Paper Review #5 - MERIOT RESERVE: Neural Script Knowledge through Vision and Language and Sound
AIComputer VisionConversational AIKBKGKnowledge ExtractionKnowledge GraphKnowledgeBaseMultimodalMultimodal Knowledge GraphNERNLPREchatbotieinformation extraction
MultimodalKnowledgeGraph
목록 보기
3/7
Zellers, Rowan, et al. "Merlot reserve: Neural script knowledge through vision and language and sound." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
MERLOT RESERVE
: 멀티모달 환경으로부터의 새로운 학습 목표를 통해 비디오를 표현하는 모델(Multimodal Event Representation Learning Over Time, with RE-entrant SupERVision of Events)
Overview
- 비디오가 주어지면 텍스트 조각과 음성을 Mask token으로 재배치하고, 모델은 정확한 Masked out snippet을 고름으로써 학습
- 각 modality가 서로를 교육하는 joint representation 학습
- modality의 타입을 뛰어 넘는 script knowledge 학습을 위한 새로운 contrastive masked span learning 소개
- visual recognition을 처음부터 학습하도록 맞춤화 된 프레임워크 - 각 비디오 프레임을 상황에 맞는 대본의 표현과 일치시킴
Contribution
- RESERVE(Multimodal script knowledge 모델)를 통해 vision, audio, text 데이터를 혼합
- 새로운 contrastive span matching을 통해 제안 모델이 text와 audio를 자가 감독 학습할 수 있음
RESERVE
- video:
- splitted video into a sequence of non-overapping segments in time: (default 5 seconds)
- Segment 구성
- A frame from the middle of the segment:
- ASR tokens spoken during the segment:
- Audio of the segment:
- text 는 audio 에서 모델에 의해 자동적으로 표기되었기 때문에 적은 양의 정보를 포함하고 있다고 가정할 수 있음. 따라서 각 segment 들에 정확히 하나의 text나 audio가 있는 모델을 제공함.
- 사전훈련 중 텍스트와 오디오의 일부를 추가로 마스킹 하여서 누락된 것을 복구함
Architecture
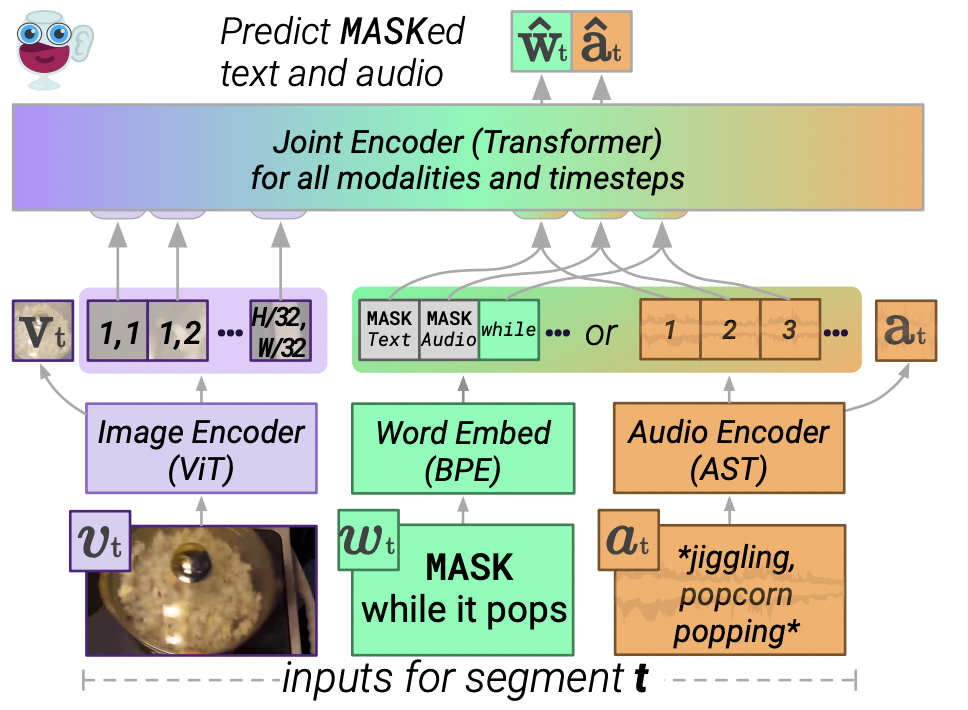
-
각 modality에 대해 독립적으로 사전 엔코딩을 수행함(images/audio- Transformer, text- BPE embedding)
-
모든 representation을 통합하기 위해 joint encoder 학습
-
Image encoder
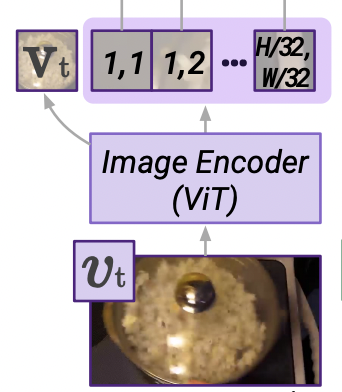
- Vision Transformer(ViT; Alexey Dosovitskiy, et. al., "An image is worth 16x16 words: Transformers for image recognition at scale", arXiv preprint, arXiv: 2010.11929, 2020, 3,4,6,19)사용
- Transformer 작업 이후 16의 patch size를 사용해 2x2의 쿼리-키-값 attention pool에 적용하여 사이즈의 이미지를 차원의 feature map으로 변경함
-
Audio encoder
-
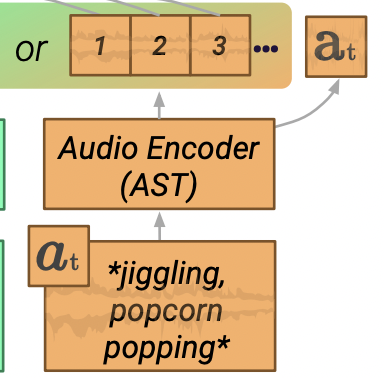
-
segment 의 audio 를 같은 크기의 subsegment 3개로 나눠줌(텍스트 마킹 시 길이 호환을 위해)
-
Multimodal Audio Spectrogram Transformer를 사용해 각 subsegment를 독립적으로 인코딩
-
세개의 feature map을 통합하여 모든 5초짜리 audio를 의 크기로 만들어줌
-
-
Joint encoder
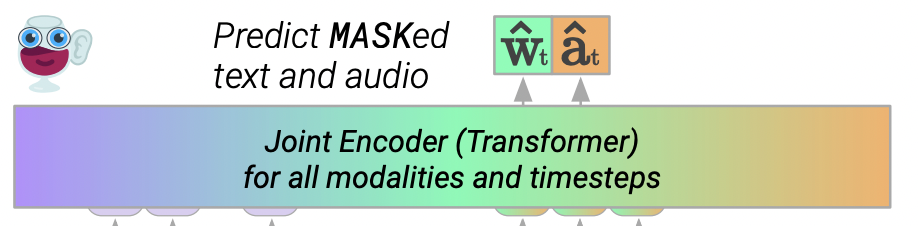
- Bidirectional Transformer를 사용해 모든 modality를 공동으로 인코딩함
- 모든 Objective()최종 레이어 hidden state의 linear projection을 사용함
- 독립적으로 엔코딩 된 target
- 각 modality에 대해 독립적으로 인코딩 된 target representation을 동시에 학습하여 joint encoder를 감독함
- input에 CLS를 추가하고 해당 위치의 최종 hidden state 나 를 얻어줌.
- Text의 경우, CLS와 candidate text span의 embedded token에서 target 를 계산하여 분리된 양방향 트랜스포머 확장 인코더를 학습
Contrastive Span Training
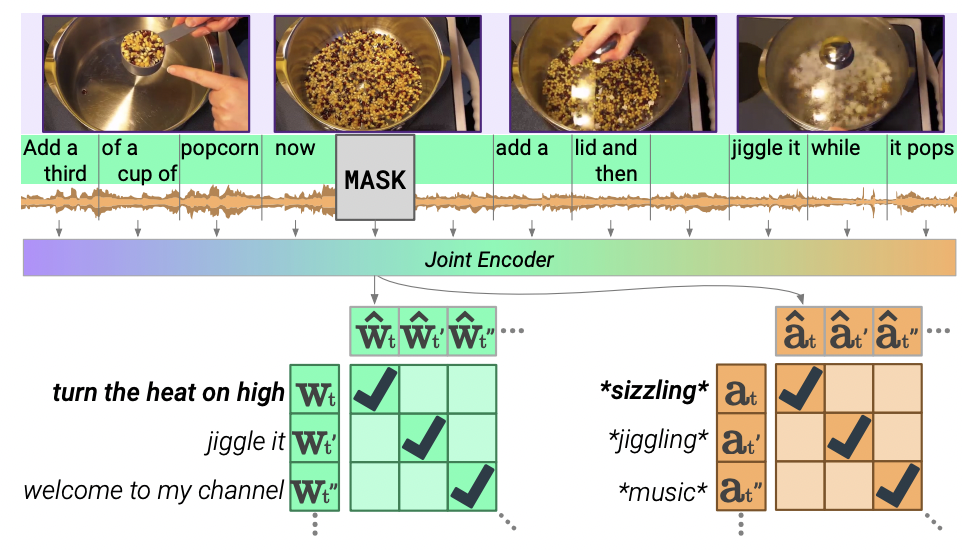
- 입력으로 들어온 각각의 video segment는 video frame, text, audio의 subsegment를 포함함
- 세분화된 audio segment는 joint encoder에 의해 fusing 되기 전에 audio encoder에 의해 독립적으로 인코딩됨
- 텍스트와 오디오의 subsegment의 25%를 특수한 Mask토큰으로 대체하여 훈련시킴
- 이때 모델은 해당 범위의 독립적인 인코딩으로만 MASK 상단의 representation과 일치시켜야함
- VisualBERT(독립 토큰에 대한 예측)로 이미지를 캡션에 일치시키는데, 이때 개별 토큰보다 더 높은 수준의 semantic unit에서 표현을 예측함
- 제안 모델은 audio와 text 모두에서 학습을 할 수 있도록하여 representation의 품질을 해칠 수 있는 raw perceptual input 또는 token를 기억하는 것을 방지함
- Masked text와 audio objecive 외에도 비디오 프레임을 스크립트의 상황별 인코딩과 일치하도록 모델을 동시에 훈련시킴
- joint encoder는 전체 비디오의 대사를 한번에 인코딩하여 segment 별로 single hidden representation 를 추출함.
- Avoding Shortcut Learning
- 동일한 modality가 주어진 perceptual modality을 예측하기 위해 모델을 훈련하는 것이 training loss는 낮지만, representation이 좋지 않은 shortcut learning으로 이어질 수 있음
- shorcut learning이 발생하면 마이크나 카메라 렌즈의 변형과 같은 감지할 수 없는 특징을 학습하는 경우가 생길 수 있음
- 이를 해결하기 위해 오디오를 target으로 사용하며 두 종류의 마스킹 된 비디오에 대한 동시 훈련을 수행함
- Audio 단일 타겟: 비디오 프레임과 자막만 제공하여 Mask된 빈칸을 채우는 오디오와 텍스트의 representation 생성
- audio 입력: 각 segment에서 model video frame과 자막, 오디오를 제공함. 모델은 입력으로 오디오가 제공되기 때문에 Mask 된 텍스트에 대한 representation만 생성

재밌나?