paper: https://arxiv.org/abs/2401.10774
implementation: https://github.com/FasterDecoding/Medusa
1. Intro
LLM의 infence latency가 실용적인 적용을 막았다. 또, 메모리 병목 현상이 주 원인이었는데, 이는 auto-regressive decoding의 순차적 성질이었다.
이를 해결하기 위해서, 부동 소수점 연산의 작업 비율을 줄이고 디코딩 스텝을 줄이려는 노력을 하였다. 이 과정을 통해서 탄생한 것이 speculative decoding이다.
speculative decoding의 문제점은 적절한 draft 모델을 만드는 것, 그리고 그를 다른 모델과 통합하는 것에 어려움이 있었다.
이 논문에서는, 다른 초안 모델을 후보를 생성하기 위해 사용하는 대신에 백본 모델의 top 부분에 multiple decoding step을 추가하였다. 이것은 speculative decoding의 단점을 극복하였고, LLM에 심리스한 통합을 가능케 하였다.
두 가지 key insight를 갖고 메두사를 더 향상시켰다.
1. 여러 개의 후보들을 생성
2. rejection sampling을 쓰지만, 이는 LLM에게 별로 필요없기 때문에 대안적으로 typical acceptance를 사용한다.
LLM에 메두사 헤드를 장착하기 위해서 2가지 다른 fine-tuning 방식을 소개한다.
원본 모델에 영향을 주지 않고, 제한된 컴퓨팅 자원을 가질 때는 MEDUSA-1
기본모델로부터 SFT(supervised fine-tuning)이 적용가능하거나, 충분한 계산 자원이 있을 때 MEDUSA-2가 적합하다.
2. Relative work
3. MEDUSA
메두사는 각 디코딩 스텝이 3개의 서브스텝으로 구성된 speculative decoding과 동일한 프레임워크를 따른다.
(1) 후보 생성
(2) 후보 처리
(3) 후보 수락
메두사에서는 (1)은 MEDUSA head로 수행된다.
(2) 는 트리 어텐션(tree attention)에 의해 실현되며, MEDUSA 헤드가 원래 모델 위에 있으므로, (2)에서 계산된 logit은 다음 디코딩 단계를 위한 서브스텝 (1)에 사용될 수 있다.
(3)은 rejection sampling에 의해서 수행되거나 typical acceptance로 실행된다.
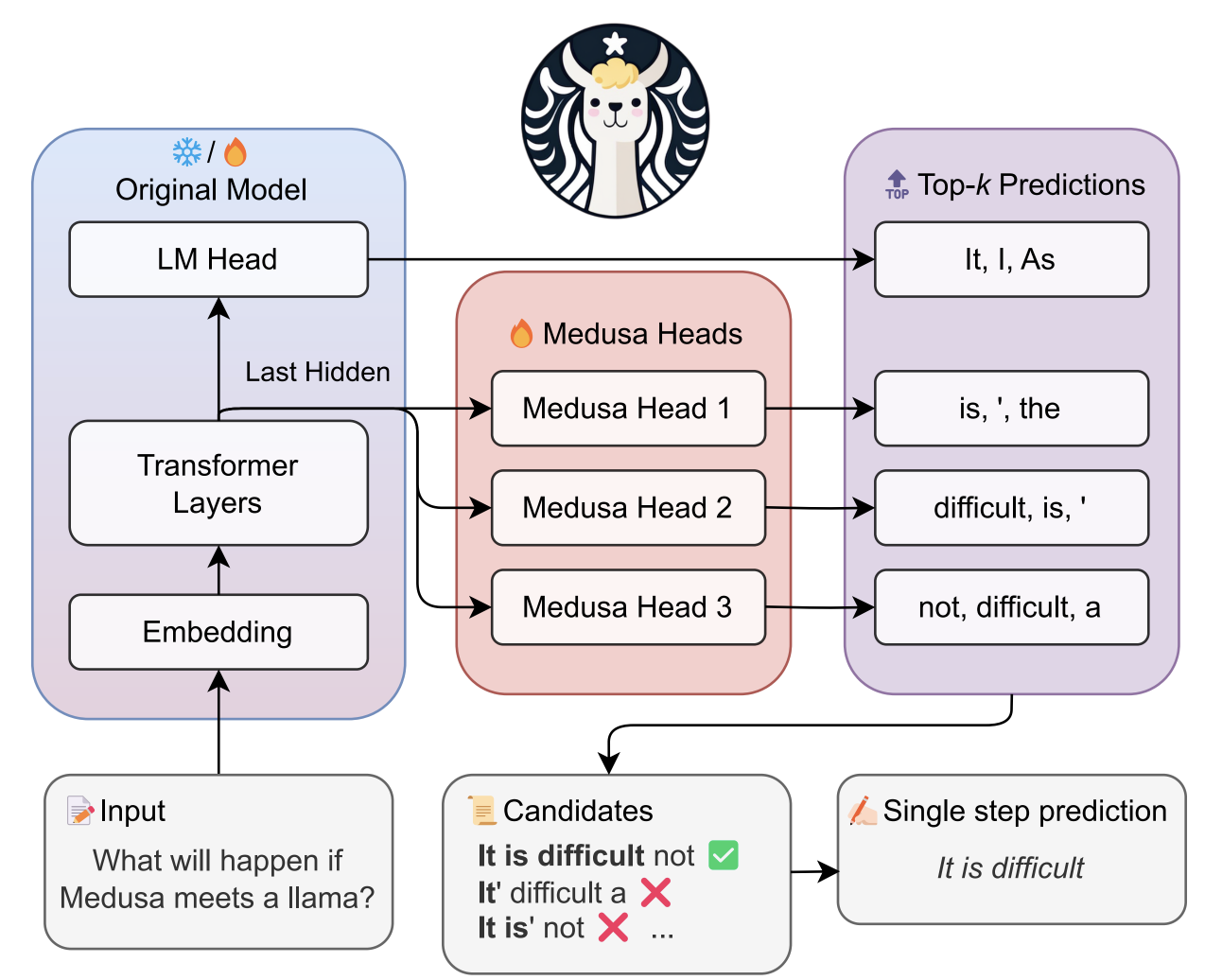
Fig1. Overview of Medusa
이번 3장에서는, 메두사의 주요 구성요소를 설명하고, 다른 쓰임을 위한 두 단계의 fine-tuning 된 메두사를 소개한다.
마지막으로는, 훈련되지 않은 데이터가 들어온 상황과 decoding 프로세스의 효율을 향상하기 위해서 사용한 2가지 확장(self-distillation & typical acceptance)를 소개한다.
3.1 Key Components
3.1.1 MEDUSA Heads
LLM 추론을 가속화 하기 위해서, MEDUSA head를 사용하였다.
이 추가적인 decoding head는 원래 모델의 마지막 hidden state 뒤에 추가된다.
position t에 있는 원본 마지막 히든 state를 ht라고 한다.
우리는 이 ht에 K개의 디코딩 헤드를 추가한다.
k번째 헤드는 (t + k + 1)번째 위치의 다음 토큰을 예측한다. (원본 언어 모델의 헤드는 (t + 1)번째를 예측함)
k번째 헤드의 예측(prediction)은 pt(k)로 표현한다.
동시에 원본 모델의 예측은 pt(0)로 나타난다.
k번째 헤드의 정의는 다음과 같다.
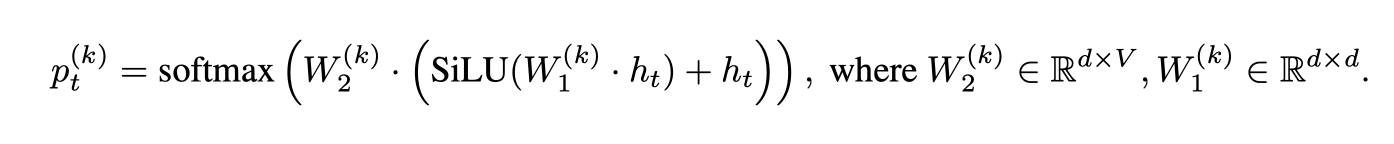
우리는 원래 언어 모델 헤드와 동일하게 W1(k)을 초기화하고, W2(k)를 0으로 초기화한다. 이는 MEDUSA 헤드의 초기 예측을 원래 모델의 예측과 일치시킨다. Lama 모델에는 SiLU 활성화 함수가 사용된다.
MEDUSA 헤드는 초안 모델과 달리 원래 백본 모델과 함께 훈련되며, 이는 훈련 중에 동결 상태를 유지하거나(MEDUSA-1) 함께 훈련될 수 있다(MEDUSA-2).
head의 학습과정은 3.2절에 소개될 예정이다.
3.1.2 Tree Attention
MEDUSA 헤드를 통해 후속 K+1 토큰에 대한 확률 예측을 얻는다. 이러한 예측을 통해 길이-K+1 연속을 후보로 생성할 수 있다.
speculative decoding 연구에서는 단일 연속 샘플링을 후보로 제안하지만, 디코딩 중에 여러 후보를 활용하면 디코딩 단계 내에서 예상되는 허용 길이를 향상시킬 수 있다.
그럼에도 불구하고 많은 후보가 computational demands를 제기할 수도 있다. 균형을 맞추기 위해 tree-structered attention 메커니즘을 사용하여 여러 후보를 동시에 처리한다. 이 attention 메커니즘은 기존의 causal attention 패러다임에서 벗어난다.
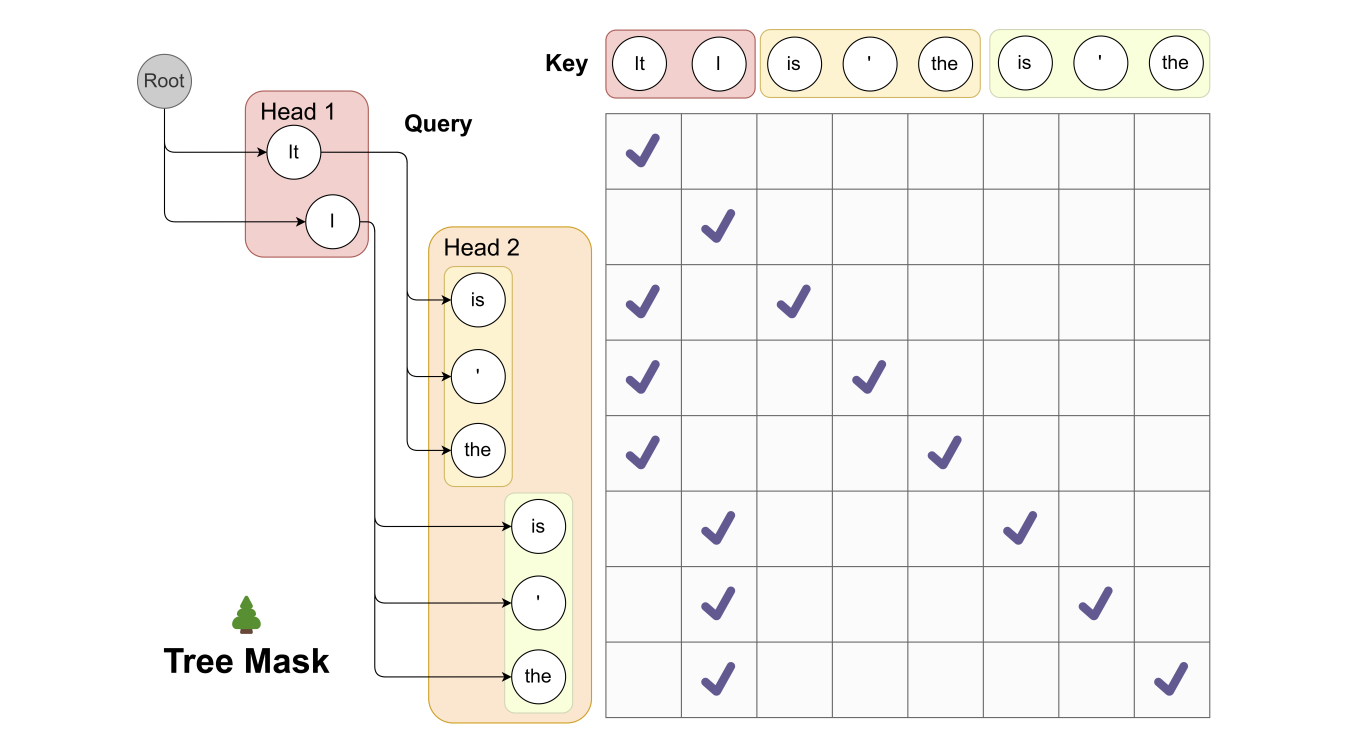
Fig2. Tree Attention Illustrated
our attention mask는 주어진 토큰에 대해 오직 그 토큰의 'predecessors' (즉, 이전에 나온 토큰들)에만 attention을 적용하도록 한다. 이것은 attention 메커니즘이 해당 토큰이 생성될 때 고려해야 하는 문맥을 제한함으로써, 모델이 특정 토큰의 직접적인 이전 토큰들에만 집중하게 만듭니다.
Figure 2를 예로 들면, 'Head 1'에서 'It'이라는 토큰이 선택되었을 때, 'Head 2'의 'is', ' ', 'the'는 모두 'It'이라는 토큰을 이어받아 후속 토큰으로 고려된다. 이 때 'Head 2'에서 'is', ' ', 'the' 중 어느 하나가 선택되더라도, attention 메커니즘은 오직 'It' (Head 1에서 나온 토큰)에만 적용된다는 것이다.
3.2 Training Strategies
3.2.1 MEDUSA-1: Frozen Backbone
메두사 헤드를 고정된 백본 모델과 훈련하게 하기 위해서,
MEDUSA 헤드의 예측과 지상 진리 사이의 교차 엔트로피 손실을 사용할 수 있다. (cross entropy의 경우는 최소화해주는 것이 목표이다.)
t+k+1 위치에 있는 ground truth 토큰을 y t+k+1이라고 하자.
k번째 헤드의 손실함수는 다음과 같다. 여기서 pt(k)(y)는 k번째 헤드가 예측한 토큰 y의 확률을 나타낸다.
(** ground truth: 모델이 출력하기 바라는 올바른 출력이나 답변)
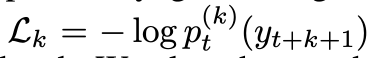
여기서 k가 커질 수록 Lk도 커지는데, 이는 뒤로 갈 수록 점점 예측이 점점 불확실해지기 때문이다.
그러므로 다른 헤드들과 손실에 대한 균형을 맞춰주기 위해서 가중치 λk을 더해줄 수 있다. total loss는 다음과 같다.
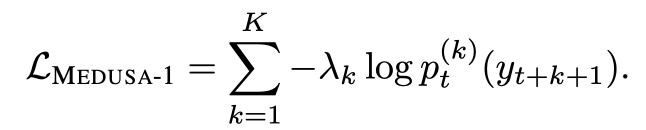
실제로 λk를 0.8과 같은 상수의 k번째 거듭제곱으로 설정한다.
3.2.3 MEDUSA-2: Joint Training
backbone model의 다음 토큰에 대한 예측 능력과 아웃풋 퀄리티 보장을 위해서 3가지를 추가하였다. 그것이 MEDUSA-2..
MEDUSA-1과 비교하자면, 1은 백본 모델의 고정으로 head의 train에만 집중하였다. 2는 backbone과 head를 함께 훈련하는 전략이다.
combined loss : 백본 모델의 다음 토큰 예측 능력을 유지하기 위해서 백본 모델의 손실 함수인 cross entropy loss를 메두사의 손실함수에 더해주어야 한다.
가중치 λ0를 통해서 그 둘의 균형을 조절해준다. 다음은 전체 loss이다.
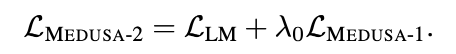
Differential learning rates : 이미 백본 모델은 잘 훈련되어 있고, 메두사의 헤드 부분은 훈련이 더 필요하기 때문에, 백본을 유지하면서 메두사 헤드의 수렴을 더 빠르게 하기 위해서 다른 learning rate를 사용한다.
Heads warmup : 훈련 시작 시 메두사 헤드의 손실이 크고, 이것은 기울기가 커지고 백본 모델의 파라미터가 왜곡되는 것을 야기한다.
우리는 이러한 아이디어를 따라서 두 단계의 훈련 프로세스를 차용하였다.
1단계: 오직 MEDUSA-1로 백본 모델만을 훈련시킨다.
2단계: 백본 모델과 메두사 헤드를 같이 학습시킨다.
구체적으로, 먼저 적은 epoch에서 백본 모델을 먼저 훈련시키고, 나중에 같이 백본 모델과 함께 메두사 헤드를 훈련한다.
이러한 간단한 전략 말고 λ0를 점점 증가시켜서 훈련하는 방법도 있는데, 둘 다 잘 작동한다는 것을 실험을 통해 파악하였다.
3.3 Extensions
3.3.1 Typical Acceptance
Leviathen이 제안한 speculative decoding paper에서는 원본 모델에서 다양한 아웃풋을 산출하는 rejection sampling이 사용되었다.
그러나, 후속 구현에서는 이 샘플링 방법이 sampling temperature가 올라갈 때 효율성 감소를 야기한다고 했다.
이때 sampling temperature에 대해서 설명을 하자면, temperature가 높으면 덜 확실한 후보에게 많은 확률을 부여함으로써 창의적인 아웃풋을 만들어낼 수 있다. 반대로, temperature가 낮으면 높은 확률만 선택하게 된다.
이 현상(온도가 높을 때 효율성 감소)을 설명하는 직관적인 예를 들어보자.
draft model = target model이고 greedy decoding을 사용한다고 할 때 모든 output이 허용된다.
반면, rejection sampling을 사용한다고 하면 완벽히 같은 분포를 같는 draft 모델이라고 해도 거부된다.
하지만 현실 상황에서는, 창의적인 답변을 위해서 temperature parameter가 사용되기도 한다. 그러므로 원래 모델이 초안 모델의 결과물을 받아들일 수 있는 기회가 더 많아져야 한다. 우리는 원래 모델의 분포와 일치시키는 것이 일반적으로 불필요하다는 것을 확인한다. 따라서 거부 샘플링을 사용하는 것이 아니라 typical acceptance 방법을 사용하여 그럴듯한 후보를 선택하는 것을 제안했다.
아래의 부등식이 참이면 토큰이 통과된다.
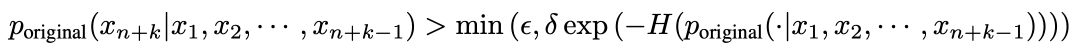
우변을 해석해보겠다.
H(·)은 엔트로피 함수를 나타낸다. 그리고 ϵ, δ은 하이퍼 파라미터이다.
이 기준은 두 가지 관측에서 의거하였다.
1) 상대적으로 높은 가능성을 가진 토큰은 의미있다.
2) 엔트로피 값이 높을 때 다양한 결과값이 합리적이라는 관찰을 하였다.
δexp(-H(poriginal(·|x1, x2, ... , xn+k-1)))을 해석해보자면
H(·)가 커질 때, 위의 값은 반비례하다. 즉 작아진다.
이때 min(ϵ, δexp(-H(poriginal(·|x1, x2, ... , xn+k-1))))이므로, ϵ와 위의 식 중 더 작은 값이 수용된다.
더 작은 값이라고 하면, H가 더 클 수록 유리하다는 것이다. H가 크다는 것은 분산이 높다는 것이고 후보의 다양성이 높다는 것을 뜻하게 된다.
만약 H(·)가 작은 값이라하는 것은 어떤걸 나타내는 걸까?
그것은 분산이 적다는 뜻이다. 즉, 가장 유망한 token 후보가 존재한다는 것!
** 하이퍼 파라미터: 사용자가 직접 값을 설정해줌.
3.3.2 Self-Distillation
3.2절에서는 타겟 모델의 아웃풋 분포에 맞는 훈련 데이터셋이 있을 것이라고 가정하였다. 그러나 항상 이러한 경우만 있는 것은 아니다. 예를 들어서, 모델 소유자는 훈련 데이터 없이 모델만 출시할 수도 있고, 모델이 훈련 데이터 세트와 다른 모델의 출력 분포를 만드는 강화 학습(RLHF) 절차를 거쳤을 수도 있다. 이러한 문제를 해결하기 위해서, 모델 스스로 메두사 헤드를 위한 데이터셋을 만들어내는 automated self-distillation을 제안한다.
이 방식은 간단하다. 공개된 seed data를 가지고, 대화를 하게 하는 것이다. self-talk 기능으로 인해 첫 프롬프트만 모델에 입력하면, 모델이 스스로 여러 라운드의 대화를 생성할 수 있다. 이렇게 생성된 대화 데이터는 데이터셋을 풍부하게 만들고, 모델이 실제 대화 상황을 더 잘 이해하고 대응할 수 있도록 한다.
그러나, 메두사1에서는 충분한 것과는 달리 메두사2에서는 낮은 생성 퀄리티를 보인다. 자기 대화를 통해 생성된 데이터셋만으로는 백본 모델이 처음에 학습했던 데이터의 다양성과 복잡성을 충분히 반영하지 못하기 때문이다. 이렇게 생성된 데이터셋은 백본 모델이 이미 알고 있는 정보를 단순히 재생산하는 경향이 있을 수 있고, 모델이 새로운 상황이나 더 복잡한 언어 구조에 대해 학습하는 데는 제한적일 수 있다. 때문에 기존 모델의 예측 확률 분포를 활용해야한다.
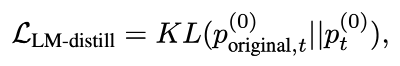
KL : KL divergence
KL divergence란? 분포 p와 q의 정보량의 차이이다
아래 링크를 들어가면 entropy, cross entropy, KL divergence의 설명을 볼 수 있다.
출처: https://hyunw.kim/blog/2017/10/27/KL_divergence.html
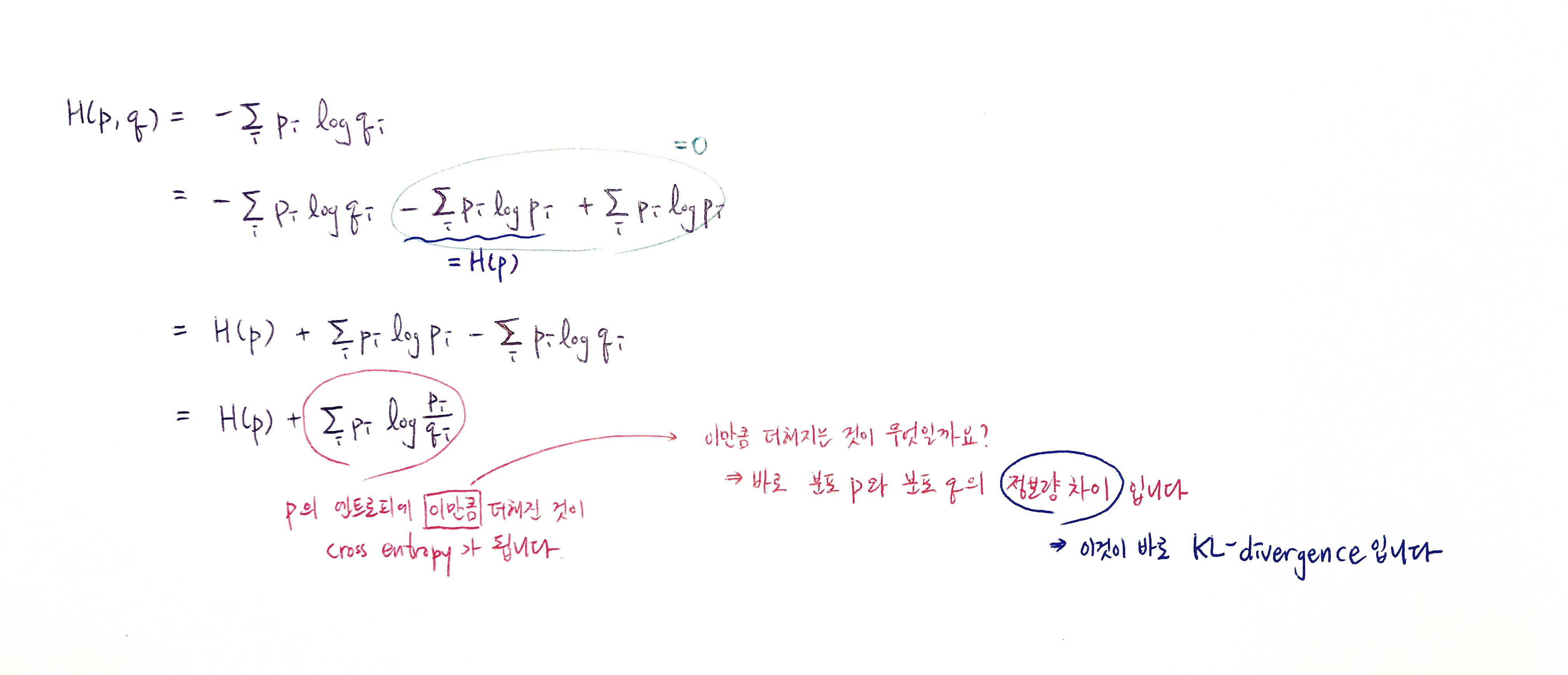
여기서 p(0)original,t는 원본 모델이 position이 t일 때 예측한 확률 분포를 말한다.
그러나 원본 모델의 예측을 얻기 위해선, 두 개의 모델을 훈련 동안 유지해야하고, 메모리 요구량이 올라간다. 이러한 문제를 더욱 완화하기 위해, self-distillation 설정을 이용하는 간단하면서도 효과적인 방법을 제안한다.
백본 모델을 fine-tuning 하기 위해서 LoRA와 같은 파라미터-효율적 어댑터를 사용하는 것이다. 이 경우 양자화 없이 LoRA를 사용하는 것이 바람직하며, 그렇지 않으면 teacher 모델이 양자화 모델이 되어 생성 품질이 저하될 수 있다.
3.3.3 Searching for the Optimized Tree Construction
3.1.2절이 카타시안 곱으로 트리를 구성하는 가장 쉬운 방법이다.
그러나, 총 노드의 개수가 정해져있는 경우에는 그것이 가장 좋은 선택이라고 할 수 없다. 직관적으로, 다른 헤드로부터 나온 높은 예측으로 구성된 후보들은 다른 정확도를 가지고 있다. 그러므로 정확도 추정을 활용하여 트리 구조를 구성할 수 있다.
저자들은 이러한 다양한 정확도를 고려하여, 전체 트리의 구조를 구성하고자 한다. 즉, 각 노드가 대표하는 후보(예측)의 정확도 추정치를 활용하여, 노드를 트리에 추가하는 방식을 최적화하려는 것
더 높은 정확도를 가진 후보를 상위에 배치하고, 더 낮은 정확도를 가진 후보는 하위에 배치하거나 제외함으로써, 트리 전체의 성능을 높이려고 한다.
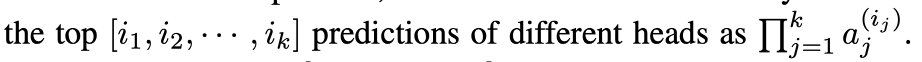
다른 헤드에서 나온 상위 예측들을 [i1, i2, ... , ik]라는 I 집합으로 표현하였다. ak(i)는 k번째 헤드의 i번째 top prediction을 나타낸다.
트리는 초기에 Cartesian product 방법으로 만들어지고, 그 후에 상위 k 예측의 통계적 기대치를 기반으로 pruning을 진행한다.
4 Experiments
experiments의 세팅은 생략하고 figure들을 해석만 써보려 한다.
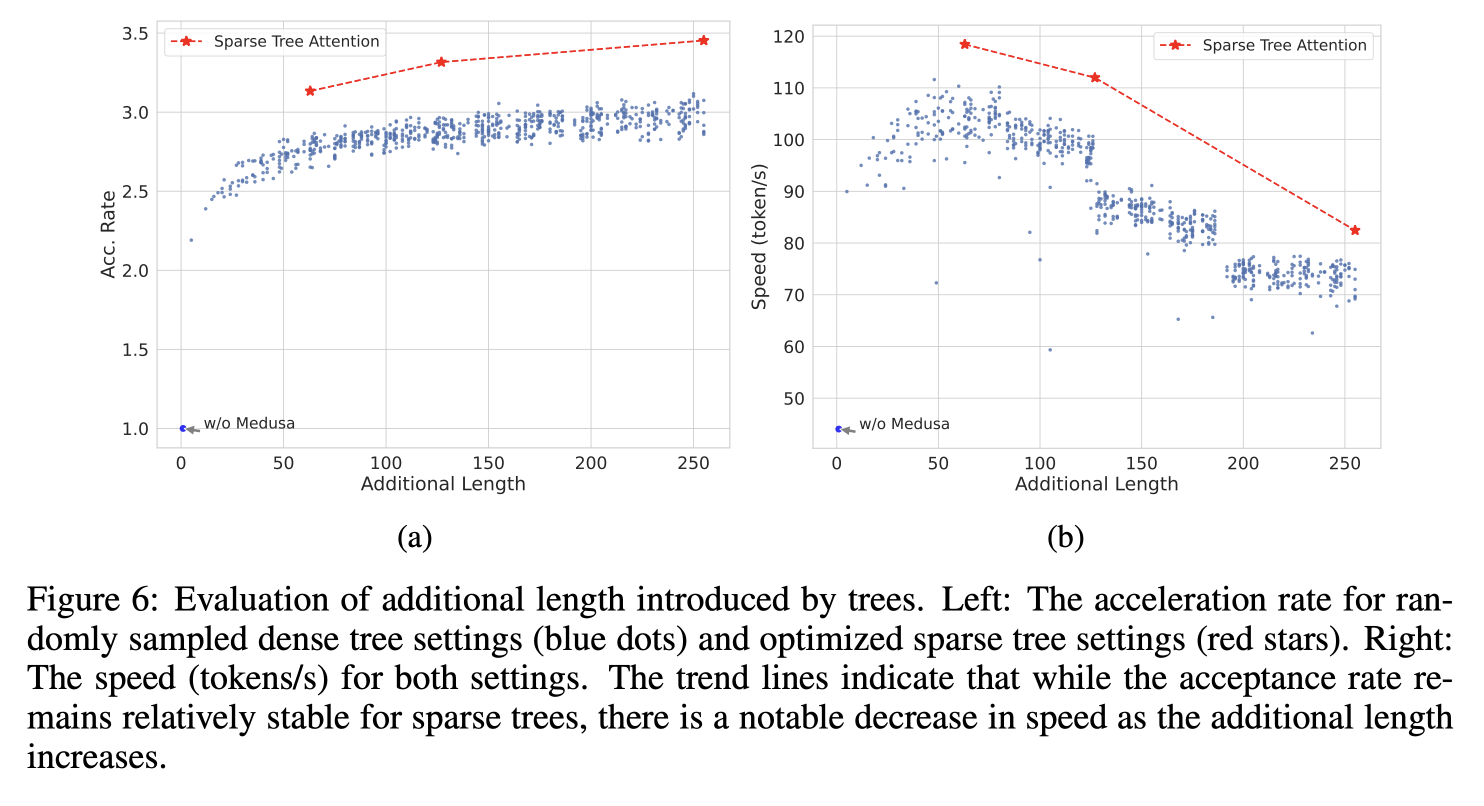
Additional Length는 tree attention이 추가적으로 생성해야할 길이를 나타낸다. 즉, medusa head가 새로 생성할 토큰의 개수.
fig6(a)의 y축은 Acc rate로 각 디코딩 스텝에서 생성하는 토큰의 개수이다. 일반 auto-regressive decoding의 경우는 1.0이다.
빨간색 선은 메두사를 통해 optimize된 sparse tree setting이고,
파란색 점은 랜덤하게 샘플된 dense tree setting이다.
fig6(b)의 y축은 Speed(token/s)로 얼마나 빨리 토큰을 처리할 수 있는지를 의미한다.
sparse tree 구조가 처리 속도를 일정하게 유지하는 데 도움을 주지만, 하드웨어의 한계로 인해 전반적인 처리 속도가 줄어들 수 있음을 설명하고 있다. 즉, 트리의 복잡성이 증가하면 하드웨어가 더 많은 계산을 해야 하므로, 속도가 느려지는 단점이 있다.
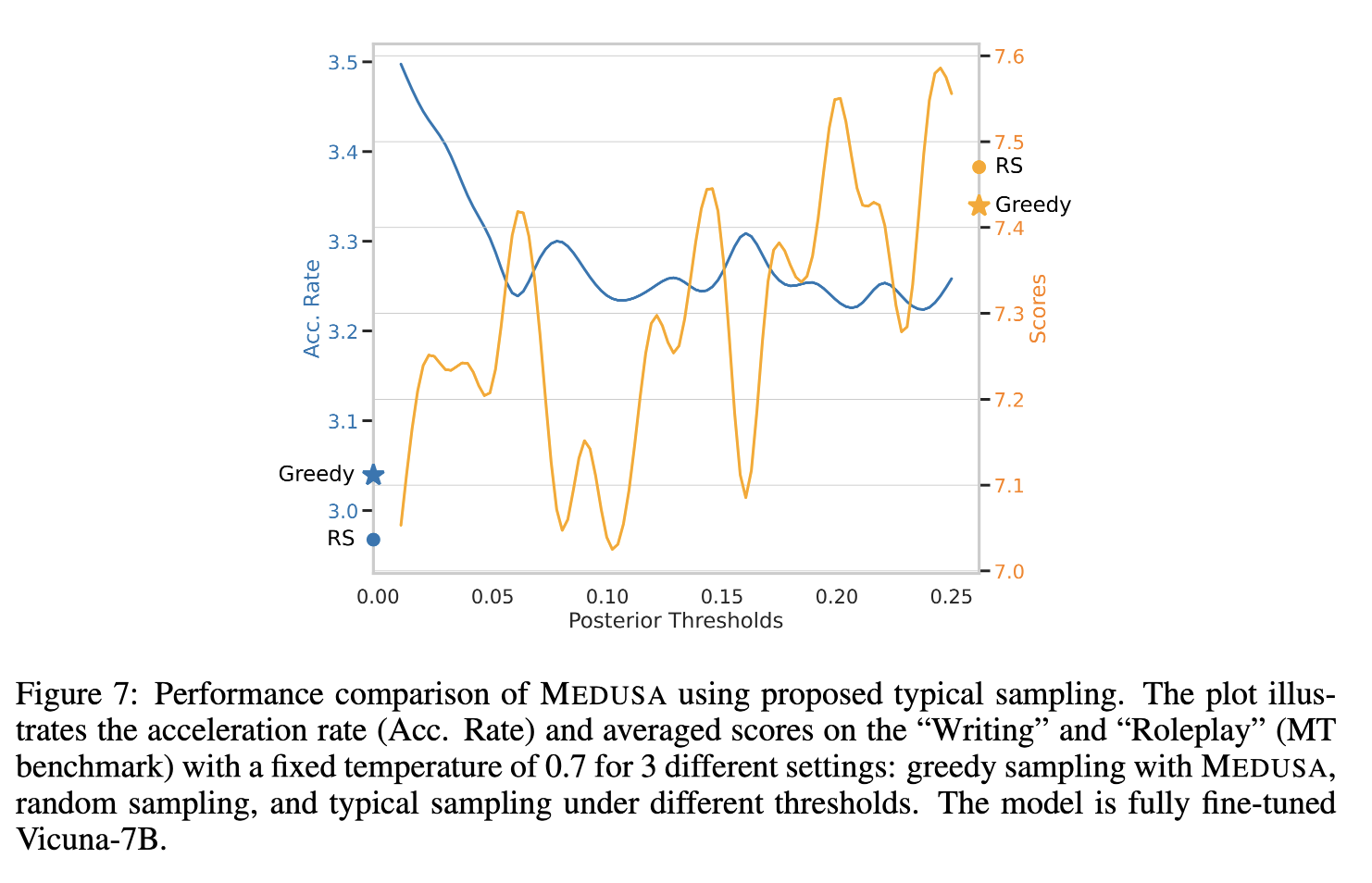
Fig7의 x축은 threshold인 ϵ이다. 0.01부터 0.25까지 0.01씩 늘려서 실험을 진행하였다.
파란색 선은 Acc rate(각 디코딩 스텝에서 산출된 토큰의 개수)이고, 노란색 선은 scores on the “Writing” and “Roleplay” (MT benchmark)이다.
감소된 acc rate을 희생시키면서 score의 상승이 존재한다는 것을 확인할 수 있다.
게다가, 창의성을 요구하는 작업들에 대해, 기본 랜덤 샘플링은 그리디를 능가한다는 것을 알 수 있다. RS --> random sampling, Greedy --> Greedy sampling

위 테이블2를 통해서 MEDUSA2는 1의 성능을 유지하며, 속도를 향상한다는 것을 알 수 있다.
Discussion
메두사의 핵심 장점은 심플함, 파라미터 효율성, 존재하는 시스템과의 쉬운 통합이다. 또한, reasonable output를 만드는 동안 발생하는 rejection sampling의 복잡성을 typical acceptance이 없앴다.
결론적으로 fine-tuning 절차가 원본 모델의 퍼포먼스에 영향을 주지 않으면서 높은 품질의 생성을 보장한다.
