해당 논문은 GPT-1의 구조를 설명하고 있다.
Introduction
NLP 분야에서 supervised learning은 많은 도메인에서의 적응성을 제한한다. 왜냐면 unlabeled corpora가 labeled corpora보다 훨씬 많기 때문!
라벨링 되지 않은 text에서 단어 레벨 수준 이상의 정보를 뽑아내는 것은 어렵다.
1) 최적화 목표가 무엇인지 명확하지 않다는 것. 여기서 언급된 최적화 목표에는 언어 모델링, 기계 번역, 담론 일관성 등이 있으며, 각각의 방법이 다른 작업에서 우수한 성능을 보였다.
2) 이러한 학습된 표현을 대상 작업에 어떻게 효과적으로 전달(transfer)할지에 대한 합의가 없다는 것이다.
이 논문의 목표는 먼저 큰 규모의 라벨이 없는 데이터를 사용하여 신경망의 기본 구조를 학습한 다음(pre-training), 특정 작업에 맞게 모델을 세부 조정하는 방법(fine tuning)에 대해 설명하고 있다. 이는 넓은 범위의 언어 처리 작업에 효과적으로 적용될 수 있는 범용적인 언어 모델을 개발하는 데 중점을 둔다.
여기서 범용 언어 모델이란? 언어 번역, 텍스트 요약 등 다양한 용도로 쓰일 수 있는 모델이라고 한다.
Framework
training 과정을 2개의 스텝으로 나눠서 설명하고 있다. 먼저 고가용성 언어 모델을 학습시키는 것이다. 그 다음엔 fine tuning을 해준다.
Unsupervised pre-training
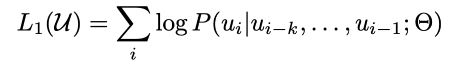
토큰의 unlabeled corpus를 U라고 할 때, 위의 L1(U)를 최대화 하는 방향으로 학습이 진행된다.
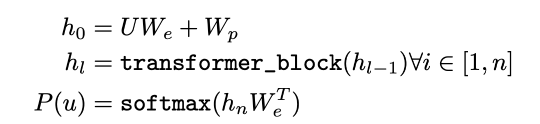
이 수식을 아래의 그림을 통해서 이해해보자.
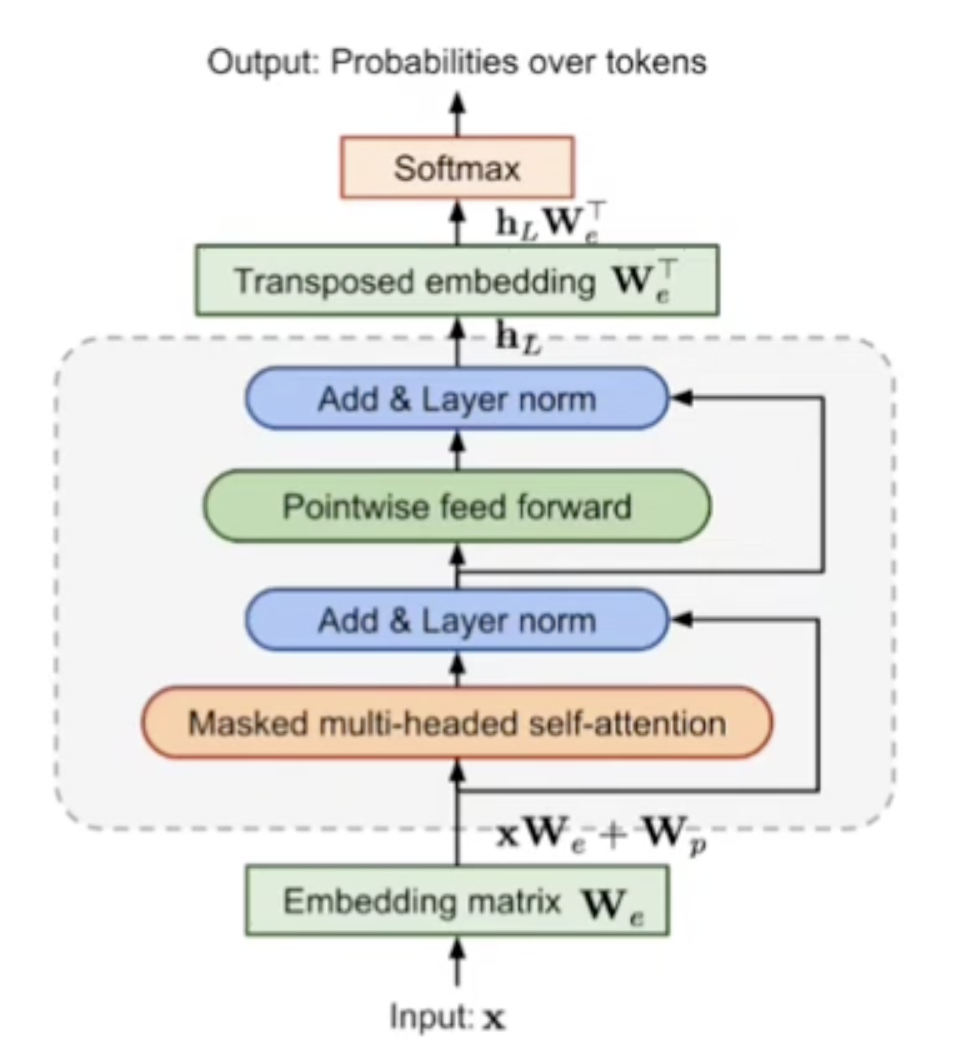
먼저 x를 input으로 넣어준다. x를 수식의 U라고 보자.
x는 Embedding matrix를 통과하면서 We와 곱해지고 Wp가 더해진다. 이때 Wp는 position을 나타내는 vector인데, input data의 순서 정보를 추가해주는 것이라고 간단히 설명하겠다.
여기까지의 작업이 수식에서 h0을 만드는 작업이었다.
이렇게 만들어진 h0을 transformer decode block에 넣어준다. 저 사진의 회색 점선 박스에 해당하는 부분이 transformer decoder block인데, 이 부분이 12번 반복된다. 이렇게 12번 반복되어 나온 값이 hl이다.
이전 Attention is all you need 논문에 나온 아키텍쳐와의 차이점은 masked multi-headed self-attention이라는 것이다.
masked multi-headed self-attention
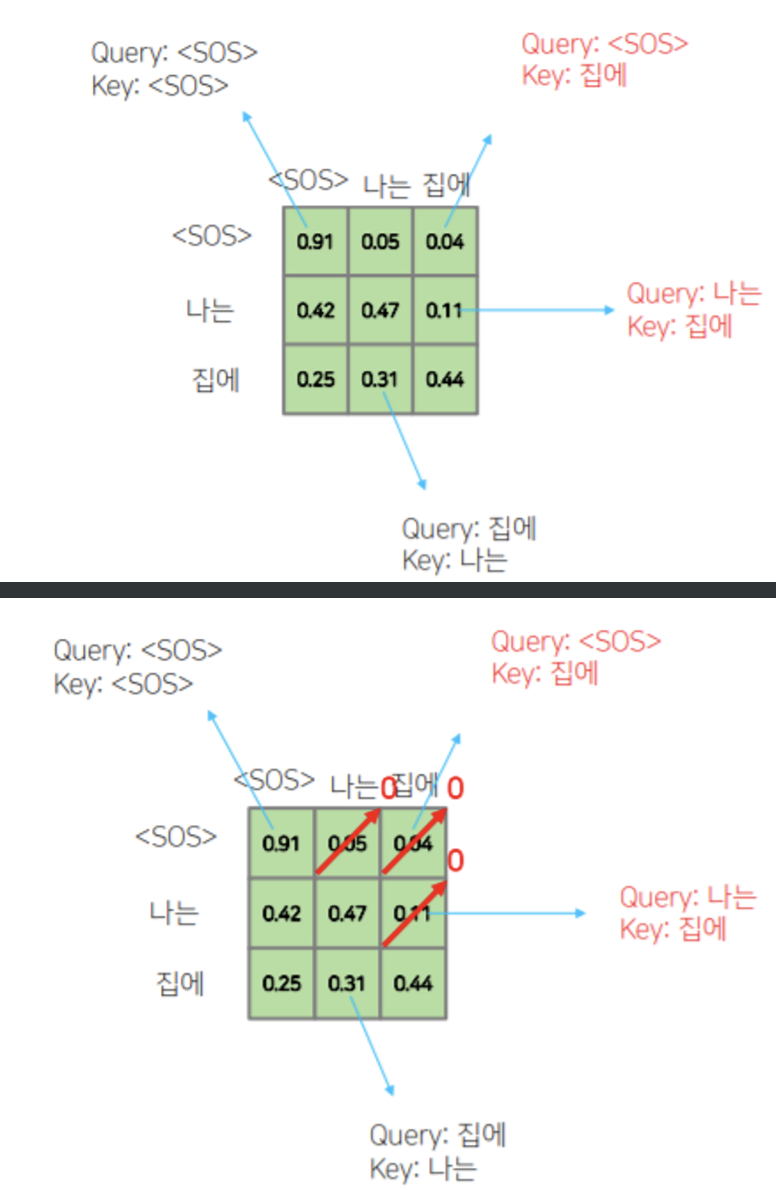
maksed는 이전 값만을 참고하기 위해서 이전 값을 날려주었다. 왜냐면 이후의 값을 알면서 학습을 하는 것은 의도치 않은 cheating가 될 수 있기 때문이다.
다시 transformer로 돌아와서,
hl을 We transpose에 넣어서 embedding vector 형태로 만들어주고 softmax를 적용해서 확률로 변환해준다.
Supervised fine-training
이렇게 pre-trained model에 추가적으로 학습을 하여 fine tuning을 해준다.
transformer block을 통과해 나온 hml이라는 결과에 새로운 linear layer Wy를 곱해준다.
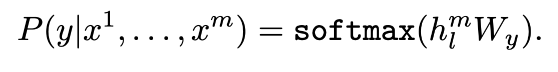
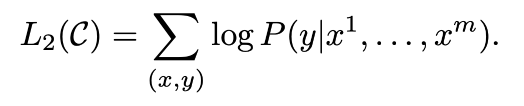
위의 수식 L2(C)가 최대화 되도록 한다.
이렇게 pre-train에서 L1, fine tuning에서 L2를 구해 L3를 만들어준다.
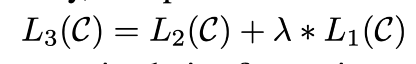
Task-specific input transformations
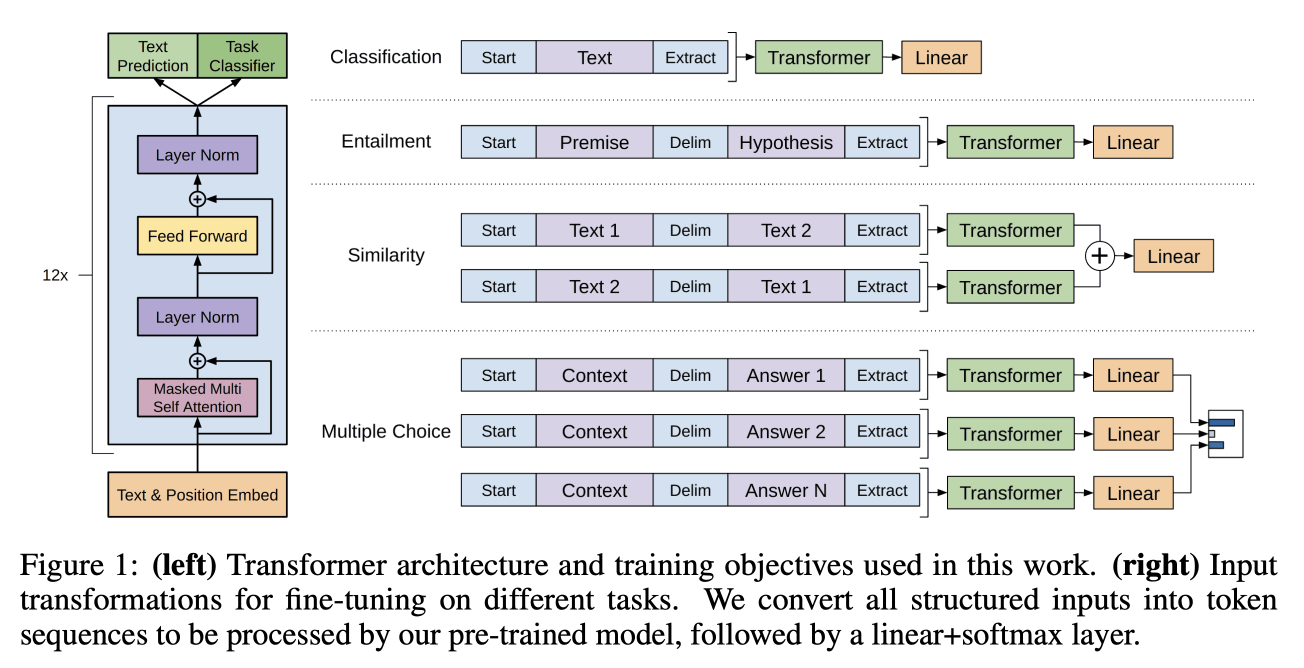
fine tuning 하기 위해서 오른쪽에 있는 것과 같은 형식으로 transformer에 넣어준다.
먼저 Classification 문제입니다. 이는 입력받은 Text를 분류하는 문제인데요. 가장 대표적으로 스팸 메일 분류 문제가 있습니다. 메일 내용 전체를 입력으로 주고 모델은 이 메일이 스팸인지 아닌지를 구분하는 문제이죠. 이때는 단순히 문장 전체를 모델에 입력으로 넣어주면 됩니다.
다음은 Textual Entailment 문제입니다. 이는 2개의 문장을 입력 받아 두 문장의 관계를 Classification 하는 문제입니다. 보통 세 가지로 분류하는데요. Entailment (함축), Contradiction (모순), Neutral (중립) 입니다. 이 경우는 문장 2개를 구분해서 입력 받아야 하는데요. 따라서 위의 그림과 같이 첫 번째 문장인 Premise를 넣고, Delim (구분)과 두 번째 문장인 Hypothesis를 구성해줍니다.
세 번째는 Similarity 문제입니다. 이는 두개의 문장을 입력 받아 두 문장이 얼마나 유사한지를 측정하는 문제입니다. 따라서 입력으로는 두개의 문장을 받아야 하고, 출력은 0~1 사이값을 내야 합니다. 위 그림을 보면 첫 번째 입력은 Text1, Text2 순서로 구성하고, 두 번째 입력은 Text2, Text1 순서로 구성하고 있습니다. 이 두 문장을 각각 모델에 입력한 뒤 나온 Representation을 Elementwise Addition 한 뒤 Linear와 Activation 함수를 거쳐 최종 유사도 값을 출력하는 구조입니다.
네 번째는 Multiple Choice 문제입니다. 구체적으로는 Question Answering and Commonsense Reasoning 문제가 있는데요. 이 문제는 Context와 Answer로 구성되어 있습니다. 예를 들면 이렇습니다.
Context는 이렇게 구성해주는 거죠. “서울은 대한민국의 수도입니다. 이 도시는 한강을 중심으로 확장되어 있습니다. 대한민국의 수도는 어디입니까?”
이에 대한 Answer는 “서울” 이죠. 모델은 Context를 입력으로 받아 그에 맞는 Answer를 출력하도록 학습합니다.
출처: https://ffighting.net/deep-learning-paper-review/language-model/gpt-1/
