self attention의 Key, Query, Value 간의 이해가 잘 안돼서
따로 포스팅을 해보겠다.
background
hidden state: 각 token을 처리할 때마다 생성됨. 이는 해당 시점에서의 토큰이 문장 내에서 어떤 의미를 가지며, 다른 토큰들과 어떤 관계를 맺고 있는지를 나타내는 벡터로 볼 수 있음. 쉽게 말하자면 현재 t 시점에 생성된 ht vector라는 것!
Wq, Wk, Wv는 무작위 값으로 초기화 되어있고, 이를 back propagate하여 점차 개선해 나가는 것!
attention score: 각 키(또는 관련된 단어)가 주어진 쿼리(또는 현재 단어)에 얼마나 중요한지를 평가하는 지표
Q, K, V란?
그림을 통해 이해를 해보자.
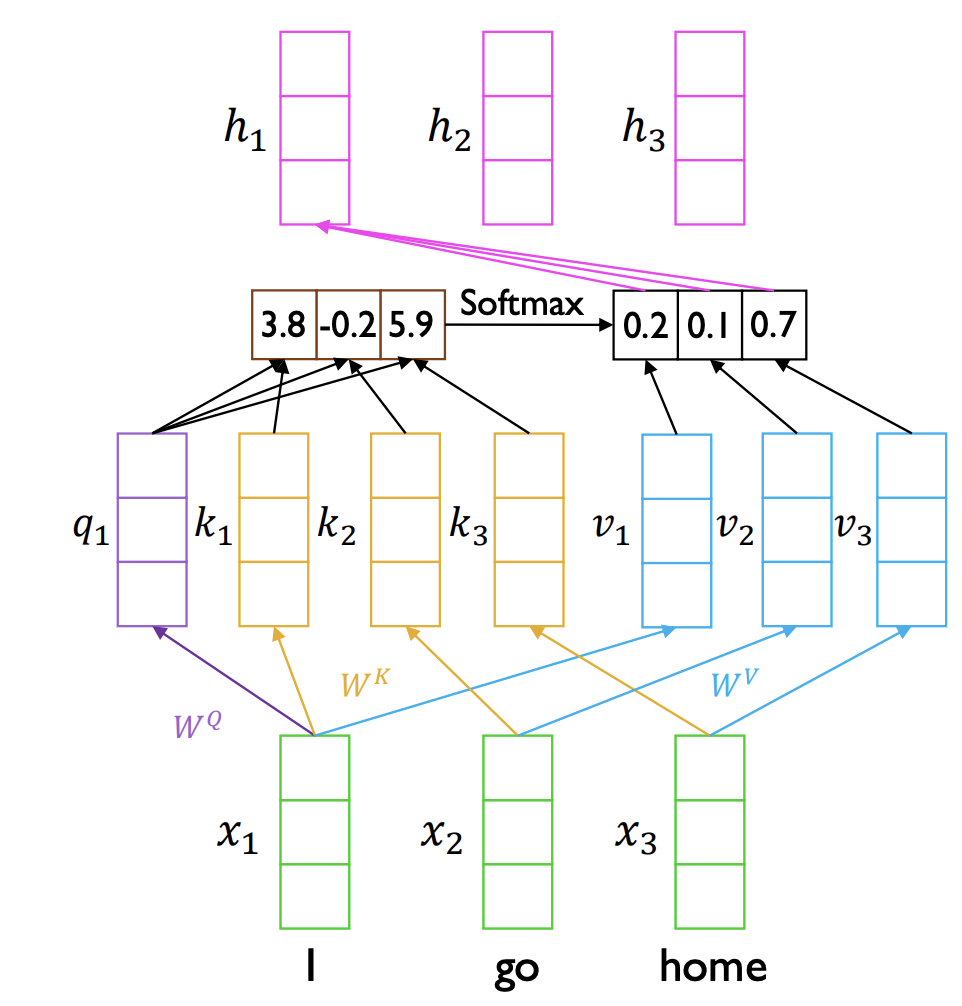
현재 input으로 "I go home"이라는 문장이 들어왔고,
이 문장을 ["I", "go", "home"]이라고 tokenize했다고 하자.
이를 차례대로 x1, x2, x3라고 하겠다.
그럼 x1의 hidden state h1을 만드는 과정을 나타내면 저 위의 그림과 같다는 것이다.
먼저 x1 ✕ Wq를 해서 q1을 만든다.
그리고 x1, x2, x3 ✕ Wk해서 key vector k1, k2, k3가 생성된다.
이렇게 만들어진 q1과 k1, k2, k3를 내적해주면 attention score가 나온다!
즉, 각 key(I, go, home)가 현재 쿼리인 x1(I)에 대하여 얼마나 중요한지 나타내는 것이다. 이를 softmax 함수를 통해 확률적 가중치로 변형해준다.
이후 value vector v1, v2, v3과 위의 값(0.2, 0.1, 0.7)을 곱해서 hidden state h1을 생성하게 되는 것이다.
h1 = (0.2 v1) + (0.1 v2) + (0.7 * v3)
이 과정을 행렬 연산으로 수행하도록 나타낸 것이 바로 아래와 같은 그림인 것이다!
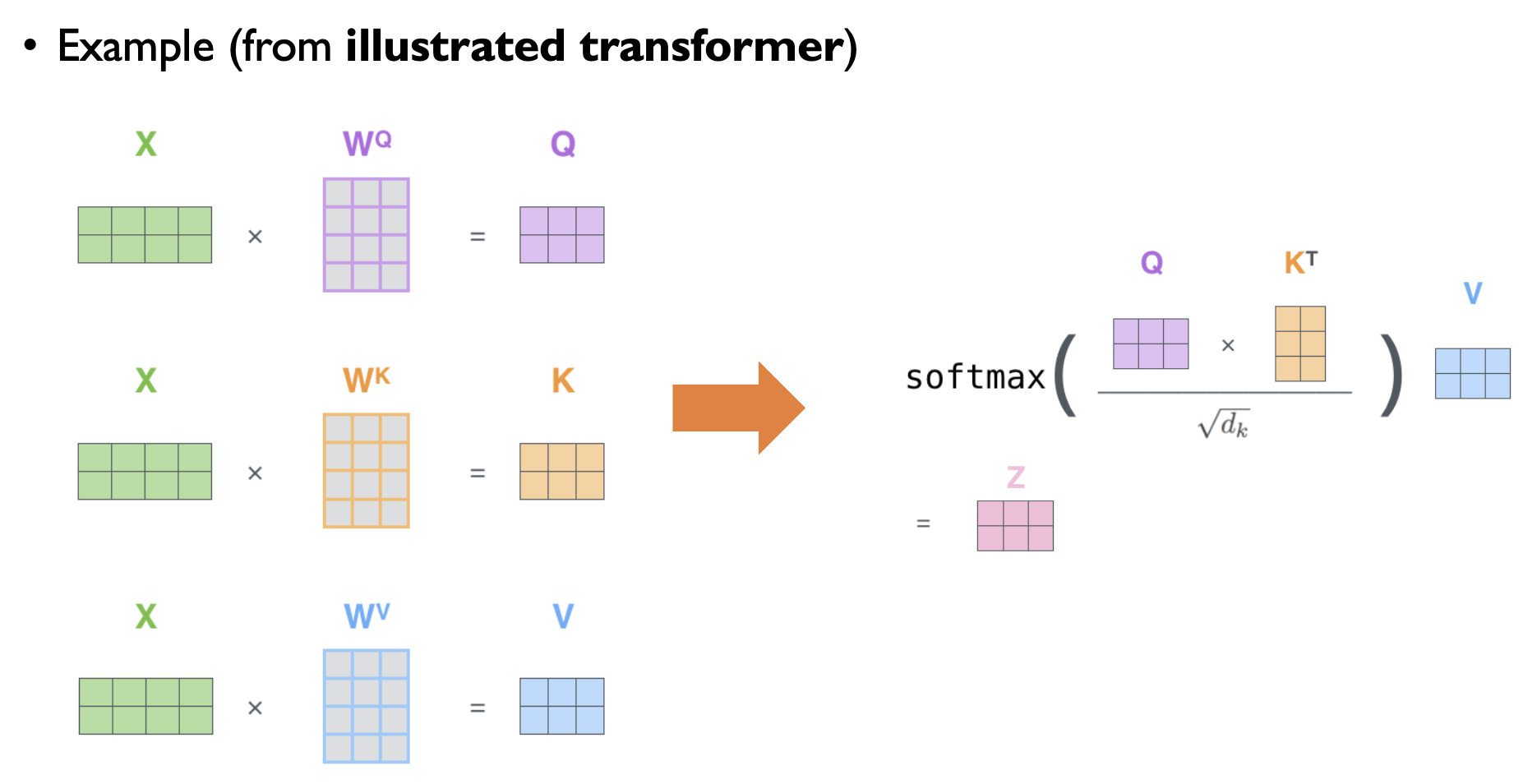
저 밑에 루트 dk(dk의 제곱근)으로 나눠주는 것이 무엇이냐?
먼저 dk는 key vector의 차원의 수다.
Q와 K transpose가 내적을 하게 되는데, 이 값이 매우 커지게 되면 문제가 발생한다. 이는 softmax 함수가 하나의 값에만 모든 확률을 몰아주게 되는 문제이다.
이를 방지하기 위해서 dk의 제곱근으로 나눠준 뒤, 그 값을 softmax에 넣어준다.
