
오늘 인공지능 수업에서 들었던 것을 정리하겠다.
영상인식이란?

그림으로 된 정보를 컴퓨터를 이용하여 처리하는 일을 말한다. 고도의 그래픽 기술과 함께 인공지능적인 요소가 필수적으로 포함되어야 하는 분야이다.
OpenCv란?

OpenCV는 Open Source Computer Vision의 약자로 영상 처리에 사용할 수 있는 오픈 소스 라이브러리 입니다.
컴퓨터가 사람의 눈처럼 인식할 수 있게 처리해주는 역할을 하기도 하며, 우리가 많이 사용하는 카메라 어플에서도 OpenCV가 사용하기도 한다
사용되는 예로는
- 공장에서 제품 검사할 때
- 의료 영상 처리 및 보정 그리고 판단
- CCTV영상
- 로보틱스
등이 있다고 한다.
가상환경 만들기

일단 가상환경을 만들기 위한 아나콘다를 설치해준다.
아나콘다를 다운받은 후에 conda -v를 쳐서 conda가 깔렸는지 확인을 해주고
그 후에 가상환경을 만들어줄 것이다.
conda create -n 환경이름 python=3.11
그 후 가상환경을 사용하기 위해서는
conda activate opencv
위 처럼 작성하면 된다.
(가상환경에서 나가기 위해서는 activate말고 deactivate를 사용하면 된다)
가상환경 주피터 노트북에 커널 연결하기
먼저 ipykernel을 깔아주기 위해서
pip install ipykernel을 해준다.
그 후에 python -m ipykernel install --user --name 가상환경이름 --display-name "커널출력이름"이라는 코드를 작성해서 커널을 만들어준 뒤에
pip install jupyter notebook 주피터 노트북을 설치해주고,
jupyter notebook으로 서버를 켜서 주피터 노트북을 사용해주면 된다.
 서버를 키면
서버를 키면 http://localhost:8888/tree이라는 로컬호스트 서버가 열리게 된다.
간단한 주피터 노트북 단축키
OpenCv입문
 간단하게 OpenCv입문을 해보자!
간단하게 OpenCv입문을 해보자!
기초 이론부분까지 서술하면 글이 너무 길어지기에 실습한 부분만 적도록 하겠다.
이미지 불러오기
import cv2 # 패키지 로드
img = cv2.imread('data/cat2.jpg') # 이미지 파일을 이미지 객체로 저장
cv2.imshow('image', img) # 이미지 객체를 image라고 하는 윈동창에 띄움
cv2.waitKey() # 키가 눌릴때까지 무한히 기다림
cv2.destroyAllWindows() # 모든 윈도우 창을 꺼버림위처럼 코드를 작성하게 되면
 위처럼 사진이 나오게 된다.
위처럼 사진이 나오게 된다.
흑백으로 바꾸기
import cv2
img = cv2.imread('data/Dog.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 트루컬러를 그레이스케일로 변경
cv2.imshow('image', gray)
cv2.waitKey()
cv2.destroyAllWindows()
동영상 처리
동영상을 읽고 출력
import cv2
cap = cv2.VideoCapture(0) # 인덱스번호로 연결된 소스를 객체로 선언 (웹캠 0번) (웹캠아니면 비디오 소스 넣기)
print(cap.isOpened()) # 소스가 열리는지 확인
while(cap.isOpened()): # 소스가 열리는 동안
ret, frame = cap.read() # 소스로부터 이미지 객체 추출, ret: 성공여부 frame: 이미지 객체
if ret : # 성공했다면
cv2.imshow('frame', frame) # 이미지객체를 frame이라는 윈도우 출력
if cv2.waitKey(1) & 0xFF == ord('q'): # Q키를 누르면 break
break
else: # 소스에서부터 이미지 불러오는 것이 실패했다면
break # 탈출
cap.release() # 소스초기화
cv2.destroyAllWindows() # 윈도우창 종료위처럼 코드를 작성하게 되면 웹캠이 열리게 되는데 캠이 없어서 이런식으로 나온다.
동영상 쓰기
import cv2
cap = cv2.VideoCapture(0)
fourcc = cv2.VideoWriter_fourcc(*'XVID')
out = cv2.VideoWriter('output.avi', fourcc, 20.0, (640,480))
print(cap.isOpened())
while(cap.isOpened()):
ret, frame = cap.read()
if ret == True:
out.write(frame)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imshow('frame', gray)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
else:
break
cap.release()
out.release()
cv2.destroyAllWindows()
동영상에 문자넣고 시간 넣기
import cv2
import datetime
cap = cv2.VideoCapture(0)
print(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
print(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
#cap.set(3, 1208) #width
#cap.set(4, 720) #height
#print(cap.get(3))
#print(cap.get(4))
while(cap.isOpened()):
ret, frame = cap.read()
if ret :
font = cv2.FONT_HERSHEY_SIMPLEX # 폰트
text = 'Width: ' + str(cap.get(3)) + ' Height: ' + str(cap.get(4)) # 각각 너비 높이
datet = str(datetime.datetime.now()) # 현재 시간
frame = cv2.putText(frame, datet, (10,50), font, 1, (0,255,255), 2, cv2.LINE_AA)
# 글자 출력
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
else:
break
cap.release()
cv2.destroyAllWindows()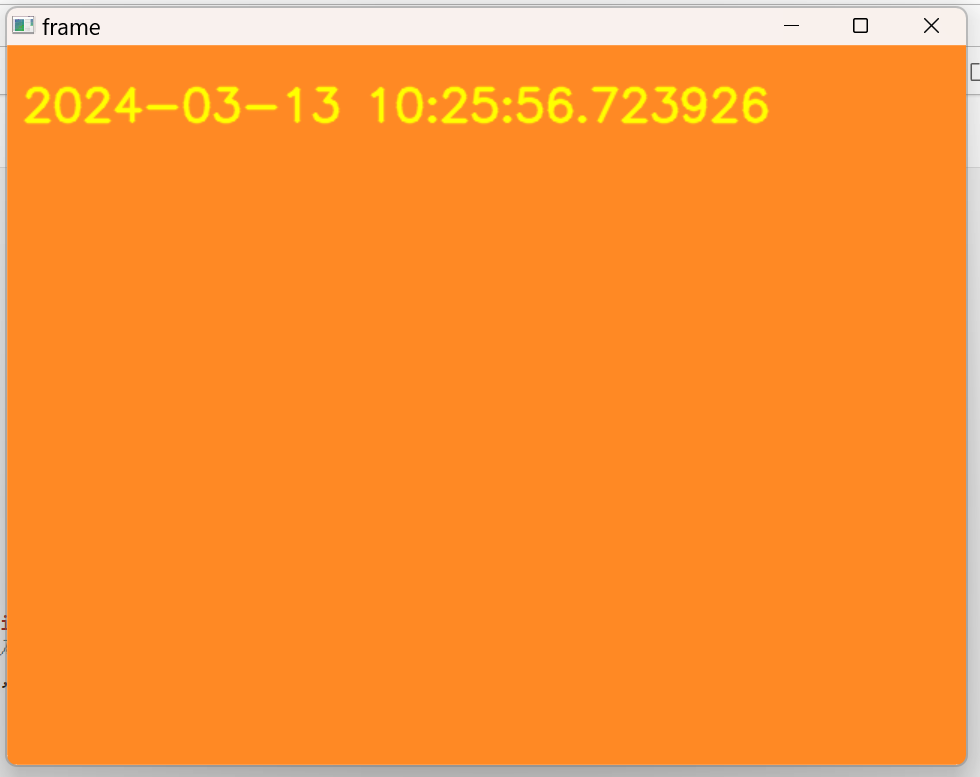
사각형 그리기
import cv2
import numpy as np
img = np.zeros((250,500,3), np.uint8) # 0으로된 텐서 생성, (행, 열, 뎁스)
img = cv2.rectangle(img, (200, 0), (300, 100), (255, 255, 255), -1)
# opencv의 좌표는 (x, y) numpy에서는 좌표가 아니고 (행, 열)
cv2.imshow('img', img)
cv2.waitKey()
cv2.destroyAllWindows()
다양한 도형 그리기
import numpy as np
import cv2
img = cv2.imread('data/lena.jpg', 1)
img = np.zeros([512, 512, 3], np.uint8)
img = cv2.line(img, (0,0), (255,255), (147, 96, 44), 10) # 44, 96, 147
img = cv2.arrowedLine(img, (0,255), (255,255), (255, 0, 0), 10)
img = cv2.rectangle(img, (384, 0), (510, 128), (0, 0, 255), 10)
img = cv2.circle(img, (447, 63), 63, (0, 255, 0), -1)
font = cv2.FONT_HERSHEY_SIMPLEX
img = cv2.putText(img, 'OpenCv', (10, 500), font, 4, (0, 255, 255), 10, cv2.LINE_AA)
img = cv2.ellipse(img,(256,256),(100,50),0,0,180,255,-1)
pts = np.array([[10,5],[20,30],[70,20],[50,10]], np.int32)
pts = pts.reshape((-1,1,2))
img = cv2.polylines(img,[pts],True,(0,255,255))
cv2.imshow('image', img)
cv2.imwrite('save.jpg',img)
cv2.waitKey(0)
cv2.destroyAllWindows() 
처리한 이미지 저장하기
cv2.imwrite('grayDog.jpg', img)이런식으로 저장해줄 수 있다.
저장 위치를 지정하고 싶다면 파일명앞에 경로를 지정해준다.
퀴즈
1번째 퀴즈
이미지를 불러오는데 제목을 이미지 오른쪽 상단에 넣기!
import cv2 # 패키지 로드
img = cv2.imread('data/cat2.jpg') # 이미지 파일을 이미지 객체로 저장
font = cv2.FONT_HERSHEY_SIMPLEX # 폰트
text = 'middle2disease'
img = cv2.putText(img, text, (350,50), font, 1, (0,255,255), 2, cv2.LINE_AA)
cv2.imshow('image', img) # 이미지 객체를 image라고 하는 윈동창에 띄움
cv2.waitKey() # 키가 눌릴때까지 무한히 기다림
cv2.destroyAllWindows() # 모든 윈도우 창을 꺼버림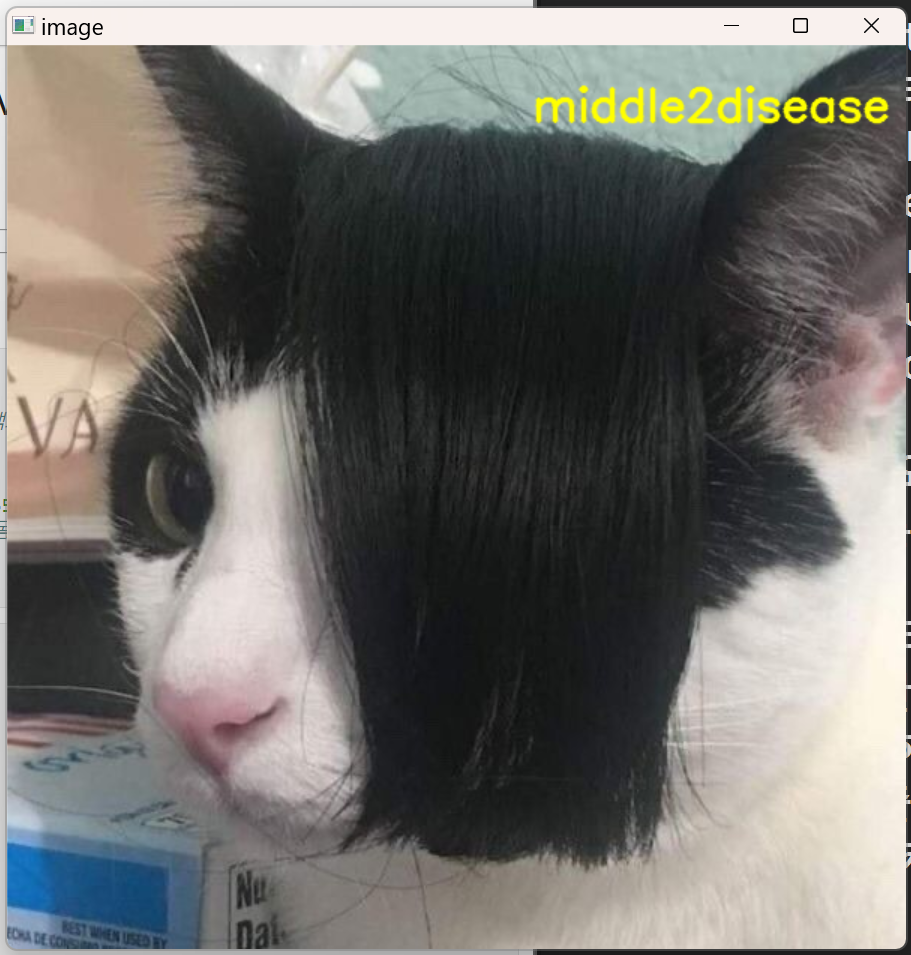
2번째 퀴즈
웹캠 영상을 불러오는데
웹캠 영상 왼쪽상단에 HADURI라고 출력
웹캠 영상 오른쪽 하단의 본인 영어이름 출력
출력될 때 컬러로 출력되지만, 녹화본은 그레이스케일로 녹화
import cv2
import datetime
# videoRef = 'data/Megamind.avi'
videoRef = 0
cap = cv2.VideoCapture(videoRef)
print(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
print(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
#cap.set(3, 1208) #width
#cap.set(4, 720) #height
#print(cap.get(3))
#print(cap.get(4))
while(cap.isOpened()):
ret, frame = cap.read()
if ret :
if videoRef != 0 : frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
font = cv2.FONT_HERSHEY_SIMPLEX # 폰트
text1 = 'HADURI'
text2 = 'HwangHyunMin'
frame = cv2.putText(frame, text1, (10,30), font, 1, (0,255,255), 2, cv2.LINE_AA)
frame = cv2.putText(frame, text2, (400,450), font, 1, (0,255,255), 2, cv2.LINE_AA)
# 글자 출력
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
else:
break
cap.release()
cv2.destroyAllWindows()웹캠일 때
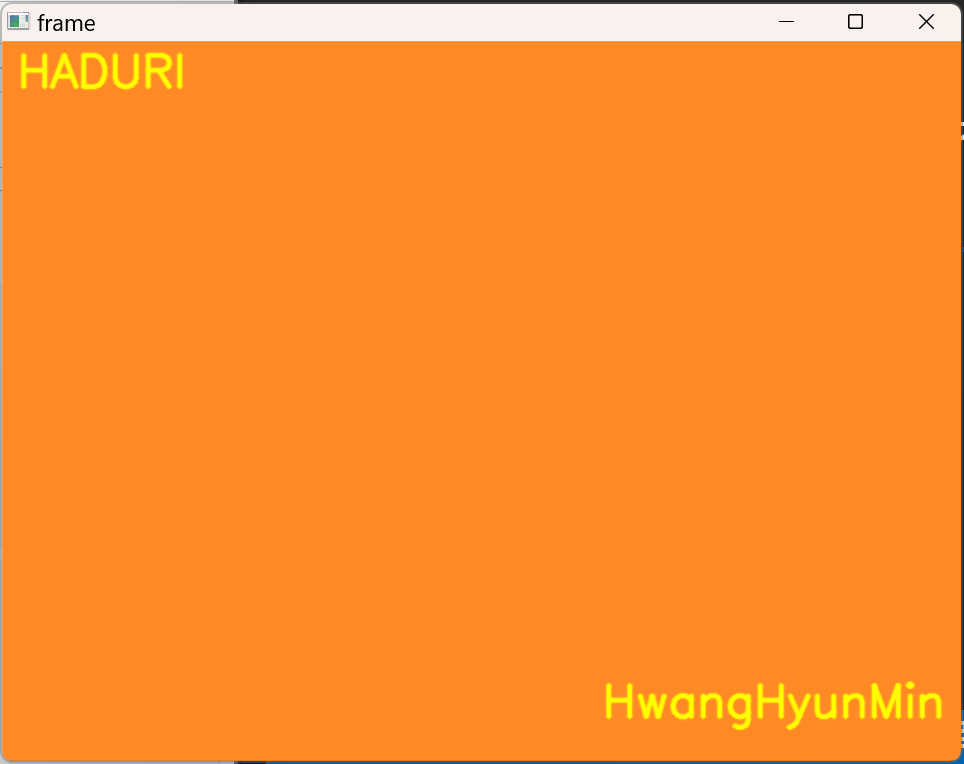
동영상일 때
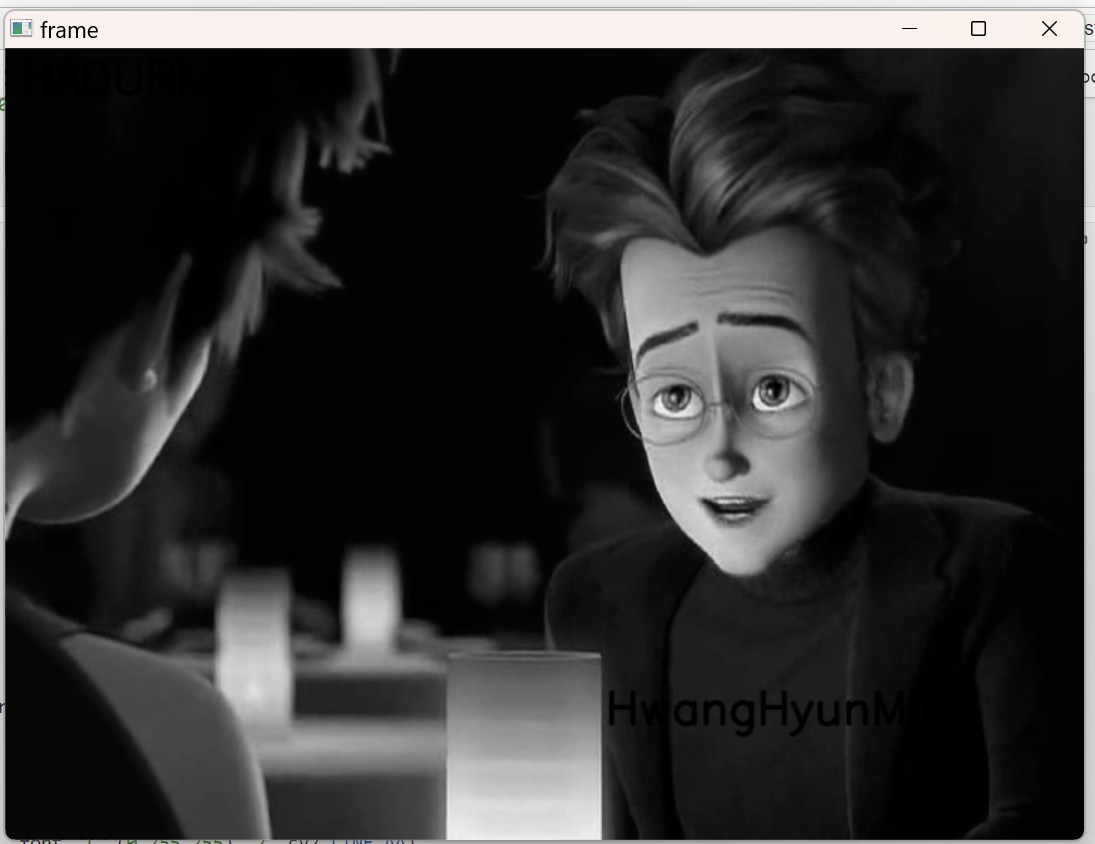
굿!

너무 잘된다.
