Paper Review #4 - Gaia: A fine-grained multimodal knowledge extraction system
MultimodalKnowledgeGraph
Li, M., et. al., "Gaia: A fine-grained multimodal knowledge extraction system.", In proceeding of the 58th Annual Meeting of the Association for Computational Linguistics:System Demonstration, pp.77-86, 2020
Motivation
지식 그래프를 구축하기 이전에 raw data에서 지식을 추출하는(KE) 작업이 우선시 되어야한다. KE는 구조화 되지 않은 raw data의 해당 엔티티에서 entity, relation, event을 찾고 이를 기존의 KB(Knowledge Base)에 연결하는 작업이다. 해당 논문에서는 데이터의 유형이나 언어에 구애받지 않는 KE 작업과 추출된 지식들을 세분화 된 유형으로 분류하기 위한 모델인 GAIA를 제안하였다.
Contribution
GAIA(는 데이터의 언어와 양식에 구애받지 않고 포괄적으로 지식을 추출, 통합하며 지식 요소를 coarse-grined/Fine-grained 유형으로 나눈다. 따라서 멀티미디어 환경에서 텍스트 데이터, 이미지, 비디오 프레임에서 보완지식을 추출할 수 있으며 데이터의 타입과 관계없이 지식을 통합할 수 있다.
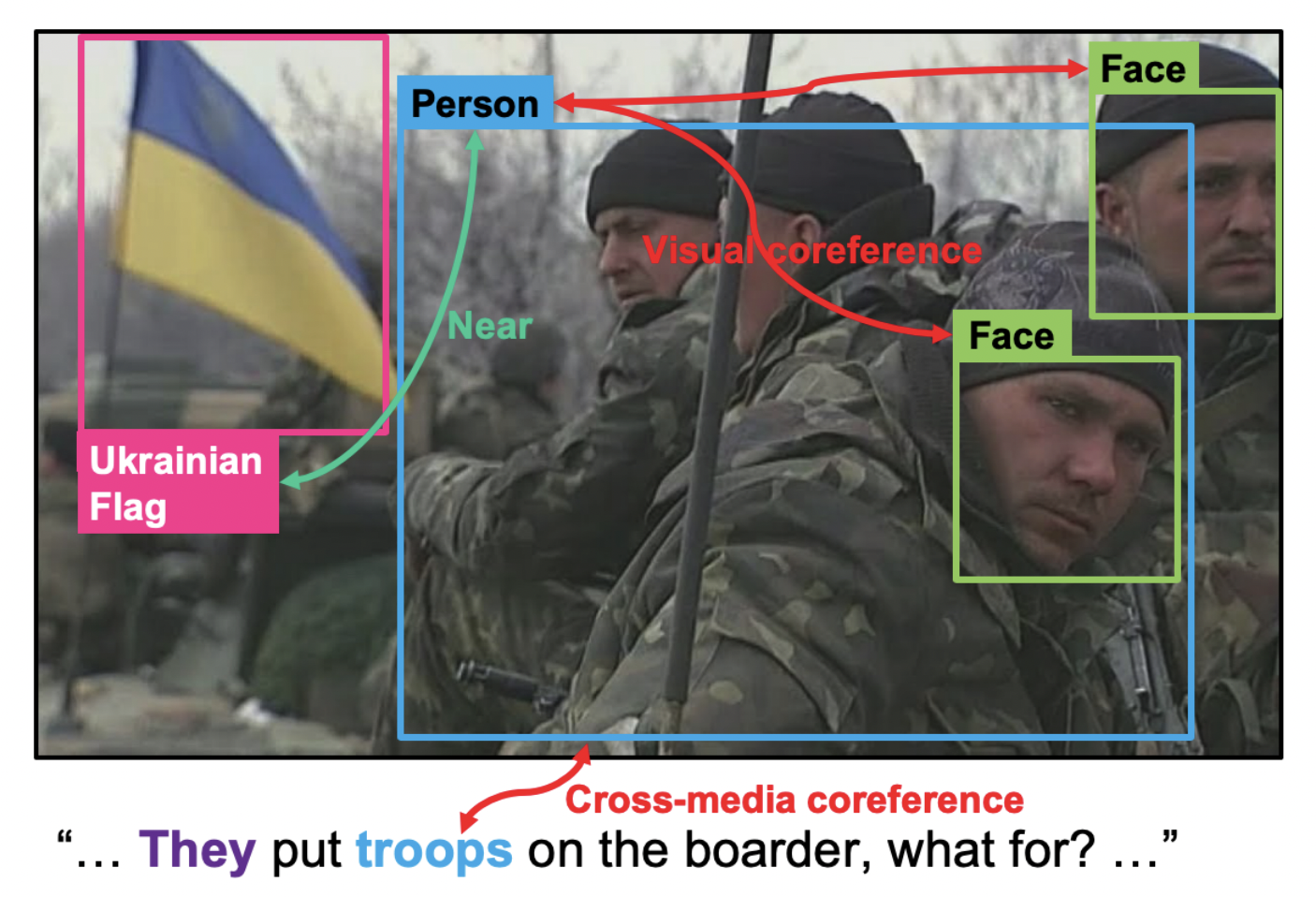
위 그림을 예로 들면 기존의 text entity 추출 시스템은 텍스트에서 언급된 troops라는 단어를 명목적으로 추출하고 entity linking 시스템이 우크라이나 국기를 인식하고 troops와의 관계를 KB에서 우크라이나 국적을 가진 시민으로 표현한다. 정확하진 않지만 여기서 탐지된 사람들이 우크라이나인이라는 것을 추론할 수 있다.
하지만 GAIA는 이미지에서 감지된 사람들이 troops라는 근거를 제공한다. 텍스트와 이미지 데이터에서 추출한 knowledge 사이의 연관성을 확립해 사진에서 보이는 군인들이 우크라이나 시민이라는 것을 추론할 수 있게 한다.
Architecture
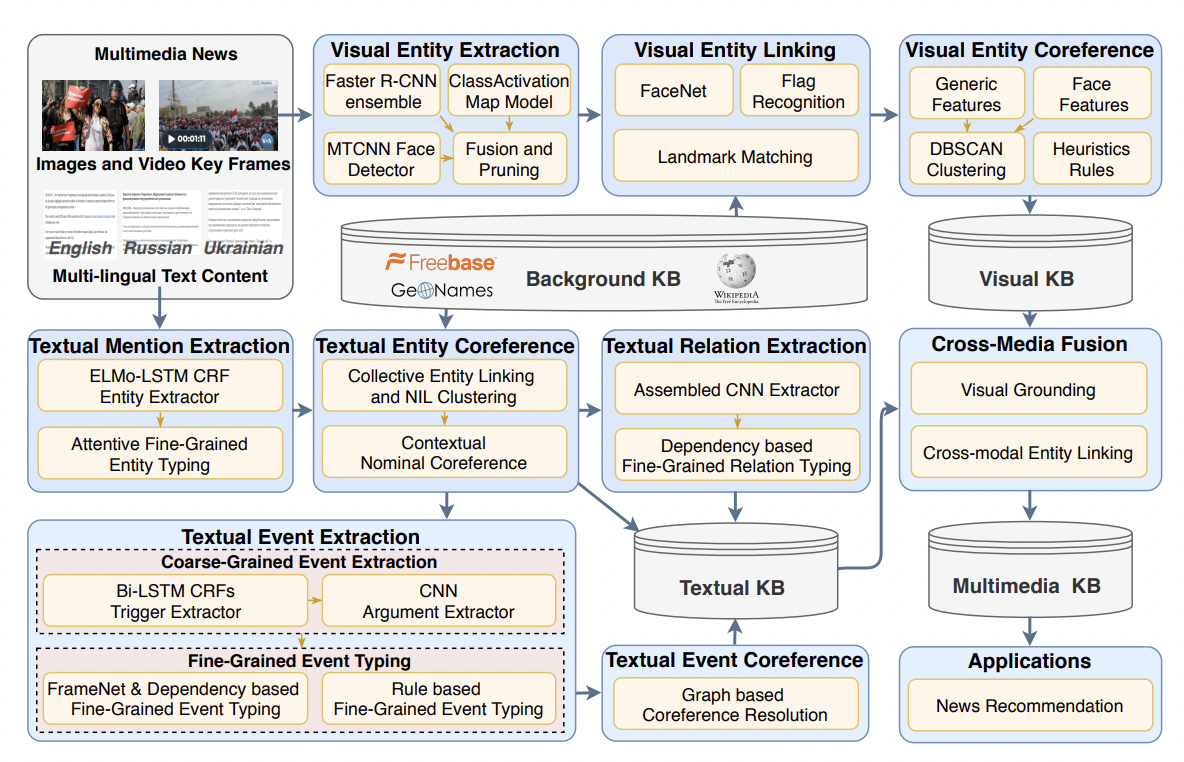
GAIA의 구조는 위 그림과 같다. system pipeline은 Text Knowledge Extraction(TKE) task branch와 Visual Knowledge Extraction(VKE) task branch로 구성되어있다. 각 branch는 입력된 것과 동일한 문서 집합을 가져오고 초기엔 각 modality의 정보를 인코딩하는 별도의 KB를 생성한다.
두 KB는 AIDA ontology를 따르는데,AIDA ontology의 예시는 이와 같다

(출처: Yu Ri Kang, "A Study on the utilization of ontology for extracting knowledge elements from text data", 1st Korean Artificial Intelligence Conference)
우선 각 Type의 하위 레벨을 만드는 type.subtype.subtype 형태로 Type을 세분화한다.
온톨로지는
1. top level type for the most coarse-grained level(eg. PER)
2. type.subtype for the next level(ev. PER.Politician)
3. type.subtype.subtype for the finest-grained level(eg. PER.Politician.Governor)
와 같은 3단계로 세분화 된다. GAIA는 이런 AIDA ontology를 활용해 추출한 각 knowledge element로부터 일관된 정보를 표현하기 위해 멀티미디어 결과를 통합한다. 다시 말해서, 두 branch 모두 형식별 추출을 KB로 인코딩하지만, 동일한 semantic space에 정의 된 유형으로 인코딩한다. 이 semantic space를 통해 cross-modal knowledge module을 통해 두 KB를 하나의 일관된 multimedia KB로 통합할 수 있다.
Text Knowledge Extraction
TKE 시스템은 입력 문서로부터 entity, relation, event를 추출한다. 이후 entity linking과 coreference를 통해 동일한 entity를 클러스터링하고 event coreference를 사용해 동일한 event끼리 클러스터링을 한다. TKE 시스템의 네 단계를 살펴보자.
1. Text Entity Extraction, Coreference
-
Coarse-grained Mention 추출
LSTM-CRF 모델을 사용해 coarse-grained entity를 추출한다. 사전훈련된 ELMo(Embedding from Language Model; 워드 임베딩 시 문맥을 고려하는 임베딩 방법) word embedding을 영어를 위한 input feature로 사용하고, Word2Vec 모델을 위키피디아 데이터에 사용해 러시아어 및 우크라이나어의 단어 임베딩을 생성한다. -
Entity Linking and Coreference
entity mention을 Freebase(메타데이터로 구성된 KB)와 GeoNames(사용자가 편집할 수 있는 지리데이터베이스)를 포함한 background KB의 기존 엔티티와 연결하는 작업이다. 동일한 Freebase entity에 연결할 수 있는 mention의 경우, coreference 정보가 추가되지만 KB에 연결할 수 없는 name mention의 경우, NIL 클러스터를 형성하기 위해서 각 문서 내의 동일한 named entity mention에 huristic rule을 적용한다. 이때 NIL클러스터는 동일한 entity를 참조하는 entity mention의 클러스터이긴 하지만 이에 맞는 KB는 존재하지 않는다. -
Fine-grained Entity Typing
잠재적인 type representation을 가진 fine-grained type분류 모델을 제안하였는데 mention을 context sentence와 함께 입력으로 받아들이고, 이에 가장 걸맞는 fine-grained type을 예측한다. 앞전의 Freebase entity linking 결과에서 YAGO(IBM의 KB)의 Fine-grainded type을 얻어 이를 AIDA ontology에 매핑한다.(뒷 내용은 이해 안 돼서 뺌 ㅠ.....) -
Entity Salience Ranking
더 나은 information distillation을 위해 각 문서마다 entity 별 중요도 점수를 할당한다. name mention에 대해 가중치가 더 높은 모든 Mention의 가중합 측면에서 entity의 순위를 매긴다. 예를 들어 한 entity가 명목상 언급되는 곳에서만 나타나는 경우 순위를 낮게 주는 식으로 이루어진다. 이렇게 매겨진 중요도 점수는 각 문서의 모든 entity들에 대해 정규화 과정을 거친다.
2. Text Relation Extraction
세분화된 relation 추출을 위해 먼저 language independent한 CNN 기반 모델을 적용하여 모든 언어에서 coarse-grained relation을 추출한다. 이후 탐지된 relation에 entity type constraint와 dependency pattern을 적용하여 fine-grained relation으로 다시 분류한다.
각 언어에서 이런 관계에 대한 dependency path를 추출하기 위해서 해당 언어를 대상으로 Universal Dependency parser(범용 종속 분석기)를 실행한다. 만약 ACE와ERE(Multilibgual Training corpus)에 Coarse-grained type이 없는 type의 경우 텍스트에서 직접 fine-grained relation을 탐지한다
3. Text Event Extraction and Coreference
이후 각 언어에 대해 Bi-LSTM 모델과 CNN 모델을 사용해 coarse-grained event와 argument를 추출한다. 이후 동사 기반 규칙, context 기반 규칙 및 argument 기반 규칙을 적용해 fine-grained event 유형을 탐지한다. 각 event type에 대해 그래프에서 event mention을 노드로 간주하고 노드간의 방향이 없고 가중치가 있는 edge가 해당 이벤트 간의 coreference 신뢰도 점수를 나타나도록 하였다. 이후 hierarchical clustering을 적용해 event cluster를 얻고, cluster feature에서 Maximum Entropy binary classifier를 훈련시킨다.
Visual Knowledge Extraction
VKE branch는 이미지와 비디오 키 프레임을 입력으로 가져와 TKE branch와 동일한 온톨로지에 의존해 하나의 KB를 생성한다. TKE와 마찬가지로 entity extraction, linking and coreference module로 구성된다.
1. Visual Entity Extraction
visual object detection과 concept localization model의 앙상블을 사용해 주어진 이미지에서 entity와 일부 이벤트를 추출한다. 사람과 차량과 같은 일반적인 물체 탐지를 위해 마이크로소프트의 MS COCO와 Open Images dataset에 대해 훈련된 두개의 R-CNN 모델을 사용하였다.
우선 시나리오별 엔티티와 이벤트 감지를 위해 이비지 수준의 label이 있는 open image 와 google image 검색을 결합해 training하는 방식으로 Class Activation Map(CAM) 모델을 훈련시킨다. 이미지가 주어지면 각 R-CNN 모델은 레이블이 지정된 bounding box를 생성하고, CAM 모델은 레이블이 지정된 heat map을 생성한 다음 bounding box 생성을 위한 threshold를 설정한다. 이후 모든 bounding box의 결합은 중복을 제거하고 품질을 보장하기 위해 huristic rule set에 의해 사후처리된다.
또한 별도의 얼굴 검출기인 MTCNN을 적용해 결과를 추가적인 person entity로, 검출된 객체 pool에 추가한다. 마지막으로 감지된 각 bounding box를 Visual KB에서 entity로 나타낸다. CAM 모델에는 일부 이벤트 타입이 포함되어 있기 때문에 이벤트로 분류된 bounding box에 대한 event entries을 생성한다.
2. Visual Entity Linking
엔티티가 visual KB에 추가되면, 큐레이션 된 KB에서 각 엔티티를 실제 엔티티와 연결해야한다. 위 과정이 복잡하기 때문에 사람과 배경 등으로 coarse-grained entity type별 별개의 모델을 개발하였다.
사람 유형의 경우 각 얼굴(전 단계에서 MTCNN에 의해 감지됨)을 가져와 사전정의된 신원 중 하나 또는 신원 미상으로 분류하는 페이스넷 모델을 훈련시킨다.
Google Image Search를 통해 background KB에서 각 사용자의 이름을 자동으로 검색하고, 얼굴이 포함된 상위 검색 결과를 수집 후 결과의 절반에 대해 Binary classifier를 교육한다. 이후 나머지 절반에 대해 평가하여 인식 가능하고 시나리오와 관련되었다고 판단 되는 신원 목록을 작성한다.
정확도가 threshold보다 높은 경우 인식 가능한 신원 목록에 해당 사용자 이름을 포함한다.
location, facility, organization entity를 인식하기 위해 Google Landmark에서 사전훈련된 DELF모델을 사용해 각 이미지를 미리 지정된 목록과 탐지된 건물을 일치시킨다. person entity와 비슷한 접근방식을 사용해 특정 location, facility, organization을 식별하는 건물 및 기타 구조와 같은 인식 가능한 시나리오와 관련된 랜드마크 목록을 작성한다.
마지막으로 geopolitical entity를 인식하기 위해 CNN을 훈련시켜 세계 모든 국가의 국기를 미리 결정된 entity list로 분류해 탐지한다. 이미지에서 국기가 인식되면 일련의 huristic rule을 적용해 현장의 일부 entity와 탐지된 국가 간의 국적 관계를 KB에서 생성한다.
3. Visual Entity Coreference
탐지된 각각의 bounding box를 output KB의 entity node로 캐스팅 하는 동안 하나의 고유한 실제 엔티티가 여러번 탐지될 수 있기 때문에 entity들 사이에 잠재적인 coreference link를 해결해야한다. 교차이미지의 coreference resolution은 여러 이미지에 나타나는 동일한 엔티티를 식별하는 것이 목표이다. 예를들어 두 이미지에서 나타나는 동일한 사람은 상관관계가 있다고 간주가 되어 동일한 NIL 클러스터에 배치된다. 이를 위해 우선 이미지 간 중복을 참지해야한다. entity coreference resolution을 위해 Youtube-BB 데이터셋에서 CNN을 훈련시켜 object bounding box를 다른 객체가 아닌 다른 비디오 프레임의 동일한 객체에 일치시킨다. 이 모델을 사용해 탐지된 각 bounding box에 대한 feature를 추출하고 DBSCAN을 적용한다.
동일한 클러스터의 entity는 coreference이며 visual output KB의 NIL 클러스터를 사용해 표시된다. 마찬가지로 face feature를 클러스터링 하기 위해서는 DBSCAN과 함께 사전훈련된 FaceNet 모델을 사용한다.
Cross-Media Knowledge Fusion
여러 타입의 데이터로 구성된 multimedia document set이 주어지면 TKE, VKE branch는 각각의 데이터 타입을 입력으로 가져와 Knowledge element를 추출하고 별도의 KB를 생성한다. 이러한 텍스트-visual KB는 동일한 온톨로지(AIDA Ontology)에 의존하지만 보완적인 정보를 포함하고 있다.
주어진 문서의 일부 Knowledge element는 텍스트에 명시적으로 언급되지 않지만 시각적으로 표시되는 경우도 있다. 또한 각 양식이 고유한 세분성을 가지고 있기 때문에 두 KB에 존재하는 Coreference knowledge elemnt 가 완전히 중복되지는 않는다. 예를들어 텍스트에서 troops라는 단어는 이미지에서 감지된 군복을 입고 있는 사람과 상관관계가 있는 것으로 간주될 수 있지만, 착용중인 군복이 개인의 군대 계급이나 조직, 국적을 식별하는 데 유용하게 쓰이는 추가적인 visual feature을 제공할 수 있다.
이러한 상호보완적인 성질을 이용하기 위해서 두 modality-specific kb를 단일의 KB로 결합한다.
두 타입의 KB 결합을 위해 visual grounding system을 사용한다. 이는 텍스트에서 추출된 각 entity mention에 대해 맥락화 된 feature를 추출하는 ELMo 모델에 전체 문장과 함께 텍스트를 제공한 다음, 이를 주변 이미지의 CNN feature map과 비교한다. 이는 각 이미지에 대한 relevance score 뿐만 아니라 각 이미지 내의 세분화된 relevance map(heat map)으로 이어진다. 충분히 관련 있는 이미지의 경우, bounding box를 얻기 위해 heatmap threshold를 설정하고, 해당 Box의 내용을 이미 알고있는 visual entity와 비교하고 가장 중복되는 entity에 할당한다.
만약 겹치는 entity가 발견되지 않으면 heat map bounding box를 사용해 새로운 visual entity를 생성한다. 이후 NIL cluster를 사용해 일치하는 text-visual entity를 연결한다. 또한 visual linking을 통해 동일한 background KB node에 연결된 cross modal entity를 제공한다.
