Paper Review #9 - MM-BiFPN: Multi-Modality Fusion Network with Bi-FPN for MRI Brain Tumor Segmentation
MultimodalKnowledgeGraph
Syazwany, Nur Suriza, et. al., "MM-BiFPN: Multi-Modality Fusion Network with Bi-FPN for MRI Brain Tumor Segmentation", IEEE Access 9(2021):160708-160720
이번 논문은 멀티모달 데이터를 처리하기 위한 multi encoder, late fusion, BiFPN 방식을 도입한 네트워크에 대한 논문이다.
본 논문에서 제안하는 MM-BiFPN은 크게
- Multimodal encoder
- Cross-modality fusion
- Shared decoder
의 세가지 피쳐로 구성되어 있다.
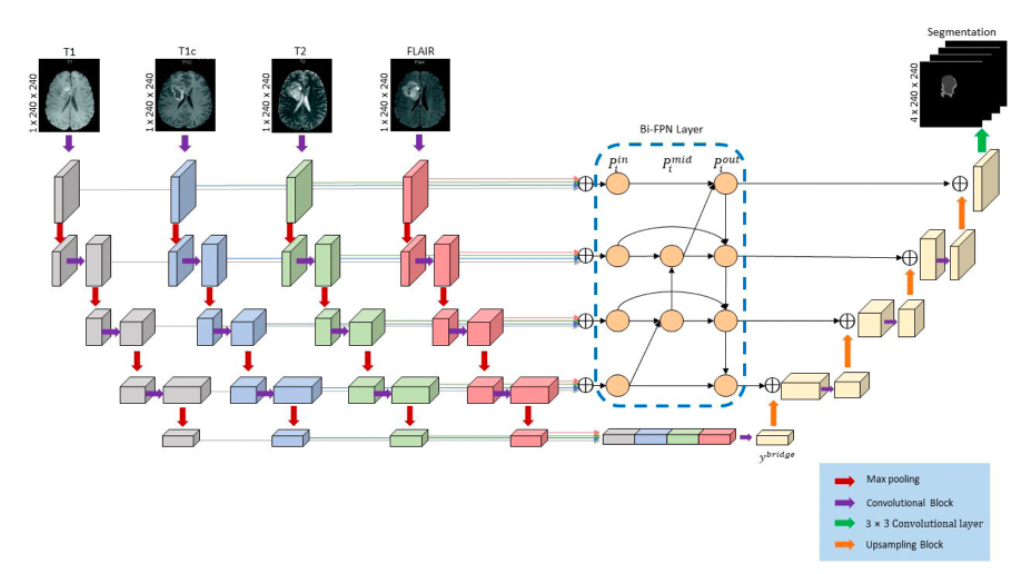
전체적인 구조는 이와 같다.
일단 각 모달리티 데이터가 따로 추출 되고, 추출된 데이터들은 depth-value에 따라 분류된다.
encoder에도 역시 modality별로 독립적인 encoder에 입력 되고 각 encoder의 output을 fusing하는 Late fusion 방식을 적용한다. 이후 업샘플링 방식으로 decoder에 입력한다.
해당 네트워크는 UNet과 비슷한 구조를 띠고 있는데, single input을 가진 UNet과 달리 Multiple input과 Bi-FPN을 적용했다는 데에서 차이가 있다.
UNet
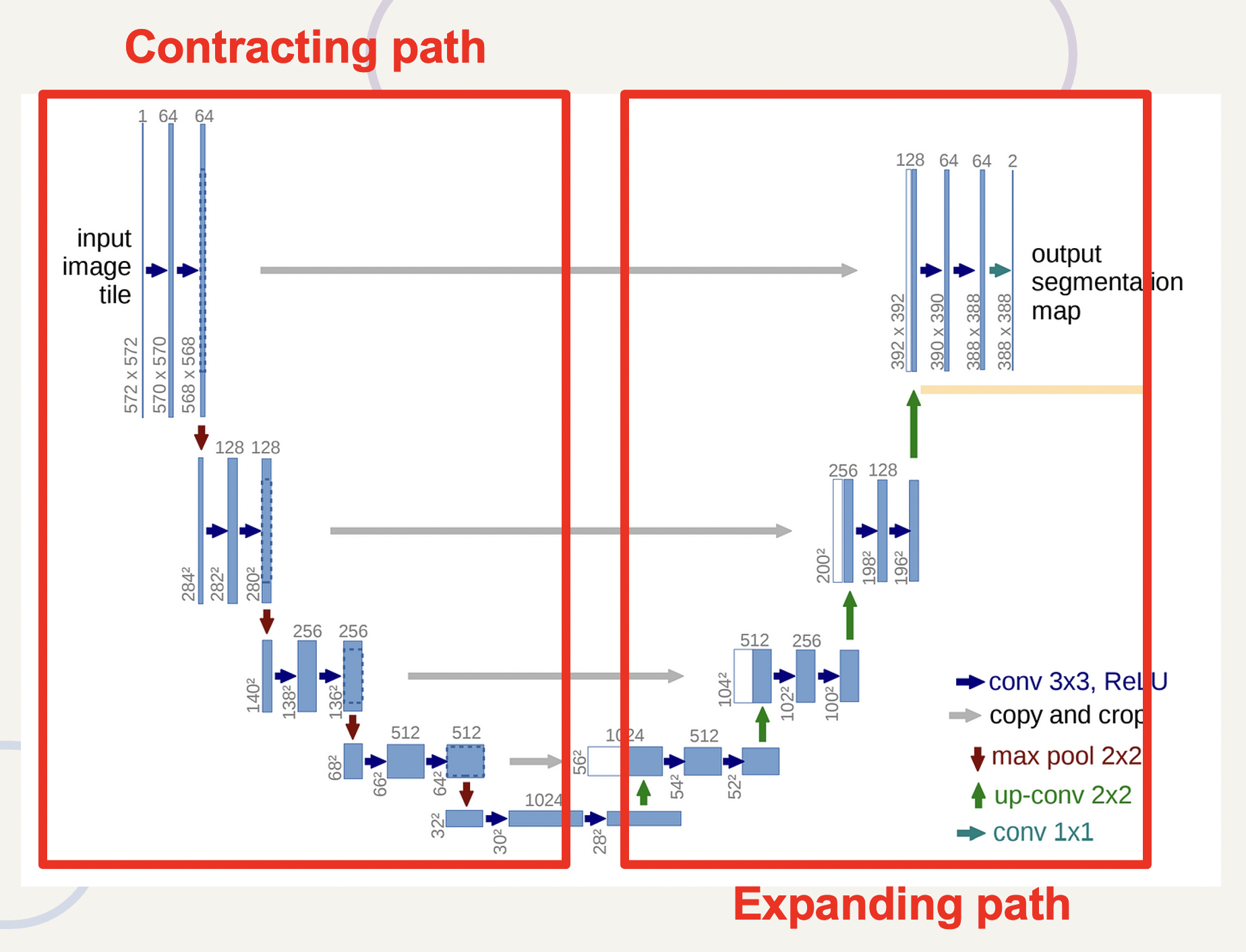
일단 UNet에대해 먼저 소개를 하자면, UNet은 이렇게 U자형 대칭구조를 가진 네트워크이다. 크게 Contracting path와 expanding path로 구분이 되는데 Contracting은 encoding, Expanding은 decoding 과정이라고 생각하면 된다. contracting path에서는 입력 이미지를 고차원 feature의 압축된 representation set으로 분해해서 입력 이미지의 context를 포착한다. 반면 extracting path에선 고차원 feature를 사용한 segmentation mask 생성을 통해 세밀한 localization이 가능하다.
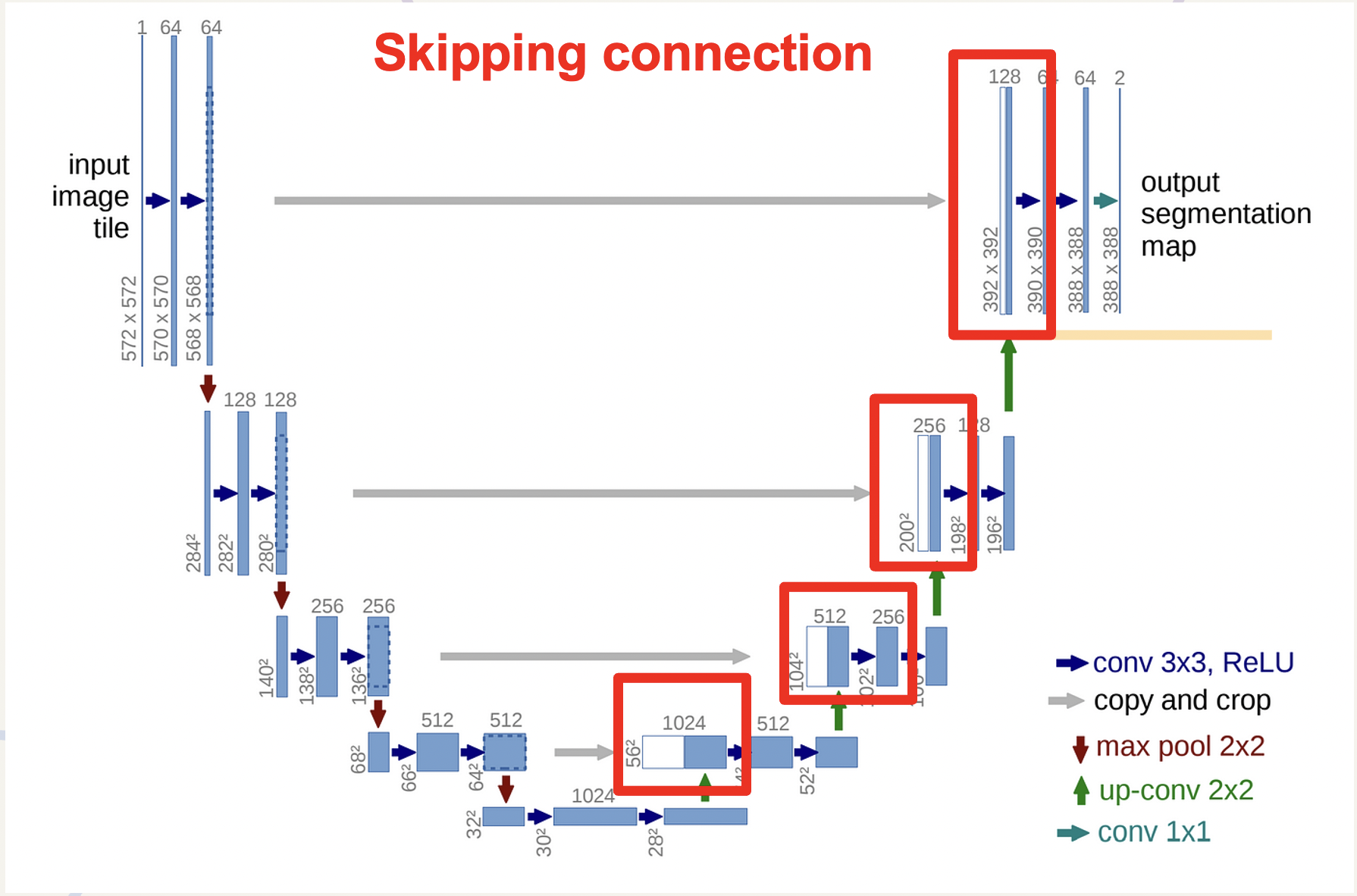
또 다른 특징 중에 하나는 Skipping connection 방식인데, upsampling을 통해 원본 이미지 크기로 복원을 해주고 그 과정에서 얕은 층의 output을 깊은 층의 input으로 사용함으로서 정보 손실을 막는 기능을 한다.
MM-BiFPN
1. Multimodal Encoder
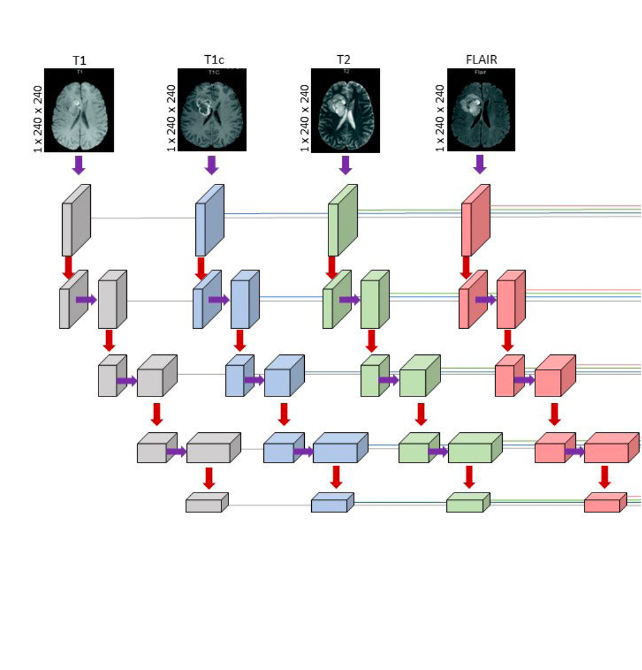
여기서는 이미지 자체를 3D 인풋으로 집어넣지 않고, 이미지를 슬라이싱해 depth를 가진 2차원으로 변형한다.
240x240x155의 원본 이미지를 155개로 슬라이싱된 240x240 사이즈로 변형 후 각 modality 별 encoder에 입력하는데 이때 다른 modality더라도 같은 depth에 있는 데이터라면 BiFPN의 같은 레이어로 입력된다.
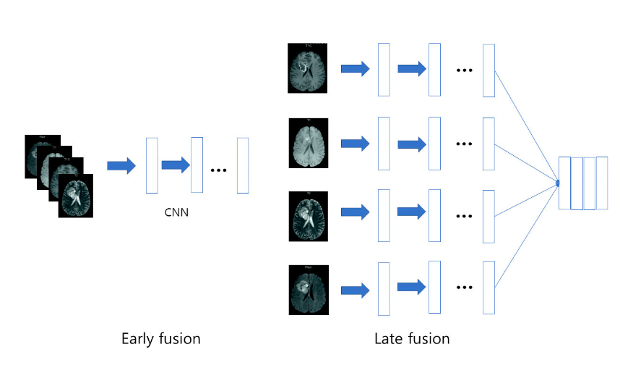
앞서 설명한 UNet의 구조를 활용해 MM-BiFPN의 encoding path를 구축하였는데, 기존 UNet은 single input인 반면 MM-BiFPN의 encoding path는 각 modality 별로 input이 따로 들어가는 것을 확인할 수 있다. 이를 위해 early fusion 방식이 아닌 late fusion 방식을 도입하였다.
Early fusion은 multiple modality를 single input으로 merging하여 네트워크에 넣는 방식인데, 이 방법은 modality 사이의 관계가 linear하고 단순하게 취급되기 때문에 modality 사이의 상관관계가 무시된다. 하지만 late fusion 방식은 각 modality의 데이터를 독립적인 input으로서 취급하기 때문에 여러 타입의 representation을 가지고 modality 간의 correlation structure를 사용할 수 있다는 장점이 있다. MM-BiFPN은 late fusion 방식으로 depth 별 데이터를 fusing해 BiFPN에 입력한다.
2. Bi-FPN
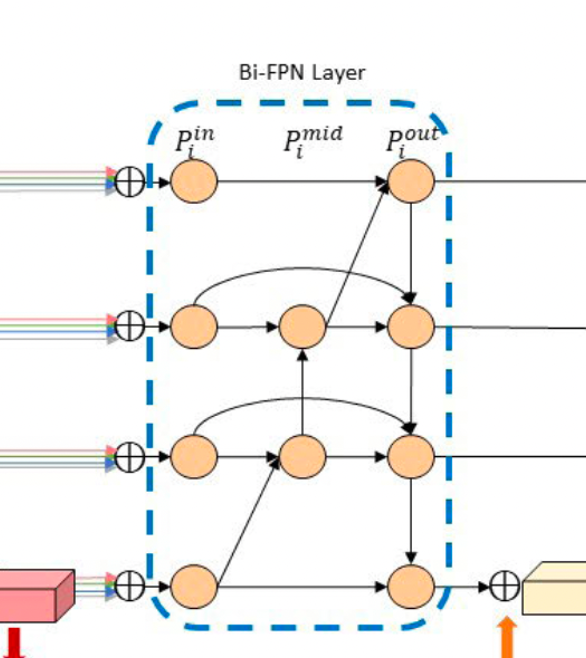
Bi-FPN은 기존의 FPN과 다르게 Multiple input을 사용하기 때문에 저차원과 고차원의 semantic feature들의 fusion을 사용할 수 있다. BiFPN에서는 feature들이 bottom-up과 top-down 두 방향으로 fusing이 되는 것을 볼 수 있고, 이를 통해 모델이 feature scale에 관련 없이 학습을 할 수 있다. 따라서 각 depth의 feature map을 확장할 수 있고 bifpn에 입력된 이후에는 depth 끼리의 cross-scale connection을 통해 여러 depth에 걸쳐 효과적인 feature fusing을 가능하게 한다.
3. Shared decoder
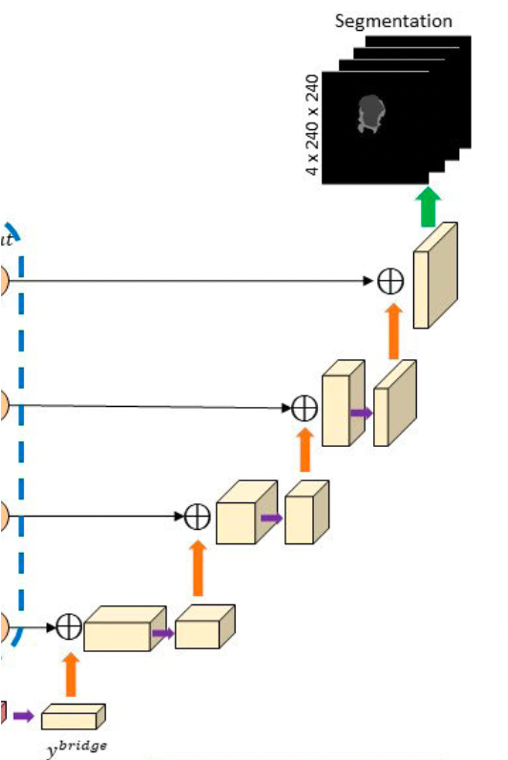
MM-BiFPN의 output과 bridge layer의 output이 shared decoder에 각각 입력되는데, 이때 brige layer는
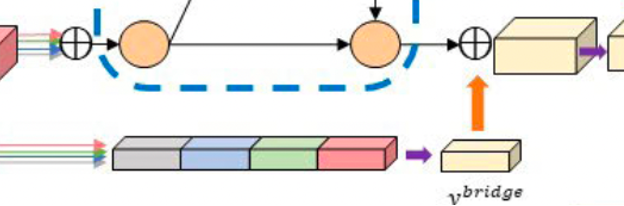
encoding path의 최종 output은 굉장히 condense하면서 저차원의 정보를 포함하고 있기 때문에 input image의 feature를 보존하고 중복되는 정보를 줄이기 위해 추가된 layer이다. maxpooling, 1x1 convolution을 통해 fusing 된 output의 차원을 축소해 이용 할 수 있다.
decoder는 기존 UNet과 비슷한 형태를 띠지만 BiFPN을 encoder와 decoder를 연결하는 매개체로서 사용을 하기 때문에 각 decoder의 layer는 이전 layer의 output과 biFPN의 output을 concat하여 input으로 입력한다.
