코딩테스트를 대비한 알고리즘 포스팅 해시(Hash)편은 여기 참고 !
코딩테스트를 대비한 알고리즘 포스팅 스택/큐(Stack/Queue)편은 여기 참고 !
🐼 힙이란 ?
세번째로 정리할 알고리즘인 힙(Heap)은 최대/최소값을 찾는데 최적화된 자료구조이다. 힙은 기본적으로 완전 이진트리 구조를 가지고 있으며, 이 노드들 중 키 값이 가장 큰 노드를 찾거나 키 값이 가장 작은 노드를 찾을 때 활용한다. 또한 힙은 데이터의 중복을 허용한다.
완전 이진트리란 ?
- 이진 트리의 각 노드들은 기본적으로 둘 이하(0,1,2개)의 자식 노드를 갖는다.
- 이 중 완전 이진트리란 마지막 레벨을 제외하고 모든 레벨이 완전히 채워져 있는 트리이다.
- 마지막 레벨은 꽉 차 있지 않아도 되지만, 노드가 왼쪽 노드부터 채워져야한다. (왼쪽을 채우지 않고 오른쪽을 먼저 채운 트리는 완전 이진 트리가 아님)
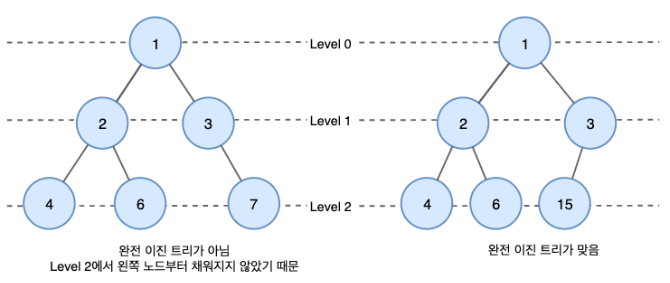
더 자세한 트리의 종류에 대해 알고 싶다면 이 블로그를 참고하자 !
우선순위 큐(Priority Queue)
일반적인 큐(Queue)의 자료구조는 지난 포스팅에서 언급했듯이 FIFO(선입선출)구조이다.
일반적인 큐가 먼저 들어온 데이터를 먼저 처리하는 구조하면, 우선순위 큐는 우선순위에 따라 우선순위가 높은 데이터를 먼저 처리하는 구조 !
4, 6, 3, 1, 2순으로 데이터가 들어오고 각각의 숫자를 우선순위라 할 때1) 4가 큐에 들어옴. 4가 현재 큐에서 우선순위가 제일 높음 2) 6이 큐에 들어옴. 6은 4보다 우선순위가 높으므로 6,4 순서로 정렬 3) 3이 큐에 들어옴. 3은 앞에 있는 두 데이터보다 우선순위가 낮으므로 변화 X 4) 1이 큐에 들어옴. 1도 앞에 있는 세 데이터보다 우선순위가 낮으므로 변화 X 5) 2가 큐에 들어옴. 2는 1보다 우선순위가 크므로 자리 교체이렇게 우선 순위를 고려하는 큐에 데이터를 삽입하면 결과적으로
[6,5,4,3,2,1]의 정렬된 리스트를 얻게 되고 이를 순서대로 처리할 경우 우선순위에 맞게 데이터를 처리하는 것이 된다.
데이터 하나가 들어올 때마다 정렬이 이루어져야 하므로 삽입하는 데이터에 따라 뒤에 위치하게 될 데이터들을 모두 한 칸씩 밀어야 하는 비효율성이 발생하거나, 최악의 경우 삽입해야 하는 위치를 찾기 위해 모든 인덱스를 탐색해야 하므로 데이터가 n개면 O(n)의 시간복잡도를 갖는다.
이런 단점들을 보완하기 위해 우선순위 큐를 구현할 때는 힙(Heap) 자료구조를 사용하는 것이다 !
| 우선 순위 큐를 구현하는 방법 | 삽입 시간 복잡도 | 삭제 시간 복잡도 |
|---|---|---|
| 순서 없는 배열 | O(1) | O(N) |
| 순서 없는 연결 리스트 | O(1) | O(N) |
| 정렬된 배열 | O(N) | O(1) |
| 정렬된 연결 리스트 | O(N) | O(1) |
| 힙(heap) | O(logN) | O(logN) |
최대 힙(Max Heap)
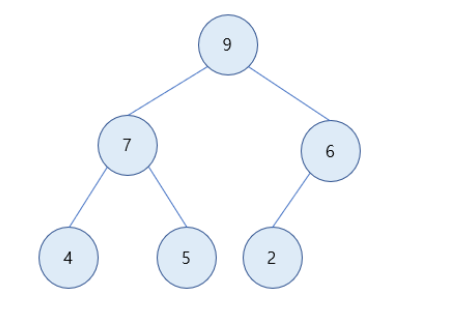
최대 힙은 부모노드의 키 값이 자식노드의 키 값보다 크거나 같은 완전 이진트리이다. 즉, 루트노드가 가장 큰 값을 가지고 부모노드가 항상 자식노드보다 값이 크거나 같다.
최소 힙(Min Heap)
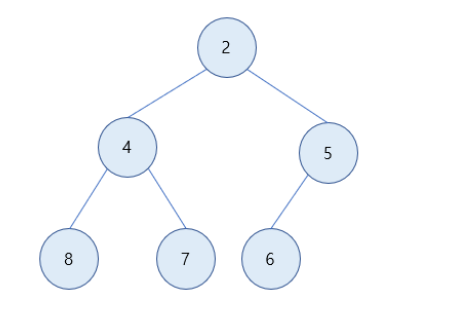
최소 힙은 부모노드의 키 값이 자식노드의 키 값보다 작거나 같은 완전 이진트리이다. 즉, 루트노트가 가장 작은 값을 가지고 부모노드가 항상 자식노드보다 값이 작거나 같다.
✏️ python에서 힙을 구현하는 방식: heapq
힙 자료구조는 우선순위 큐를 구현하기 위해 사용하는 자료구조 중 하나인데, 파이썬에서는 우선순위 큐를 구현할 수 있는 라이브러리로 PriorityQueue와 heapq를 제공한다. 일반적으로 heapq가 더 빠르게 동작하기 때문에 수행시간이 제한된 상황에서는 heapq를 사용한다. (heapq는 느슨한 정렬, PriorityQueue는 완벽한 정렬 유지)
힙을 사용하면 좋은 경우 !
- 우선순위 큐
힙 기본연산
-
탐색
peek(): 가장 위에 있는 원소를 읽어 반환한다.(삭제X) -
삽입
push(): 원소를 추가한다.
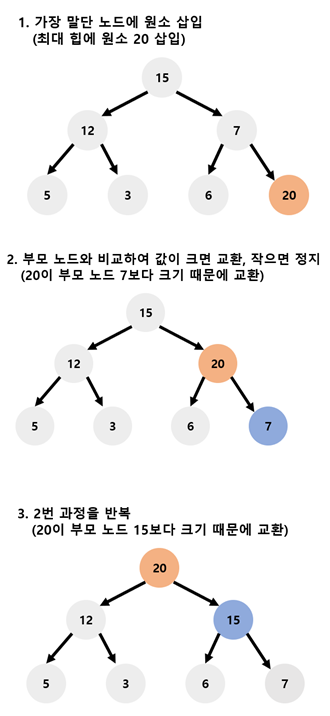
힙에 원소를 삽입 시 언제나 가장 말단노드에 삽입한다. 그 후 가장 말단노드부터 부모노드와 값을 비교하면서 힙 조건을 만족하는지 확인한다. 따라서 원소를 추가하는 연산은 O(1)이지만, 이를 다시 힙의 조건을 만족시키기 위한 힙의 재구조화에 O(log n)의 시간복잡도가 발생한다.
최대 힙일 경우 아래 그림과 같다.
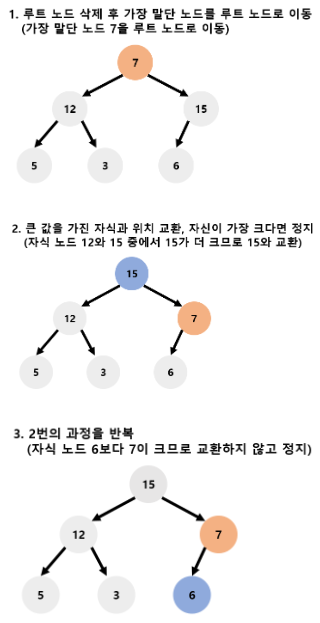
- 삭제
pop(): 가장 위에 있는 원소를 삭제하고 그 원소를 반환한다.
힙의 삭제 연산은 언제나 루트노드에 있는 원소를 삭제해 반환한다. 따라서 루트노드를 삭제하는 연산은 O(1)이지만, 이를 다시 힙의 조건을 만족시키기 위한 힙의 재구조화에 O(log n)의 시간복잡도가 발생한다.
최대 힙일 경우 아래 그림과 같다.
heapq으로 힙을 구현하는 방법
파이썬에서는 힙을 heapq로 구현한다. 파이썬에서 heapq는 기본적으로 최소 힙이다.
import heapq as h
a = [] # 빈 리스트 생성
h.heappush(a,2) #push
h.heappush(a,4)
h.heappush(a,5)
h.heappush(a,8)
h.heappush(a,7)
h.heappush(a,6)
print(a)
h.heappush(a,1)
print(a)
h.heappop(a) # pop -> 1
print(a) [2, 4, 5, 8, 7, 6]
[1, 4, 2, 8, 7, 6, 5]
[2, 4, 5, 8, 7, 6]push와 pop 외에도 기존 리스트를 힙으로 변환할 수 있다.
import heapq as h
a2 = [8, 6, 7, 5, 2, 4]
h.heapify(a2)
print(a2)[2, 4, 5, 8, 7, 6]
파이썬에서 최대 힙을 구현하는 방법
파이썬의 heapq 라이브러리에서는 최대 힙을 제공하지 않는다. 따라서 다음과 같이 부호를 변경해서 최소 힙을 구현한 다음에 최솟값부터 pop을 해줄때 다시 부호를 변경해주면 최대 힙과 동일하게 구현을 할 수 있다.
import heapq
heap = []
values = [1,5,3,2,4]
# 아래 for문을 실행시키고 나면 heap은 [-5,-4,-3,-1,-2]가 된다.
for value in values:
heapq.heappush(heap, -value)
# 아래 for문을 실행시키면 5,4,3,2,1이 출력된다. 즉, 큰 숫자부터 출력이 된다.
for i in range(5):
print(-heapq.heappop(heap))해당 포스팅을 작성하는데 참고한 블로그
힙 알고리즘을 활용한 코딩테스트 문제 풀이
