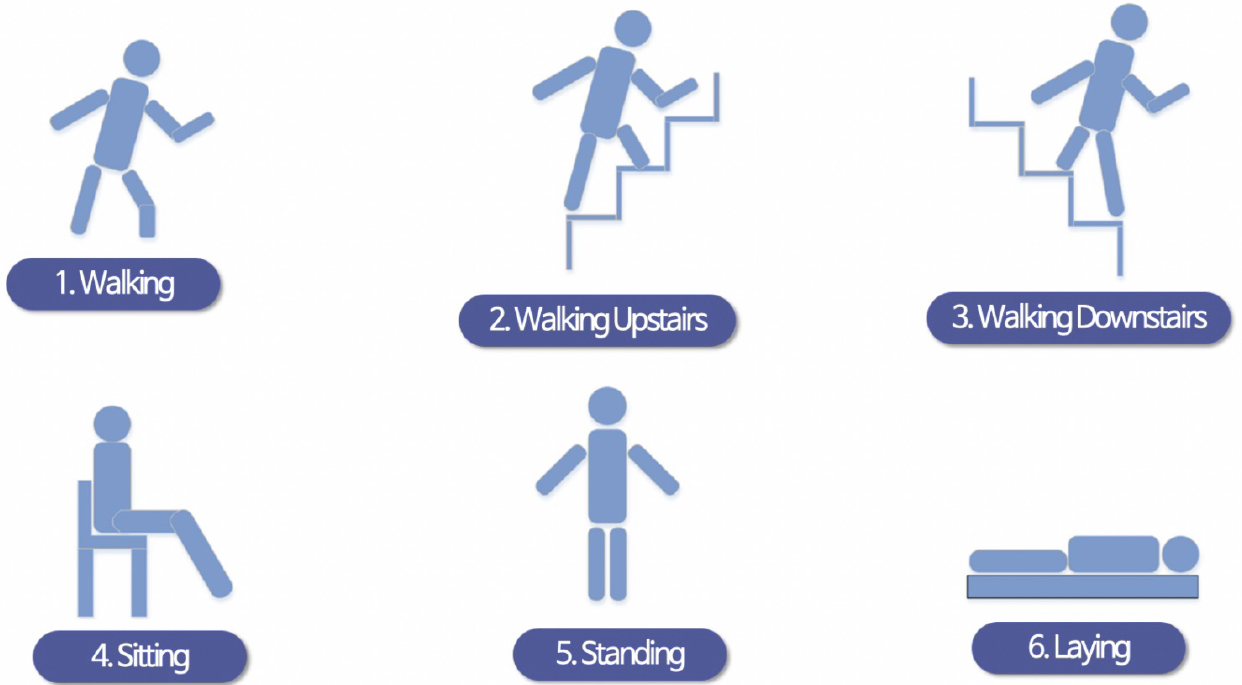 |
|---|
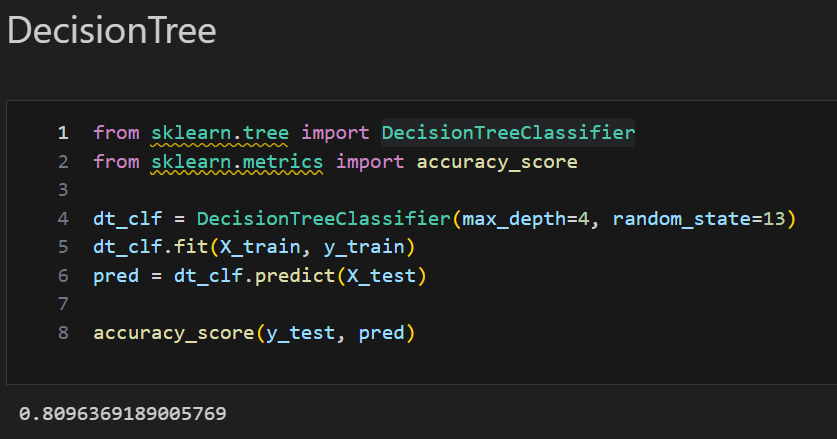
GridSearchCV를 이용한 DecisionTree 먼저 확인
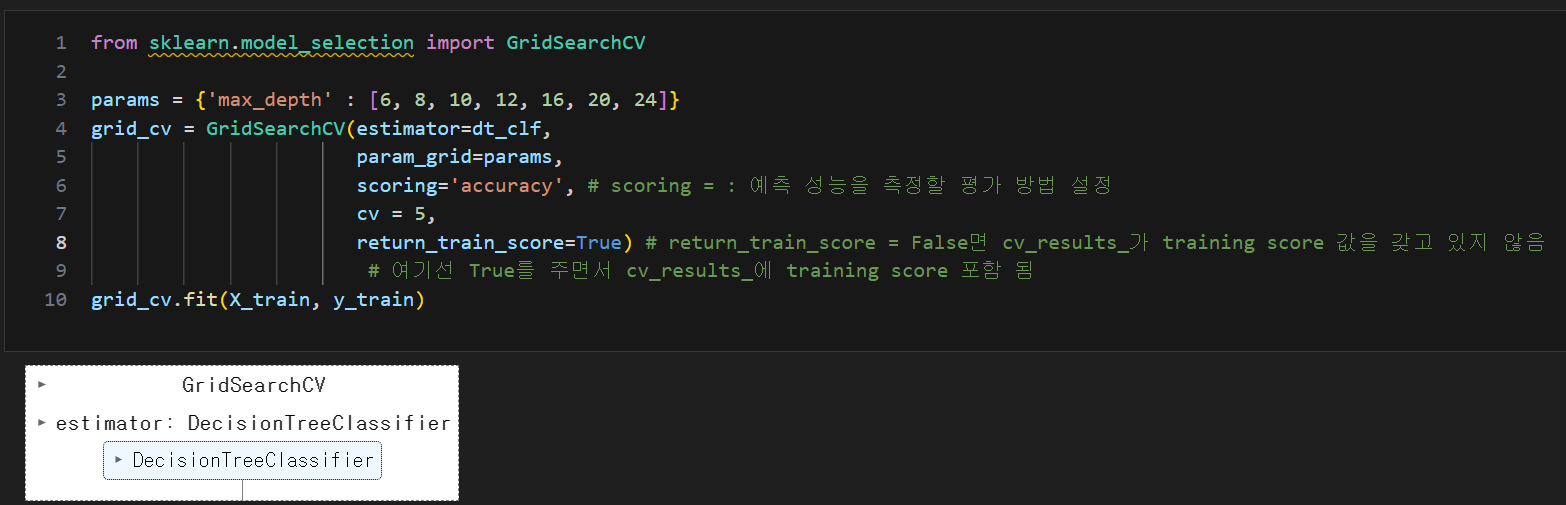
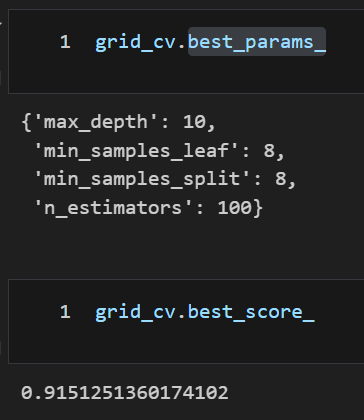
best_score
- X_test, y_test가 아닌 X_train, y_train 을 5개(cv=5)로 나누어 교차 검증한 값 중 가장 높은 값 산출
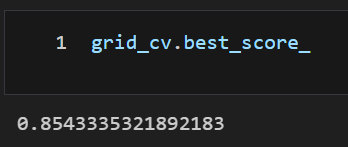
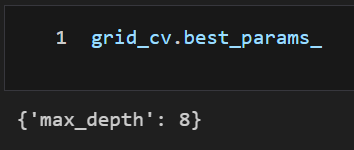
best_params
- X_test, y_test가 아닌 X_train, y_train 을 5개(cv=5)로 나누어 교차 검증한 파라미터 중 가장 좋은 파라미터
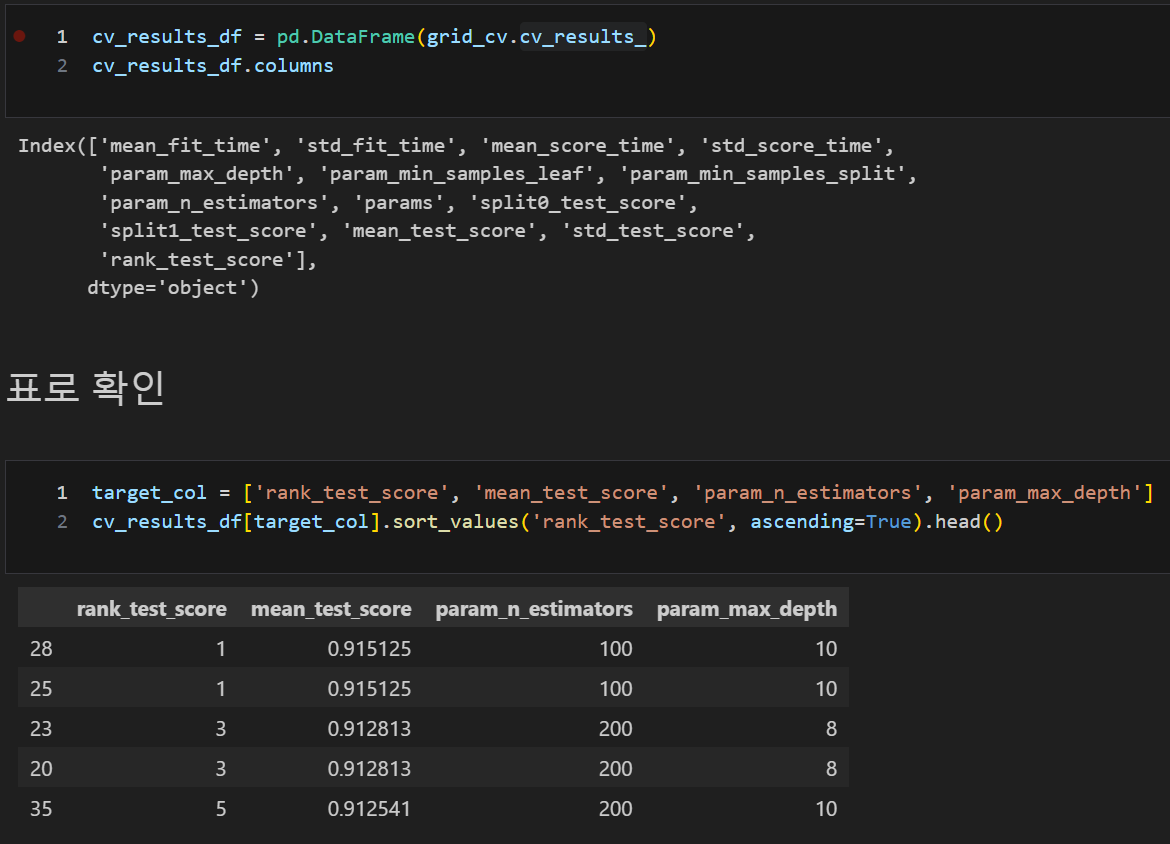
cv_results_
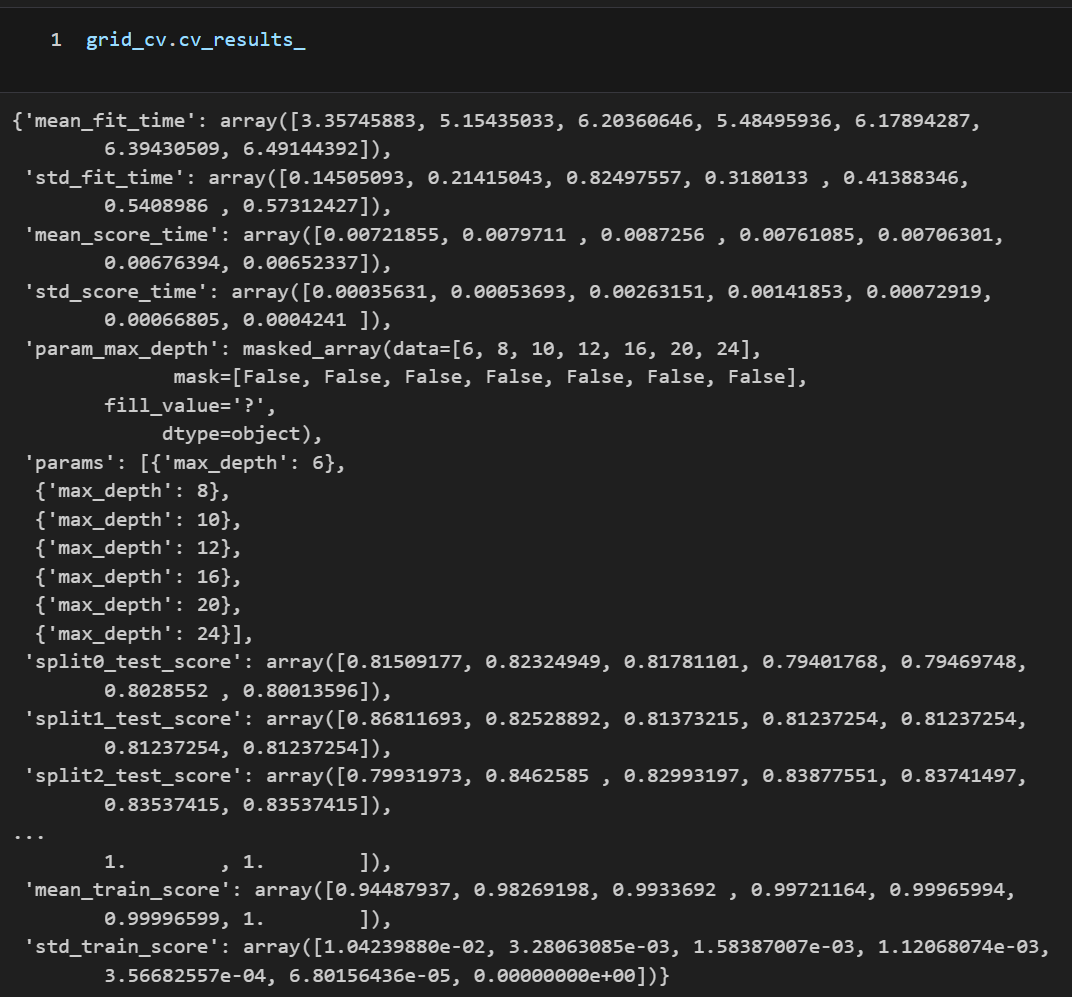
cv_results_ 판다스를 이용하여 필요한 부분만 보기
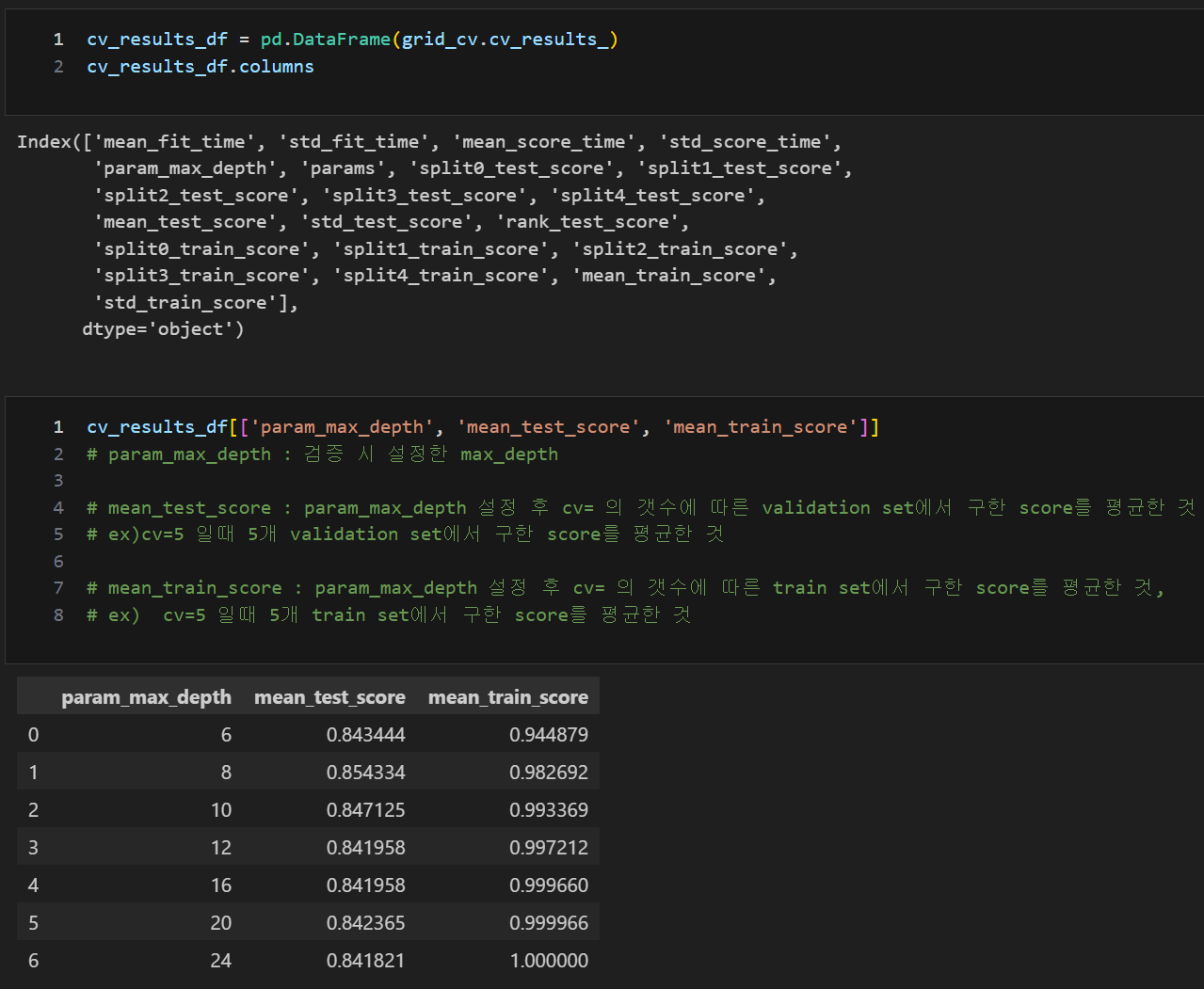
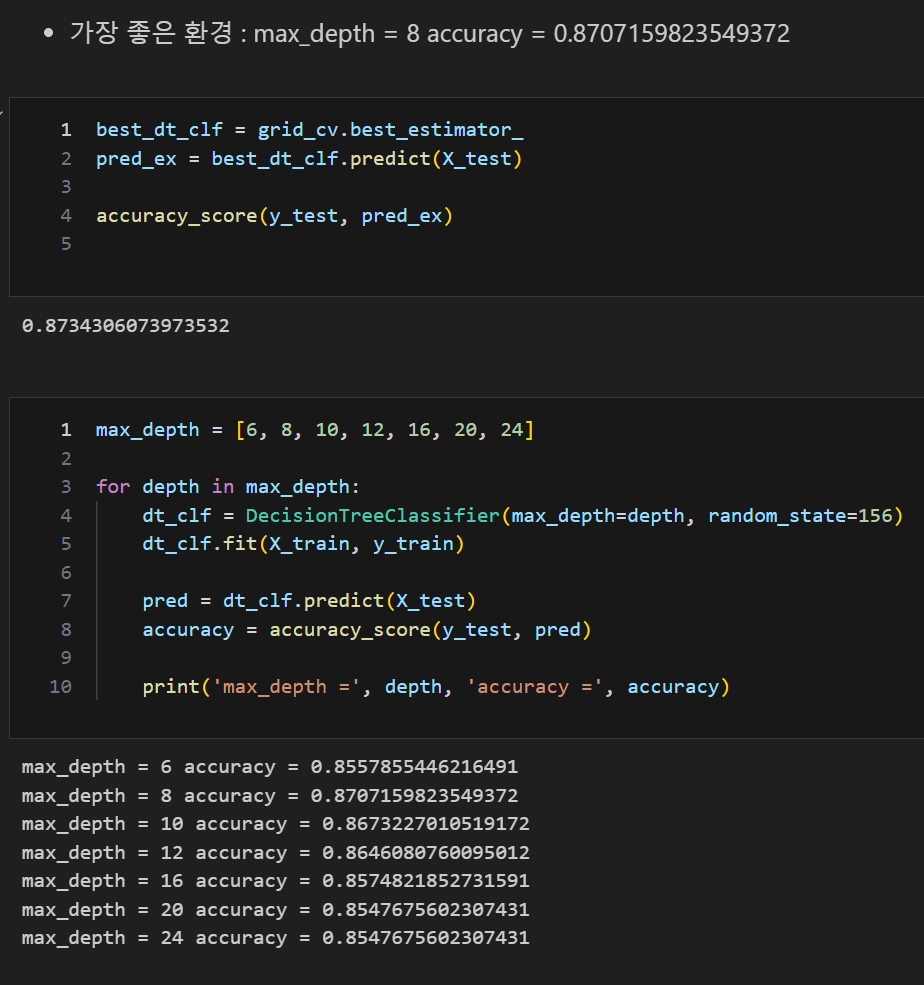
GridSearchCV에서 max_depth별 test 데이터 accuracy 확인
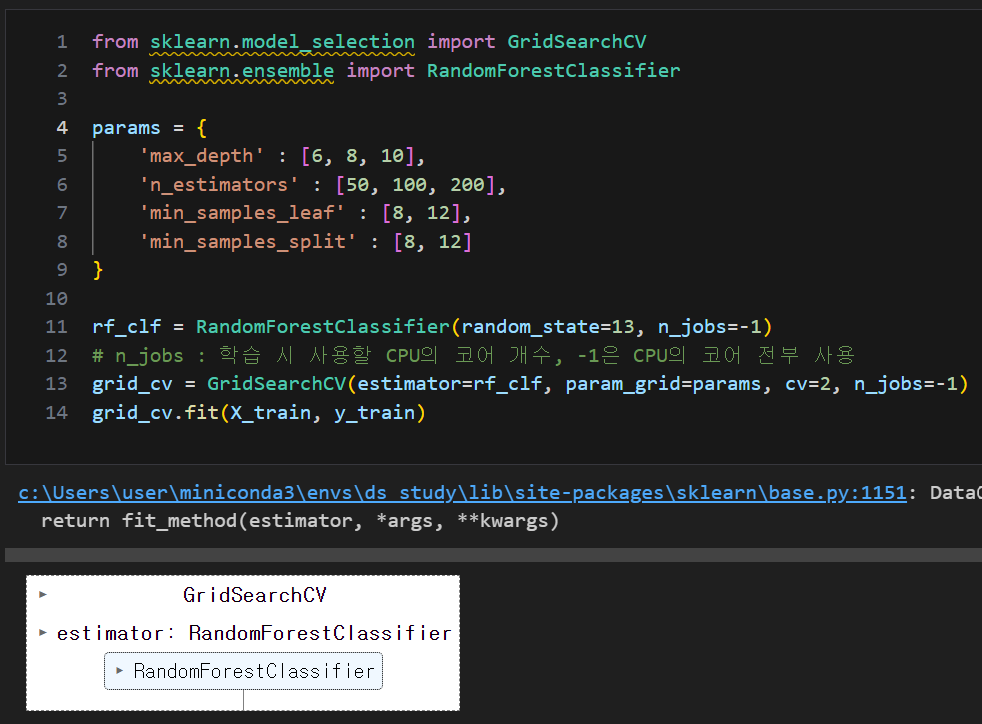
GridSearchCV를 이용한 RandomForest 적용
- max_depth : DecisionTree의 가지의 수
- n_estimators : 사용한 DecisionTree 수
- min_samples_leaf : max_depth가 한계치에 오지 않았지만 분할해서 leaf가 될 수 있는 최소 샘플수를 지정하는 것
- min_samples_split : leaf에서 가지로 분할 할 수 있는 샘플수를 지정하는 것
cv_results_ 및 best_params_ 및 best_score_ 확인
 |  |
|---|
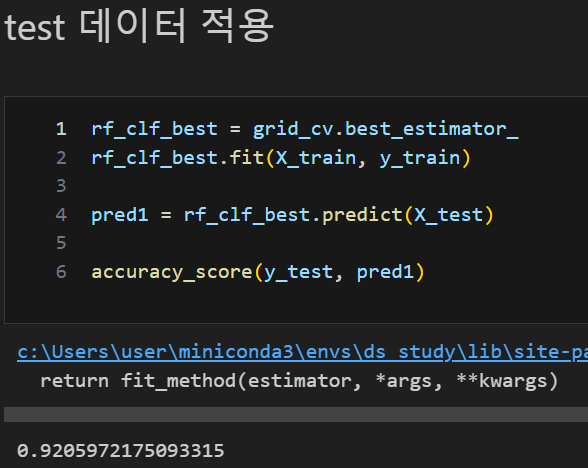
test 적용
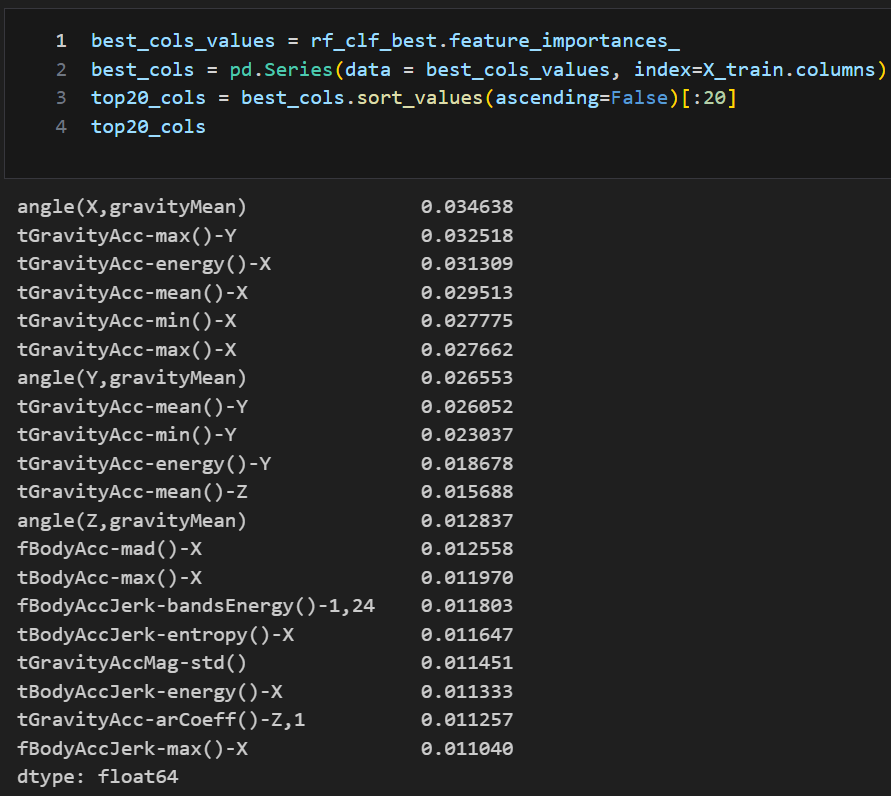
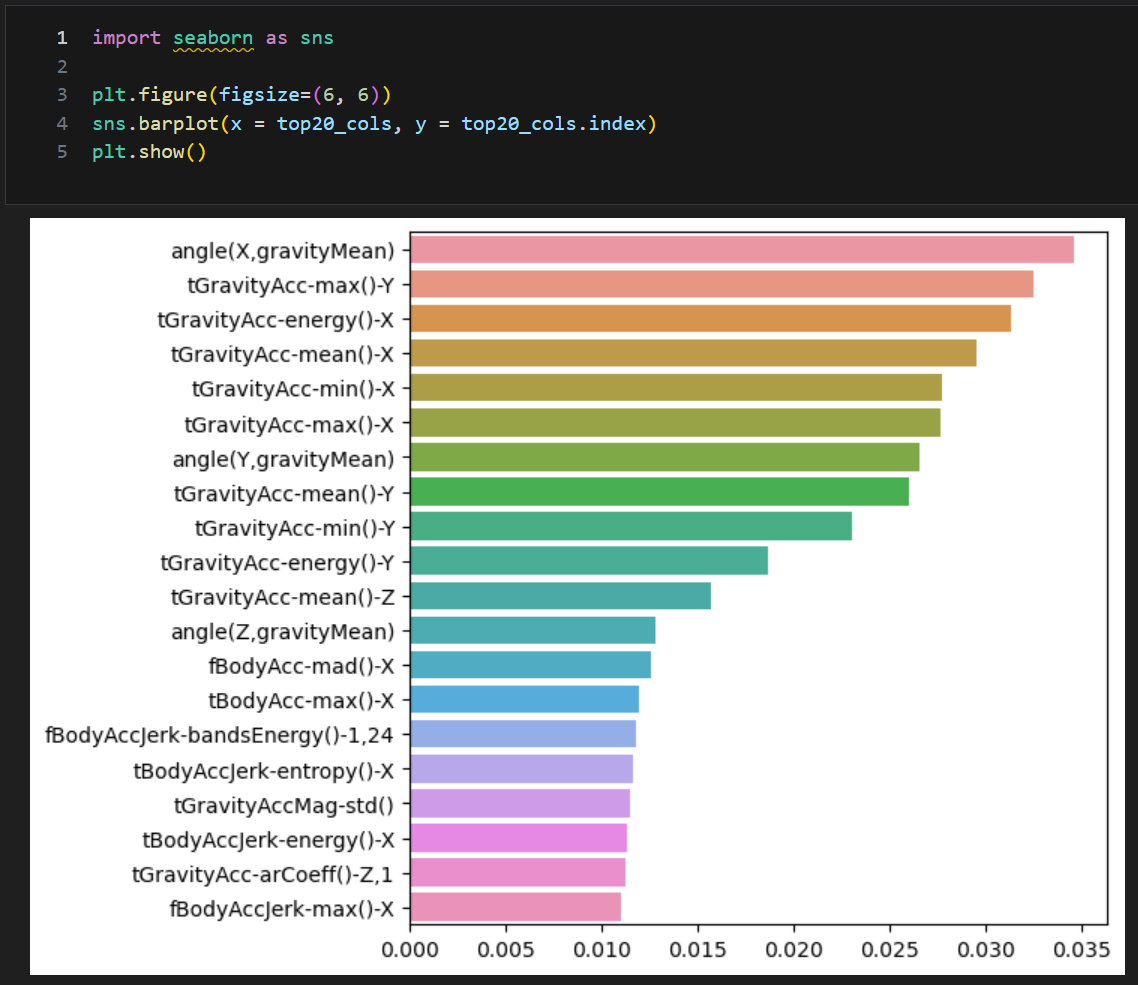
feature_importances_
- 모델을 결정하기 위한 중요 feature가 어떻게 나왔는지 각각의 중요도를 보여주는 메써드
- 여기선 상위 20개만 확인

비전공 데이터 분석가 도전