데이터 불러오기
from sklearn.datasets import load_iris
iris = load_iris()sklearn dataset은 python dict 형과 유사
iris.keys()
iris.target_names
iris.target
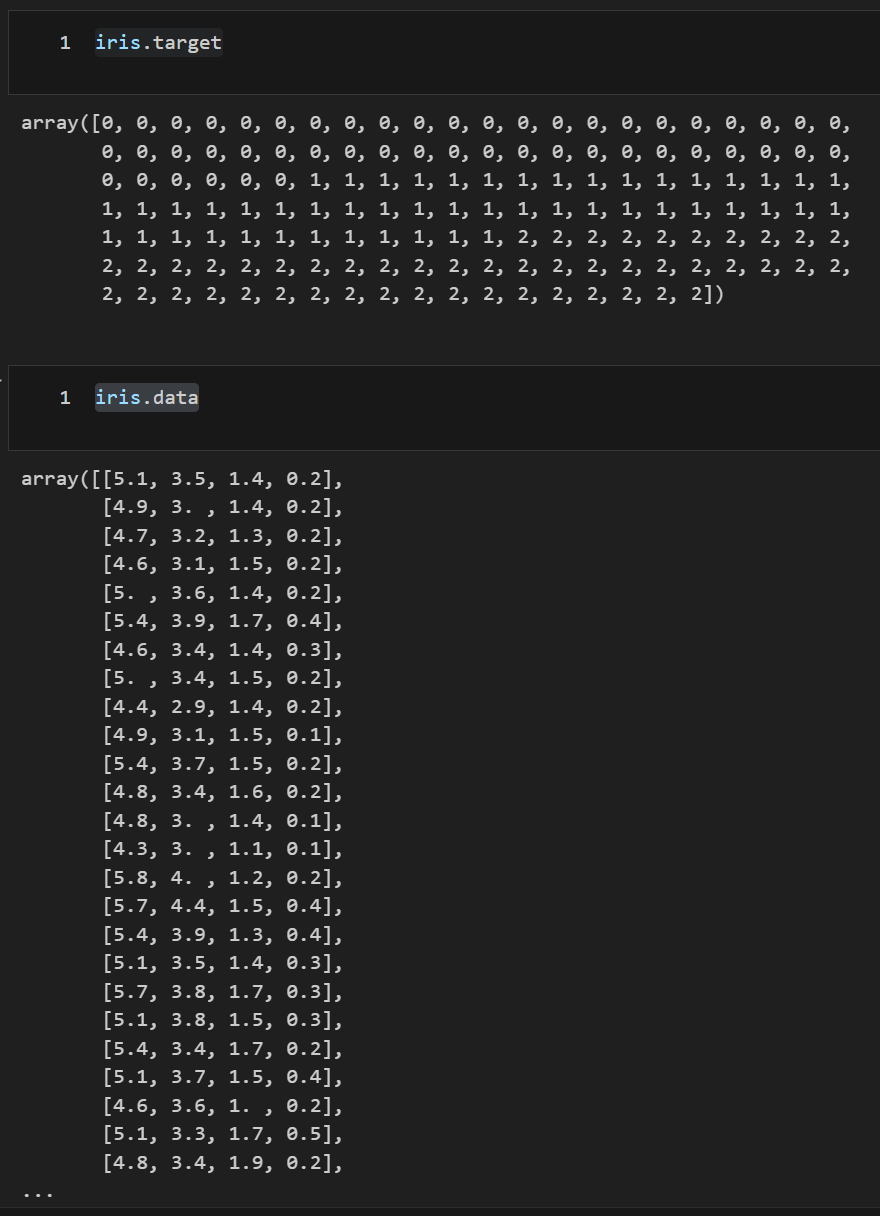
iris.data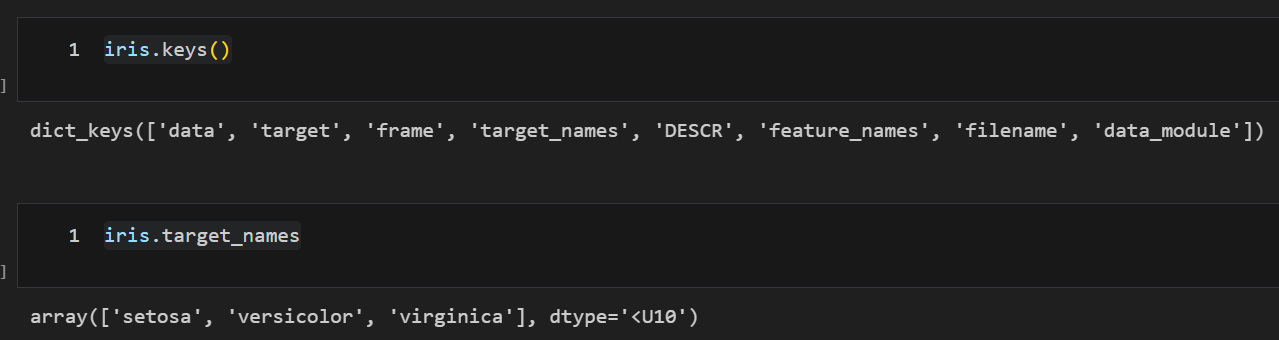
DataFrame 만들기
import pandas as pd
iris_pd = pd.DataFrame(iris.data, columns=iris.feature_names)
iris_pd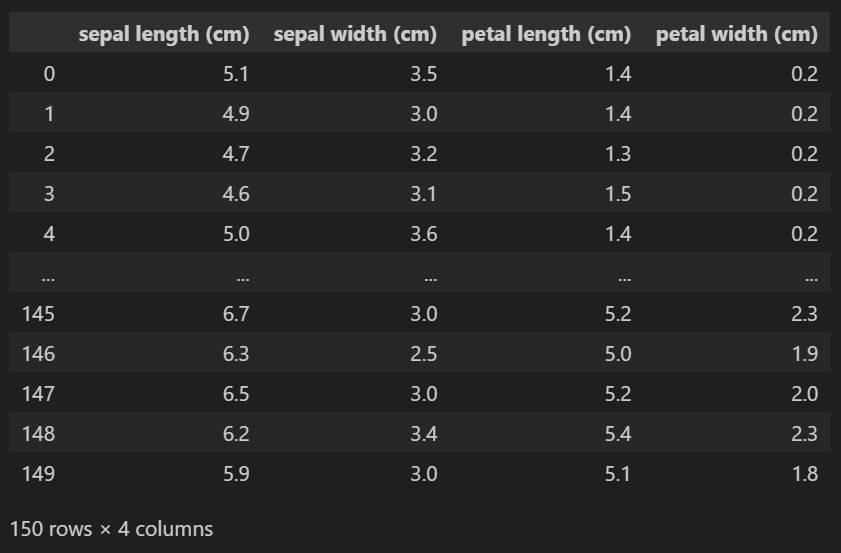
iris_pd['species'] = iris.target
iris_pd.head()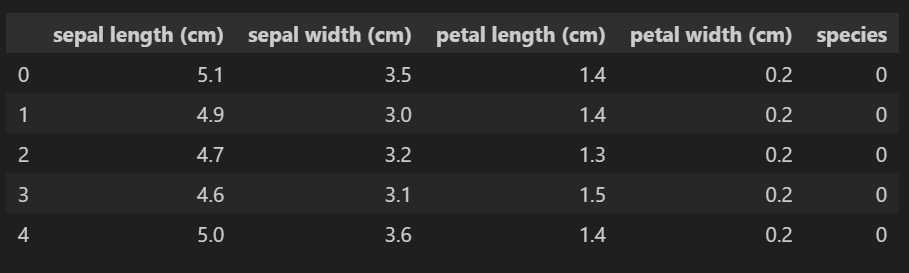
boxplot을 통하여 각 컬럼별 중복 구간 확인
- 다양한 컬럼들을 이용하였지만 중복구간은 항상 발생
plt.figure(figsize=(12, 6))
sns.boxplot(x='sepal length (cm)', y='species', data=iris_pd, orient='h')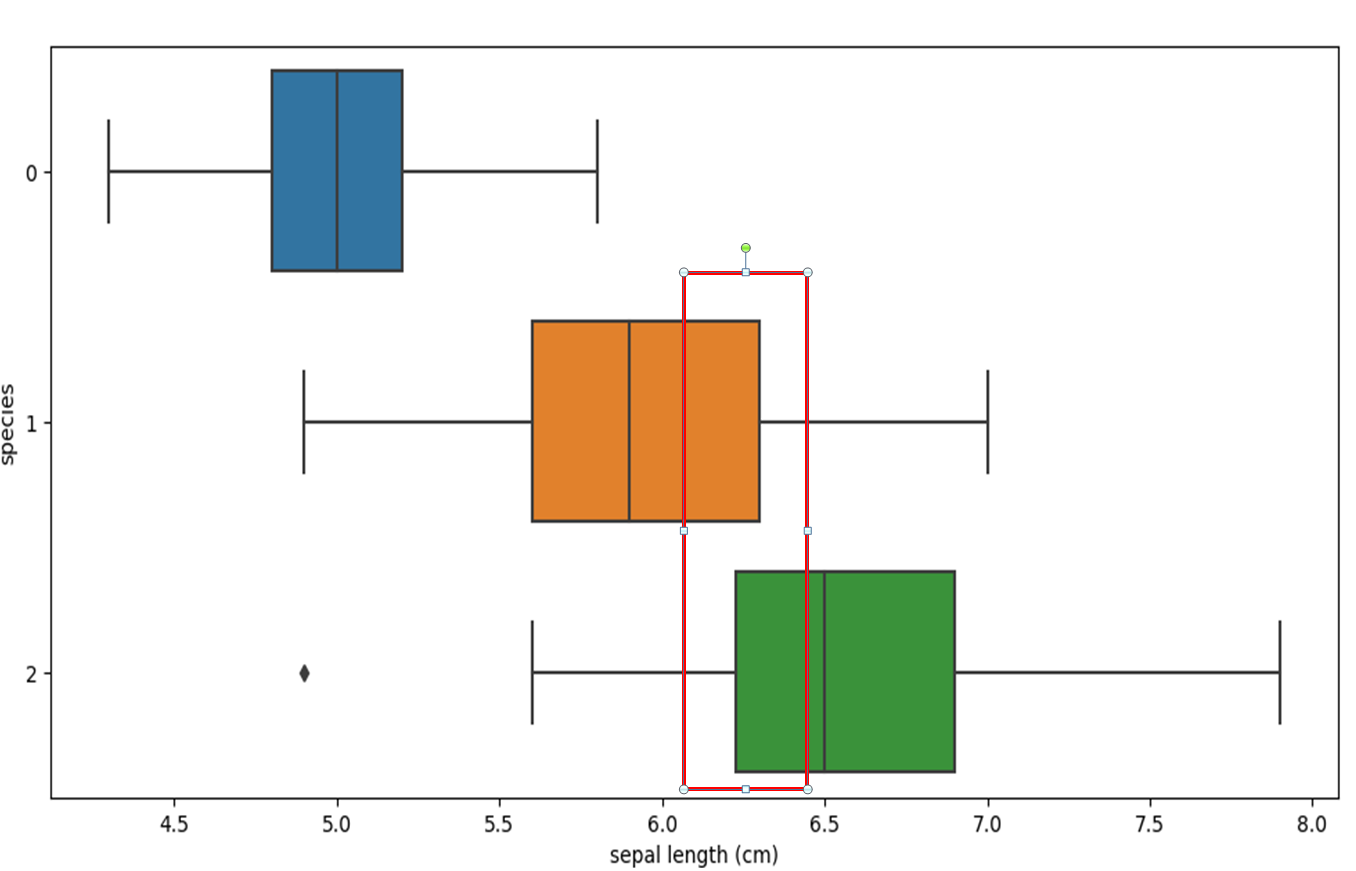
pairplot을 통하여 각 컬럼별 관계 확인
- 그나마 petal width (cm), petal length (cm) 구분을 잘하는 것을 확인
sns.pairplot(iris_pd, hue='species')
sns.pairplot(iris_pd,
vars=['petal width (cm)', 'petal length (cm)'],
hue='species', height=4)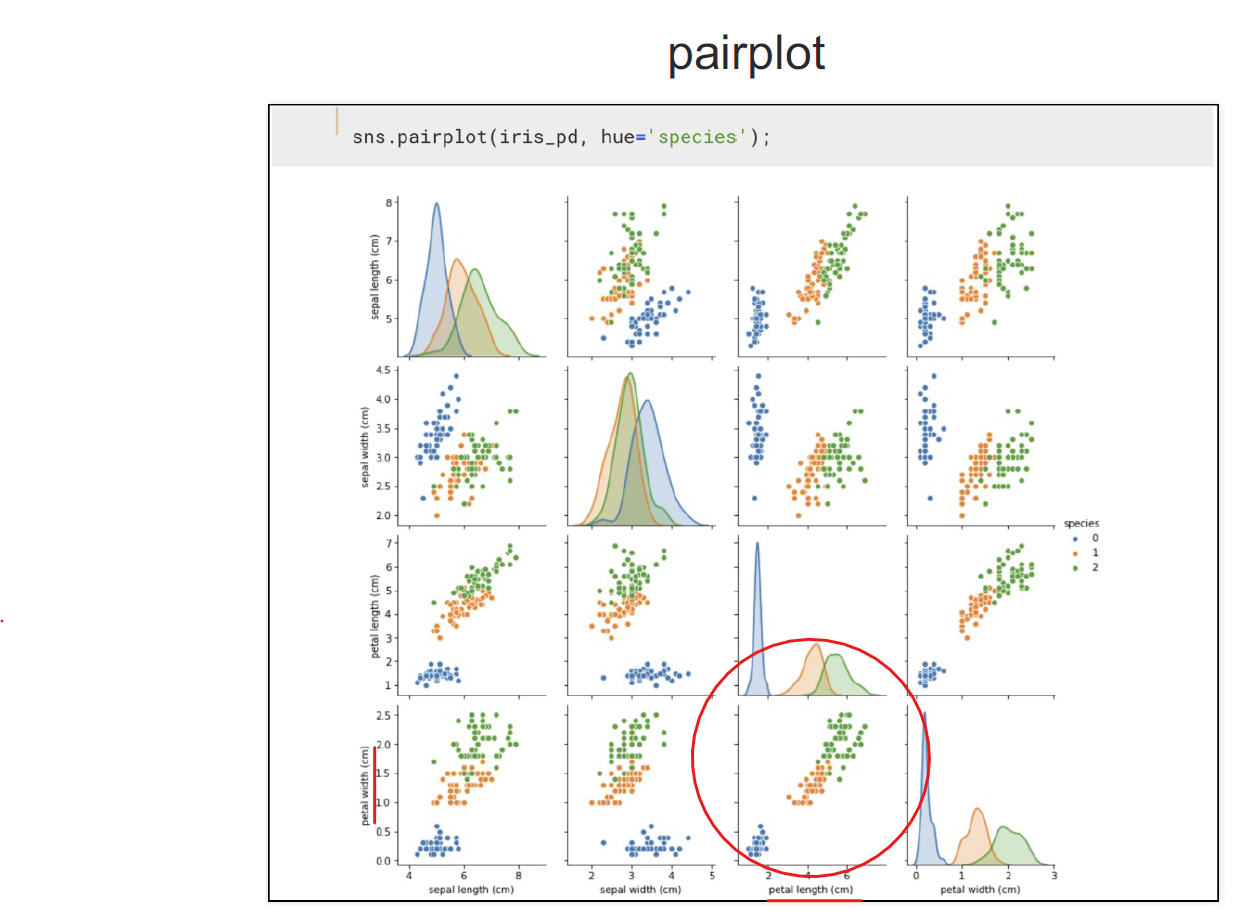
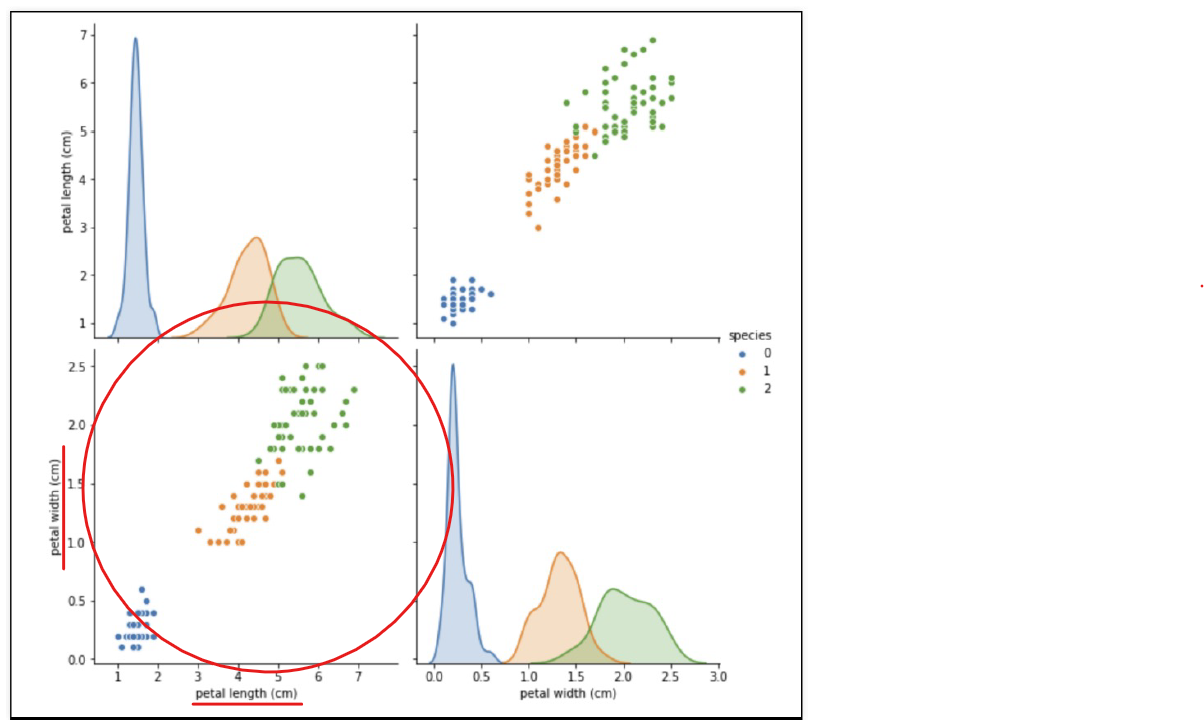
petal width (cm), petal length (cm)에 따른 iris 분포도 확인
- '0'인 setosa는 분류가 잘된다
plt.figure(figsize=(12, 6))
sns.scatterplot(x='petal width (cm)', y='petal length (cm)',
data=iris_pd, hue='species', palette='Set2')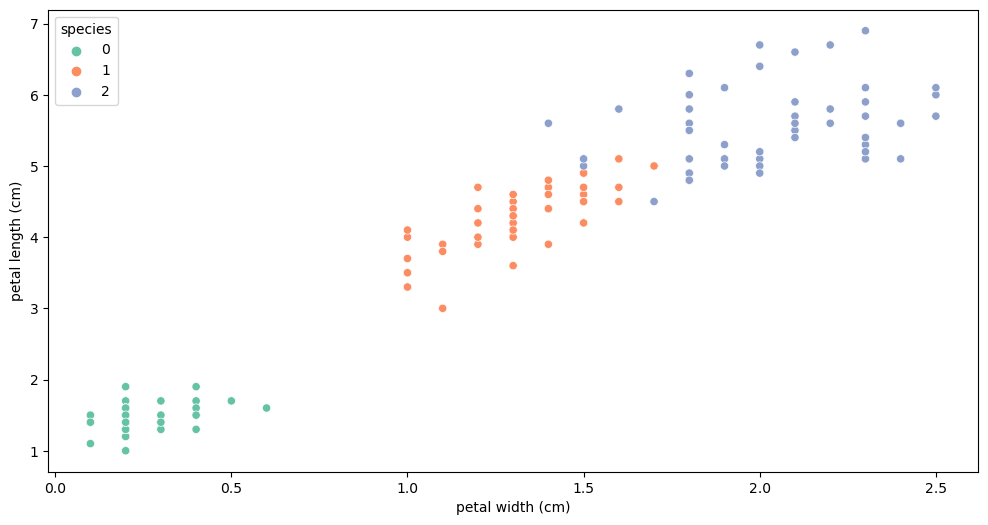
species가 '0'인 setosa를 제외하고 확인
iris_12 = iris_pd[iris_pd['species'] != 0]
plt.figure(figsize=(12, 6))
sns.scatterplot(x='petal width (cm)', y='petal length (cm)',
data=iris_12, hue='species', palette='Set2')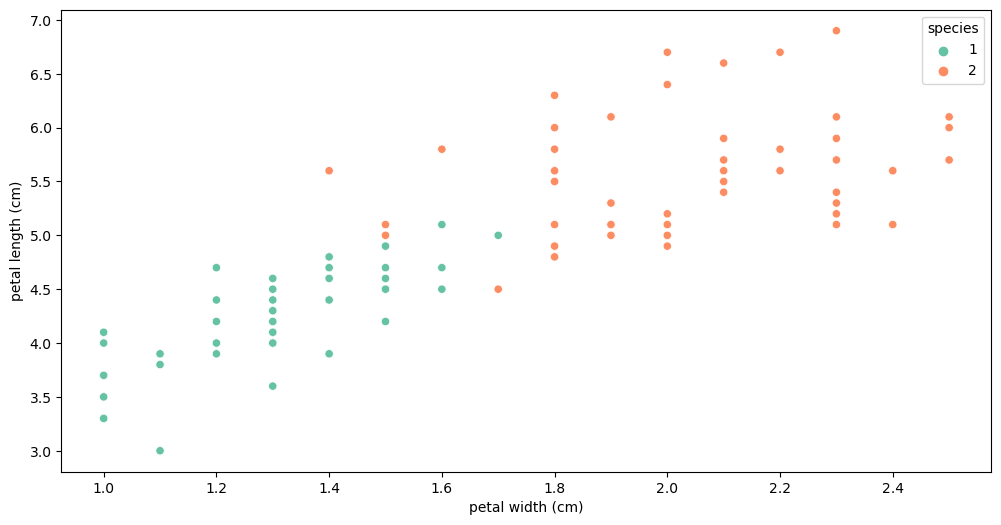
sklearn을 이용한 결정나무(DecisionTree) 구현
- iris 데이터의 petal width (cm), petal length (cm) 값만 학습용 데이터로 제공
from sklearn.tree import DecisionTreeClassifier
iris_tree = DecisionTreeClassifier()
iris_tree.fit(iris.data[:, 2:], iris.target)
# iris.data[:, 2:] : 모든 열은 제공하고 컬럼은 2, 3인 petal width (cm), petal length (cm)만 제공
# .fit(학습용 데이터, 학습용 데이터에 맞는 값(=정답)) : 데이터를 제공할테니 학습시키기위한 명령어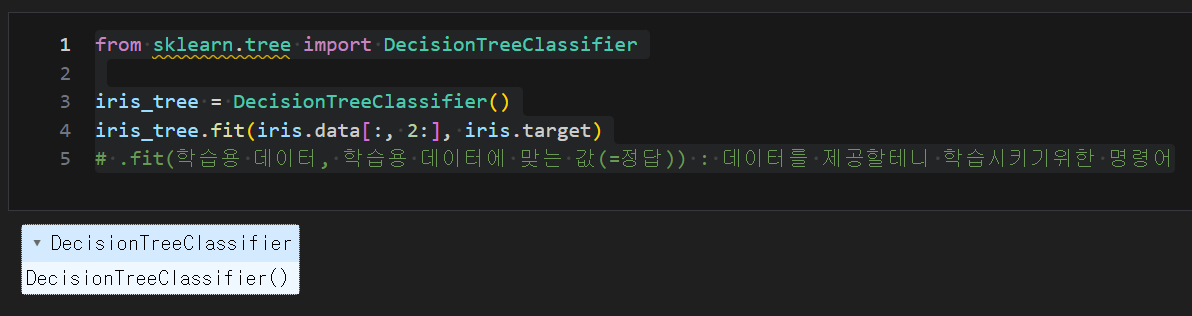
학습한 결정나무(DecisionTree) 시각화
from sklearn.tree import plot_tree
plt.figure(figsize=(8, 8))
plot_tree(iris_tree)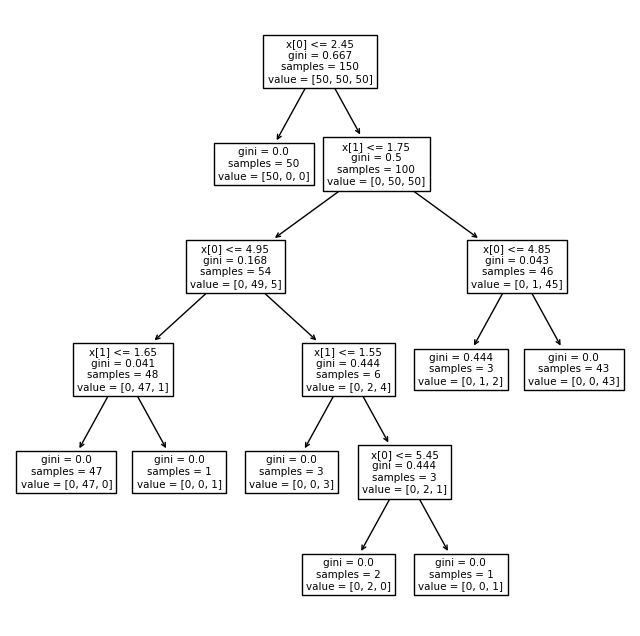
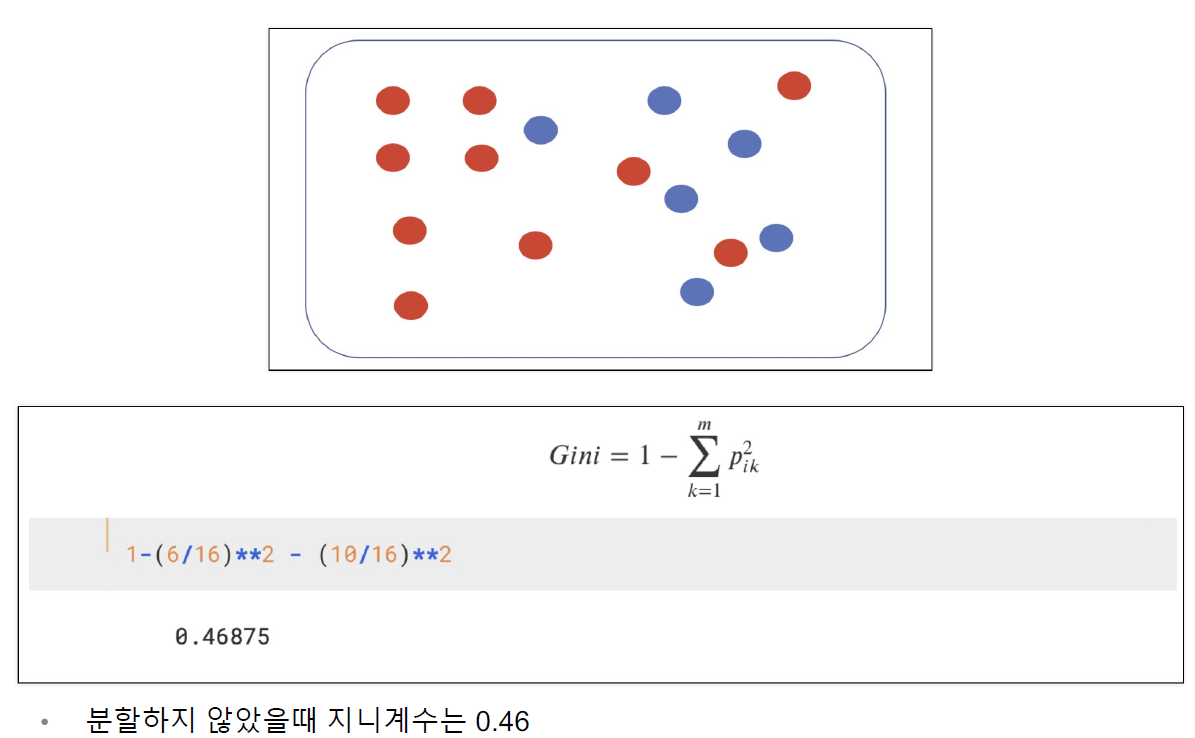
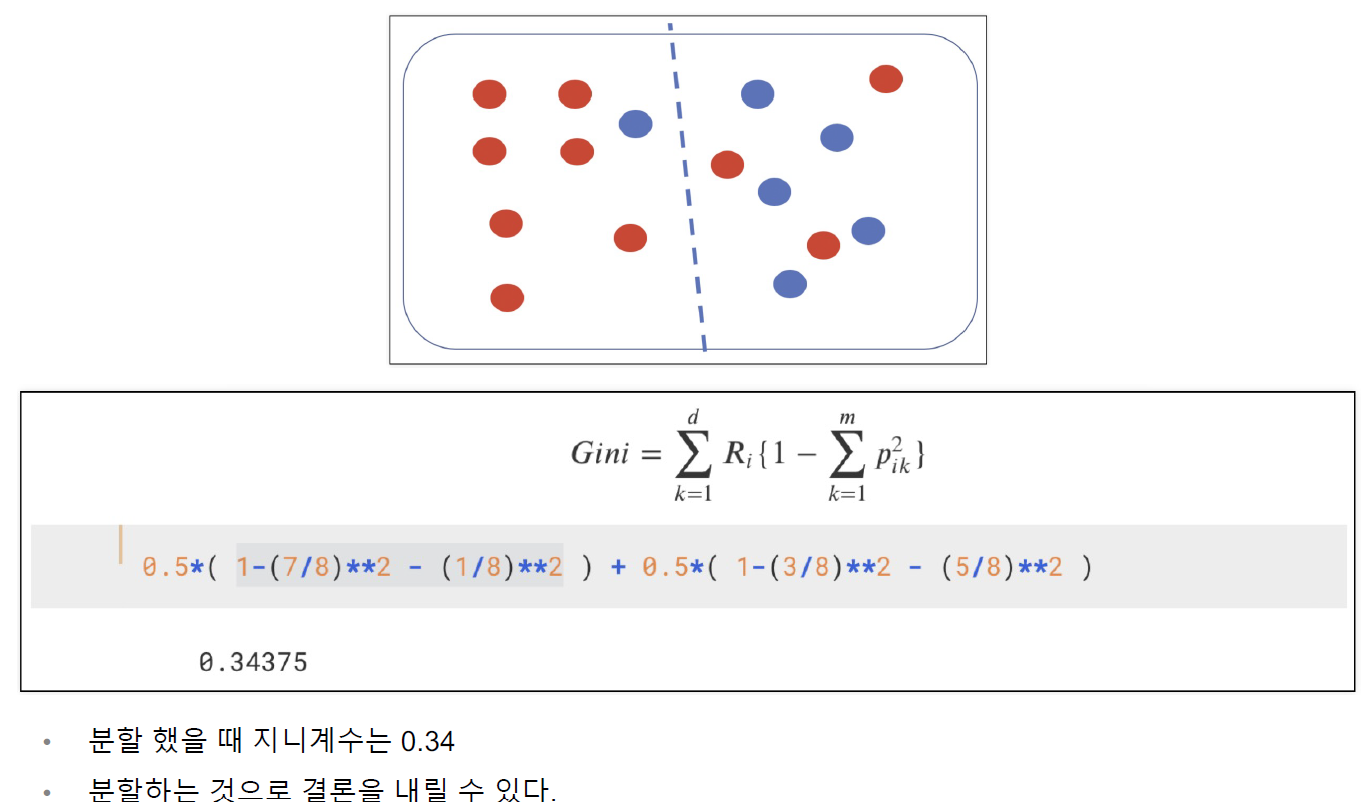
결정나무(DecisionTree)의 분할 기준_지니계수
- 분할을 통하여 계속해서 지니계수의 값을 작게 하는 것

학습한 결정나무(DecisionTree)로 정확도 측정, from sklearn.metrics import accuracy_score
from sklearn.metrics import accuracy_score
y_pred_tr = iris_tree.predict(iris.data[:, 2:])
# .predict : 데이터를 줄테니 .fit을 통해 학습한데로 예측을 해봐라
y_pred_tr
accuracy_score(iris.target, y_pred_tr)
# accuracy_score(정답데이터, 예측데이터) : 정답데이터와 예측데이터를 비교하여 정확도를 계산해달라는 명령어 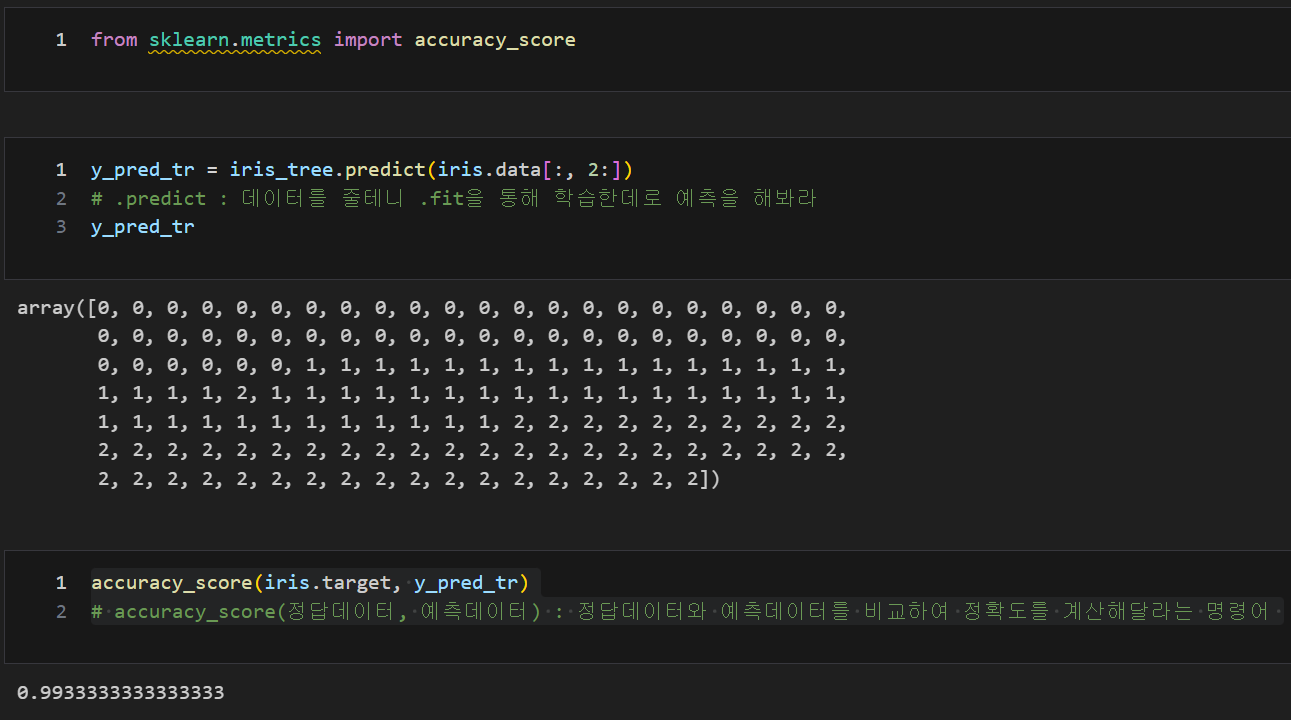
학습한 결정나무(DecisionTree) iris 품종 분류 시각화
from mlxtend.plotting import plot_decision_regions
plt.figure(figsize=(8, 8))
plot_decision_regions(X=iris.data[:, 2:], y=iris.target, clf=iris_tree, legend=2)
# clf : classifier(=분류기), 여기선 iris를 구분하기 위해 학습한 iris_tree
plt.show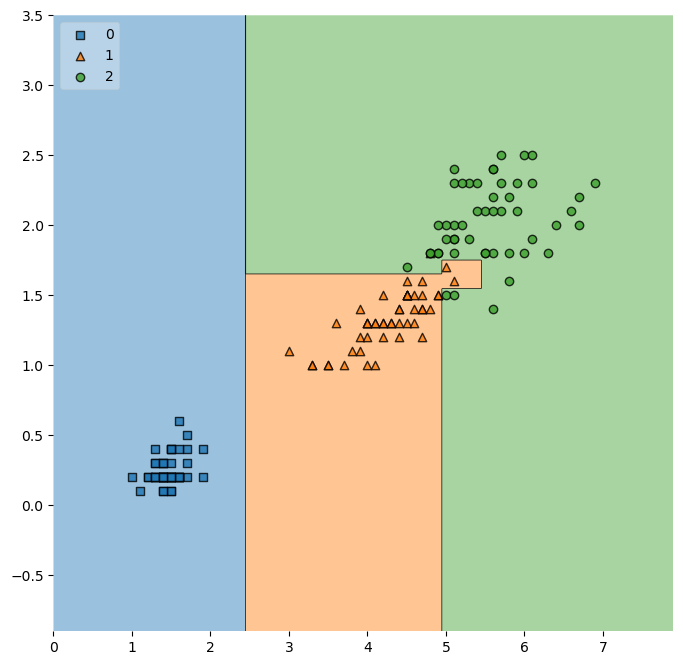
의문점과 신뢰도
- 저 경계면은 올바른 경계면인가?
- 저 결과는 내가 가진 데이터를 외 일반화가 가능한가?
과적합
- 과적합 : 내가 가지고 있는 데이터에 너무 최적화 되어(fit이 맞아버려서) 내가 가진 데이터 이외에 일반적인 데이터에서 제 성능을 못하거나 올바른 답을 내지 못하는 것
- 상기에 만들어놓은 tree들로 모든 아이리스를 정확하게 나눌 수 없다
데이터 분리
- 과적합을 극복하기 위해 데이터를 학습 및 테스트를 위하여 훈련/검증/평가로 분리

데이터를 훈련/테스트로 분리
from sklearn.model_selection import train_test_split
features = iris.data[:, 2:]
labels = iris.target
# 8:2 확률로 특성(features)과 정답(labels)을 분리
X_train, X_test, y_train, y_test = train_test_split(features, labels,
test_size=0.2,
# test_size= : 분리 기준 설정
# train : 80%, test : 20% 로 데이터 분리
stratify=labels,
# stratify= : 나눈 데이터에 labels 수를 동일한 비율로 맞춰주는 설정
random_state=13)
y_train.shape, y_test.shape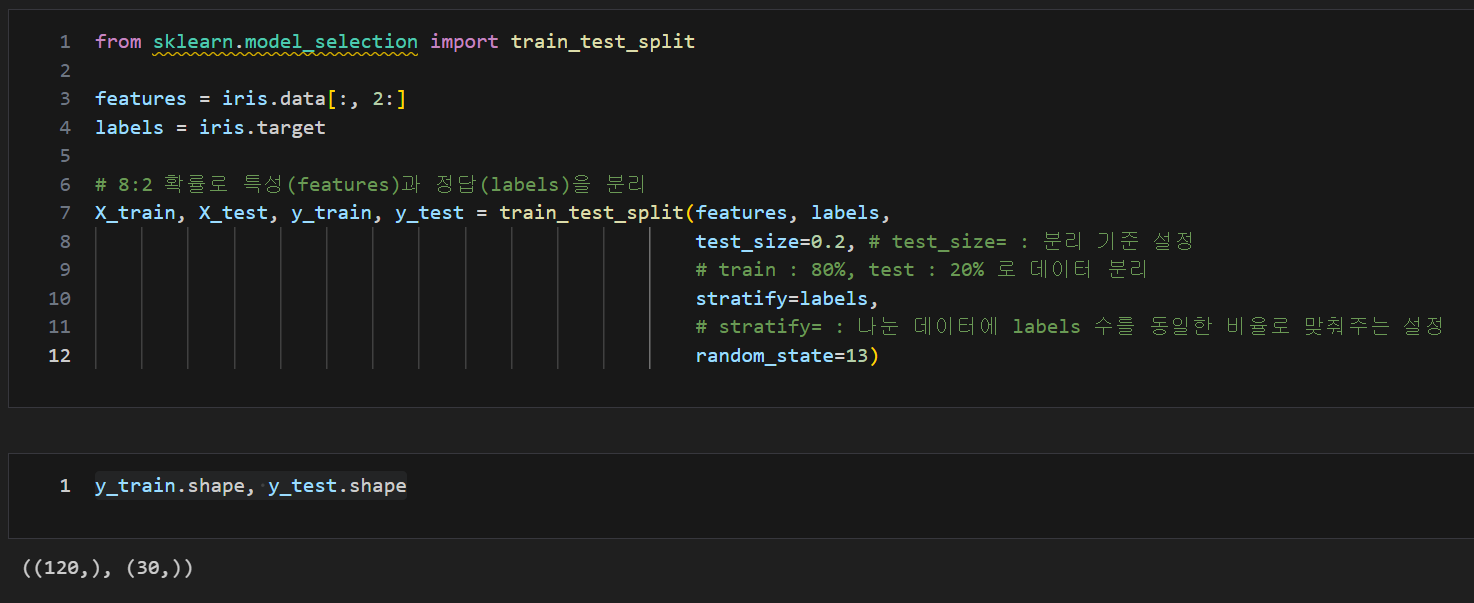
random_state : 수행시마다 동일한 결과를 얻기 위해 적용
- train_test_split(..., test_size=0.2) 과 같은 함수는 80% train, 20% test 데이터 세트를 추출
- 하지만 random_state 미설정 시 추출된 데이터는 수행을 할때마다 다르게, random하게 80%, 20%를 추출
- 이를 random_state를 통하여 80%, 20% 추출 시 동일한 데이터를 추출하기 위해 설정하는 메써드
- random_state 뒤의 숫자는 특별한 의미를 가지는 것은 아니며 지정한 숫자별로 동일한 데이터를 추출하는 기준 값으로 인식
각 클래스 별로 동일한 비율로 나누어 졌는지 확인, stratify=labels 확인
import numpy as np
# 위에서 120, 30 개로 나눈 데이터에 3가지 속성의 값들이 동일한 비율로 들어가있는지 확인,
# 비율이 동일한 것이 좋은 데이터
np.unique(y_test, return_counts=True)
train_data를 통한 결정나무(DecisionTree) 생성 및 학습 후 시각화
from sklearn.tree import DecisionTreeClassifier
iris_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
iris_tree.fit(X_train, y_train)
# 이번엔 fit에 상기에서 분리한 데이터 입력
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(8, 8))
plot_tree(iris_tree)

max_depth : decision tree의 반복할 조건 수 지정, DecisionTree의 가지 갯수
- 높게 지정할 수록 정확도는 100%에 가까워 진다
- 정확도가 높은 것은 좋으나 이 또한 과적합을 발생 할 수 있기 때문에 규제하여(max_depth를 낮게 주어=모델을 단순화하여) 모델에 제공한 트레이닝 데이터에 최적화되지 않도록 모델의 성능을 제한시켜야 한다
train_data의 accuracy 확인
- accuracy는 더 좋아짐
from sklearn.metrics import accuracy_score
y_pred_tr = iris_tree.predict(iris.data[:, 2:])
accuracy_score(iris.target, y_pred_tr)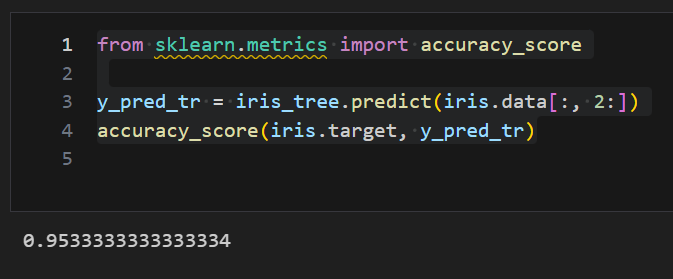
train_data의 결정경계 확인
from mlxtend.plotting import plot_decision_regions
plt.figure(figsize=(8, 8))
plot_decision_regions(X=X_train, y=y_train, clf=iris_tree, legend=2)
# clf : classifier(=분류기), 여기선 iris를 구분하기 위해 학습한 iris_tree
plt.show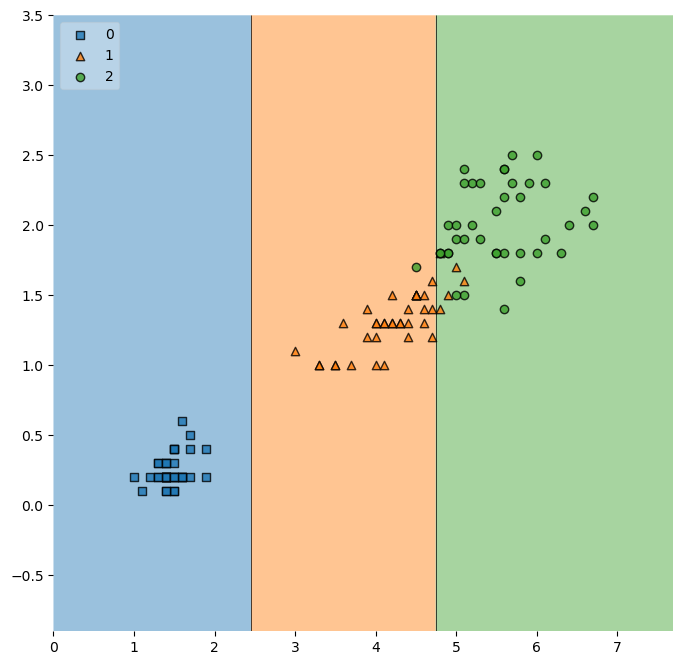
test_data accuracy
y_pred_test = iris_tree.predict(X_test)
# .predict : 데이터를 줄테니 .fit을 통해 학습한데로 예측을 해봐라
accuracy_score(y_test, y_pred_test)
# accuracy_score(정답데이터, 예측데이터) : 정답데이터와 예측데이터를 비교하여 정확도를 계산해달라는 명령어
기존과 같이 feature를 네개로 설정한 DecisionTree 설정 및 학습 후 시각화
features = iris.data
labels = iris.target
# 8:2 확률로 특성(features)과 정답(labels)을 분리
X_train, X_test, y_train, y_test = train_test_split(features, labels,
test_size=0.2, # test_size= : 분리 기준 설정
# train : 80%, test : 20% 로 데이터 분리
stratify=labels,
# stratify= : 나눈 데이터에 labels 수를 동일한 비율로 맞춰주는 설정
random_state=13)
iris_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
iris_tree.fit(X_train, y_train)
plt.figure(figsize=(8, 8))
plot_tree(iris_tree)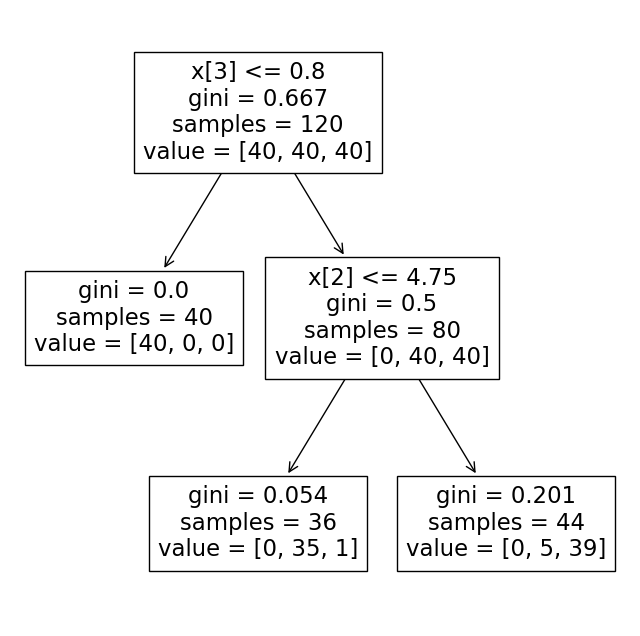
사용자가 지정한 sample 예측
test_data = np.array([[4.3, 2.0, 1.2, 1.0]])
iris_tree.predict(test_data)
iris_tree.predict_proba(test_data)
# predict_proba() : 예측된 값이 3가지 속성들 중 얼마나 비중을 차지하는지 보여주는 함수
iris.target_names[iris_tree.predict(test_data)]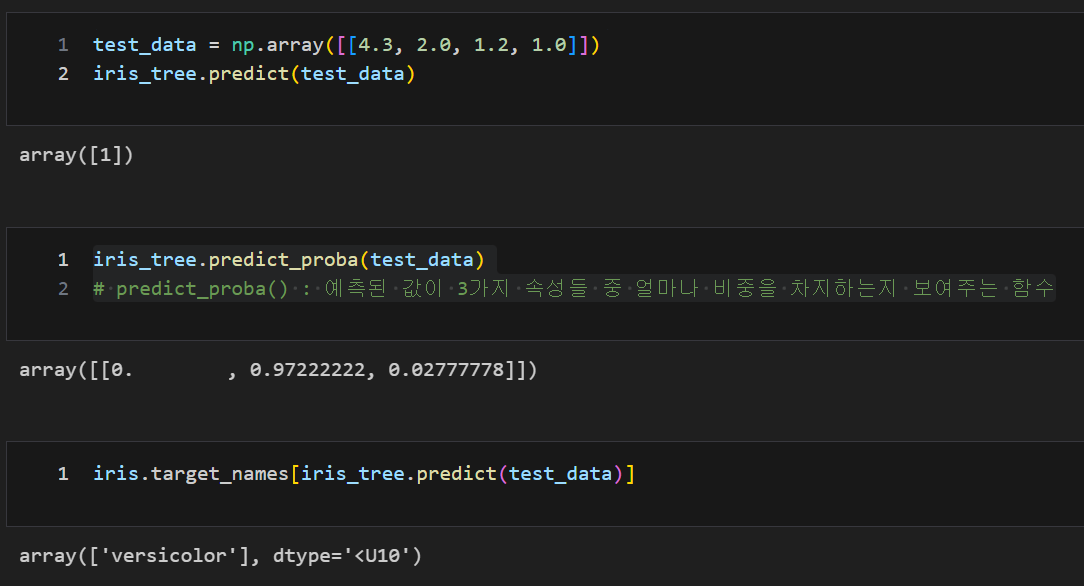
feature_importances 통한 feature 중요도 확인
- max_depth= 설정 시 모델을 결정하기 위한 중요 feature가 어떻게 나왔는지 각각의 중요도를 보여주는 메써드
iris_tree.feature_importances_
iris_clf_model = dict(zip(iris.feature_names, iris_tree.feature_importances_))
iris_clf_model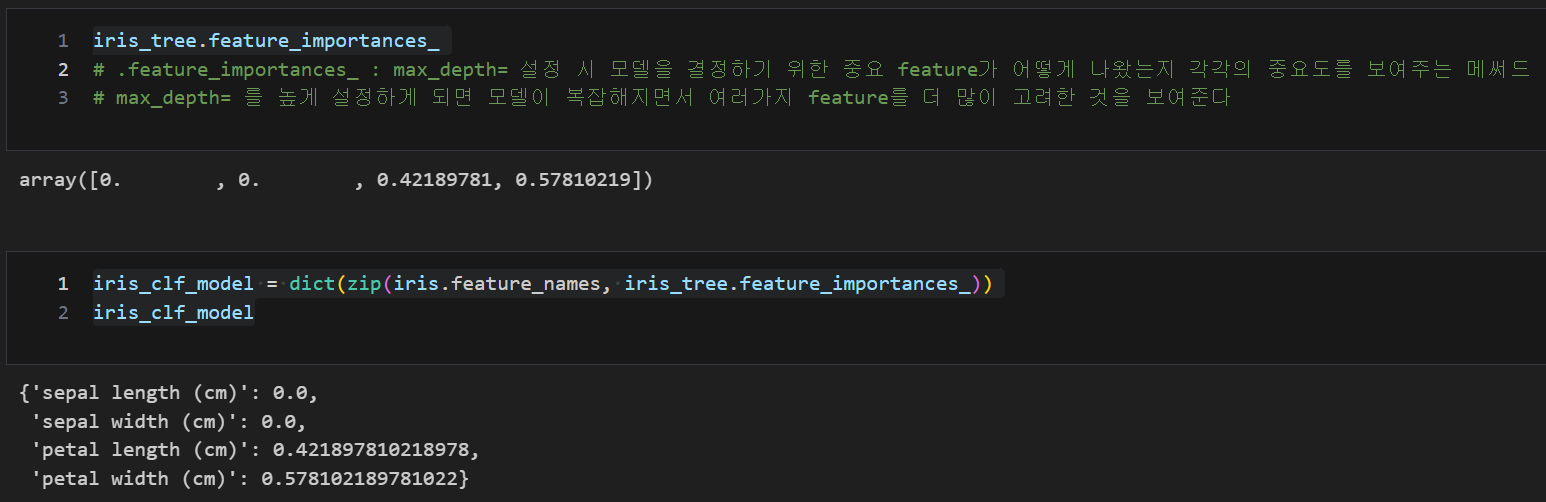
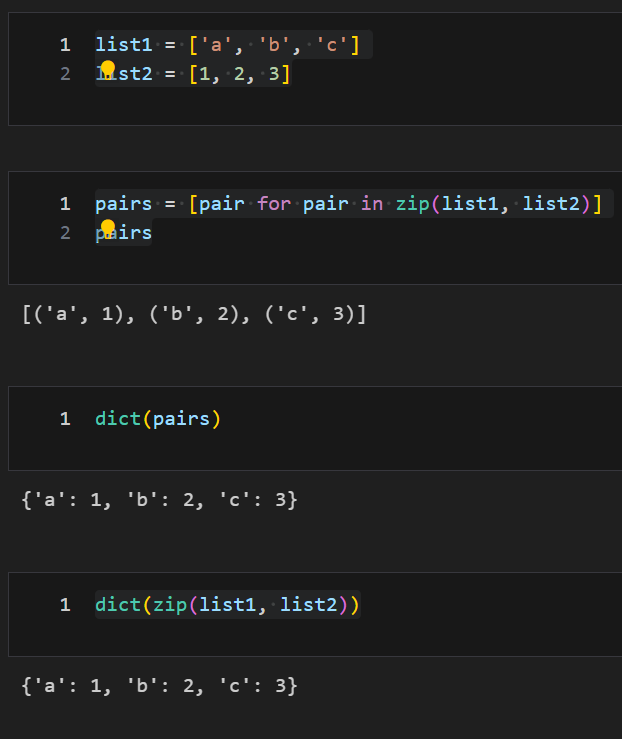
zip() : 리스트를 순서대로 묶어서 튜플 형태로 변환
list1 = ['a', 'b', 'c']
list2 = [1, 2, 3]
pairs = [pair for pair in zip(list1, list2)]
pairs
dict(pairs)
dict(zip(list1, list2))
unpack => ' * ' 을 통한 역변환
x, y = zip(*pairs)
x
list(x)
y
list(y)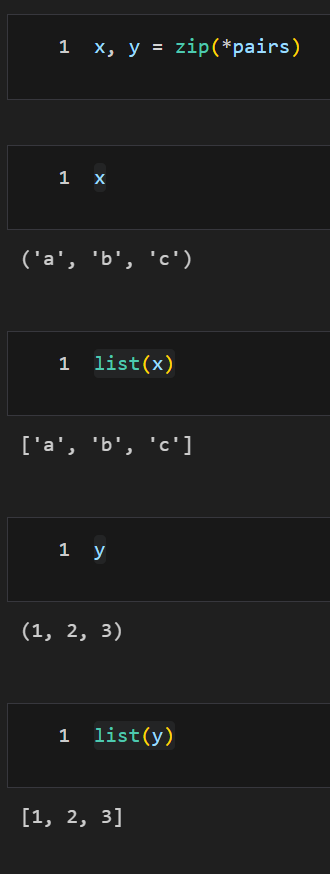

비전공 데이터 분석가 도전