KMeans 클러스터링 알고리즘은 n개의 중심점을 찍은 후에, 이 중심점에서 각 점간의 거리의 합이 가장 최소화가 되는 중심점 n의 위치를 찾고, 이 중심점에서 가까운 점들을 중심점을 기준으로 묶는 클러스터링 알고리즘이다.
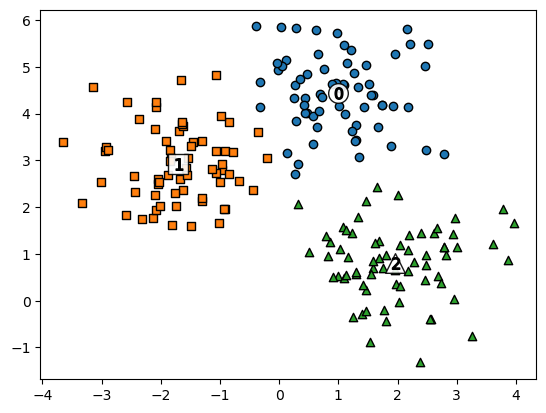
아래 그림을 보면 3개의 군집이 존재하는 것을 볼 수 있다. 각 군집별로 중심점이 찍혀 있는데, 이 중심점의 위치를 움직여 가면서 각 군집의 데이타와 중심점의 거리가 가장 작은 중심점을 찾는 것이다.
먼저 Iris 데이타를 로딩해보자
from sklearn.preprocessing import scale
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
iris =load_iris()
iris_df = pd.DataFrame(data=iris.data,columns=iris.feature_names)데이타를 로딩한 후에, 이 예제에서는 두개의 속성만 사용해서 분류하기로 해보자. “Sepal length”와 “Sepal width” 컬럼 두개만 추출하여 학습용 feature라는 데이타 프레임으로 학습용 데이타를 만든다. Iris 데이타는 skearn.datasets에 들어있고 이를 로딩하려면 iris = datasets.load_iris()를 하면 로딩이 된다.
데이타는 로딩된 iris 데이타의 iris.data 필드에 들어가 있고, label은 iris.labels 컬럼에 들어가 있다.
## kmeans
kmeans = KMeans(n_clusters=3,init='k-means++',max_iter=300,random_state=0)
# 붓꽃 데이이터 에 군집화
kmeans.fit(iris_df)
print(kmeans.labels_)
iris_df['cluster'] = kmeans.labels_
iris_df['target'] = iris.target
iris_result = iris_df.groupby(['target','cluster'])['sepal length (cm)'].count()
print(iris_result)iris의 features 를 pca를 통해 차원을 축소하여 그 주성분2 개를 변수로하여 군집했을때 확인해 보았습니다.
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca_transformed = pca.fit_transform(iris.data)
iris_df['pca_x'] = pca_transformed[:,0]
iris_df['pca_y'] = pca_transformed[:,1]
iris_df.head(3)sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) cluster target pca_x pca_y
0 5.1 3.5 1.4 0.2 1 0 -2.684126 0.319397
1 4.9 3.0 1.4 0.2 1 0 -2.714142 -0.177001
2 4.7 3.2 1.3 0.2 1 0 -2.888991 -0.144949## cluster 값에 대한 시각화
mk0_ind = iris_df[iris_df['cluster']==0].index
mk1_ind = iris_df[iris_df['cluster']==1].index
mk2_ind = iris_df[iris_df['cluster']==2].index
plt.subplot(2,1,1)
plt.scatter(x=iris_df.loc[mk0_ind,'pca_x'],y=iris_df.loc[mk0_ind,'pca_y'],marker='o')
plt.scatter(x=iris_df.loc[mk1_ind,'pca_x'],y=iris_df.loc[mk1_ind,'pca_y'],marker='x')
plt.scatter(x=iris_df.loc[mk2_ind,'pca_x'],y=iris_df.loc[mk2_ind,'pca_y'],marker='s')
plt.xlabel('pca_1')
plt.ylabel('pca_2')
plt.title('3 clusters visualization by 2 pca components')
plt.show()
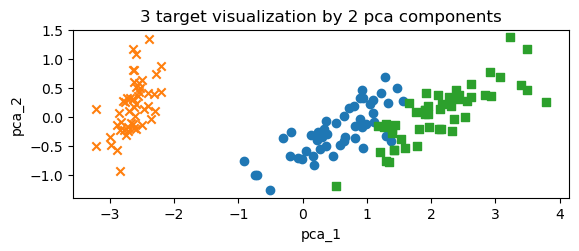
## target 값에 대한 시각화
mk0_ind = iris_df[iris_df['target']==1].index
mk1_ind = iris_df[iris_df['target']==0].index
mk2_ind = iris_df[iris_df['target']==2].index
plt.subplot(2,1,2)
plt.scatter(x=iris_df.loc[mk0_ind,'pca_x'],y=iris_df.loc[mk0_ind,'pca_y'],marker='o')
plt.scatter(x=iris_df.loc[mk1_ind,'pca_x'],y=iris_df.loc[mk1_ind,'pca_y'],marker='x')
plt.scatter(x=iris_df.loc[mk2_ind,'pca_x'],y=iris_df.loc[mk2_ind,'pca_y'],marker='s')
plt.xlabel('pca_1')
plt.ylabel('pca_2')
plt.title('3 target visualization by 2 pca components')
plt.show()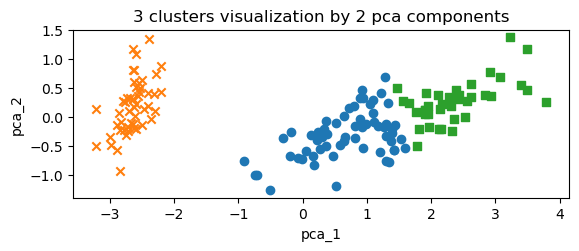
clustering 알고리즘을 테스트하기 위한 데이터를 생성하겠습니다
sklearn에 있는 make_blobs를 통하여 클러스터링할 데이터 생성
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
# 클러스터링할 데이터 생성 - make_blobs (생성할 데이터 200개 피쳐 갯수 2개 군집개수 3개, 데이터 표준편차0.8)
x,y = make_blobs(n_samples=200,n_features=2,centers=3, cluster_std=0.8,random_state=0)
print(x.shape,y.shape)
cluster_df = pd.DataFrame(data=x, columns=['ftr1','ftr2'])
cluster_df['target']= y make_blobs로 만들어진 데이터 시각화
3개의 cluster 영역으로 구분한 데이터 셋을 생성했으므로 target_list는 [0,1,2]
target==0,target==1,target==3로 scatterplot 을 marker별로 생성
target_list = np.unique(y)
# 각 target별 scatter_plot 의 marker 값
markers= ['o','s','^','P','D','H','x']
for target in target_list:
target_cluster = cluster_df[cluster_df['target']==target]
plt.scatter(x=target_cluster['ftr1'],y=target_cluster['ftr2'],
edgecolors='k',marker=markers[target])
plt.show()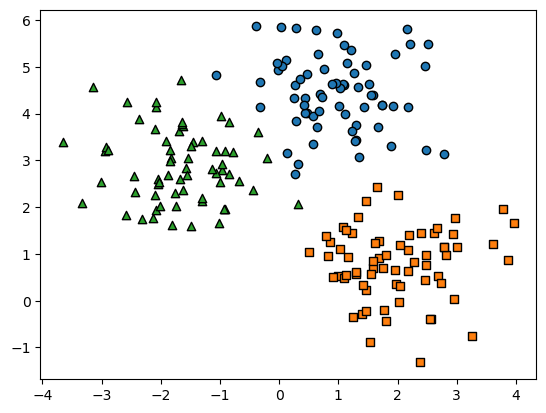
## k-means 군집화 수행하고 개별 클러스터의 군집 중심 시각화
# kmeas 객체를 이용하여 x데이터를 k-means 클러스터링 수행
kmeans = KMeans(n_clusters=3,max_iter=200,random_state=0)
cluster_labels = kmeans.fit_predict(x)
cluster_df['kmeans_label']= cluster_labels
# cluster centers 는 개별 클러스터의 중심 위치 좌표 시각화를 위해 추출
centers = kmeans.cluster_centers_
unique_labels = np.unique(cluster_labels)
markers= ['o','s','^','P','D','H','x']
# 군집된 label유형별러 iteration 하면서 marker 별로 scatter plot 수행
for label in unique_labels:
label_cluster = cluster_df[cluster_df['kmeans_label']==label]
center_x_y = centers[label]
plt.scatter(x = label_cluster['ftr1'],y=label_cluster['ftr2'],edgecolor='k',
marker=markers[label])
# 군집별 중심 위치 좌표 시각화
plt.scatter(x=center_x_y[0], y=center_x_y[1],s=200,color='white',
alpha=0.9,edgecolors='k',marker=markers[label])
plt.scatter(x=center_x_y[0], y=center_x_y[1],s=70,color='k',
edgecolors='k',marker='$%d$' % label)
plt.show()