[논문 리뷰] Continuous Learning for Android Malware Detection
안녕하세요. 오늘 리뷰할 논문은 Continuous Learning for Android Malware입니다.
제목에서 알 수 있듯이 Continous 즉, 지속할수 있는 훈련에 관한 논문입니다.
시간이 지남에 따라 기존에 학습된 모델의 입력 데이터 분포와 출력 데이터 분포가 변하는 현상 즉, Concept drift 현상이 발생 할 수 밖에 없습니다.
예를들어, 악성 프로그램에 대응하기 위해 2023년에 랜섬웨어 관련된 데이터를 기존 모델에 입력 했다고 가정하겠습니다.
하지만 2024년의 랜섬웨어는 공격자가 최대한 Normal data처럼 보이도록 정교한 조작을 할 것입니다.
그렇기 때문에 2023년의 랜섬웨어 분포와 2024년의 랜섬웨어 분포는 다를 것입니다.
이렇게 시간이 지남에 따라 분포에 변화가 있는 sample을 drifting sample이라고 부릅니다.
그럼 drifting sample을 select 하였다면 이러한 drifting sample들은 어디에 사용할까요?
Active Learning에 사용하게 됩니다.
Active Learning이 필요한 이유는,
예를들어 10,000개의 데이터가 들어왔을 때 그 모든 것을 사람이 직접 labeling 하기엔 현실적으로 무리가 있습니다.
그래서 기존 모델의 입장에서 그 중 가장 drifting(uncertain)한 sample을 추려내어 score을 매겨 상위 100개 정도의 샘플만을 사람에게 전달
합니다.
10,000개는 사람이 직접 labeling하기엔 상당히 부담스러웠지만 100개 정도면 직관적으로 생각해도 부담이 훨씬 덜 할 것입니다.
기존에 있던 논문에서는 real-world 환경에 적합하지 않았습니다.
real-world 환경에서는 imbalanced dataset이 주어지는데에 반해
기존에 있던 논문에서는 임의로 dataset을 balanced하게 맞추던지 혹은 그 정도가 본 논문에 비해 빈약합니다.
또한 몇 몇 논문은 dataset을 imbalanced한 환경 탓에 새로운 데이터에 대해 제대로 탐지를 못하고 대부분을 많은 dataset을 차지하는 Benign으로만 분류를 하는 한계점이 존재했습니다.
그래서 본 논문에서는 real-world 환경에 적합하도록 imbalanced한 dataset을 설정하고 테스트 하였습니다.
그리고 imbalanced한 환경에 더 적합한 훈련을 하기 위해 기존 논문들이 제안한 Contrastive Learning이 아닌 Hierarchical Contrastive Learning을 제안합니다.
또한 그에 맞는 수식을 갖는 drifting sample Selector인 Pseudo Loss sample Selector을 제안합니다.
1. Introduction
The need to solve the concept drift
말씀드린대로 Concept drift는 real-world 환경에서는 필연적으로 일어나는 현상입니다.
특히나 창과 방패의 싸움이 빈번한 cyber security 분야에서는 더욱 더 Concept drift 현상이 가파르게 나타납니다.
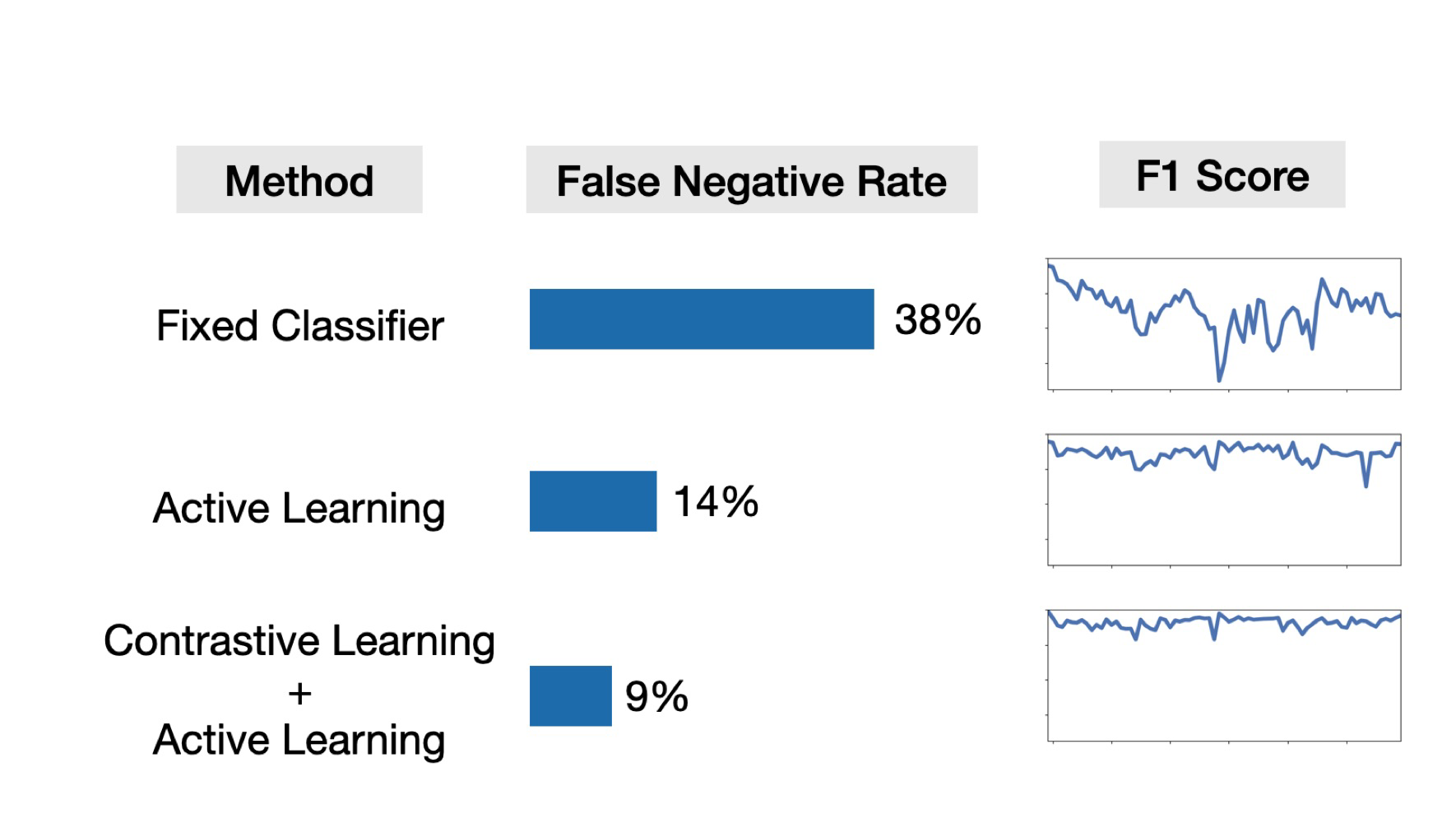
위 이미지는 2012-2018년, 총 7년 동안의 평균 FNR score입니다.
FNR이란?TP (True Positive): 실제 긍정인 데이터를 긍정으로 올바르게 예측한 경우
TN (True Negative): 실제 부정인 데이터를 부정으로 올바르게 예측한 경우
FP (False Positive): 실제 부정인 데이터를 긍정으로 잘못 예측한 경우
FN (False Negative): 실제 긍정인 데이터를 부정으로 잘못 예측한 경우위 설명에 따라 FNR은 실제 긍정인 데이터를 부정으로 잘못 예측한 경우의 비율을 뜻합니다.
즉, 1을 0이라고 잘못 판단 했다는 것인데 본 논문에서 1은 Malware을 뜻하고 0은 Benign을 뜻합니다.그러기 때문에 Malware을 Benign으로 판단한다는 것이므로 매우 위험한, 그리고 가장 위험한 상황이 되는 것입니다.
1번 째 Method는 Fixed Classifier으로,
2012년에 모델을 훈련한 상태로 2018년 까지의 데이터를 입력했을 때의 FNR Score입니다.
당연하게도 2012년도 모델을 통해 2018년 까지의 데이터를 classify하려 했기때문에 FNR이 38%로 상당히 높게 나왔습니다.
2번 째 Method는 Active Learning으로,
2012년에 모델을 훈련하고 시간이 지남에 따라 지속적으로 Active Learning을 해준 경우입니다.
Active Learning을 이용한 지속적인 훈련에 따라 14%로 FNR이 상당히 감소하였습니다.
3번 째 Method는 Contrastive Learning + Active Learning으로,
2012년에 모델을 훈련하고 시간이 지남에 따라 지속적으로 Active Learning을 한 것 뿐만 아니라 Contrastive Learning도 해주었습니다.
FNR score가 Active Learning을 사용하였을 때 보다 Contrastive Learning + Active Learning을 하였을 때 더 감소하였습니다.
Contrastive Learning
Contrastive Learning은 서로 다른 label을 갖는 샘플들의 거리를 벌려주는 형식으로 훈련이 됩니다.
본 논문에서는 Contrastive Learning이 cyber security 분야에 매우 적합하다고 주장합니다.
그 이유는 다음과 같습니다.
-
similarity 측정
서로 다른 label을 갖는 샘플들의 거리를 벌려주게 되면 similarity를 측정 할 수 있게 됩니다.
기존에 알던 data가 입력되면 어느 한 label에 similar 할 것이고 새로운 data가 들어오게 된다면 그 어느 label에도 similar 하지 못할 것입니다. -
drifting sample 선택의 용이성
이러한 특성 덕분에 Active Learning을 하며 drifting sample을 select 해야할 때 훨씬 수월 할 것입니다.
어느 label에도 similar 하지 못한 sample을 drifting sample로 선택하면 되기 때문입니다.
Hierarchical Contrastive Learning
위에서 말했듯이 Active Learning에 Contrastive Learning을 더하게 되면 FNR score가 더 감소합니다.
특히 기존 논문인 CADE에서 Contrastive Learning + Active Learning을 사용하였지만, real-world datset 환경에 대해서는 한계점이 존재했습니다.
CADE 논문에서 나름 imbalanced dataset 환경으로 세팅을 하였지만 본 논문의 imbalanced dataset에 비해 그 정도가 약합니다.
또한 drifting sample 혹은 새로운 유형의 attack이 들어오더라도 대부분 benign sample로 분류하는 경우가 많습니다.
그 이유는 예를들어
- benign data (10,000개)
- malware1 data (1,000개)
- malware2 data (1,000개)
- malware3 data (1,000개)
- malware4 data (1,000개)
- malware5 data (1,000개)
위와 같이 있을 때 benign data가 10,000개로 다른 data에 비해 x10 가량 imbalanced하게 훈련되었기 때문입니다.
이런 경우 새로운 유형의 data가 입력되었을 때 benign으로 보는 경향이 있습니다.
Hierarchical Contrastive Learning은 이러한 문제를 해결하기 위해 Bening과 Malware의 계층을 아래와 같이 나눠줍니다.
- benign data (10,000개)
- malware data (5,000개)
ㄴ malware1 data (1,000 개)
ㄴ malware2 data (1,000 개)
ㄴ malware3 data (1,000 개)
ㄴ malware4 data (1,000 개)
ㄴ malware5 data (1,000 개)
이렇게 Hierarchical하게 benign과 malware을 나눠줌으로써 새로운 유형 혹은 새로운 분포의 data가 입력되었을 때 benign으로 판단 되는 것을 어느 정도 해결해줍니다.
또한 Hierarchical Contrastive Learning과 기본적인 Contrastive Learning의 거리를 나누는 기준이 약간 다릅니다.
- Hierarchical
Benign 한 쌍 or 다른 family를 갖는 Malware 한 쌍 - 거리 다소 가까움
동일 family를 갖는 Malware 한 쌍 - 거리 매우 가까움
한 개는 Malware, 나머지 한 개는 Benign - 거리 매우 떨어짐
- Non-Hierarchical
한 쌍이 동일 family 갖을 시 - 거리 가까움
한 쌍이 다른 family 갖을 시 - 거리 떨어짐
위와 같이 Heirarchical에서는 계층을 한 단계 더 나누는 개념이 존재하므로 거리를 나누는 기준에 한 단계가 더 존재합니다.
Pseudo Loss sample Selector
또한 이렇게 Hierarchical하게 나누는 수식을 상당부분 재활용하여 pseudo loss를 도출할 수 있습니다.
Selector는 pseudo loss를 사용하여 drifting sample을 추출합니다.
수식은 잠시 뒤에 설명하도록 하겠습니다.
Warm start
본 논문에서는 Warm start를 사용하였습니다.
Warm start와 Cold start의 차이는 다음과 같습니다.
- Warm start
기존 dataset에 대해 훈련된 모델의 weight를 유지한채 훈련을 이어간다.
- Cold start
기존 dataset에 대해 훈련된 모델의 weight를 버린채 훈련을 다시 처음부터 시작한다.
Continous Learning 분야에선 Warm start가 효과적인 것으로 보입니다.
그 이유는 예를들면,
모델이 2012년까지의 dataset을 입력으로 훈련되었다고 가정하겠습니다.
2013년에 drifting sample이 생겨 이를 기존의 dataset에 추가합니다.
이렇게 되면 (2012년 dataset) + (2013년 drifting sample)이 최종 dataset이 됩니다.
이 최종 dataset을 입력 data로 warm start와 같이 사용한다면,
이미 2012년 dataset에 대해 한 번 훈련 된 모델이기 때문에 2012년 data에 대해선 loss값이 작게 나올 것이고
2013년에 새롭게 추가된 drifting sample에 대해 loss 값이 크게 나올 것입니다.
이러한 이유때문에 Continous Learning에서는 Warm start가 대부분의 경우에는 효과적입니다.
2. Method
Architecture
본 논문에서는 Hierarchical Contrastive Learning을 하기위한 Hierarchical Contrastive Classfier와
drifting sample을 select 하기 위한 Pseudo Loss Sample Selector가 있습니다.
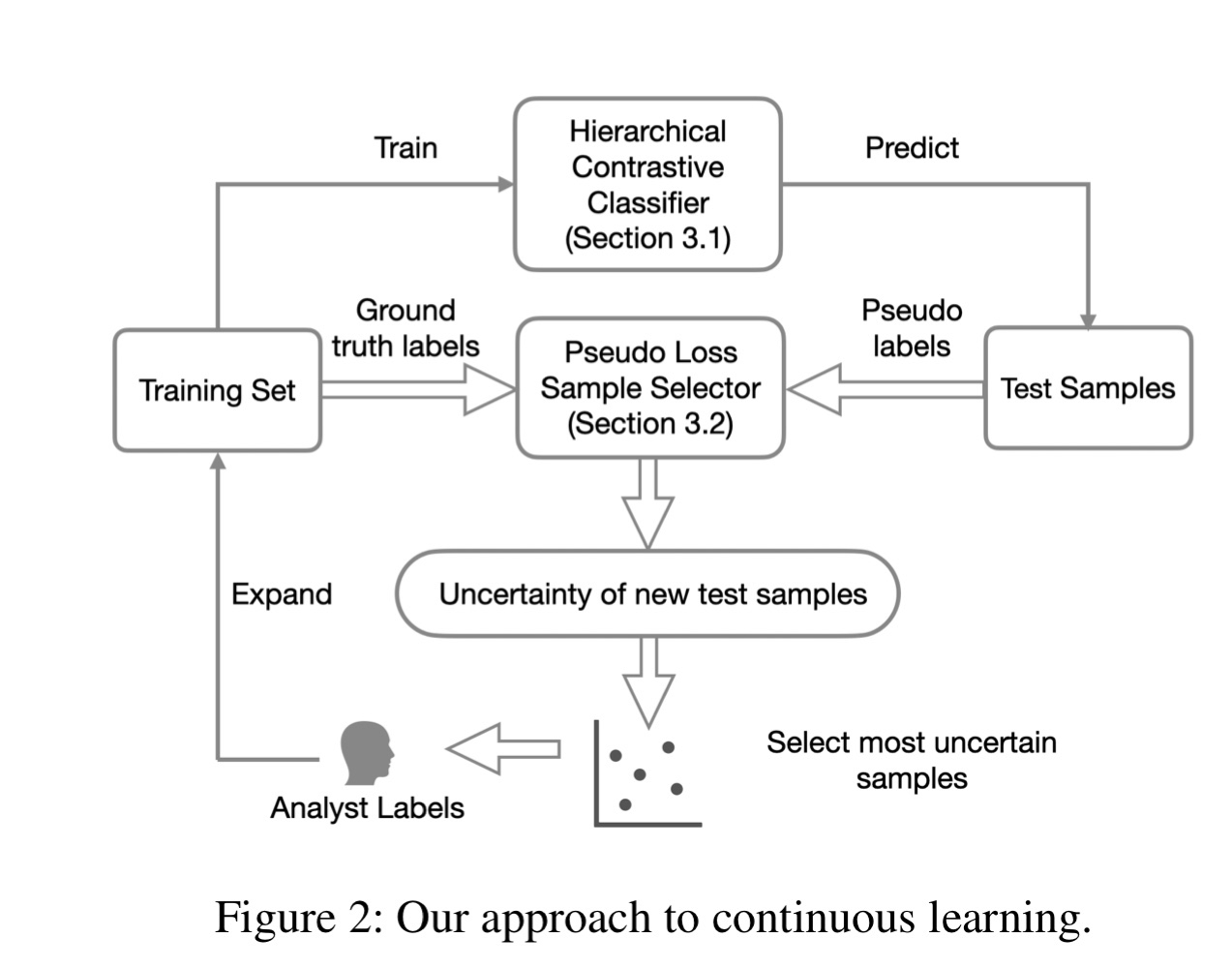
작용 순서는 다음과 같습니다.
1)
2012년 train dataset을 Hierarchical Contrastive Classfier에 입력하여 훈련합니다.
2)
2013년 새로운 dataset을 Hierarchical Contrastive Classfier에 다시 입력해봅니다.
3)
Pseudo Loss Sample Selector에서는 2013년 dataset에 대해 pseudo loss 값을 통해 uncertain score을 매겨 drifting sample을 추출합니다.
4)
추출된 drifting sample을 Analyst에게 전달합니다.
(2013년 dataset이 10,000개 였다면 Analyst에게 전달되는 drifting sample은 100개 정도)
5)
Analyst는 drifting sample에대해 직접 라벨링 합니다.
6)
(2012년 train dataset) + (2013년에 추가된 drifting sample)을 합쳐 train dataset으로 다시 만듭니다.
7)
합쳐진 train dataset을 통해 1번부터 다시 훈련합니다.
Hierarchical Contrastive Learning Loss
Introduction에서 말씀드린대로 Hierarchical Contrastive Learning의 Loss 값 도출은 다음과 같은 과정으로 이루어집니다.
- Hierarchical
Benign 한 쌍 or 다른 family를 갖는 Malware 한 쌍 - 거리 다소 가까움
동일 family를 갖는 Malware 한 쌍 - 거리 매우 가까움
한 개는 Malware, 나머지 한 개는 Benign - 거리 매우 떨어짐
위 과정을 수식으로 표현한다면 아래와 같이 됩니다.

1)
위 (5)의 첫번 째 줄에서,
은 다음을 의미합니다.
Benign 한 쌍 or 다른 family를 갖는 Malware 한 쌍 = 거리 다소 가까움
에서 는 i와 j로 한 쌍이 이루어졌을 때 둘 사이의 거리입니다.
m은 margin이라는 의미이며 m = 10으로 설정되어 있다면 가 10의 거리보다 더 작게 표현되도록 유도합니다.
즉, Benign끼리는 10의 거리 안으로 뭉치도록 유도하며 Malware끼리도 10의 거리 안으로 뭉치도록 유도합니다.
2)
위 (5)의 두번 째 줄에서,
은 다음을 의미합니다.
동일 family를 갖는 Malware 한 쌍 = 거리 매우 가까움
동일 family를 갖는 경우는 Malware에서도 그 종류까지 같은 경우를 말합니다.
즉, 에서 i와 j인 한 쌍이 모두 Malware이며 같은 family인 경우입니다.
이런 경우에는 거리를 1)이였을 경우보다 더 가깝도록 유도합니다.
3)
위 (5)의 세번 째 줄에서,
은 다음을 의미합니다.
한 개는 Malware, 나머지 한 개는 Benign = 거리 매우 떨어짐
에서 i와 j인 한 쌍으로 이루어져 있을 때 i는 Malware, j는 Benign (혹은 그 반대)인 경우를 의미합니다.
이런 경우에는 m = 10으로 설정되어 있는 경우 Malware와 Benign이 20의 거리만큼 벌어지도록 유도합니다.
즉, 아래와 같은 clustring을 유도합니다.
보시면 아시겠지만 Benign과 Malware은 거리가 매우 떨어진 것을 볼 수 있고 (20만큼),
Benign 끼리는 거리가 다소 가까운 것을 볼 수 있고 (10만큼),
Malware에서 같은 family 끼리는 거리가 매우 가까운 것을 볼 수 있습니다.

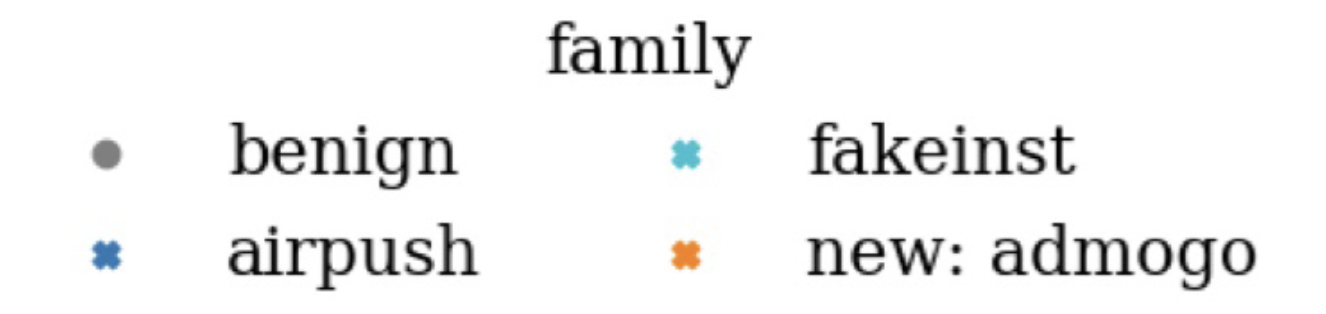
Pseudo Loss
drifting sample을 도출하기 위해 Pseudo Loss를 계산합니다.
Selector는 이 Pseudo Loss가 높게 나온 것을 drifting sample의 우선순위에 둡니다.
Pseudo Loss는 위 Hierarchical Contrastive Loss 값과 상당히 유사합니다.
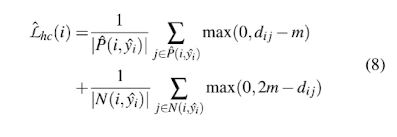
위 (8)번 수식은 (5)번 수식에서 두번 째 줄을 제외하면 (거의) 같습니다.
두번 째 줄을 제외하는 이유는 Hierarchical 개념이 들어갔기 때문입니다.
다시 말해서 계층의 개념으로 인해 0(Benign)과 1(Malware)을 구분하는게 주 목적이기에
0과 1을 넘어 Malware일 시 family까지 classify 하는 데에는 무리가 있습니다.
여기서 궁금하실 수 있는게 Hierarchical Contrastive Learning Loss에서는 family까지 수식에 들어가있는데 Pseudo Loss에서는 family 관련 수식이 없다는 점입니다.
Hierarchical Contrastive Learning Loss 부분은 training 부분입니다.
그렇기때문에 classifier을 훈련하며 family 값 까지 줄 수 있습니다.
그리고 이 family 값을 이용하여 (5)의 수식을 이용해 Hierarchical Contrastive Learning을 수행합니다.
그리고 나서 MLP에 Hierarchical Contrastive 하게 되어있는 latent sapce의 값을 입력 받아 Benign인지 Malware인지 분류를 수행할 수 있게 훈련합니다.
Pseudo Loss 부분은 testing 부분입니다.
그렇기때문에 classifier는 Benign인지 Malware인지만 분류하도록 훈련되었기 때문에 family 값까지 classify 할 순 없습니다.
애초에 training 부분에서 family 값 까지 classify하게 훈련했으면 될 거 아니냐라는 궁금증이 생기실 수 있지만 그렇지 않습니다.
그 이유는 classify를 0과 1로만 되도록 했을 때의 이점이 있기 때문입니다.
그 이점은 새로운 분포의 data가 입력되었을 때 상대적으로 0과 1이 imbalanced 하지 않기 때문에 dataset의 대부분을 차지하는 0으로 분류될 가능성을 줄여줍니다.
만약 0과 1 뿐만 아니라 family까지 나누게 된다면 1에 속한 dataset들이 각각의 family label로 다시 잘게 쪼개져 훨씬 더 imbalanced한 dataset이 될 것이기 때문입니다.
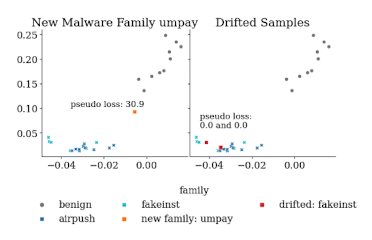
위 이미지를 보면 new family인 umpay sample에 대해선 pseudo loss 값이 높게 산출된 것을 볼 수 있습니다.
위 drifting sample을 Analyst에게 전달하여 labeling하고 retraing을 하게 된다면 오른쪽과 같이 pseudo loss가 0에 가깝게 나오는 것을 확인할 수 있습니다.
CE Loss
여기서 말하는 CE Loss는 cross entropy에 의해 훈련되는 MLP에 적용되는 Loss입니다.
위의 Hierarchical Contrastive Learning Loss는 encoder에서 훈련되며, 그 다음 CE Loss를 통해 MLP를 훈련해 0과 1을 classify 하도록 합니다.
그래서 최종적으로 training 할 때 Hierarchical Contrastive Learning Loss + CE Loss를 통해 훈련되며,
Selector에서 drifting sample을 도출하기 위해 Pseudo Loss + CE Loss를 통해 uncertain 점수를 산출합니다.
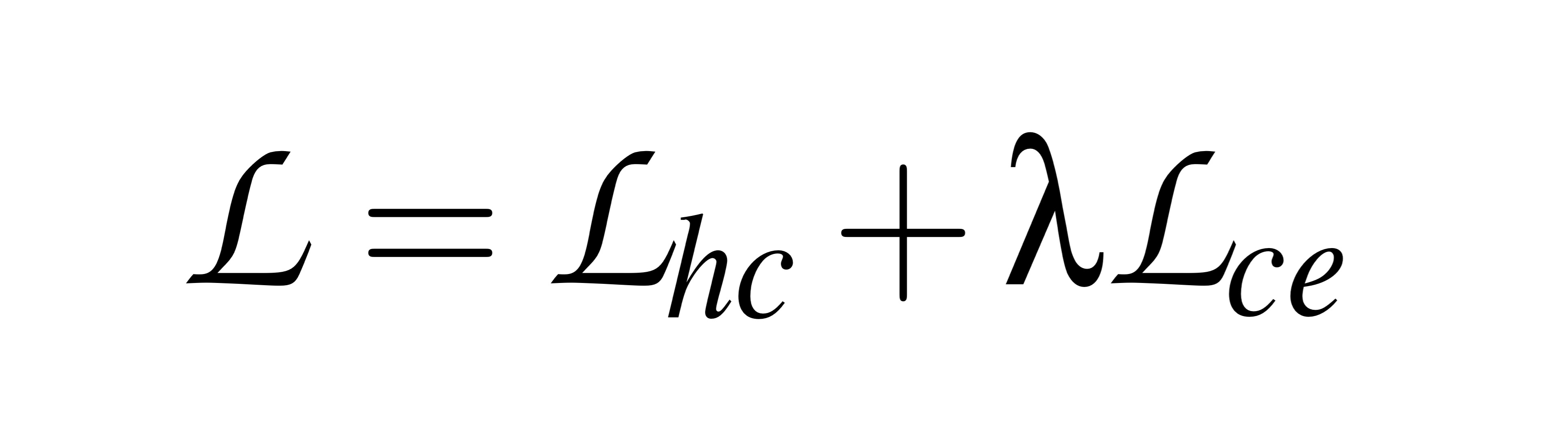
3. Experiments
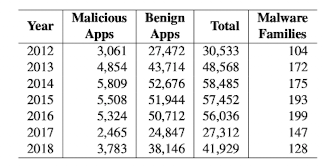
imbalanced dataset
본 논문에서는 imbalanced한 dataset을 설정하기위해 Benign과 Malware를 거의 9:1 ~ 10:1의 비율로 맞춰주었습니다.
Active Learning Setup
Active Learning의 특성상 Continuos 하게 훈련이 되어야기 때문에 시간 개념이 매우 중요합니다.
시간 개념을 더하기 위해 2012년 dataset에 대해서는 1-12월까지 한번에 training 시킨 뒤, 그 다음 해인 2013년 부터는
2013-01 부터 시작해서 매 달 drifting sample을 도출하고 retraing 하는 방식입니다.
Result
본 논문에서 제안한 방식과 기존 연구인 CADE, TRANSCENDENT을 기준으로 F1 score을 비교합니다.
가장 큰 차이점으로는 본 논문에는 Hierarchical 개념이 들어가있는 반면에 CADE, TRANSCENDENT 모두 Hierarchical 개념이 들어가있지 않다는 차이점이 있습니다.
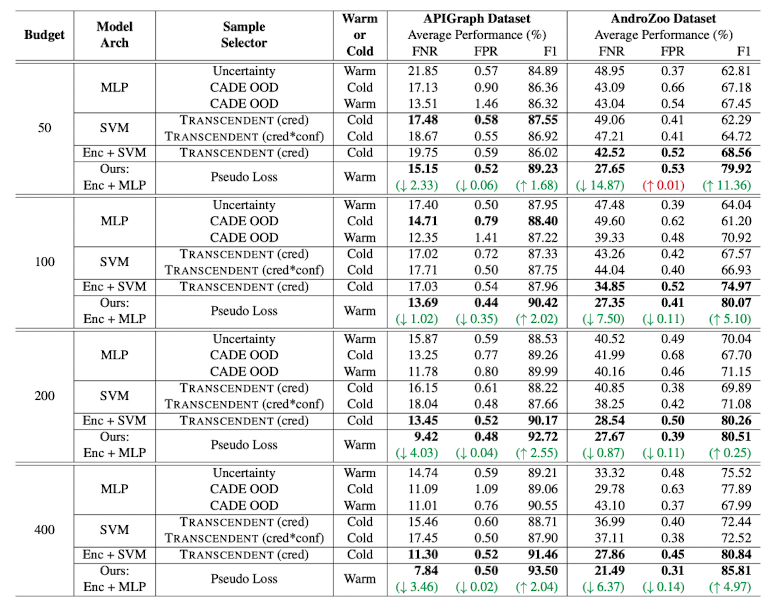
위와같이 drifting sample을 100개 추출한다는 가정하에 비교해보면,
본 논문에서 제안하는 방식이 CADE 방식보다 F1 score가 2.02% 높은 것을 볼 수 있습니다.
또한 FNR score도 1.02% 낮아졌습니다.
4. 후기
Hierarchical 개념을 추가함으로써 F1 score을 2.02% 올린 것이면 충분히 유의미한 연구 결과라고 생각합니다.
하지만 아쉬운 점은 본 논문에서는 classifier가 Benign과 Malware만을 classify 한다는 것입니다. 그 밑에 속해있는 family까지는 구분을 못한다는 점입니다.
물론 이러한 희생을 통했기에 기존 논문에 비해 F1 score을 올릴수 있었던 것이지만,
기존 논문에서는 Explanation도 가능했지만 본 논문에서는 family를 구분하지 못하는 탓에 Explanation을 하기에는 힘들어 보입니다.
만약 Hierarchical 하면서도 family까지 구분이 가능해 Explanation이 가능하다면 좀 더 좋은 논문이였을 것 같다는 아쉬움이 남습니다.
