git : https://github.com/bbangcha/ML/blob/main/23.%20ML_GBM%2C%20XGBoost%2C%20LGBM.ipynb
GBM
- 부스팅 알고리즘은 여러 개의 약한 학습기(week learner)를 순차적으로 학습-예측하면서
잘못 예측한 데이터에 가중치를 부여해서 오류를 개선해가는 방식 - GBM은 가중치를 업데이트할 때 경사 하강법(Gradient Descent)을 이용하는 것이 큰 차이
HAR 데이터 적용
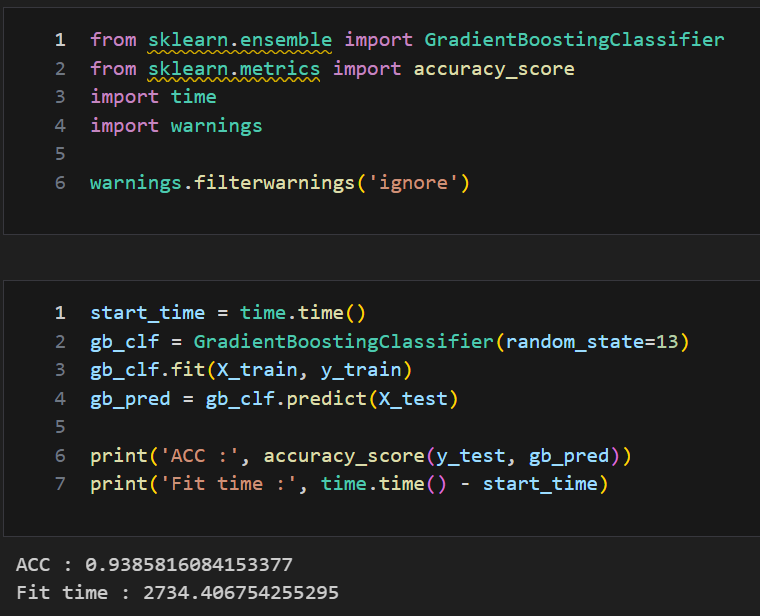
Gridsearch를 이용한 GBM

XGBoost
- 트리 기반의 앙상블 학습에서 각광받는 알고리즘 중 하나
- GBM 기반의 알고리즘을 다양한 규제를 통해 느린 속도 해결
- 병렬학습이 가능하도록 설계
- 반복 수행 시마다 내부적으로 학습데이터와 검증데이터를 교차검증 수행
- 교차검증을 통해 최적화가 완료되면 반복을 중단하는 조기 중단 기능 보유
XGBoost 주요 파라미터
- nthread : CPU의 실행 스레드 개수를 조정, 디폴트는 CPU 전체 스레드 사용
- eta : GBM 학습률
- num_boost_rounds : n_estimators와 같은 기능
- max_depth
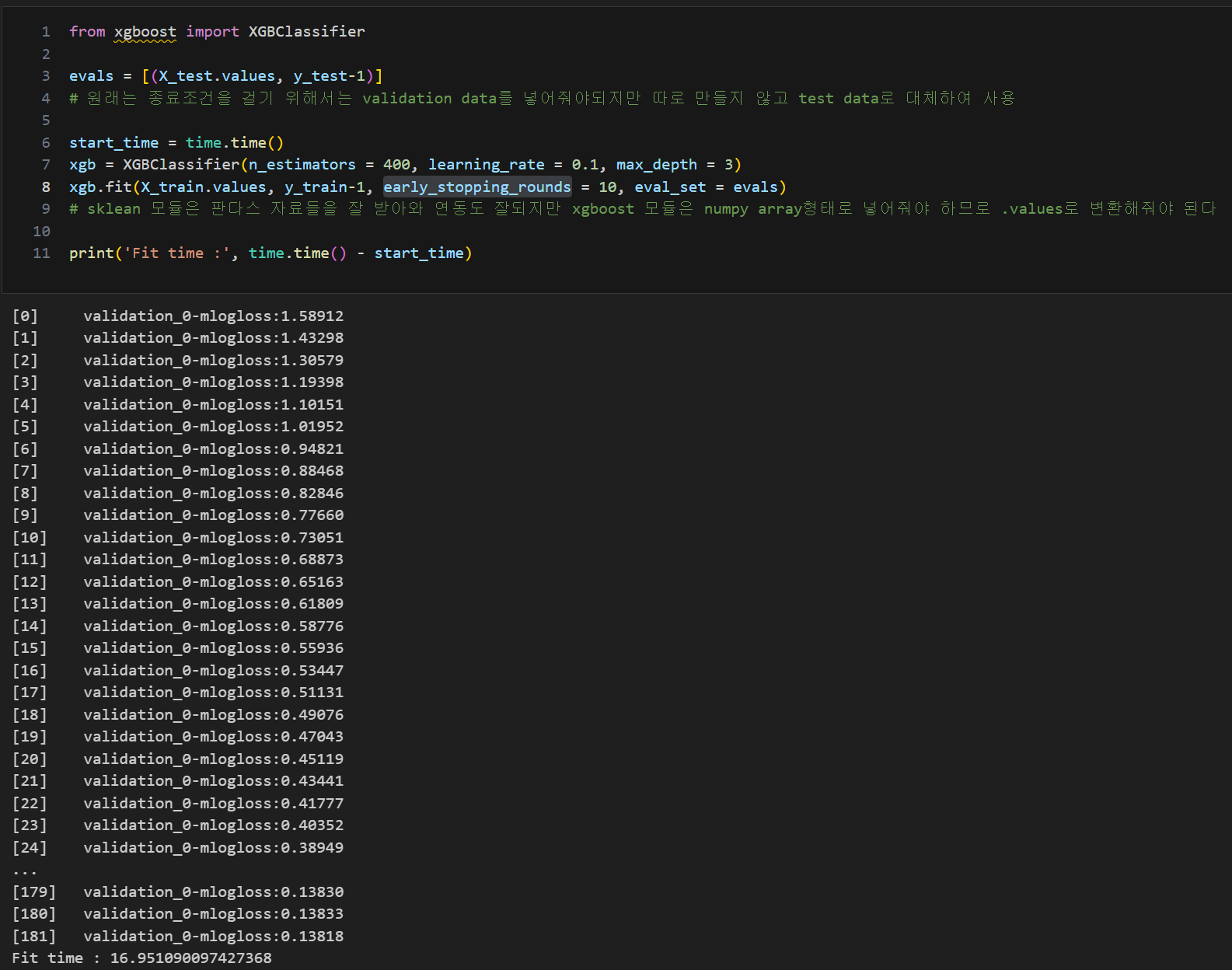
HAR 데이터 적용
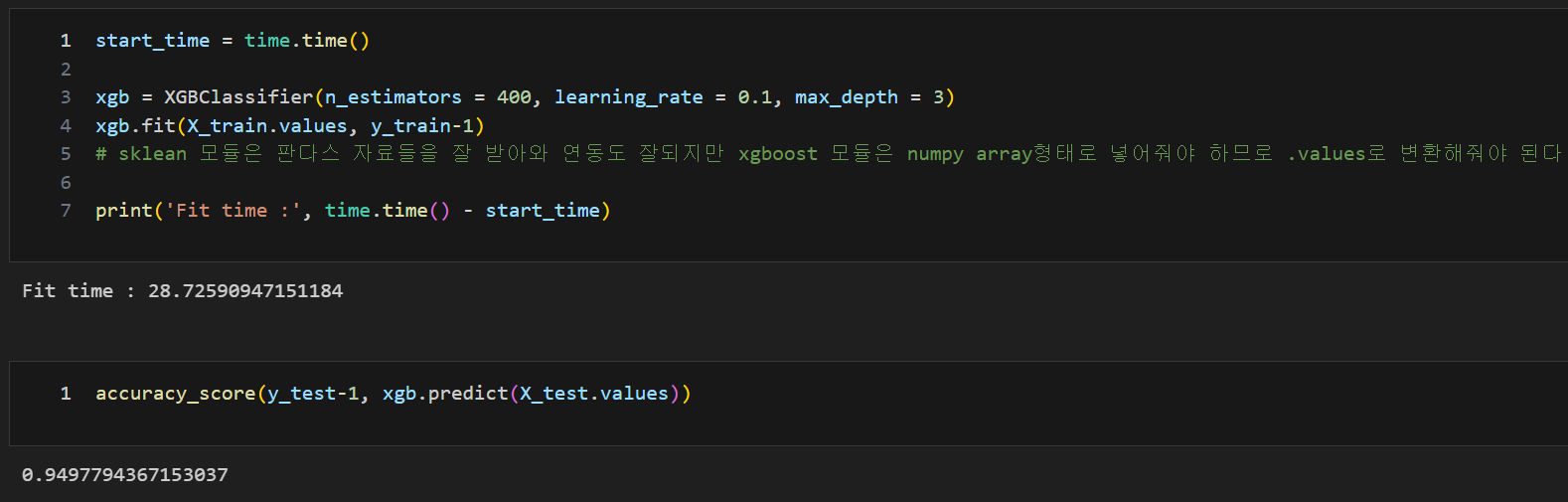
조기 종료 : early_stopping_rounds
- early_stopping_rounds : 검증 세트의 손실 또는 정확도와 같은 성능 지표를 지속적으로 계산하고, 일정한 횟수 동안 성능이 개선되지 않을 때 훈련을 중단
- 매 반복마다 모델이 개선되는지를 모니터링
- 모델이 지정된 반복 횟수 동안 개선되지 않으면, 그 때의 모델이 최종 모델로 선택
- 이를 통해 과적합을 방지하고 최적의 일반화 성능 획득

LightGBM
- LightGBM은 XGBoot와 함께 부스팅 계열에서 가장 각광받는 알고리즘
- LBGM의 가장 큰 장점은 속도
- 단, 적은 수의 데이터에는 어울이지 않음(일반적으로 10,000건 이상의 데이터가 필요)
- GPU 버전도 존재
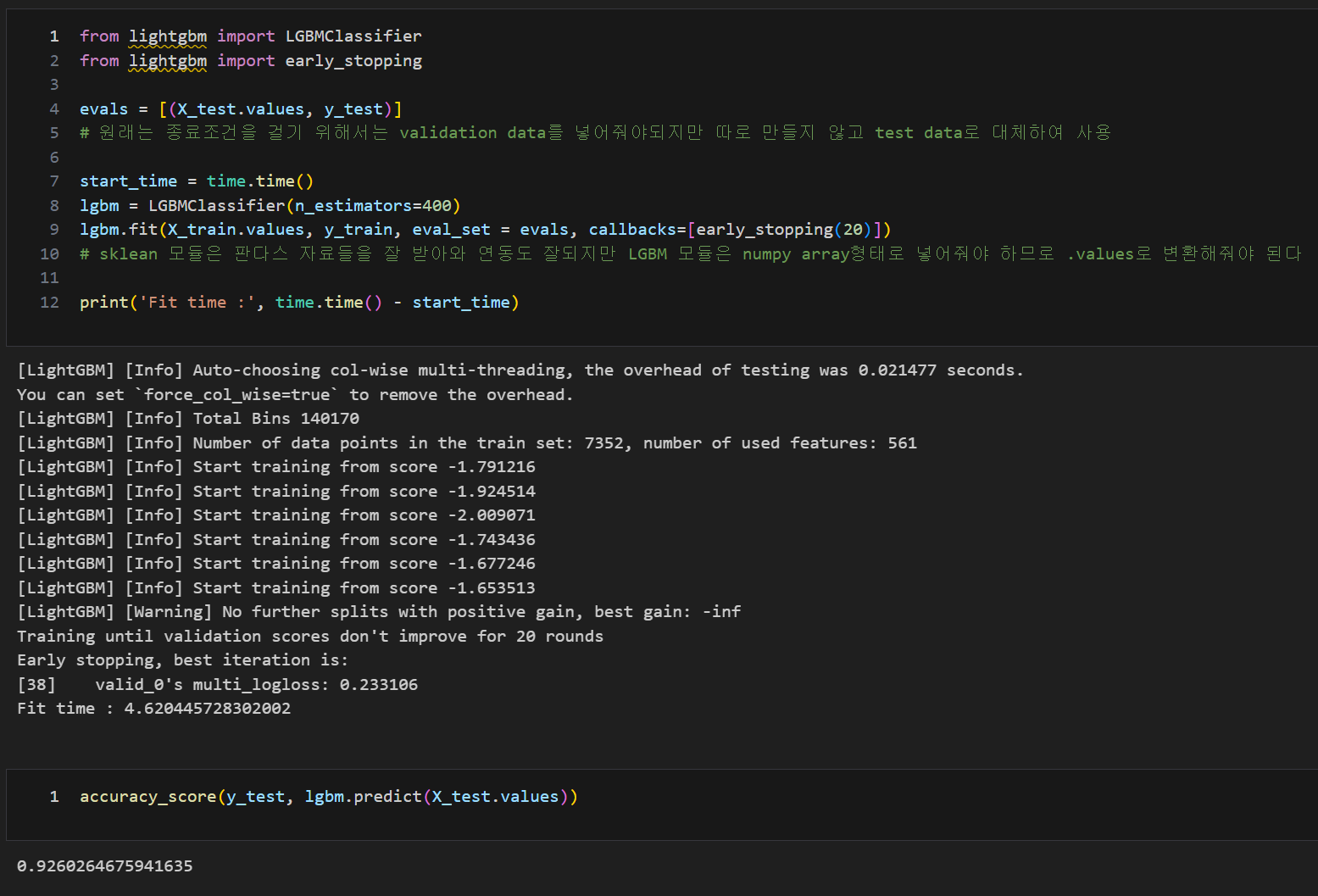
- eval_set : 검증set
callbacks=[early_stopping(?)]
- early_stopping_rounds와 같이 조기 종료 기능(from lightgbm import early_stopping 필수)
HAR 데이터 적용

비전공 데이터 분석가 도전